A fully research of Llama3, Qwen2,5, Deepseek2 tech blog / paper, summarize all the benchmarks used and its corresponding paper details. Welcome to add new benchmark and your summarization!
MMLU——(5 shot / 0-shot + COT)
该基准测试涵盖57个学科领域,包括STEM、人文学科和社会科学,旨在评估模型在零样本和少样本设置下的知识和推理能力。

覆盖57种任务的大型多任务测试。这些任务涵盖了多个学科,包括:
- 人文学科:法律、哲学、历史等。
- 社会科学:经济学、心理学、政治学、社会学等。
- STEM领域:数学、物理、计算机科学、工程学等。
- 其他领域:医学、商业伦理、营养学等。
每个任务根据学科和难度级别分类,例如高中、大学或专业水平。
任务的问题数据来源主要包括以下:
- 在线免费资源,如GRE考试和美国医师执照考试的练习题。
- 面向本科课程的设计题目。
- 其他专业考试的示例问题,如心理学和医学考试题。
数据集共包含15,908个问题,分为开发集、验证集和测试集。
- 手动收集:由研究生和本科生从公开资源中提取问题。
- 多层次难度:测试问题的难度从基础到专业级别不等。
- 广泛覆盖:涵盖世界知识与问题解决能力的测试,从传统领域(如数学)到伦理学等新兴领域。
数据集进一步划分为少样本开发集(每个学科5个问题)、验证集(1540个问题)和测试集(14,079个问题)。
测试通过多项选择题的分类准确率来评估模型的表现。
- 零样本和少样本设置:测试模型在没有微调的情况下解决问题的能力,模拟人类对知识的学习方式。
- 跨任务平均表现:通过所有57个任务的平均准确率来衡量模型的整体能力。
- 人类基准:与真实人类表现相比(例如亚马逊工人和专业人士的平均得分)。

MMLU-Pro——(5 shot + COT)
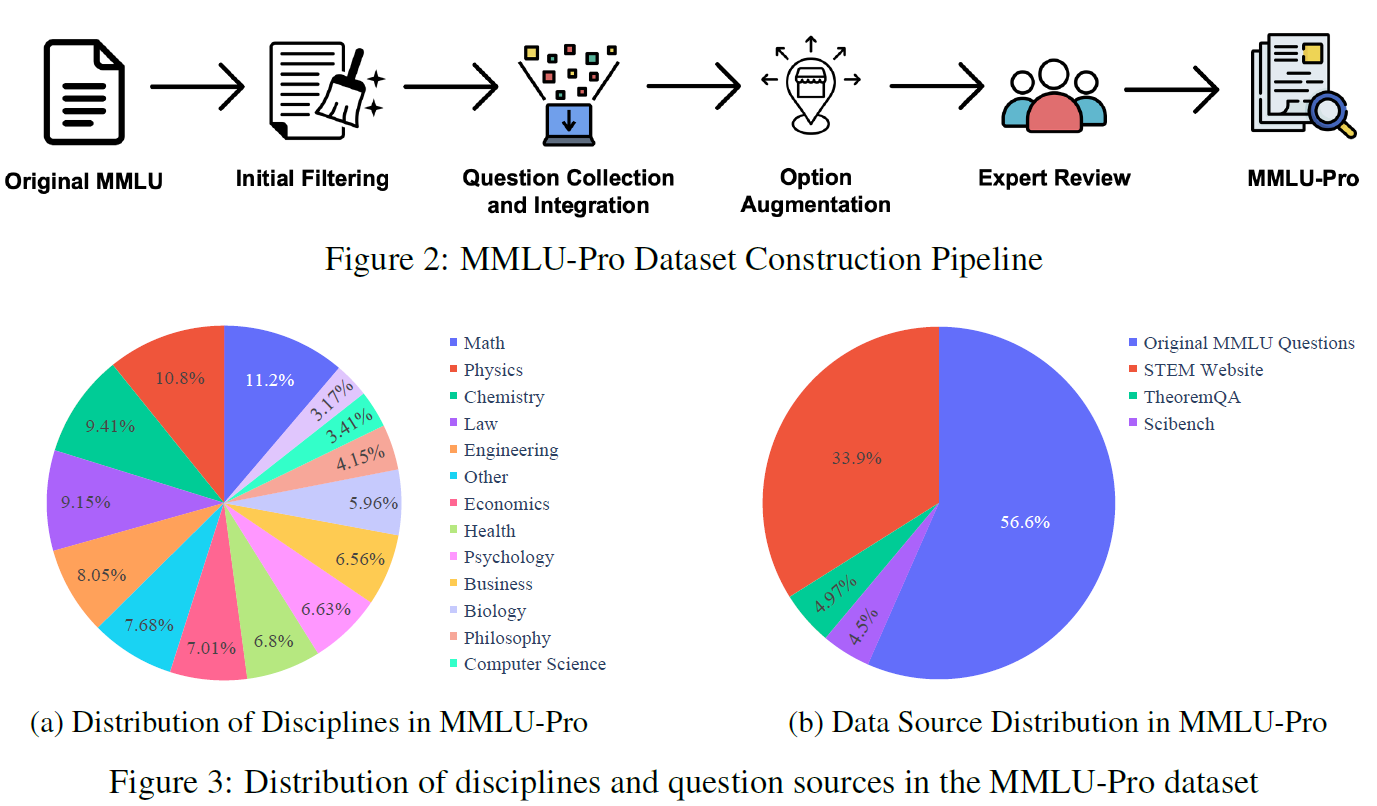
- 性能饱和:例如,GPT-4在MMLU上的准确率已达到86%以上,使得区分高性能模型变得困难。
- 测试偏差:MMLU题目多为知识驱动,推理要求较低;选项数限制在4个,易被模型通过统计或模式识别技巧破解。
- 数据质量问题:部分题目存在标注错误或无法回答的问题。
- 选项扩展:将题目选项数量从4个增加到10个,通过引入更多的干扰项,降低模型通过猜测正确回答的概率。
- 高难度题目:增加大学水平考试题目比例,尤其是需要模型进行推理的学科(如数学、工程)。
- 质量提升:通过专家和高级语言模型两轮校验,清理错误标注和无效题目,提高数据集的可靠性。
- 学科整合:将原MMLU的57个学科整合为14个更广泛的学科领域,包括数学、物理、法律、心理学等。
- Task: "Mathematical Problem Solving"
- Input: "What is the square root of 144?"
- Output: "12"
- Difficulty: "Easy"
用于评估LLMs遵循指令的能力。作者开发了一个名为IFEval的基准测试框架,通过“可验证指令”来实现高效且自动化的评估,避免了传统人工评估的高成本和主观性。
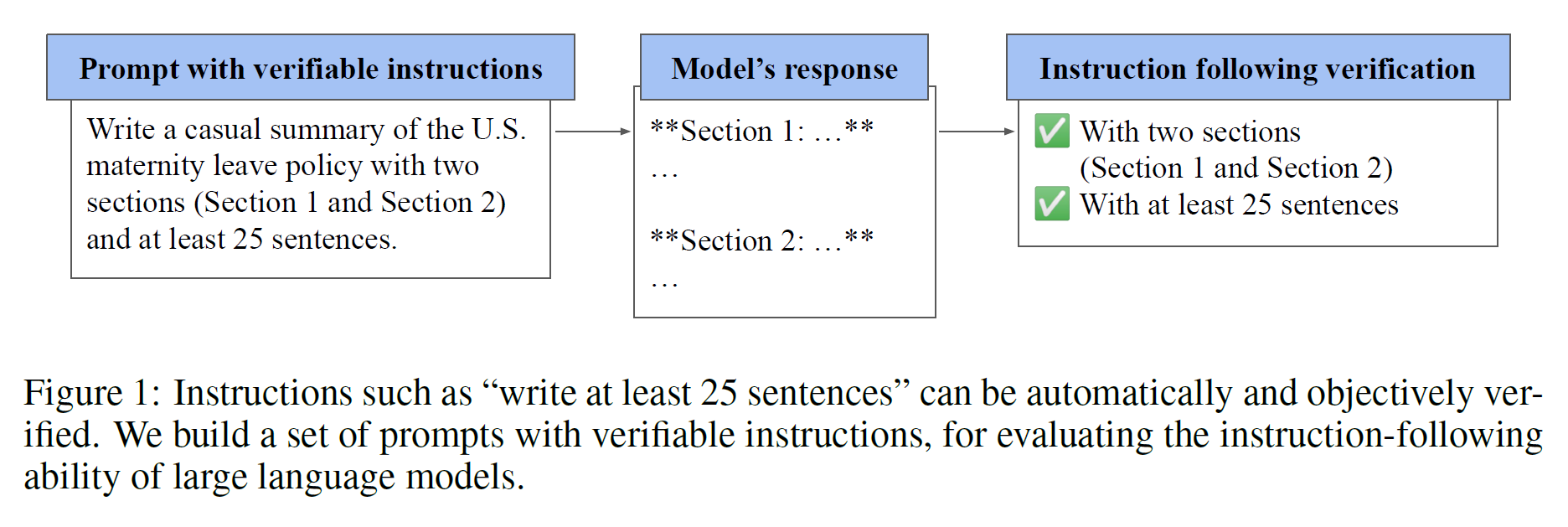
LLM能够解析和执行自然语言指令,但评估这一能力面临多重挑战:
- 人工评估昂贵且不易复现,可能因主观性带来偏差。
- 模型自评估依赖评估模型的能力,容易引入错误信号。
- 标准化不足:现有方法未能为不同指令类型提供统一的评价指标。
因此,作者开发了IFEval,旨在通过可验证指令评估模型的指令执行能力,确保评价的客观性和可复现性。
可验证指令是明确且可通过程序验证的任务指令,如:
- 写一段450至500字的文字。
- 确保响应包含关键词3次。
- 用特定格式(如JSON)输出。
特点:
- 明确性:每条指令都包含具体要求,可通过算法检测是否达成。
- 多样性:覆盖语言、格式、长度、关键词等多方面。
- 可扩展性:通过增加指令种类提升复杂性。
文章列出了25种可验证指令类型,并结合多样化的任务设计了约500条提示。
作者通过以下流程构建和验证指令:
- 指令生成:从基本任务提示出发,随机附加1至3条可验证指令。
- 去歧义与优化:采用少样本学习排除矛盾或无效指令。
- 手动校对:通过人工检查确保指令的逻辑性和多样性。
验证标准分为:
- 严格匹配:完全符合指令要求的为正确。
- 松散匹配:允许文本变体或格式调整后的验证。
作者测试了GPT-4和PaLM 2等模型在IFEval上的表现,并提出以下评估指标:
- 提示级准确率:整个提示中的所有指令被正确遵循的百分比。
- 指令级准确率:单条指令被正确执行的比例。
结果:
- GPT-4表现显著优于PaLM 2,提示级准确率达到76.89%。
- 不同指令类型的准确率分布揭示了模型在特定任务上的强弱。
作者指出,IFEval的改进方向包括:
- 增加指令类型和任务数量。
- 拓展到多模态场景(如生成图像)。
- 优化评价指标以适配更复杂的应用场景。
GSM8K —— (8-shot + COT)
这篇文章由OpenAI团队撰写,提出了一种基于验证器(verifiers)的新方法,用于解决数学文字题(math word problems)。主要目标是提高LLM在多步骤数学推理任务中的性能,解决模型容易犯错和缺乏自我纠错机制的问题。
数学文字题要求模型不仅需要理解自然语言,还需执行多步骤推理。然而:
- 错误敏感性高:生成的答案中任何一个步骤的错误都会导致最终答案错误。
- 生成过程不可逆:现有的自回归生成模型难以纠正中间步骤的错误。
因此,作者提出通过训练验证器来对模型生成的答案进行评估,并选择最优解。
为支持研究,文章引入了一个新的数据集GSM8K,包括8500道高质量的小学数学文字题:
- 多样性:避免模板化设计,问题形式和语言风格多样化。
- 难度适中:题目使用基本算术运算(加、减、乘、除),设计为难倒现有的大型模型但仍可解决。
- 自然语言解答:解答过程采用自然语言描述,而不是纯粹的数学表达式,帮助理解模型的推理过程。
数据集分为7500道训练题和1000道测试题,所有题目经过人工和算法的质量检查,错误率低于2%。
作者提出了两种方法来提升模型解决问题的能力:
- 微调(Finetuning):
- 直接通过微调训练语言模型。
- 在测试时,生成单个low temperature样本并检查答案是否正确。
- 验证(Verification):
- 生成多个解答(high temperature样本),利用验证器对每个解答评分。
- 验证器判断解答是否正确,并选择评分最高的答案。
- 验证器的训练只需判断生成的解答是否能达到正确答案。
- 定义:设置一个较低的温度值(通常接近 0,例如 T=0.1T = 0.1T=0.1 或 T=0T = 0T=0)。
- 效果:
- 模型倾向于选择概率最高的词汇(最确定的选项)。
- 生成结果更“保守”,更具确定性。
- 优点:
