- Jose Rojas
- Justin Gutter
- Gabriel Hart Rockwell
Our team's agent is broken down into a heirarchy of individual subnetworks that were trained independently for each particular task. The subnetworks were trained exclusively on each task using reinforment learning via policy gradients.
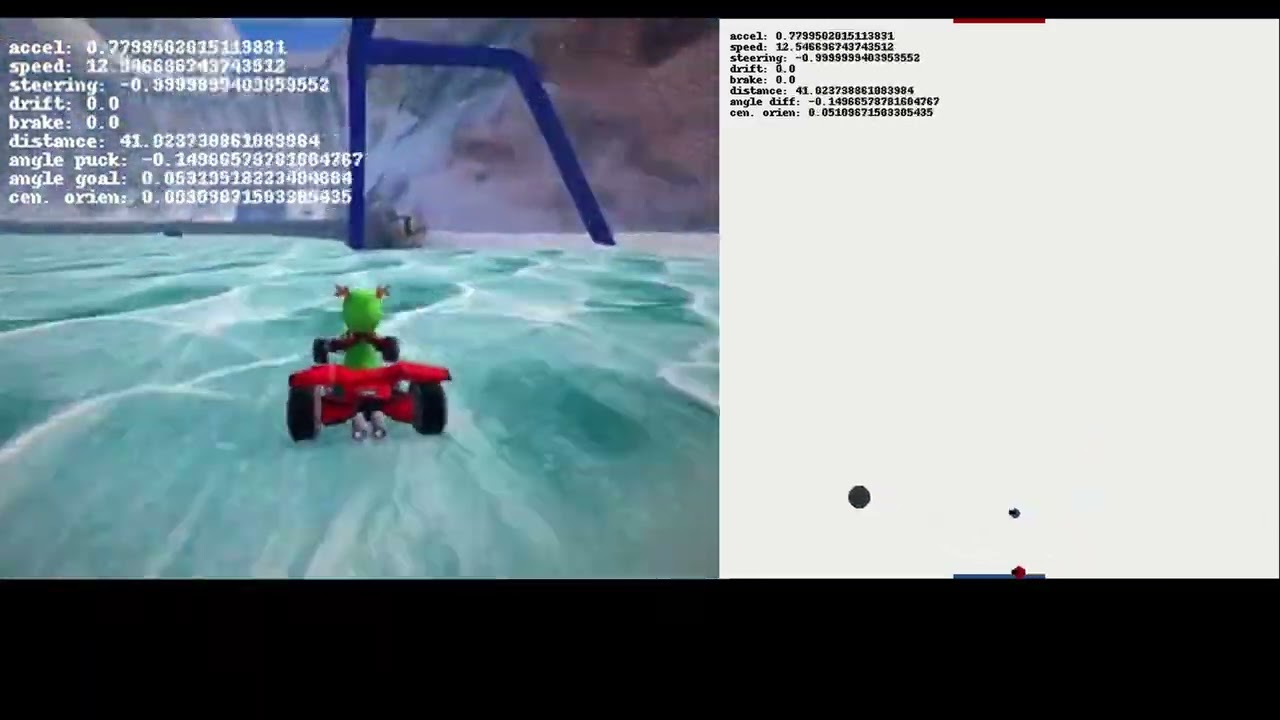
At the highest structure, there are the agents that make up the team. Each agent is broken into 'Actors' and at the bottom tiers are the 'Action Networks' which are PyTorch models. The agent executes each Actor, which is responsible for extracting the features for its respective Action network. The Networks/Actors communicate with each other via a global feature object (SoccerFeatures). This decouples the networks and allows for reconfiguration for easier training and debugging. The outputs of the networks at the bottom of the heirarchy of Actors produce the final actions to manipulate the cart without any controller logic or post-processing.
The agent extracts different features from the current and past states of the environment and feeds each set of features to the respective actor (SteeringActor|steer_net.pt, DriftActor|drift_net.pt, and SpeedActor|speed_net.pt), which then calculate the particular actions given the features. The Planner (planner_net.pt) then identifies the best policy action to take given a small set of pre-trained scenarios (e.g., head to the puck, move the puck to the goal, back up if stuck against a wall). The actions are then fed to the Fine Tuned Planner (ft_palnner_net.pt) which filters the actions to better act in the environment.
