MPI in PetaVision
PetaVision uses MPI in two different ways: parallelizing across a batch, or splitting layers in the x- and y- directions. This page describes the use of MPI in PetaVision.
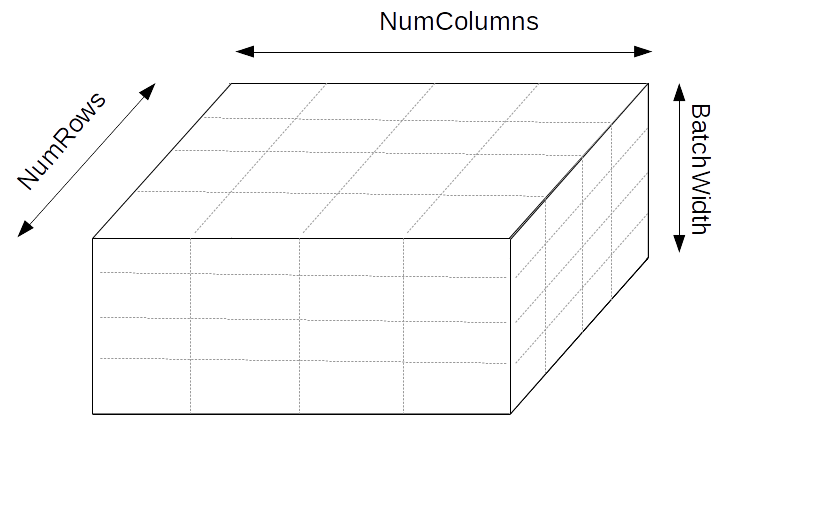
The diagram illustrates that MPI processes are arranged in a 3-dimensional
block. The dimensions of this block are coverned by the config file settings
NumColumns, NumRows, and BatchWidth. If you use command-line options instead
of a config file, the options are -columns, -rows, and -batchwidth.
Note that these are specified with a single hyphen, not a double hyphen.
If NumColumns is greater than one, then each HyPerLayer is split horizontally
into NumColumns slices. For each layer, the number of neurons in the
x-direction must divide by NumColumns evenly. NumRows acts the same way
regarding the y-direction.
If BatchWidth is greader than one, then it must divide the HyPerCol
parameter nbatch evenly. Each MPI process in the BatchWidth direction
will handle nbatch/BatchWidth of the batch elements.
Thus, suppose that a HyPerLayer is 256 pixels in the x-direction and 100 pixels
in the y-direction, and that the HyPerCol specifies an nbatch of 16.
Then in the example shown in the diagram, each MPI process takes a 64-pixel by
25-pixel slice of the layer, and computes it for four batch elements.
Note that if the layer were 256-by-50, it would be an error because NumRows=4
is not a divisor of 50.
The default input/output scheme for PVP files is that the entire column, across all batch elements is written to a single PVP file and read from a single PVP file. It is assumed that only the root process has access to the file system. However, if the number of MPI processes is large, the MPI communication costs from this scheme can be prohibitive. Therefore, there is also an N-to-M communication scheme, where the overall MPI block is divided into several smaller blocks, each of whose root process performs input/output.
The config file settings that define the dimensions of these smaller MPI blocks
are CheckpointCellNumColumns, CheckpointCellNumRows, and
CheckpointCellBatchDimension. They define the size of the smaller
input/output blocks. (The CheckpointCell terminology reflects that it was
originally created for checkpointing, but it now controls other input/output
behavior as well.) There are no command-line equivalents for these settings;
to set them a config file must be used.
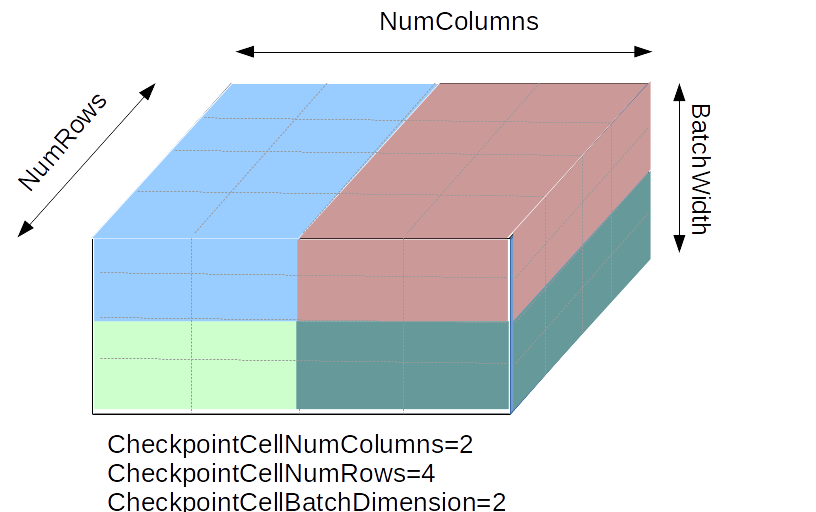
For example, if CheckpointCellNumColumns=2, CheckpointCellNumRows=4,
and CheckpointCellBatchDimension=2, then the MPI arrangement depicted is
divided into smaller 4-by-1-by-2 blocks, as shown by the shading in the
diagram. Note that the values refer to the size of the individual block,
not the number of blocks in the overall MPI arrangement.
The default value for each CheckpointCell config setting is the corresponding dimension of the overall MPI arrangement; that is, there is a single input/output block in that direction.
If there is a single input/output block, the PVP files generated by checkpointing are written to the CheckpointWriteDir directory, and read from either the CheckpointReadDir directory or the initializeFromCheckpointDir directory; and the PVP files generated by outputState is written to the outputPath directory.
If there is more than one input/output block, these directories contain
subdirectories, one for each input/output block. The directories have
names of the form block_coliirow_jelem_k, where i, j, and k
indicate the column, row, and batch position of the block. The values of
i run from 0 through I-1, where I = NumColumns/CheckpointCellNumColumns,
and similarly for j and k. Each subdirectory contains a PVP file
corresponding to the section covered by its input/output block.
Each input/output block has its own MPI communicator. The code assumes
that the root process of each MPI block has access to the file system; it
does not assume that any nonroot processes do.
When input/output blocks are used with layer in the InputLayer hierarchy (ImageLayer, PvpLayer), the root process of each input/output block assumes that the file it loads input from contains the input for the entire layer, not just for its block. The root process loads the entire input, and then scatters the relevent sections for its block to the other processes in its input/output block.