- 在数学问题中,低温生成适合测试模型是否能够在严格推理下生成正确答案。
- 输出更稳定,可复现性高。
- 使用场景:在验证微调模型时,生成单个解答来判断模型是否能准确完成任务。
- 定义:设置一个较高的温度值(例如 T=0.7T = 0.7T=0.7 或 T=1.0T = 1.0T=1.0)。
- 效果:
- 增加生成结果的多样性,模型更可能选择概率较低的词汇。
- 生成结果更具创造性和随机性。
- 优点:
- 有助于生成多个解答(高温样本)以供验证器评分。
- 在任务需要探索更多解答可能性时效果显著。
- 使用场景:为验证器生成多个候选解答,让验证器挑选最优解。
验证器的优势在于:
- 任务简单,评分效率高。
- 可以扩展到更复杂的数据分布和模型架构。
实验比较了基于微调和验证器的方法在不同模型规模(如6B和175B)上的表现:
- 性能提升显著:验证器比微调基线提升了相当于30倍模型参数规模的效果。
- 数据规模的影响:验证器对数据扩展的效果优于微调,特别是在大数据集上。
- 计算效率:尽管生成多个样本增加了计算开销,但在计算次数适中(如100次)时验证器效果最佳。
- 计算器注释:训练中加入计算器注释以减少计算错误,例如将“20 + 10 =”替换为“<<20+10=30>>”。
- 验证器目标:通过解决正确性判断的辅助目标,帮助模型更准确地评分。
- 错误识别局限:验证器在某些场景中无法区分逻辑正确性与答案正确性。
- 数据集依赖:GSM8K主要关注基础算术,尚未涵盖更高级数学或跨领域问题。
MATH —— (0-shot + COT)
数学问题解决能力是评估人工智能推理能力的重要指标,然而:
- 现有模型在数学问题上表现较差,尤其是多步骤推理任务。
- 许多数据集只关注简单的计算或形式化证明,而缺乏自然语言描述的复杂问题。
因此,作者引入了MATH数据集,旨在通过具有挑战性的数学问题评估模型的推理能力。
- 数据来源与规模:
- MATH包含12,500道问题,这些问题主要来自数学竞赛(如AMC和AIME)。
- 每个问题附带详细的分步解答和最终答案,便于模型学习与评估。
- 覆盖范围:
- 包括7个数学领域:代数、几何、数论、概率统计等。
- 每个领域的问题按难度分为1到5级,从简单计算到高难度问题不等。
- 解答格式:
- 问题和解答使用LATEX书写,确保一致性和清晰度。
- 解答以分步形式呈现,帮助模型学习完整的推理过程。
作者测试了多种语言模型(如GPT-2、GPT-3)在MATH上的表现,主要发现包括:
- 表现较低:
- GPT-3(175B参数)在MATH上的准确率仅为6.9%。
- 即使是最简单的问题(难度1),模型的准确率也仅为15%。
- 规模效应有限:
- 增加模型参数量只能带来有限的性能提升。
- 预计需要极其庞大的模型才能显著提高准确率,这在计算资源上是不现实的。
- 人类表现:
- 普通大学生在测试中平均得分为40%。
- 数学奥赛金牌获得者的得分为90%,表明MATH数据集对人类也有一定挑战性。
为了提高模型在MATH上的表现,作者开发了一个辅助预训练数据集AMPS:
- 包含超过500万道问题,包括Khan Academy练习题和通过Mathematica生成的问题。
- 涉及从基础数学到高等数学的多个领域。
- 在预训练阶段引入AMPS显著提高了模型性能。
- 分步解答的作用:
- 训练中引入分步解答可以提高模型准确率。
- 但生成过程中的逻辑错误会影响最终答案质量。
- 提示帮助:
- 给模型提供部分解答作为提示,可以提升最终解答的准确率。
- 即使提供接近完整的解答,模型的正确率也仅为40%左右,表明仍有很大改进空间。
- MATH数据集通过具有挑战性的问题和细化的评估指标,为研究数学问题解决的AI提供了新的基准。
- 尽管当前模型在MATH上的表现有限,作者强调,需要新的算法改进,而不仅仅是依赖于模型规模的扩展。
- 未来的研究方向包括更好地利用分步解答和开发新的数学推理算法。
GPQA —— (0 shot + COT)
专为研究如何在极具挑战性的场景中监督和评估模型而设计
随着大型语言模型(LLMs)的发展,其在复杂推理任务中的潜力逐渐显现。然而,在处理需要高度专业化知识的问题时,AI模型的准确性和可靠性仍然是一个挑战。研究者提出GPQA的主要目标包括:
- 测试AI在领域知识问题中的能力,尤其是那些超出一般人类专家能力范围的问题。
- 支持“可扩展监督”研究,通过人类监督协议提高AI模型在未来超人类任务中的表现。
- 高质量与高难度:
- GPQA数据集包含448道多项选择题,这些问题由生物、化学和物理领域的博士及博士生撰写。
- 问题涵盖了复杂领域知识,具有明确的正确答案和详细的解答说明。
- “Google-proof”设计:
- GPQA的问题设计使得即使非专家使用互联网搜索答案,也无法轻松解答。
- 数据集旨在挑战现有语言模型及其工具辅助能力。
- 验证流程:
- 专家与非专家分别对问题进行验证。
- 专家平均准确率为65%,非专家仅为34%,表明数据集的高难度。
- 问题撰写:
- 61名领域专家通过详细指导撰写问题,问题需清晰、难度高,并包含可验证的答案。
- 每个问题至少需要两个领域专家验证,确保客观性。
- 验证阶段:
- 专家验证:两轮专家独立解答和反馈。
- 非专家验证:来自其他领域的专家尝试解答问题,以测试问题对非熟悉领域人员的难度。
- 问题分类:
- 数据集分为GPQA主集和GPQA Diamond子集:
- 主集包含所有高质量问题。
- Diamond子集包括那些两个专家均答对且至少2/3非专家答错的问题,难度更高。
- 数据集分为GPQA主集和GPQA Diamond子集:
作者在GPQA上测试了多个大型语言模型(如GPT-4)和人类验证者:
- GPT-4表现:使用链式推理提示,GPT-4的准确率为39%,略高于非专家,但远低于专家。
- 非专家表现:即便具备丰富资源(包括网络搜索),非专家的平均准确率仅为34%,表明问题的Google-proof属性。
- 专家表现:两轮专家验证后,准确率达到65%-74%。
GPQA的主要应用场景包括:
- AI模型的可扩展监督实验:研究如何通过人类与AI协作改进模型输出的准确性。
- 超高难度问答任务:帮助开发更强大的模型来解答远超一般人类能力的问题。
- 数据集规模有限:仅有448道问题,难以进行大规模模型训练。
- 多样性不足:问题集中在生物、化学和物理领域,其他学科尚未覆盖。
- 偏差可能:问题设计依赖专家的背景和文化,这可能会引入偏差。
ARC-Challenge —— (0 shot)
ARC的目标是挑战现有的语言模型,使其需要更强的知识推理能力,而不仅仅依赖表面信息。
当前的许多问答任务数据集(如SQuAD或SNLI)主要依赖于检索任务,模型可以通过表面级信息(如关键词匹配)来找到答案。这种形式的问答测试未能推动模型在推理、常识知识整合等方面的发展。
ARC旨在弥补这一不足,推动人工智能在以下领域的进步:
- 更复杂的推理:需要整合多种知识和信息。
- 超越简单检索:答案无法通过简单的检索算法获得。
- 学科多样性:问题覆盖广泛的领域(主要是科学领域)。
-
数据量与分类:
- 数据集包含7787道题目,分为:
- Challenge Set(挑战集):2590道较难的问题。
