Chinese-English dictionary and digital library of literary Chinese classic and historic texts for English speakers. It includes a framework that can be re-used for other corpora including a template system, a Chinese-English dictionary, a corpus management system written in Go, web pages for learning grammar and such, a collection of texts, and a system for looking up the words in the texts by mouse over and popover by clicking on the words. Please join the low volume email group chinesenotes-announce for announcements of new features and other updates.
The software and dictionary powers several web sites with different corpora:
- http://chinesenotes.com - for literary Chinese documents and a small amount of modern Chinese
- http://ntireader.org - for the Taisho version of the Chinese Buddhist Canon
- http://hbreader.org - for Venerable Master Hsing Yun's collected writings
- http://www.primerbuddhism.org - A Primer in Chinese Buddhist Writings
The Chinese Notes software includes several components:
- cnreader - a Go program to analyze the library corpus, performing text segmentation, matching Chinese text to dictionary entries, indexing the text, and generating HTML files for reading the texts. This utility is something like Hugo or the Sphinx Python documentation generator.
- cnweb - a Go web application for reading and searching the texts and looking up dictionary entries. Dictionary data, library metadata, and a text retrieval index is loaded into a SQL database to support the web site.
Web application software for searching the dictionary and corpus is at https://github.com/alexamies/chinesenotes-go
A JavaScript library to help in presenting the web application is at https://github.com/alexamies/chinesedict-js
Python utilities for analysis of text in the structure here are at https://github.com/alexamies/chinesenotes-python
For a description of how the framework can be used for other corpora see FRAMEWORK.md.
Major sources used directly in the dictionary whose professional and freely shared work is gratefully acknowledged include:
- CC-CEDICT Chinese - English dictionary, shared under the Creative Commons Attribution-Share Alike 3.0 License
- Chinese Wikisource from the Wikimedia Foundation, aslo under a Creative Commons license
- Unihan Database from the Unicode Consortium under a freely reusable license
- 教育部國語辭典 Republic of China Ministry of Education Standard Chinese Dictionary, also under a Creative Commons license
This section explains building the Chinese Notes web site.
Installation instructions are for Debian.
Install git on the host and checkout the code base
git clone git://github.com/alexamies/chinesenotes.com
cd chinesenotes.com
export CNREADER_HOME=`pwd`Generates markup for HTML page popovers
Install go (see https://golang.org/doc/install)
For more details on the corpus organization and command line tool to process it see corpus/CORPUS-README.md and https://github.com/alexamies/cnreader
Basic use:
bin/cnreader.sh/bin
- Wrappers for command line Go programs, sich as the bin/cnreadher.sh script
/corpus
- raw text files for making up the text corpus
/data
- dictionary data files
/data/corpus
- metadata files describing the structure of the corpus
/html
- raw HTML content minus headers, footers, menus, etc. This is the source HTML before application of templates for pages that are not considered part of the corpus. The home, about, references, and relates pages are here.
/html/material-templates
- Go templates for generation of HTML files using material design lite styles. This directory can be overridden by setting an environment variable named TEMPLATE_HOME with the path relative to the project home.
/index
- Output from corpus analysis
/web-resources
- Static resources, including CSS, JavaScript, image, and sound files
/web-staging
- Generated HTML files. Many but not all files are generated with the Go command line tool cnreader. This is a default that can be overridden by setting an environment varialbe named WEB_DIR with the path relative to the project home.
The build machine builds the source code and Docker images. Get the project files from GitHub:
git clone https://github.com/alexamies/chinesenotes.com.gitSet the CNREADER_HOME env variable for reading data files:
export CNREADER_HOME=${PWD}/chinesenotes.comGet the web application code
git clone https://github.com/alexamies/chinesenotes-go.gitSet the web application binary home:
CNWEB_BIN_HOME=${PWD}/chinesenotes-goBuild the web application binary:
cd $CNWEB_BIN_HOME
go buildIf you have a GCP project setup, you can optionally connect to it from a local build by creating a service account key and defining shell variables
export PROJECT_ID=$PROJECT_ID
export GOOGLE_APPLICATION_CREDENTIALS=${PWD}/service-account.jsonRun the web app
cd $CNREADER_HOME
export CNWEB_HOME=$CNREADER_HOME
$CNWEB_BIN_HOME/chinesenotes-goContainerization has now replaced the old system of deployment directly on a virtual machine.
Instance name: BUILD_VM
Image type: Ubuntu Zesty 17.04
gcloud compute --project $PROJECT ssh --zone $ZONE $BUILD_VM
sudo apt-get remove docker docker-engine docker.io
sudo apt-get update
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get install docker-ce
sudo usermod -a -G docker ${USER}
# Run a test
docker run hello-world
For database setup see https://github.com/alexamies/chinesenotes-go
Compile the library document files and tiles into a tab separated file for loading into the database with the Python program
bin/doc_list.shCopy the text files to an object store. If you prefer not to use GCS, then you can use the local file system on the application server. The instructions here are for GCS. See Authenticating to Cloud Platform with Service Accounts for detailed instructions on authentication.
