This project implements a high performance, distributed task scheduler based on Golang.
Golang, Mongodb, etcd, JQuery + BootStrap, Docker, GCP
- Schedule a task to be executed at a fixed interval on front end page
- Kill a currently executing task on front end page
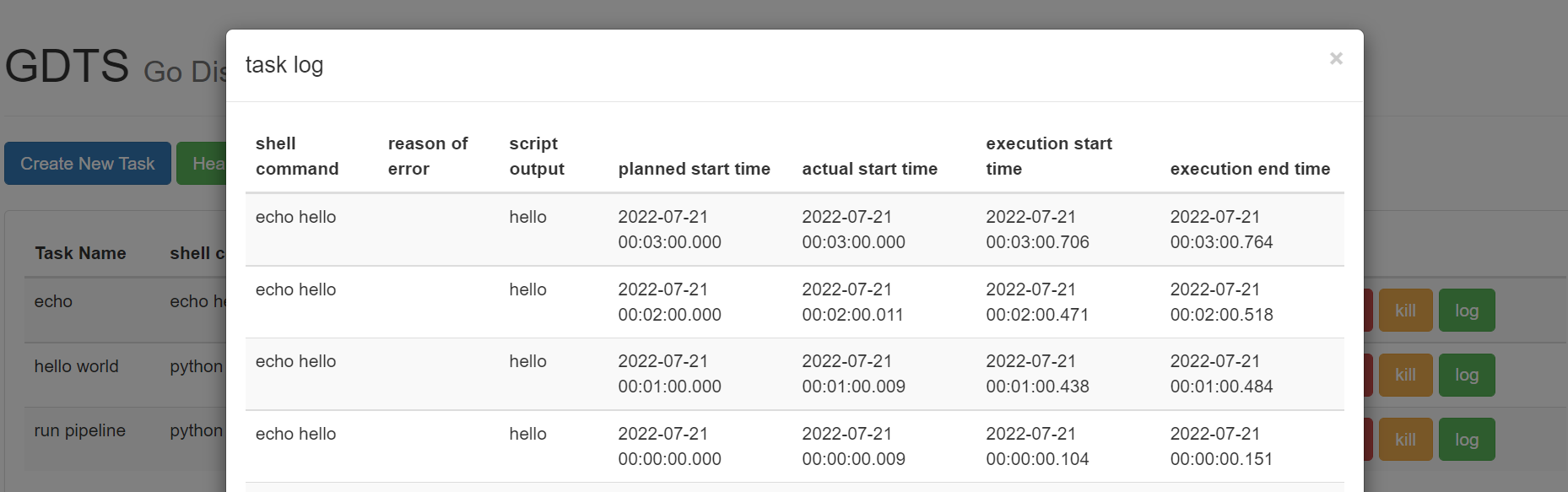
- View the logs of a task on front end page
- Can work in situations where network and machine failures are frequent, for it is distributed
srccontains source code.managercontains code of job managermainmanager.goentry point of job managermanager.jsonconfiguration of job managerwebrootfront end of job manager
workercontains code of job workermainworker.goentry point of job workerworker.jsonconfiguration of job worker
commoncontains common code shared by all modulestestcontains api examples in .http format, can be run in IntelliJ IDEslibcontains go examples interact with different toolsutilcontains database drivers and cron expression parse tool
softwarecontains linux programsserver-deployment-confcontains server deployment configuration on Linux
Testing on Google Cloud Compute Engine
2 CPUs, 4 GB RAM, 10 GB SSD, Ubuntu 20.04 LTS
2 manager + 10 workers + 3 etcd cluster + 2 mongodb
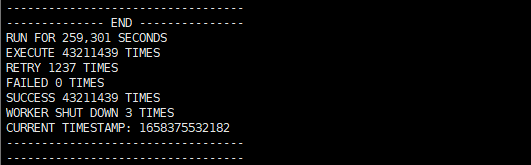
10000 simple jobs (each done in 1 ms) every minute
10 complex jobs (each done in 1 hour) every 12 hours
Ran for 72 hours with 0 errors

POST /job/save
Content-Type: application/x-www-form-urlencoded
job={"name":"<JOB NAME>","command":"<COMMAND>","cronExpr":"<7 fields cron expression>"}
POST /job/delete
Content-Type: application/x-www-form-urlencoded
name=<JOB NAME>
POST /job/kill
Content-Type: application/x-www-form-urlencoded
name=<JOB NAME>
GET /job/list
GET /job/log?name=<JOB NAME>&skip=<LOG OFFSET>&limit=<LOG LIMIT>
GET /worker/list
All APIs have an example in src/test in .http format, which can run in IntelliJ IDEs.