- Easy Set(简单集):5197道较容易的问题。
- 问题类型为多项选择题(通常为4选1)。
- 数据集包含7787道题目,分为:
-
问题来源:
- 所有问题均来自美国小学和中学的标准化科学测试。
- 覆盖广泛学科知识,包括生物学、物理学、地质学等。
-
分类标准:
挑战集中的问题是那些无法通过以下两种简单方法解答的问题:
- 信息检索算法(IR):基于检索的答案匹配。
- 共现算法(PMI):基于词语的统计相关性。
为了解决复杂问题,ARC还提供了一个科学语料库(ARC Corpus),包含1400万句科学相关的句子。语料库特点:
- 包含与科学相关的背景知识。
- 覆盖约95%的挑战集问题所需的知识。
作者测试了多种基线模型在ARC上的表现,包括:
- 简单方法:
- 信息检索(IR)
- 共现算法(PMI)
- 神经网络模型:
- BiDAF:适用于阅读理解的双向注意流模型。
- DecompAttn:分解注意力模型。
- DGEM:基于图的推理模型。
实验结果:
- 在挑战集上,无论是传统方法还是神经模型,其表现均接近随机猜测(25%准确率)。
- 在简单集中,模型准确率可以达到50%-60%。
ARC中的问题需要多种知识和推理能力,包括:
- 知识类型:
- 定义性知识(例如:“什么是全球变暖?”)。
- 基本事实与属性(例如:“空气中含量最多的元素是什么?”)。
- 过程与因果推理(例如:“沉积岩形成的第一步是什么?”)。
- 推理类型:
- 多跳推理(需要从多个知识点中整合答案)。
- 假设推理与反事实推理。
- 空间与运动推理。
ARC为当前的问答研究提出了新的挑战:
- 推动模型超越简单的检索与匹配,提升推理和知识整合能力。
- 强调模型在复杂推理问题上的发展,而不仅仅依赖规模扩展。
- 为AI研究提供了一个全新的基准,吸引更多研究者关注高难度任务。
- 问题来源有限:问题集中在科学领域,学科覆盖范围可以进一步扩展。
- 模型改进空间:当前的基线模型在挑战集上的表现仍有很大提升空间。
HumanEval——(0-shot)
- 随着大型语言模型在自然语言处理中的成功,研究者开始探索将其应用于代码生成。
- 传统的代码生成面临挑战,如代码的功能正确性和复杂任务的推理需求。
- 本研究开发了Codex模型,并设计了一个新的测试集HumanEval,用于评估模型从自然语言生成代码的能力。
- 训练数据:
- 使用来自GitHub的公开代码库训练,包含179 GB的Python代码。
- 数据经过筛选,剔除了自动生成文件、超长行代码和低质量文件。
- 评估目标:
- 模型需根据注释生成正确的Python函数。
- 使用单元测试(unit tests)验证生成代码的功能正确性,而非仅匹配参考解答。
- 模型优化:
- 在GPT-3基础上微调以提升代码生成能力。
- 采用高温和多样化采样策略生成多种代码解答。
- 数据集内容:
- 包含164道手写编程问题,每个问题包含函数签名、自然语言描述(docstring)、完整函数体和单元测试。
- 问题涵盖算法、数学运算和语言理解任务。
- 评估指标:
- 使用pass@k指标评估模型生成代码的功能正确性:
- pass@1:单次生成的正确率。
- pass@k:从k个生成样本中至少有一个通过测试的概率。
- 使用pass@k指标评估模型生成代码的功能正确性:
- 模型性能:
- Codex在HumanEval上的pass@1表现显著优于未训练于代码任务的GPT模型:
- Codex-12B的pass@1为28.8%,而GPT-3为0%。
- Codex在HumanEval上的pass@1表现显著优于未训练于代码任务的GPT模型:
- 多样化生成的效果:
- 对每个问题生成100个样本,Codex能在77.5%的问题上找到至少一个通过测试的代码。
- 与其他模型比较:
- Codex在pass@k上的表现优于GPT-Neo和TabNine等其他代码生成模型。
- 功能性错误:
- Codex有时生成表面上正确但功能错误的代码。
- 对长链式操作描述(如复杂任务注释)或变量绑定可能失败。
- 训练数据的依赖:
- 由于训练数据来自GitHub,模型可能对特定的编程风格或库存在偏差。
- 效率问题:
- Codex的生成方法需要大量样本以提高正确率,可能不适合实时或高效部署。
- 潜在用途:
- 提高程序员生产力,支持代码自动补全。
- 为非程序员提供代码生成工具,降低编程门槛。
- 潜在风险:
- 可能生成不安全或偏差代码,导致安全问题。
- 在某些情况下,过于依赖生成代码可能引发对AI工具的过度信任。
- 优化模型以减少功能错误。
- 扩展模型以支持更多编程语言和复杂任务。
- 研究如何更高效地生成高质量代码以适应实际应用。
EvalPlus + HumanEval+ —— (0-shot)
文章提出了一种名为EvalPlus的框架,用于评估由大型语言模型(LLMs)生成代码的功能正确性。研究的重点是现有基准(HUMANEVAL)在测试充分性上的不足,以及EvalPlus在生成高质量测试用例以捕获更多错误代码上的改进能力。
- 编程任务的复杂性:代码生成是LLMs的重要应用场景,但现有的测试方法难以捕捉生成代码中的潜在错误。
- HUMANEVAL的局限性:每个任务仅包含少量测试用例(平均不到10个),不足以捕捉边界情况。自然语言描述模糊,可能导致模型对任务目标的错误解释。
- 核心方法:
- 自动测试用例生成:使用ChatGPT生成高质量的种子测试输入,涵盖复杂和边界情况。基于种子测试用例,应用类型感知(type-aware)的变异方法生成大规模测试用例。
- 差分测试:通过对比生成代码与基准代码的输出,检测潜在错误。
- 测试用例优化:利用集合覆盖算法减少测试用例数量,同时保留测试效果。
- HUMANEVAL+ 数据集:
- EvalPlus将原始HUMANEVAL扩展了80倍,生成了HUMANEVAL+。
- 添加了更全面的测试用例,覆盖边界情况并修正了原始数据集中的逻辑错误。
- 测试准确性提升:
- 在EvalPlus改进的测试集上,LLMs的功能正确性(pass@k)下降了19%-28%,表明原有测试不足以捕捉错误。
- 示例:ChatGPT在HUMANEVAL上的pass@1为73.2%,而在HUMANEVAL+上仅为63.4%。
- 模型排名变化:
- 在原始HUMANEVAL中表现较差的模型(如WizardCoder-CodeLlama),在HUMANEVAL+上超过了ChatGPT。
- 发现新的缺陷:
- 原始HUMANEVAL中有11%的任务存在不正确的参考解答,EvalPlus通过自动生成测试用例发现并修复了这些缺陷。
- 增强评估标准:
- EvalPlus通过生成更多测试用例,显著提高了LLMs评估的准确性。
- 数据集扩展:
- HUMANEVAL+提供了更全面的测试基准,可用于未来的代码生成研究。
- 测试用例优化:
- HUMANEVAL+-MINI仅使用原测试数量的1/47,却达到了类似的测试效果。
- 扩展EvalPlus至更多编程语言和实际场景。
- 研究如何结合正式验证方法提升测试的覆盖率和准确性。