The Action Networks that generate the policy actions are all 2 layer linear networks, seperated by a tanh activation across the hidden network and have either raw outputs, tanh or sigmoid activations depending on what is best suited for the particular actuatiton that is needed to execute the policy actions. For example, tanh activations are used for the steering action network to produce outputs from -1 to 1.
__init__.py- initialization script for thestate_agentaction_nets.py- contains the various neural networks used by theactorsactors.py- contains the low level actors:SteeringActor,DriftActor,SpeedActorwhich actuate the cart by taking policy decision from the planner actors.agents.py- includes the agents, which are wrapers of the actors to allow them to act in the environment.core_utils.py- a subset ofutils_agentthestate_agentuses for the graderfeatures.py- contains the features that are extracted from the state of the environment and used in the action calculationsplanners.py- includes the Planner and Fine Tuned Planner classes, which determine the current state of the world and decide on what high level policy action is best. The planners output speed and steering offsets for the Drift, Steering and Speed Actors to process for final output.reinforce.py- REINFORCE implemntation by Jose, not used to train the modelremote.py- copy of the tournamentremoteused in development to train thestate_agentrewards.py- rewards for the policy gradient algorithmrunner.py- copy of the tournamentrunnerused in development to train thestate_agenttrain_arena.ipynb- main tool used to train the actors using policy gradientstrain_policy_gradient.py- contains the main policy gradient algorithm used to train thestate_agenttrain_reinforce.py- REINFORCE implemntation by Justin, not used to train the modeltrain_runner.py- A wrapper around runner and train for executing repetitve reinforement learning data collection and training. Not used extensively to in training thestate_agent.utils.py- copy of the tournamentutilsused in development to train thestate_agentutils_agent.py- all custom utilities used in development to train thestate_agent
All code below was used for trying to imitate agents in the environment. The
R&D proved unfruitful and the final state_agent did not use imitation learning
to train the agent.
train_imitation.py- implentation of imitation algorithm by Justintrain_imitation_action_network.py- neural nets used for the imitation agenttrain_imitation_categorize_movements.py- script to isolate segments of particular movements: moving backwards, moving to the puck, scoring a goal, etc.train_imitation_extract_features_for_categories.py- functions used to isolate movements from a entire match. Used bytrain_imitation_categorize_movements.train_imitation_improved.py- improvement oftrain_imitationby Hart including bug fixes and batch gradient descent.train_imitation_utils.py- utilities used bytrain_imitation_improved
Files listed below are the JIT Scripts for each actor that work in unison to act in the environment.
drift_net.ptft_planner_net.ptplanner_net.ptspeed_net.ptsteer_net.pt
Note that train_reinforce trajectory data is generated and used in code/state_agent/reinforce_data.
Create a new ActionNetwork and roll out 3 trajectories per 2 epochs
python -m state_agent.trainers.train_reinforce -nt 3 -ep 2
Load an existing ActionNetwork from code/state_agent/state_agent.pt and rolls out against only jurgen_agent. Perform training using SGD and learning rate of 0.01.
python -m state_agent.trainers.train_reinforce --load_model --training_opponent jurgen_agent --optimizer SGD -lr .01
For a complete list of available command line options.
python -m state_agent.trainers.train_reinforce --help
Load an existing ActionNetwork from code/state_agent/state_agent.pt and perform self-play (i.e. play against state_agent). Record a video every 5 games.
python -m state_agent.trainers.train_reinforce --load_model --training_opponent state_agent --record_video_cadence 5
Rollout 10 trajectories and save the state pkl files in state_agent/imitation_data. Team1 is set to jurgen_agent and team2 is randomized each trajectory (either jurgen_agent, geoffrey_agent, yann_agent, or yoshua_agent):
python -m state_agent.utils --datapath state_agent/imitation_data --n_trajectories 10 --team1 jurgen_agent --team2 random
Create a new ActionNetwork and performs imitation learning for 10 epochs.
python -m state_agent.trainers.train_imitation -ep 10 -dp state_agent/imitation_data
Load an existing ActionNetwork from code/state_agent/state_agent.pt and performs imitation learning. State_Agent will imitate Team2.
python -m state_agent.trainers.train_imitation --load_model -dp state_agent/imitation_data --imitation_team 2
For a complete list of available command line options.
python -m state_agent.trainers.train_imitation --help