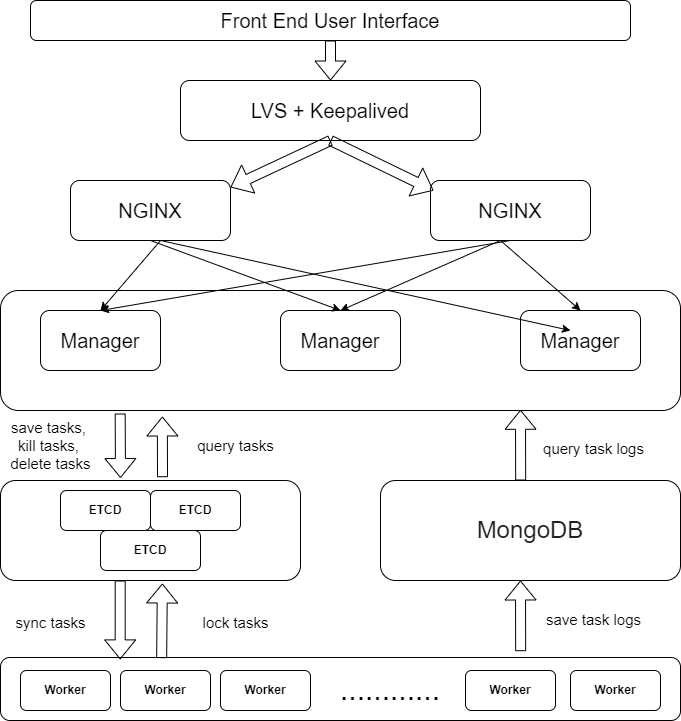
When there are too many scheduled tasks, one machine can be overloaded. GDTS has a manager service to handle as many as possible workers to solve this problem.
However, we may meet partition tolerance issues in distributed environment. We want to avoid the situation that several workers executing the same task. This can happen when a manager mistakenly think that a worker is dead and assign the corresponding task to another worker, because of the network issue.
Thus we use etcd as the middleware to solve this problem. The most important idea is to implement an optimistic distributed lock using etcd. When a worker trying to execute a task, it firstly acquire the lock of the task. If the lock was acquired before, the worker knows that some other worker is executing the task so it will simply skip it. Lease mechanism of etcd ensure that the lock is released after the task is finished or the worker dies.
Manager and Workers will not communicate directly. Both of them send and get information through etcd. Most data is stored in etcd, such as information of all jobs, registered healthy workers, locks, etc. With the watcher mechanism of etcd, worker can easily know new jobs assigned and its status, and the manager can easily know the status of workers.
After executing a task, the worker will send the execution result to the mongodb too, so that the manager can easily get the logs and offers an API for it.
The front end is implemented using JQuery and Bootstrap to provide a simple user interface.
To improve the availability of the system, we can use a load balancer to balance the load of the workers (e.g. LVS + keepalive). We can have several managers, each one with a stand-by. The image below shows the architecture:
Go SDK 1.10.8etcd (cluster) v3.3.8GOPATHneed to set as/GDTS- Set up mongodb and etcd first, and edit the ip & port in worker.json and manager.json
- simply run src/manager/main/manager.go and src/worker/main/worker.go
- then you can visit http://localhost:8070 to view the frontend user interface.
- package is fixed using go mod and go vendor so no need to re-install
- if on linux, you can use config files under
/server-deployment-conf/to deploy server