- 将EvalPlus集成至代码生成工具(如Copilot)以实时提醒潜在错误。
MBPP——(0-shot + COT)
作者提出并评估了两个新的基准数据集,并探讨了模型在不同规模、提示和微调设置下的性能。
程序合成是人工智能领域的重要任务,旨在通过自然语言描述生成符合功能要求的代码。传统的程序合成多基于有限的领域特定语言(DSL),而这项研究探索了LLMs在通用编程语言中的潜力。
目标:
- 评估LLMs能否从自然语言描述中生成短程序。
- 探讨模型规模和微调对程序合成性能的影响。
- 研究模型与人类交互提升代码质量的潜力。
- MBPP(Mostly Basic Programming Problems):
- 包含974道编程问题,适合初级程序员解决。
- 每个问题包括自然语言描述、目标Python函数和三个测试用例。
- 数据集中426道问题经过人工验证以确保准确性。
- MathQA-Python:
- 基于MathQA数据集改编,包含23914道数学问题及其Python实现。
- 问题更复杂,侧重自然语言描述转化为代码。
- Few-shot学习:
- 在MBPP上,使用提示的最大模型(137B参数)能正确解决59.6%的问题。
- MathQA-Python的Few-shot准确率为33.4%。
- 微调的效果:
- 在MBPP上微调后,性能提高约10个百分点,达到69.6%。
- 在MathQA-Python上,微调后准确率提高到83.8%。
- 模型规模的影响:
- 合成性能与模型规模呈对数线性关系增长。
- 更大的模型对复杂任务具有显著优势。
- 错误分析:
- 错误类型包括语法错误、运行时错误和功能性错误。
- 随着模型规模增大,语法和运行时错误显著减少,但功能性错误仍占大多数。
- 对话增强:
- 在少样本学习中,加入人类反馈(如自然语言提示)能显著提高性能。
- 准确率从无反馈时的30%提升至有反馈时的65%。
- 示例案例:
- 模型生成初始代码,人类通过对话指出错误并提供改进建议。
- 示例表明模型能通过人类提示修正错误,但多轮对话可能导致模型失去上下文。
- 基准数据集:提出MBPP和MathQA-Python,为程序合成研究提供了新的评估标准。
- 模型性能分析:展示了模型规模、提示设计和微调对代码生成性能的显著影响。
- 人机协作探索:表明模型通过人类反馈可以显著改善代码质量。
- 测试覆盖不足:部分测试用例未能覆盖所有边界情况,可能高估性能。
- 复杂任务不足:MBPP任务较为基础,未来可扩展至更复杂的实际编程场景。
- 模型局限:模型对多步推理任务仍存在挑战,需进一步提升逻辑推理能力。
文章提出了一个名为MultiPL-E的框架,专注于多编程语言代码生成模型的评估,探索了如何将现有的Python代码生成基准扩展到其他18种编程语言,从而创建了首个大规模并行多语言代码生成基准。
- 现有代码生成研究主要集中在单一编程语言(如Python),缺乏对多语言环境中性能的全面了解。
- MultiPL-E框架的目标是研究多语言代码生成模型的能力,并评估模型如何从一种语言的知识中泛化到其他语言。
-
目标:
- 提供一个通用框架,将现有的代码生成基准从Python翻译到多种编程语言。
- 通过翻译单元测试和Python特定术语来实现跨语言的并行代码生成评估。
-
支持的编程语言:
- 包括18种语言,如C++、JavaScript、Rust、TypeScript等,涵盖了多种编程范式和语言特性。
- 语言被分为高频(如Python、Java)、中频(如Go、PHP)和低频(如Lua、Bash)类别。
-
方法:
- 使用一组“轻量编译器”将Python基准翻译为其他语言。
- 通过单元测试来验证代码生成的正确性,确保评估的一致性和可复现性。
-
数据集扩展:
扩展了两个著名的Python基准数据集:
- HumanEval:包含164个测试问题,用于检查函数输出的正确性。
- MBPP(Mostly Basic Programming Problems):以简单编程任务为主,适合初学者。
- 模型表现:
- 测试了Codex、CodeGen和InCoder三种先进的代码生成模型。
- Codex在某些语言(如JavaScript、TypeScript)上的表现超过了Python,表明模型在多语言环境中的潜在能力。
- CodeGen在其微调数据集中包含的语言(如Python、JavaScript)上表现优异。
- InCoder在低频语言上的表现相对较弱。
- 语言频率与模型表现:
- 模型在高频语言上的表现普遍优于低频语言,但Codex在一些低频语言(如Lua)上的表现出人意料地好。
- 语言特性(如静态类型与动态类型)对生成性能的影响较小。
- 错误分析:
- 常见错误包括语法错误、类型错误以及语言特定的语义错误。
- 特定语言(如Racket)中出现模型生成非目标语言代码的情况,可能是训练数据分布的结果。
- 通用框架:
- MultiPL-E通过翻译基准和单元测试,为多语言代码生成模型的研究提供了一个高效、可扩展的框架。
- 新数据集:
- 创建了第一个覆盖19种语言的并行多语言基准,为未来研究提供了重要的测试资源。
- 深度分析:
- 探讨了语言频率、类型注释、提示设计等因素对代码生成模型性能的影响。
- 局限性:
- 生成的基准主要基于Python的任务,不一定能完全反映目标语言的实际使用场景。
- 现有翻译策略无法覆盖所有Python特性,例如复杂类型或动态行为。
- 未来方向:
- 扩展到更多语言和基准(如SQL、C)。
- 研究如何改进模型以减少多语言生成中的语法和语义错误。
MGSM —— (0 shot + COT)
文章提出了一个新的基准——Multilingual Grade School Math (MGSM),专门用于评估多语言数学推理能力
- 大型语言模型(LLMs)在英语任务中的多步推理能力已得到广泛研究,例如通过链式推理(Chain of Thought, CoT)提高模型表现。
- 然而,多语言环境中的复杂推理能力尚未得到充分研究,特别是在需要数学推理的任务上。
研究目标:
- 探索语言模型在不同语言上的推理能力。
- 评估链式推理在多语言环境中的有效性。
- 研究训练数据中语言频率对推理性能的影响。
- 数据来源:
- MGSM扩展自GSM8K数据集(一个英语小学数学题目集),包含250个经过手动翻译的问题。
- 目标语言覆盖10种语言,横跨8个语言家族,包括高频语言(如中文、法语)和低频语言(如泰卢固语、斯瓦希里语)。
- 数据特点:
- 每道题需要2到8步推理。
- 所有问题和答案以阿拉伯数字表示,确保跨语言一致性。
- 数据处理:
- 所有翻译由专业译者完成,并经过质量验证,避免使用机器翻译工具。
- 模型与方法:
- 使用GPT-3和PaLM两种模型进行实验。
- 比较四种不同的推理提示方式:
- DIRECT:直接预测答案,无中间推理步骤。
- NATIVE-COT:在问题语言中提供链式推理。
- EN-COT:使用英语进行链式推理。
- TRANSLATE-EN:将问题翻译为英语后进行链式推理。
- 评价指标:
- 使用问题的正确解答率(accuracy)作为主要指标。
- 对比高频语言与低频语言的表现,分析模型在语言频率上的表现差异。