TEXT_BUCKET={your txt bucket}
# First time
gsutil mb gs://$TEXT_BUCKET
gsutil -m rsync -d -r corpus gs://$TEXT_BUCKET
To enable the web application to access the storage system, create a service account with a GCS Storage Object Admin role and download the JSOn credentials file, as described in Create service account credentials. Assuming that you saved the file in the current working directory as credentials.json, create a local environment variable for local testing
export GOOGLE_APPLICATION_CREDENTIALS=$PWD/credentials.json
go get -u cloud.google.com/go/storage
The Go app is not needed for chinesenotes.com at the moment but it is use for other sites (eg. hbreader.org).
Build the Docker image for the Go application:
docker build -t cn-app-image .
Run it locally with minimal features (C-E dictionary lookp only) enabled
docker run -it --rm -p 8080:8080 --name cn-app \
--mount type=bind,source="$(pwd)",target=/cnotes \
cn-app-image
Test basic lookup with curl
curl http://localhost:8080/find/?query=你好
curl http://localhost:8080/findsubstring?query=男&topic=Idiom
Run it locally with all features enabled
DBUSER=app_user
DBPASSWORD="***"
DATABASE=cse_dict
docker run -itd --rm -p 8080:8080 --name cn-app --link mariadb \
-e DBHOST=mariadb \
-e DBUSER=$DBUSER \
-e DBPASSWORD=$DBPASSWORD \
-e DATABASE=$DATABASE \
-e SENDGRID_API_KEY="$SENDGRID_API_KEY" \
-e GOOGLE_APPLICATION_CREDENTIALS=/cnotes/credentials.json \
-e TEXT_BUCKET="$TEXT_BUCKET" \
--mount type=bind,source="$(pwd)",target=/cnotes \
cn-app-image
Debug
docker exec -it cn-app bash Test locally by sending a Curl command. Home page
curl http://localhost:8080Translation memory:
curl http://localhost:8080/findtm?query=結實Push to Google Container Registry
docker tag cn-app-image gcr.io/$PROJECT/cn-app-image:$TAG
docker -- push gcr.io/$PROJECT/cn-app-image:$TAGOr use Cloud Build
BUILD_ID=[your build id]
gcloud builds submit --config cloudbuild.yaml . \
--substitutions=_IMAGE_TAG="$BUILD_ID"Check that the expected image has been added with the command
gcloud container images list-tags gcr.io/$PROJECT_ID/cn-app-imageSee the section web-resources/README.md for compiling and testing JavaScript and CSS files, including ther Material Design resources.
To generate all HTML files, from the top level project directory
export CNREADER_HOME=`pwd`
export DEV_HOME=`pwd`
bin/cnreader.sh
For production, copy the files to the storage system.
See e2etest/README.md
This is not stored to a container, rather the web files are uploaded to Google Cloud Storage. These command will run faster if executed from a build server in the cloud
export BUCKET={your bucket}
# First time
gsutil mb gs://$BUCKET
bin/push.sh
gsutil web set -m index.html -e 404.html gs://$BUCKET
The JSON file containing the version of the dictionary for the web client should be cached to reduce download time and cost. Create a bucket for it.
export CBUCKET={your bucket}
WEB_DIR=web-staging
# First time
gsutil mb gs://${CBUCKET}
gsutil iam ch allUsers:objectViewer gs://${CBUCKET}
# After updating the dictionary
gsutil -m -h "Cache-Control:public,max-age=3600" \
-h "Content-Type:application/json" \
-h "Content-Encoding:gzip" \
cp -a public-read -r $WEB_DIR/dist/ntireader.json.gz \
gs://${CBUCKET}/cached/ntireader.json.gz
Test that content is returned properly:
curl -I https://${DOMAIN}/cached/ntireader.json.gzNew: Replacing management of the Mariadb database in a Kubernetes cluster Follow instructions in Cloud SQL Quickstart using the Cloud Console.
Connect to the instance from a VM
DB_INSTANCE=[your database instance]
gcloud sql connect $DB_INSTANCE --user=root
Execute statements in first_time_setup.sql and corpus_index.ddl to define database and tables as per instructions at https://github.com/alexamies/chinesenotes-go
Don't forget to switch to the proper database
use cse_dictLoad the proper files into the words table as per data/load_data.sql, the proper corpus files into the database as per data/load_index.sql, and the proper index files as per index/load_word_freq.sql.
Deploy the web app to Cloud Run
PROJECT_ID=[Your project]
IMAGE=gcr.io/${PROJECT_ID}/cn-app-image:${BUILD_ID}
SERVICE=cnreader
REGION=us-central1
MEMORY=800Mi
TEXT_BUCKET=[Your GCS bucket name for text files]
gcloud run deploy --platform=managed $SERVICE \
--image $IMAGE \
--region=$REGION \
--memory "$MEMORY" \
--allow-unauthenticated \
--set-env-vars TEXT_BUCKET="$TEXT_BUCKET" \
--set-env-vars CNREADER_HOME="/" \
--set-env-vars PROJECT_ID=${PROJECT_ID} \
--set-env-vars AVG_DOC_LEN="4497"If needing to update traffic to the latest version run
gcloud run services update-traffic --platform=managed $SERVICE \
--to-latest \
--region=$REGION
Test it with the command
curl $URL/find/?query=你好You should see a JSON reply.