- 整体表现:
- 在MGSM基准上,PaLM-540B在最佳设置下的平均解答率达到55%,显著高于其他模型。
- 所有模型均在链式推理(COT)下表现优于直接预测(DIRECT)。
- 链式推理的效果:
- EN-COT的表现普遍优于NATIVE-COT,表明在多语言环境下使用英语作为中间推理语言更具优势。
- TRANSLATE-EN达到或超过EN-COT的表现,进一步验证英语推理的有效性。
- 语言频率的影响:
- 低频语言(如斯瓦希里语、孟加拉语)的表现仅比高频语言低3%,显示模型具有一定的跨语言泛化能力。
- 模型规模的影响:
- 更大的模型(如PaLM-540B)在所有语言上表现更好,说明推理能力是语言模型的“涌现能力”。
- XCOPA任务:
- 在因果常识推理任务XCOPA上,PaLM-540B通过EN-COT设置实现了新的SOTA表现(89.9%)。
- XL-WiC任务:
- 在语境中词义判断任务XL-WiC上,PaLM-540B也表现出色,但链式推理未显著提升性能。
- MGSM作为首个多语言数学推理基准,为研究多语言环境下的模型能力提供了重要工具。
- 链式推理(尤其是英语推理)显著提升了模型在多语言任务中的推理表现。
- 模型的推理能力与训练数据中语言频率的相关性较低,表现出跨语言迁移的潜力。
-
工具操作模型的重要性:随着AI的发展,能够调用软件工具的语言模型(如API函数调用)成为了重要的研究方向。
-
现有问题
:
- 很多开源工具操作模型(如Gorilla、ToolLLAMA)依赖于专有模型(如GPT-4)的数据蒸馏,但由于法律限制,其商业适用性受到限制。
- 专有模型(如GPT-4 API)虽性能优越,但成本高、延迟大,不适合实时商业应用。
目标:
- 开发一个小型、开源、商用许可的模型,能在工具操作任务中与GPT-4媲美甚至超越。
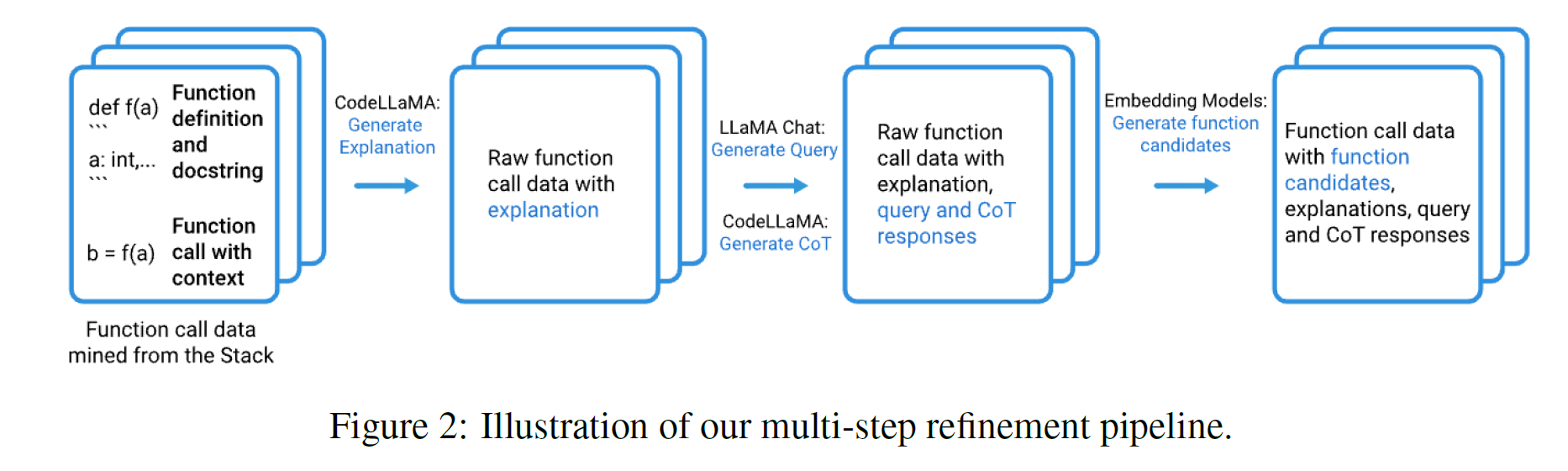
- 训练数据的多步精炼(Multi-Step Refinement):
- 数据来源:从开源数据集(如The Stack)挖掘函数调用代码及其上下文,生成自然语言查询、函数解释和调用代码。
- 精炼流程:
- 函数挖掘:提取函数定义、文档字符串和上下文代码。
- 查询生成:生成自然语言描述,让模型更好理解调用目的。
- 链式推理(Chain of Thought, CoT)增强:生成推理过程,优化查询与函数的匹配。
- 难例生成:通过嵌入模型生成具有干扰性的候选函数列表,提升模型在复杂场景中的泛化能力。
- 示例检索增强(Demonstration Retrieval Augmentation):
- 从历史查询-响应对中检索最相关的示例,提升模型的函数调用准确率。
- 成效:在网络安全领域的函数调用任务中,成功率从72%提升至94%。
- 性能优势:
- 零样本能力:在未见过的函数上实现与GPT-3.5相当的准确率。
- 检索增强能力:在复杂函数调用任务中超过GPT-4,尤其是网络安全领域。
- 零样本评估:
- NexusRaven-13B在网络安全领域的函数调用准确率比GPT-3.5高出4%,并显著超越所有开源模型。
- 在通用领域,NexusRaven-13B比CodeLLAMA-13B-instruct高16%。
- 检索增强评估:
- 使用检索增强后,NexusRaven-13B在网络安全工具(如VirusTotal、CVE搜索)的成功率超越GPT-4,提升了30%。
- 效率与延迟:
- 相比于GPT-4的多步推理策略,NexusRaven-13B能以低延迟实现高质量的函数调用,适合实时应用。
- 商用许可:解决了依赖专有数据带来的法律和成本问题,为企业提供了安全的开源解决方案。
- 多领域应用:涵盖网络安全、软件操作等多个场景,适应性强。
- 灵活扩展:通过检索增强和动态数据更新,支持定制化和持续优化。
- 多轮交互:目前仅支持单轮查询与响应,未来将扩展至复杂多轮交互。
- 标准化评估框架:需要统一的工具描述格式和评估基准,文章计划开放源码以推动社区合作。
文章提出了一个名为API-Bank的基准测试框架,用于评估大型语言模型(LLMs)在工具增强场景下的能力。研究目标是通过引入一个具有高多样性和真实性的评估系统,全面测试和提高模型在调用API工具上的性能。
- 动机:尽管大型语言模型在开放域任务中表现优越,但其在工具操作(如调用API、检索信息、处理复杂查询)中的表现仍有待提高。
- 目标:
- 测试现有LLMs在工具调用中的有效性。
- 提供高质量的训练数据,改进模型的工具使用能力。
- 确定模型在工具增强任务中需要克服的关键挑战。
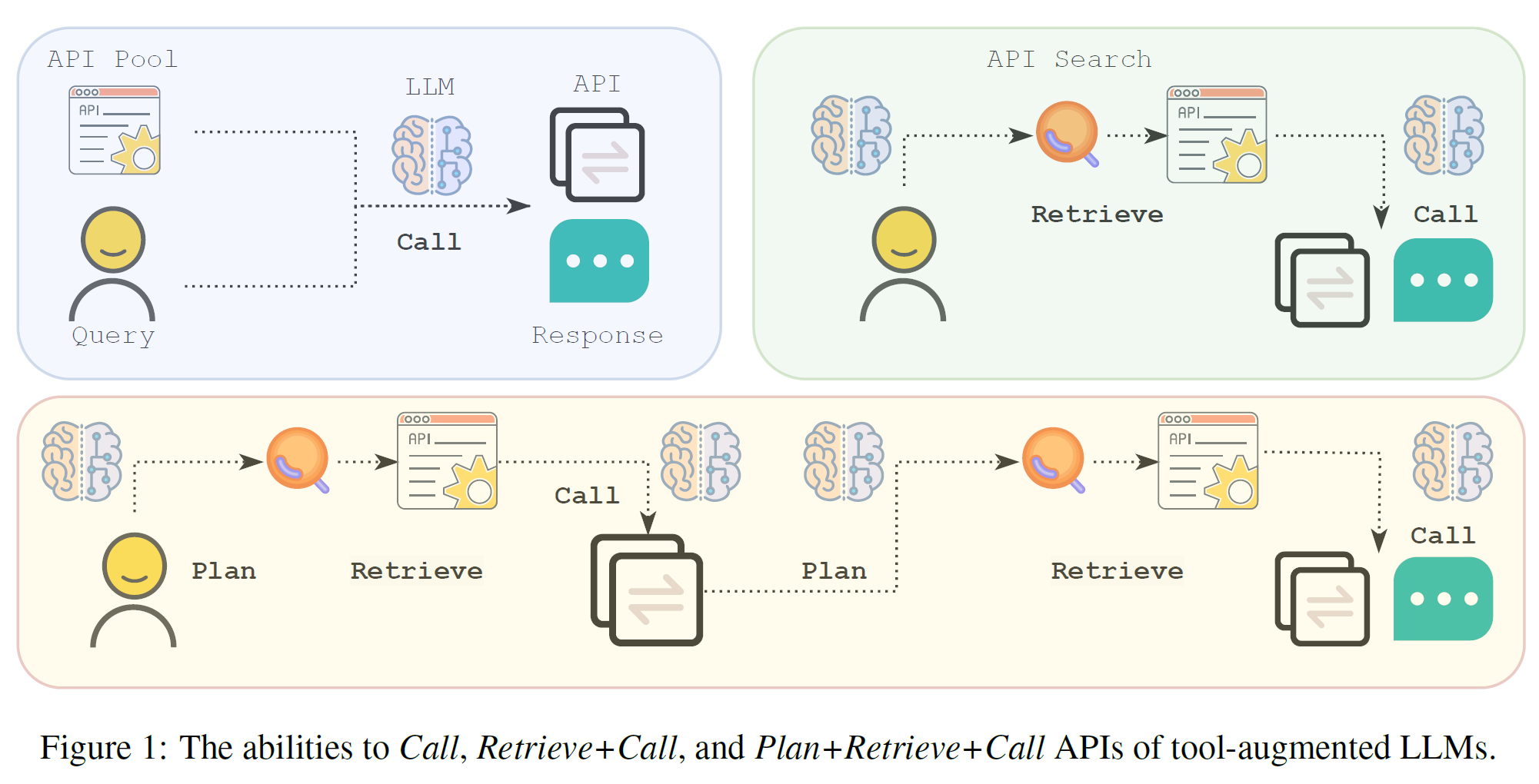
-
功能和能力评估:
-
API-Bank关注三大能力:
- 调用(Call):在已知API池中调用API完成任务。
- 检索+调用(Retrieve+Call):在未知API池中先检索合适的API再调用。
- 计划+检索+调用(Plan+Retrieve+Call):复杂场景下的多步API调用。
-
每种能力对应不同的使用场景,例如单一API调用、多步骤任务或复杂计划。
-
-
数据构建原则:
- 领域多样性:覆盖从健康管理到金融服务的1008个领域。
- API真实性和多样性:模拟真实API的名称、参数和功能。
- 评估真实性:通过实时执行API调用,确保评估结果的准确性。
-
评估系统:
- 系统内包含73个真实实现的API,用于测试模型在多个领域和任务中的能力。
- 提供了314条带注释的工具使用对话,包含753次API调用。
为了解决人工注释成本高的问题,作者提出了一个多代理数据生成方法:
-
五个协作代理:
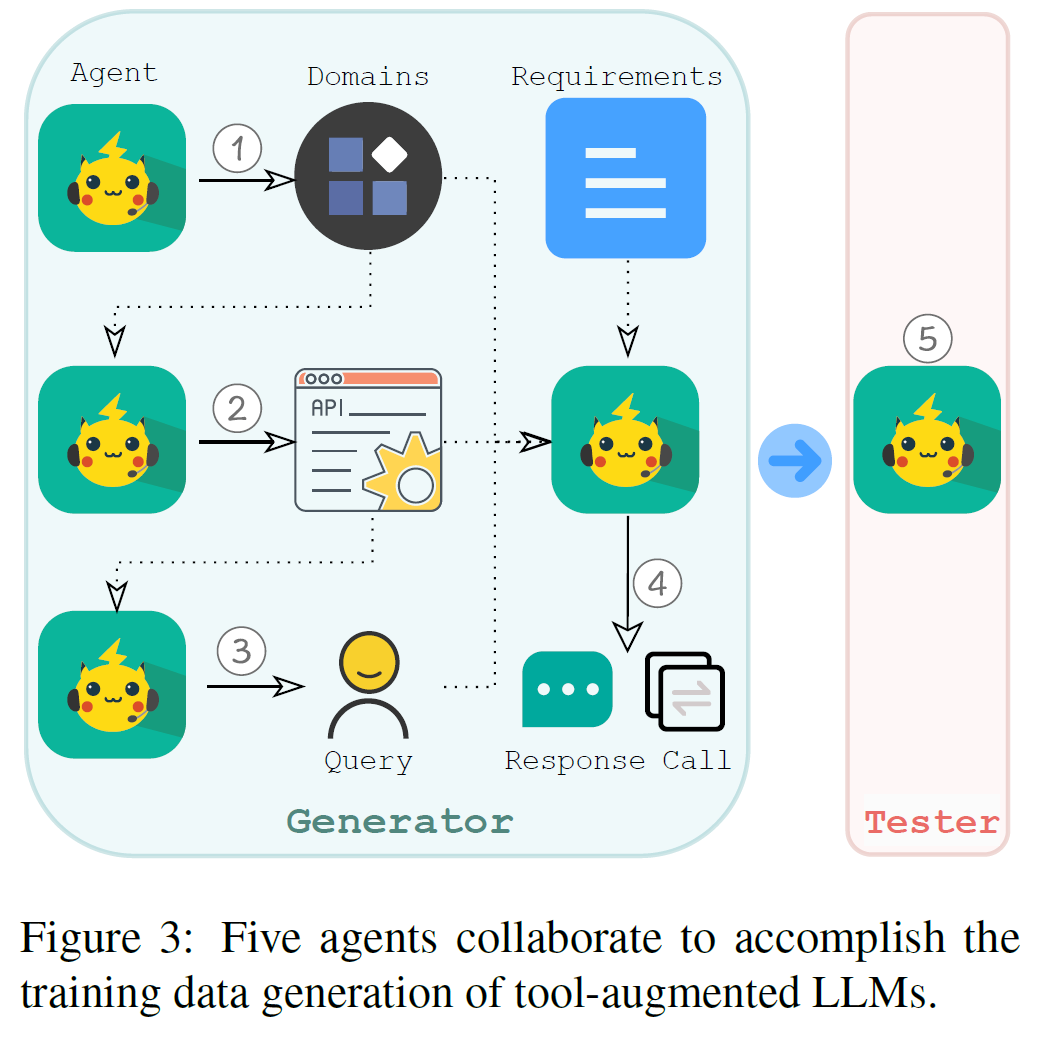
- 域生成代理:创建领域(如健康管理、智能家居)。
- API生成代理:生成符合领域的API定义。
- 查询生成代理:基于API生成自然语言查询。
- 响应生成代理:模拟API调用并生成响应。
- 测试代理:验证生成的数据是否符合设计原则。
-
效率与质量:
- 生成一条对话的成本仅为$0.1,较人工注释节约98%的成本。
- 数据集质量通过四名注释员评估,显示94%的生成数据符合标准。
- 模型表现:
- GPT-4在复杂任务(Plan+Retrieve+Call)中表现最优,但仍有改进空间。
- GPT-3.5表现显著优于ChatGLM和Alpaca等开源模型。
- API-Bank微调后的Lynx模型在API调用正确性上比Alpaca提升了26个百分点,接近GPT-3.5。
- 错误分析:
- 常见错误包括API调用格式错误、参数无效和API检索失败。
- Lynx的主要问题是API幻觉(调用不存在的API),占总错误的61%。
- 数据集对比:
- API-Bank在领域覆盖、多轮对话和能力测试上显著优于现有基准(如ToolBench、ToolQA)。
- API-Bank通过真实和多样的基准测试,为工具增强的语言模型研究提供了关键资源。
- 通过高质量训练数据和多代理生成方法,显著提升了模型在工具使用任务中的能力。