Run the term frequency analysis with Google Cloud Dataflow. Follow instructions at Chinese Text Reader
Create a GCP service account, download a key, and set it to the file:
export GOOGLE_APPLICATION_CREDENTIALS=${PWD}/dataflow-service-account.json
Set the location of the GCS bucket to read text from
TEXT_BUCKET=[your GCS bucket]
Use a different bucket for the Dataflow results and binaries:
DF_BUCKET=[your other GCS bucket]
Set the configuration environment variable
export CNREADER_HOME=${PWD}
From a higher directory, clone the cnreader Git project
cd ..
git clone https://github.com/alexamies/cnreader.git
export CNREADER_PATH=${PWD}/cnreader
cd cnreader/tfidf
The GCP project:
PROJECT_ID=[your project id]Run the pipeline on Dataflow
DATAFLOW_REGION=us-central1
CORPUS=cnotes
GEN=0
go run tfidf.go \
--input gs://${TEXT_BUCKET} \
--cnreader_home ${CNREADER_HOME} \
--corpus_fn data/corpus/collections.csv \
--corpus_data_dir data/corpus \
--corpus $CORPUS \
--generation $GEN \
--runner dataflow \
--project $PROJECT_ID \
--region $DATAFLOW_REGION \
--flexrs_goal=FLEXRS_COST_OPTIMIZED \
--staging_location gs://${DF_BUCKET}/binaries/
Track the job progress in the GCP console, as shown in the figure below.
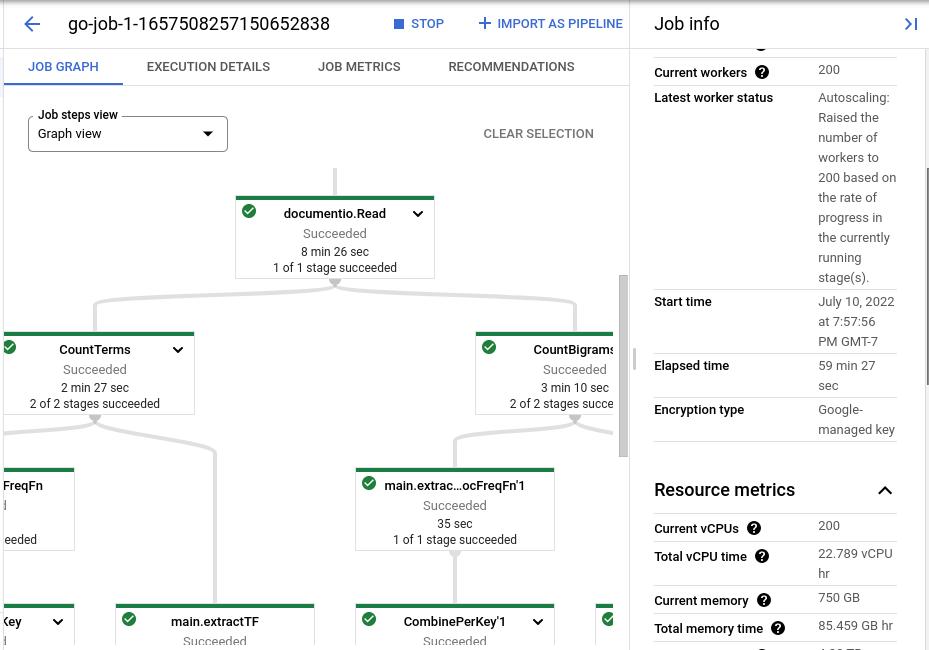
Validation test:
cd ..
COLLECTION=sunzibingfa.html
$CNREADER_PATH//cnreader --test_index_terms "兵,者" \
--project $PROJECT_ID \
--collection ${COLLECTION}Generate the bibliographic database
cd $CNREADER_HOME
$CNREADER_PATH/cnreader -titleindexTry full text search in the web app
export PROJECT_ID=$PROJECT_ID
export CNWEB_HOME=$CNREADER_HOME
$CNWEB_BIN_HOME/chinesenotes-go$CNREADER_PATH/cnreader --titleindex --project $PROJECT_IDAlso, generate a file for the document index, needed for the web app:
$CNREADER_PATH/cnreader --titleindex Run a search against the title index:
$CNREADER_PATH//cnreader --project $PROJECT_ID --titlesearch "尚書虞書"Run a full text Search search:
export TEXT_BUCKET=chinesenotes-text
$CNREADER_PATH/cnreader --project $PROJECT_ID --find_docs "所以風天下而正夫婦也" --outfile results.csvTo index idioms use the command
$CNREADER_PATH/cnreader --project $PROJECT_ID --dict_index Idiom
To index the translation memory use the command
nohup $CNREADER_PATH/cnreader --project $PROJECT_ID --tmindex &Indexing may take about 12 hours.
Search the translation memory index
$CNREADER_PATH/cnreader --project $PROJECT_ID --tmsearch 柳暗名明