- 未来研究方向包括更复杂的多语言扩展、更严格的API调用标准以及更大规模的数据生成。
- API调用的复杂性:随着应用编程接口(API)数量的增加,现有语言模型在生成准确API调用上的能力有限,特别是在复杂的函数参数和不断变化的文档环境下。
- 现存问题:
- 语言模型容易出现“幻觉”(hallucination),即生成不存在或错误的API调用。
- 无法有效适应API文档的频繁更新。
研究目标:
- 提出一个系统性方法,训练模型准确调用大规模的API。
- 设计机制降低模型在API调用中的幻觉错误。
- 提供框架支持动态变化的API文档。
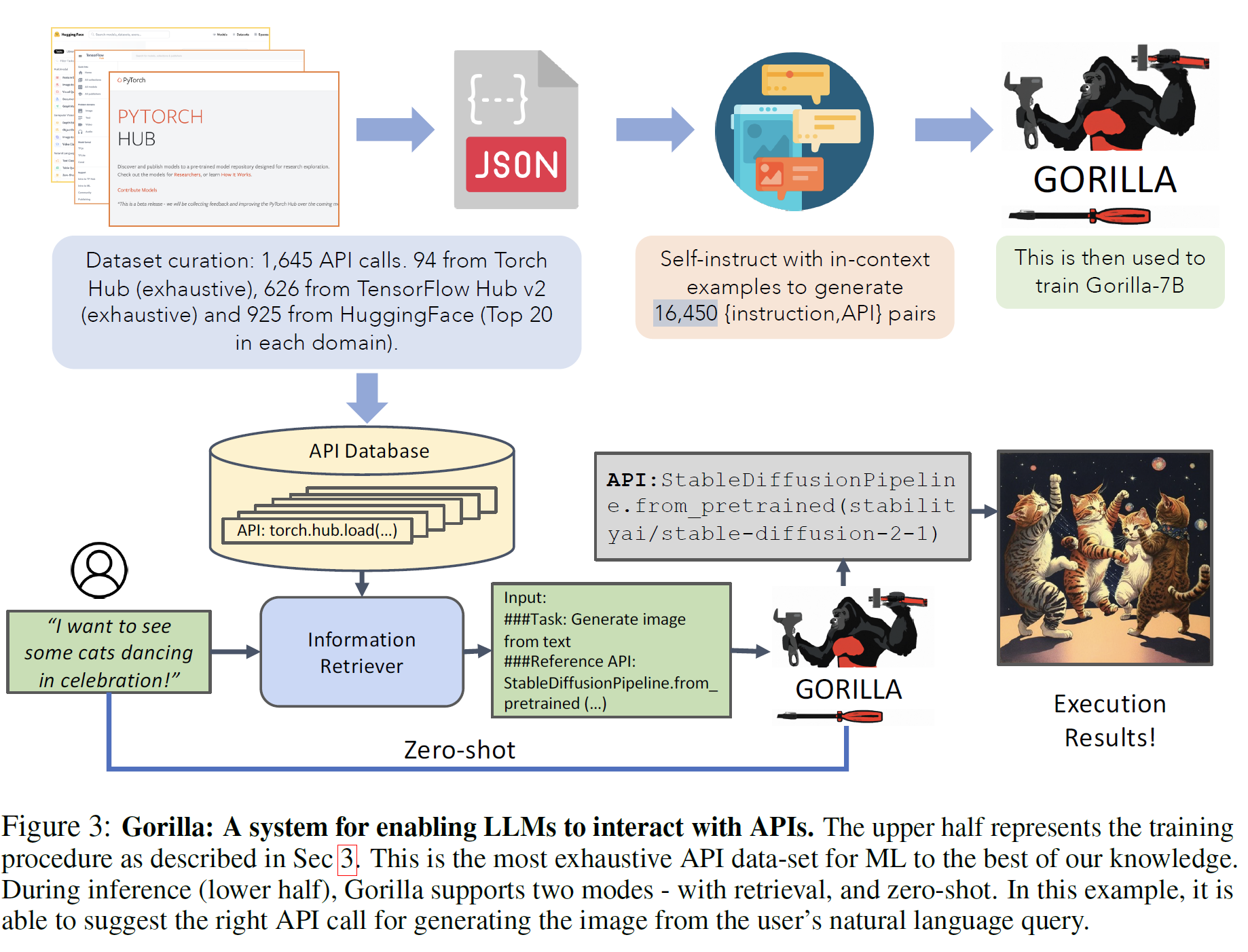
- 数据集与基准测试:APIBench
- 数据集来源:从TorchHub、TensorHub和HuggingFace三大模型库中收集了1,645个API,涵盖94个TorchHub、626个TensorHub和925个HuggingFace的API。
- 数据特点:
- 每个API配备10条基于Self-Instruct的自然语言查询。
- 包含API的功能描述、参数、示例代码和性能信息。
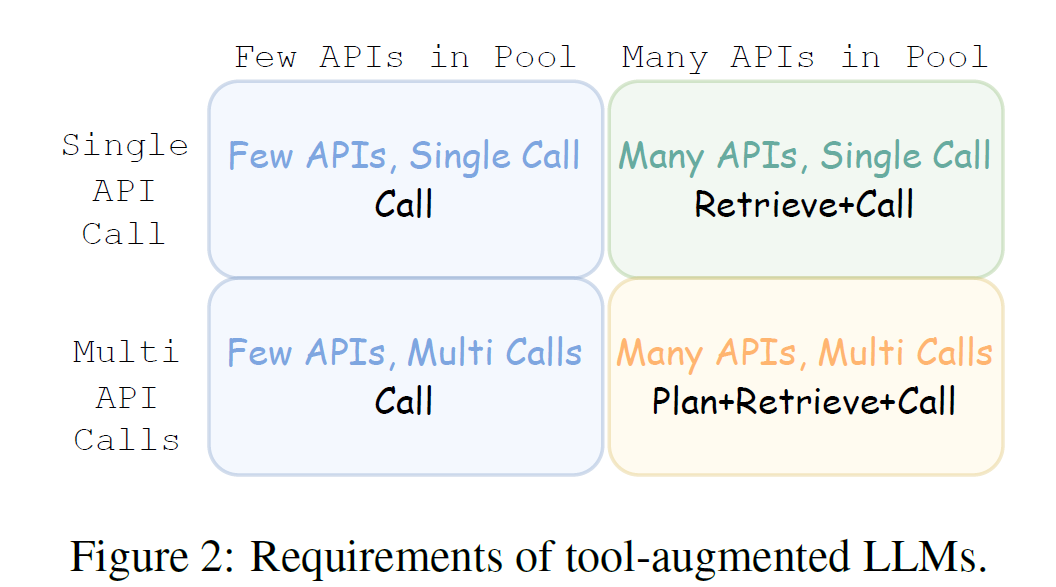
- 基准测试关注三个能力:
- 直接调用(Call)。
- 检索+调用(Retrieve+Call)。
- 计划+检索+调用(Plan+Retrieve+Call)。
- 模型架构
- 检索增强:在推理过程中,通过检索相关API文档作为参考,帮助模型生成准确的调用代码。
- AST子树匹配:通过抽象语法树匹配验证API调用的功能正确性,捕获幻觉或调用错误。
- 训练过程
- 采用LLaMA-7B模型为基础,结合指令微调(Instruction Fine-Tuning)和检索增强技术。
- 自指生成了16,450对“指令-API调用”训练样本。
- 在训练中引入真实文档,帮助模型学习解析复杂参数和约束。
- 模型表现:
- 在TorchHub、TensorHub和HuggingFace三个数据集上,Gorilla在零样本(zero-shot)条件下的准确率超越GPT-4和GPT-3.5。
- 特别是在TorchHub上,Gorilla的AST准确率达到59.13%,比GPT-4高20%以上。
- 检索的作用:
- 使用检索增强后,Gorilla的性能在所有数据集上进一步提高。
- 在TorchHub数据集上,带有检索的Gorilla准确率达67.2%,幻觉错误降至0%。
- API文档动态变化的适应性:
- Gorilla能处理API文档的实时更新,例如从旧版ResNet-50模型升级到ResNet-101。
- 在测试中,模型正确适应了文档变化,保持高准确率。
- 约束条件处理:
- Gorilla在满足用户约束(如参数规模或模型性能)时表现出色。
- 在ImageNet准确率约束的实验中,Gorilla选择正确API的比例超过其他模型。
- 创新的训练框架:
- 提出了结合检索和自指生成的训练策略,显著提升了API调用的准确性。
- 新基准测试:
- APIBench作为首个涵盖多领域、多平台API的评估框架,为API调用研究提供了标准化工具。
- 动态适应性:
- Gorilla能够跟随API文档的变化调整输出,解决了传统模型依赖静态训练数据的局限。
- 领域局限性:
- 当前数据集以机器学习API为主,其他领域的API支持需要进一步扩展。
- 检索依赖性:
- 检索器的质量直接影响模型性能,需要开发更高效的检索方法。
- 动机:
- 工具增强的语言模型(如API调用、函数生成)对实际应用的影响正在增长,但现有基准未能充分覆盖这些能力。
- BFCL旨在创建一个统一平台,评估模型在函数调用、API使用和多语言环境中的能力。
- 目标:
- 通过多种语言和场景测试LLMs的函数调用能力。
- 测试模型在处理复杂任务(如多步骤调用和并行调用)中的表现。
- 研究函数相关性检测能力,分析模型如何在没有相关函数时处理用户请求。
- 问题数量与领域:
- 数据集包括2,000对问题-函数-答案组合,涵盖Python、Java、JavaScript、REST API和SQL等语言。
- 涉及多个领域(如数学、金融、体育、云计算、法律等),确保任务多样性。
- 任务类型:
- 简单函数调用:单一函数调用。
- 多函数选择:从多个候选函数中选择最优函数。
- 并行函数调用:一次调用多个函数处理任务。
- 多步骤并行调用:结合并行调用和多函数选择的复杂场景。
- 函数相关性检测:
- 测试模型能否识别用户问题中无关的函数定义,并避免生成幻觉式调用。
- API调用评估:
- 包括常见的REST API调用,测试模型生成可执行API调用(如
requests.get())的能力。
- 包括常见的REST API调用,测试模型生成可执行API调用(如
- 模型表现:
- GPT-4 在复杂任务(如并行多函数调用)中表现最佳,其准确率在大多数场景下显著高于其他模型。
- 开源模型(如OpenFunctions-v2)在简单任务中接近专有模型的性能,但在复杂任务中仍有差距。
- 语言与场景影响:
- 高频语言(如Python)上,模型的表现普遍优于低频语言(如Java)。
- 在简单函数调用中,开源和专有模型表现接近,但多步骤并行调用对模型提出了更高要求。
- 函数相关性检测:
- Gorilla模型在相关性检测任务中表现优越,能够有效避免无关函数的调用。
- 常见错误:
- 幻觉错误:生成不存在或无效的函数调用。
- 参数错误:未正确解析复杂参数或缺少必需参数。
- REST API遗漏URL:部分模型在生成API调用时缺失必要的URL信息。
- 多语言支持:
- BFCL覆盖Python、Java、JavaScript等多种编程语言,测试模型在跨语言环境中的适应能力。
- 多场景任务:
- 涉及从简单到复杂的函数调用任务,真实反映实际应用中的挑战。
- 动态更新:
- 包括最新的API文档,模拟实时环境中的函数变化。
- 局限性:
- 当前评估集中在函数调用任务,未涉及更广泛的工具增强场景(如图像处理、数据分析)。
- 低频语言和小众领域的覆盖仍有限。
- 未来方向:
- 扩展到更多编程语言和工具类型。
- 引入更复杂的任务(如交互式多轮函数调用)。
- 优化评估方法,减少API调用中的误差。
- 长文本理解的挑战: 当前的大型语言模型(LLMs)在短文本任务上表现良好,但对于需要处理长文本(如科学文献、小说等)的复杂推理任务,其能力尚未充分验证。
- 目标: 创建一个以长文本推理为核心的**零样本(Zero-Shot)**基准测试,测试模型在没有任务特定训练数据的情况下处理长文本的能力。
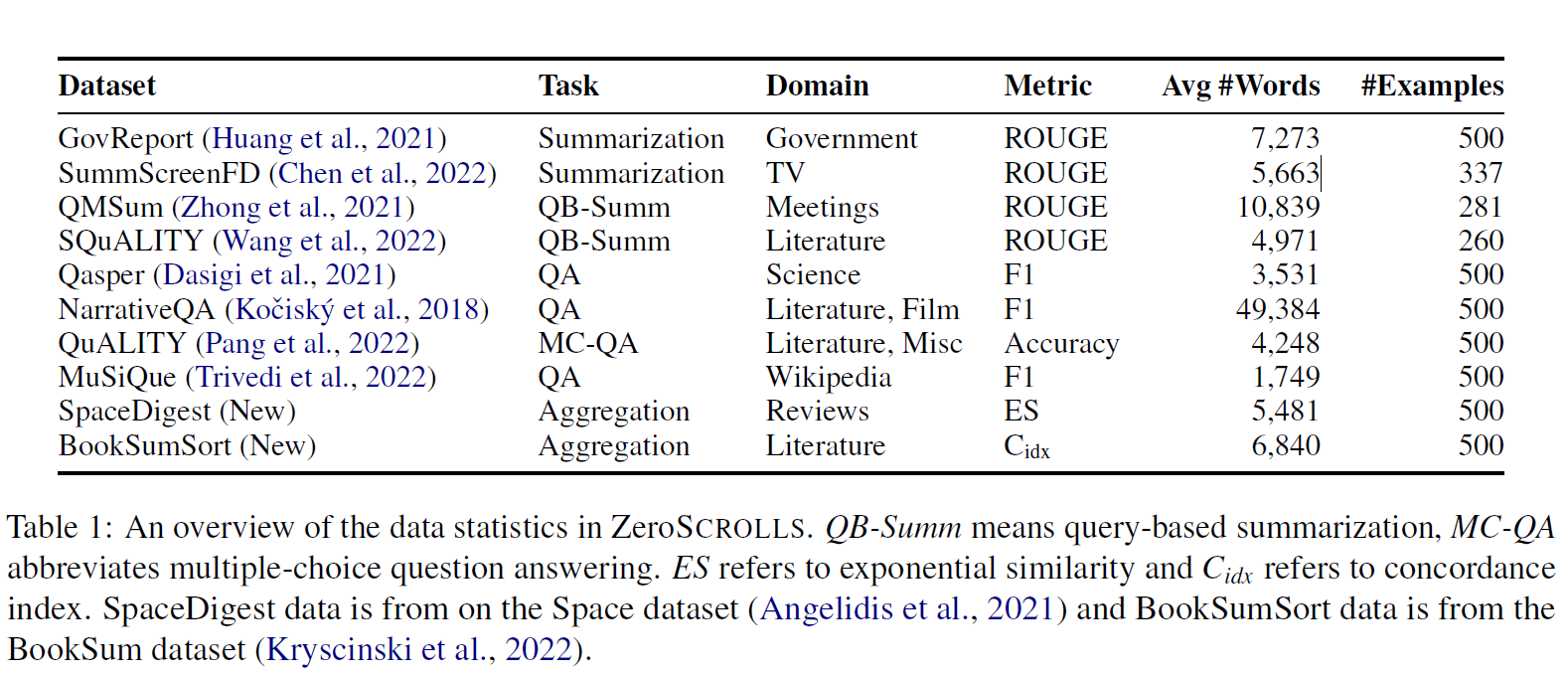
- 核心设计:
- 数据集由10个任务组成,其中包括从SCROLLS基准改编的6个任务,以及新增的4个任务。
- 测试任务涵盖长文本摘要、多跳问题回答、情感聚合和章节排序等。
- 新任务:
- SpaceDigest:
- 聚合任务,给出酒店评论,计算正面评论的比例。
- 测试模型在情感分析、计数和聚合任务中的表现。
- BookSumSort:
- 排序任务,给出打乱顺序的小说章节摘要,要求恢复原始顺序。
- 测试模型对全局文本顺序的理解。
- SpaceDigest:
- 零样本测试:
- 每个任务仅提供测试集和小型验证集,无训练数据。
- 测试设置注重模型的推理和任务适配能力,而非任务特定的优化。
- 自动化评估:
- 使用指标如ROUGE、F1、准确率、指数相似度(Exponential Similarity)和一致性指数(Concordance Index)评价模型表现。
- 主要结果:
- GPT-4在所有任务上的平均分最高(41.7),紧随其后的是Claude(39.1)。
- 开源模型(如Flan-UL2)在部分任务(如多跳问题回答)中表现优异,但总体上落后于专有模型。
- 任务表现细节:
- 摘要任务:GPT-4在摘要任务上得分最高,但与专门微调的CoLT5模型相比仍有差距。
- 问题回答:GPT-4在多选问题任务(如QuALITY)接近人类表现,但在NarrativeQA中因格式偏差而得分低于Claude。
- 聚合任务:所有模型在SpaceDigest和BookSumSort任务中表现不佳,仅GPT-4略高于基准值。
- 模型规模和输入长度的影响:
- 规模:更大的模型在几乎所有任务中表现更好。
- 输入长度:更长的上下文窗口(如8k tokens)显著提高了Claude和Flan-T5的表现。
- 多任务测试:
- ZeroSCROLLS覆盖长文本摘要、问答和聚合任务,全面测试模型的长文本处理能力。
- 零样本设定:
- 通过无训练数据的设计,真实评估模型的通用推理能力。
- 开放性:
- 提供实时更新的排行榜和公开代码,推动社区研究。
- 局限性:
- 模型输出格式偏差可能导致评分偏低,影响对实际能力的评估。
- 指标(如ROUGE、F1)难以捕捉语义等价的答案,可能低估模型性能。
- 未来方向:
- 扩展到更复杂的任务,如多轮推理和多模态输入。
- 提高对长文本上下文中语义关系的理解能力。
示例数据

测试长上下文 LLM 的能力
Needle-in-a-Haystack Benchmark 是一个专门设计的基准测试,旨在评估**长上下文(Long Context)**模型在处理极大文本上下文时的能力。它通过将一个特定信息(称为“针”)嵌入到长文档中(称为“草堆”),测试模型是否能准确检索出该信息。此测试能够帮助评估长上下文模型(如GPT-4 128K、Claude 2.1)在实际应用场景中的性能。
- 创建草堆上下文:
- 将一段随机的事实或声明(“针”)插入到一个长文档中(“草堆”)。
- 文档长度和针的位置会随机变化,以模拟不同的上下文复杂度。
- 测试任务:
- 提问模型一个问题,要求其检索插入的特定声明(针)。
- 通过调整上下文长度和针在文档中的深度(depth),评估模型的检索能力。
- 变量控制:
- 文档深度:针在文档中的位置,按百分比表示(如 50% 表示针在文档的中间位置)。
- 上下文长度:文档的总长度(以 token 计)。
支持的模型提供商包括:
- OpenAI(如 GPT-4, GPT-3.5)
- Anthropic(如 Claude 2.1)
- Cohere(如 command-r)
needle:插入上下文中的随机声明。context_lengths:文档总长度(如 2000 或 8000 tokens)。document_depth_percents:针插入文档中的深度百分比(如 50%)。model_name:使用的语言模型名称(如 GPT-4, Claude 2.1)。multi_needle:是否插入多个针。
-
测试 OpenAI 的 GPT-3.5 模型,针在文档中间位置(50%),文档长度为 2000 tokens:
needlehaystack.run_test --provider openai --model_name "gpt-3.5-turbo-0125" --document_depth_percents "[50]" --context_lengths "[2000]"
-
测试 Anthropic 的 Claude 2.1 模型,使用相同参数:
needlehaystack.run_test --provider anthropic --model_name "claude-2.1" --document_depth_percents "[50]" --context_lengths "[2000]"
-
使用多针模式,测试模型从多个“针”中检索信息:
needlehaystack.run_test --multi_needle True --needles '["Statement 1", "Statement 2", "Statement 3"]' --context_lengths "[2000]" --document_depth_percents "[50]"
- 准确率(Accuracy):
- 模型是否正确检索出了插入的声明。
- 上下文长度对性能的影响:
- 测试不同上下文长度下的表现。
- 文档深度对检索的影响:
- 模型是否能够正确检索文档深处的信息。
- 多针评估:
- 在多个声明存在的情况下,模型是否能够分别检索每个针。
- 长文档搜索:
- 测试模型在长文档中查找特定信息的能力。
- 高上下文场景:
- 例如法律文件分析、大型科研报告的查询等。
- 模型能力比较:
- 针对不同模型(如 OpenAI、Anthropic、Cohere)进行跨平台对比。
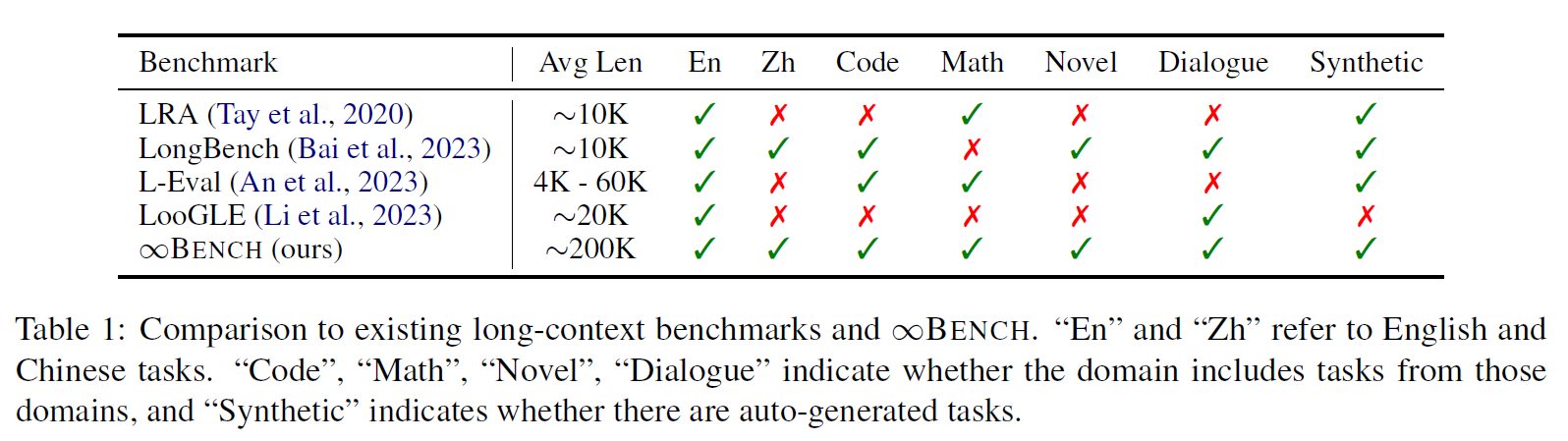
- 长上下文处理的重要性: 随着语言模型(LLMs)的广泛应用,处理长文本上下文(如科学文献、代码库或小说)的能力变得至关重要。然而,现有大多数模型的训练上下文长度限制在8K tokens 左右,限制了它们在更复杂场景中的使用。
- 现有基准测试的不足: 当前的长上下文评估基准(如LongBench、L-Eval)主要聚焦于10K以下的文本任务,无法全面评估100K+ 长文本场景下模型的能力。
- 研究目标: 提出∞BENCH,第一个专门设计用于测试超过100K tokens 上下文处理能力的基准测试,涵盖多领域、多任务,并包括中英双语。
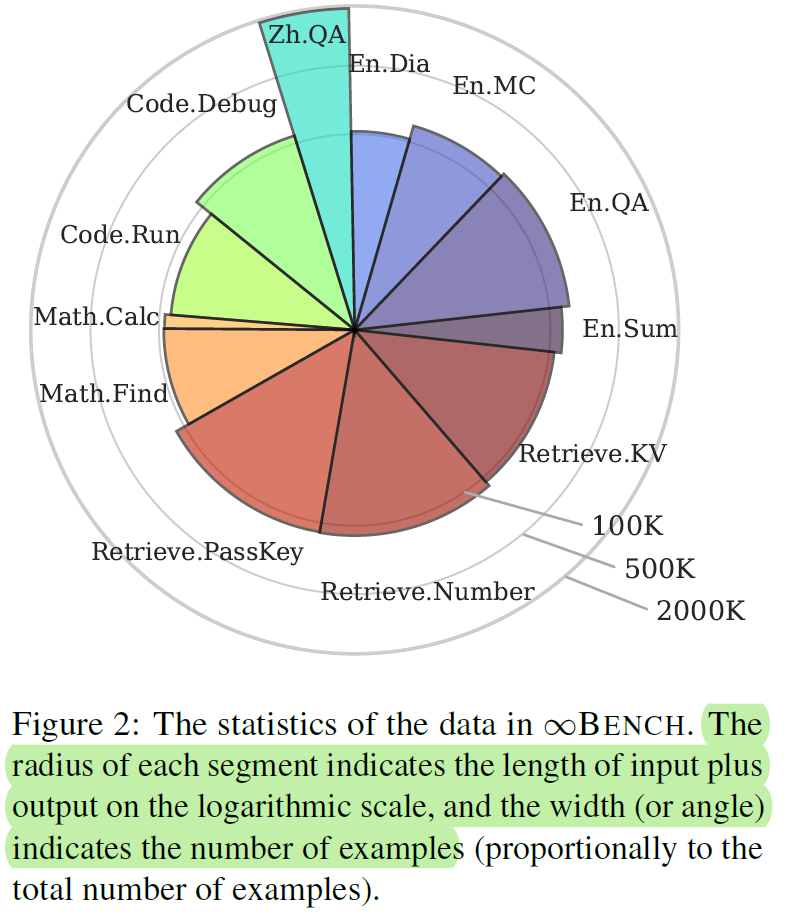
- 覆盖任务与领域:
- 任务种类:
- 现实场景任务:基于真实文本的任务,如小说摘要、代码调试和对话推理。
- 合成场景任务:生成的任务,用于测试模型特定能力,如检索与数学运算。
- 覆盖领域:
- 检索(Retrieve)
- 代码分析与运行(Code.Debug 和 Code.Run)
- 数学推理(Math.Calc 和 Math.Find)
- 小说处理(如 En.Sum, En.QA)
- 多角色对话(En.Dia)
- 任务种类:
- 上下文长度与语言支持:
- 数据集平均长度超过200K tokens,最大长度达2000K。
- 提供英语与中文任务,涵盖中英文问答和摘要。
- 数据生成与标注:
- 人工标注任务:例如小说摘要和开放问答。
- 自动生成任务:如键值对检索和数字定位任务,能快速扩展数据规模。
- 每个任务都经过多轮质量检查,确保标注准确性。
- 小说任务(Novel):
- 包括摘要(En.Sum)、开放问答(En.QA 和 Zh.QA)和多选题(En.MC)。
- 通过实体替换技术(如更改主角名字)创建“伪小说”,避免模型因见过相关文本而作弊。
- 代码调试(Code.Debug):
- 在代码库中插入明显的语法错误,要求模型识别出错误的函数。
- 难度很高,当前模型仅能识别简单错误。
- 对话任务(Dialogue):
- 基于电影和剧本,要求模型通过上下文推断对话中被屏蔽的角色名字。
合成场景任务
- 检索任务(Retrieve):
- Retrieve.PassKey:检索嵌入冗长文本中的5位数字密钥。
- Retrieve.Number:更复杂的数字检索,密钥扩展为10位重复数字。
- Retrieve.KV:从JSON对象中检索指定键值对。
- 数学任务(Math):
- Math.Find:从长列表中查找最大值、最小值或中位数。
- Math.Calc:要求模型逐步计算复杂的数学表达式的中间结果。
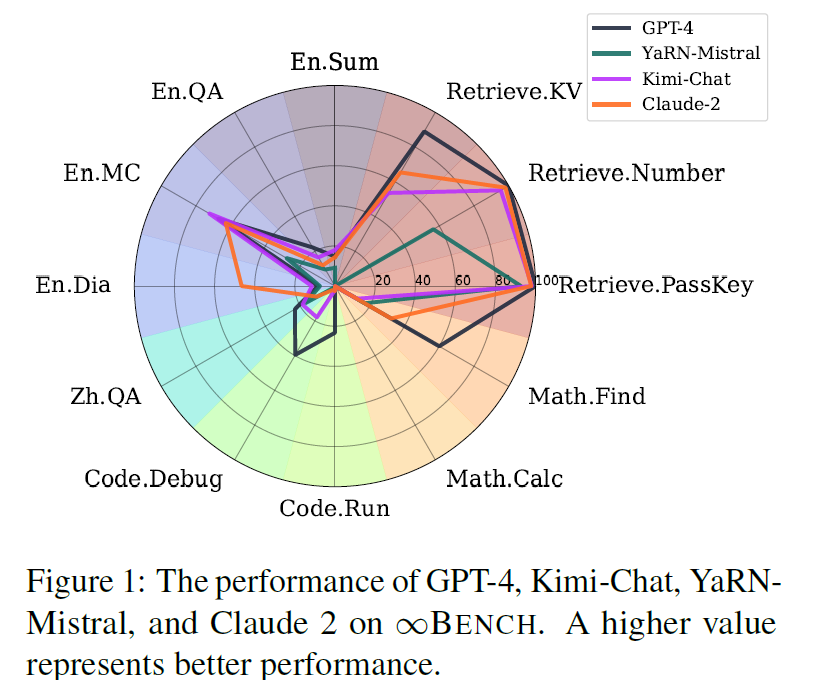
- 参与模型:
- 专有模型:GPT-4(OpenAI),Claude 2(Anthropic),Kimi-Chat。
- 开源模型:YaRN-Mistral。
- 主要结果:
- GPT-4 在整体任务中表现最佳,尤其是在检索、代码和数学领域。
- 所有模型在现实场景任务(如 En.Sum, En.QA)中表现均不理想,表明长上下文推理仍是挑战。
- 在合成任务中,检索类任务表现最好,而计算类任务(如 Math.Calc)结果最差。
- 有趣现象:
- “中间迷失”现象的缺失:与以往研究不同,本实验未发现模型在上下文中间位置的表现显著下降。
- “上下文回忆”技术的效果:通过要求模型显式回忆上下文信息,可以显著提升准确率。例如,GPT-4 在 Code.Debug 中的准确率从15.74%提高到39.59%。
- 全新基准测试:
- ∞BENCH 是第一个覆盖超过100K tokens 长度的基准,填补了长上下文评估领域的空白。
- 任务多样性:
- 提供现实与合成任务,涵盖不同领域,全面评估模型能力。
- 开放数据与工具:
- 数据集与代码完全开放,支持社区研究与改进。
- 局限性:
- 虽然数据集涵盖多个领域,但仍需扩展到更多应用场景,如跨文档推理。
- 当前方法在评估复杂推理任务时,可能低估了模型实际能力。
- 未来方向:
- 探索处理百万 tokens 级别上下文的模型。
- 提升模型在长上下文下的高效性和推理能力
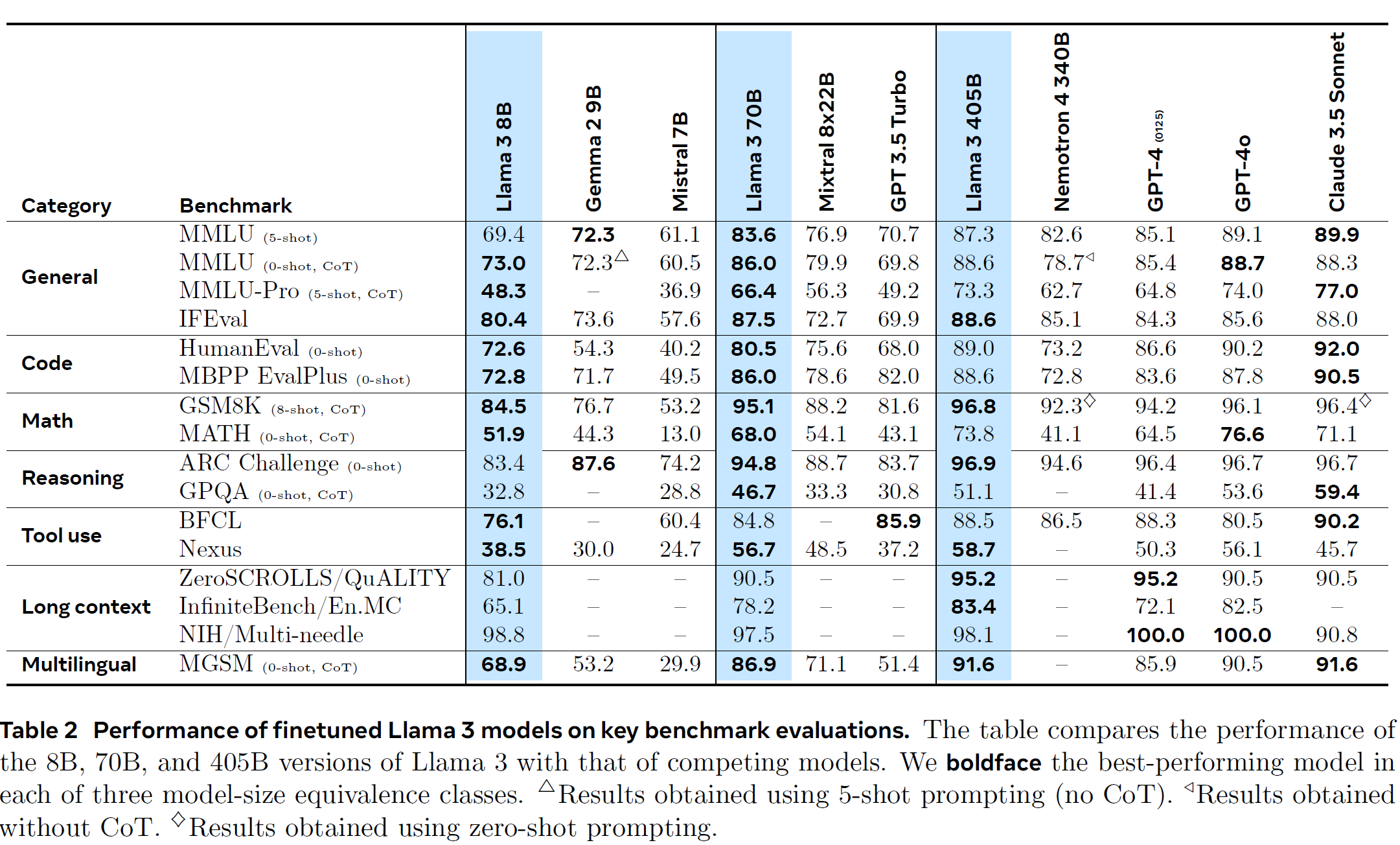
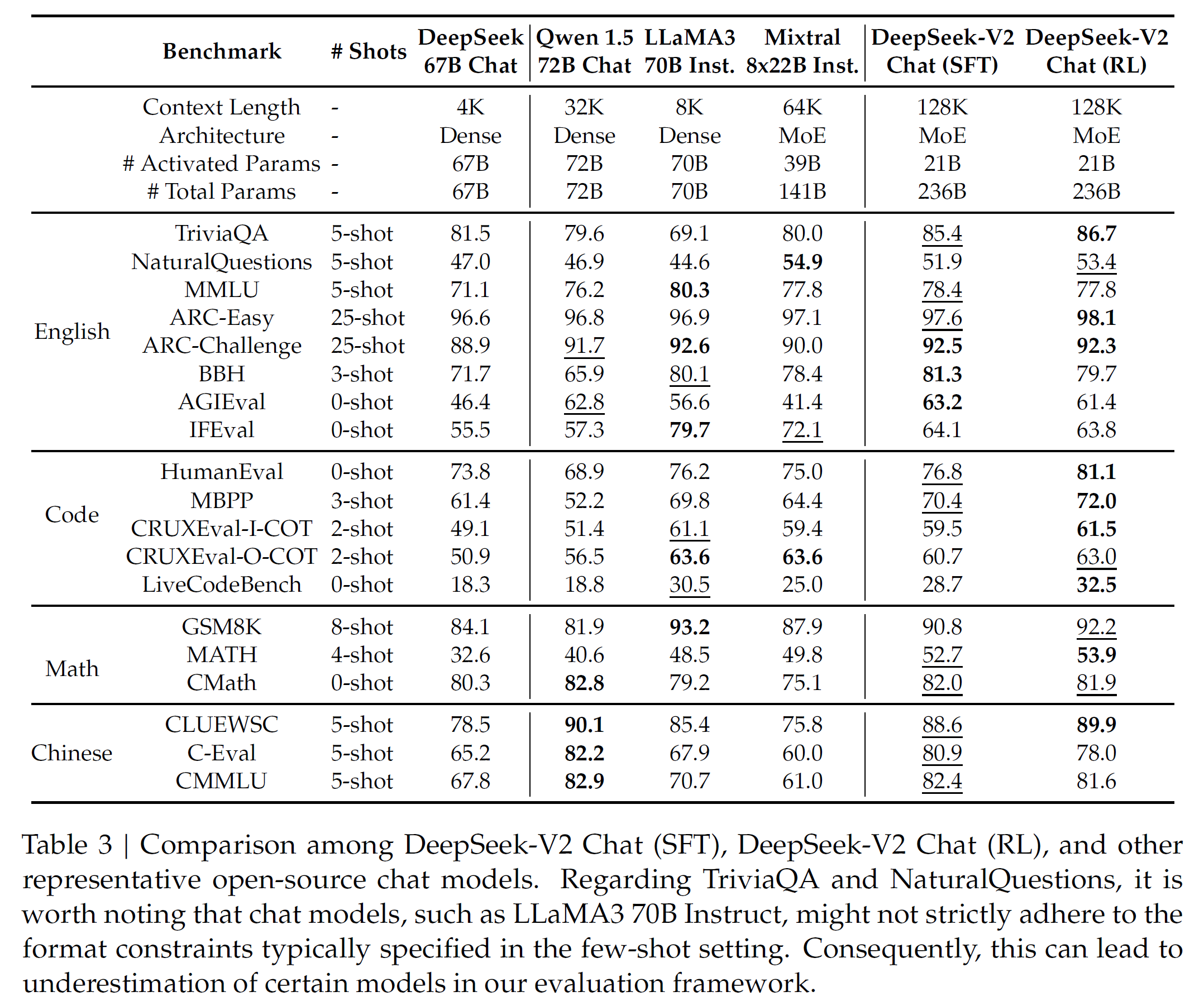
通用任务:MMLU (5-shot)、MMLU-Pro (5-shot)、MMLU-redux (5-shot)、BBH (3-shot)、ARC-C (25-shot)、TruthfulQA (0-shot)、Winogrande (5-shot)、HellaSwag (10-shot)
数学与科学任务:GPQA (5-shot)、Theorem QA (5-shot)、GSM8K (4-shot)、MATH (4-shot)
代码任务:HumanEval (0-shot)、HumanEval+ (0-shot)、MBPP (0-shot)、MBPP+ (0-shot)、MultiPL-E (0-shot) (Python、C++、JAVA、PHP、TypeScript、C#、Bash、JavaScript)
多语言任务:Multi-Exam (M3Exam 5-shot、IndoMMLU 3-shot、ruMMLU 5-shot、mMMLU 5-shot)、Multi-Understanding (BELEBELE 5-shot、XCOPA 5-shot、XWinograd 5-shot、XStoryCloze 0-shot、PAWS-X 5-shot)、Multi-Mathematics (MGSM 8-shot)、Multi-Translation (Flores-101 5-shot)
见前文
- MMLU简介:
- MMLU(Massive Multitask Language Understanding)是一个广泛应用的基准,用于评估大型语言模型(LLMs)在不同学科(如数学、历史、计算机科学、逻辑和法律)上的表现。
- MMLU的目标是衡量模型的知识广度和推理深度。
- 动机:
- MMLU虽然流行,但其数据集存在显著的错误,包括答案标注错误、问题表达不清和选项混乱等。这些问题可能导致对模型性能的误判。
- 本研究旨在系统评估MMLU的质量并引入经过改进的MMLU-Redux数据集。
- MMLU问题的识别与分类:
- 作者开发了一个分层错误分类体系,将错误分为两大类:
- 问题评估错误(Question Assessment Errors):
- 问题表达不清、选项混淆。
- 答案评估错误(Ground Truth Verification Errors):
- 无正确答案、多正确答案或标注答案错误。
- 问题评估错误(Question Assessment Errors):
- 作者开发了一个分层错误分类体系,将错误分为两大类:
- MMLU-Redux数据集:
- 重新标注了MMLU的3,000个问题,覆盖30个学科。
- 确保每个问题被专家手动检查,标记错误类型并校正答案。
- LLM性能的重新评估:
- 使用MMLU-Redux重新评估多个主流模型(如GPT-4、Claude-3等),发现排名和性能指标发生显著变化。
- 数据集错误的广泛性:
- 在MMLU-Redux中,约57%的Virology问题存在错误,Logical Fallacies和College Chemistry也有显著比例的问题。
- 错误包括:
- 错标答案:例如,正确答案应该是B,但标注为C。
- 多答案或无答案:例如选项中有多个正确答案或根本没有正确答案。
- 问题表述不清:例如问题缺乏背景信息。
- 对模型性能的影响:
- 数据集错误导致的模型排名变化显著。例如:
- Claude-3在Business Ethics上的排名从第1降到第2。
- Palmyra X在Virology上的排名从第4升到第1。
- 数据集错误导致的模型排名变化显著。例如:
- 记忆效应:
- 某些模型在含有错误的实例中仍表现良好,表明这些错误可能出现在模型的预训练数据中。
- 实验方法:
- 使用4种主流模型(如GPT-4 Turbo、Claude-3 Opus)和多种提示技术(如零样本、少样本、Chain-of-Thought)进行错误检测。
- 还引入了检索增强生成(RAG)方法,从Wikipedia或MS-MARCO中检索相关背景信息。
- 主要结果:
- **Few-Shot Chain-of-Thought(少样本+推理链)**在错误检测中表现最佳。
- Claude-3 Opus结合RAG方法达到了最高的F2分数(41.92),但整体性能仍有改进空间。
- MMLU-Redux的意义:
- 提供了一个更准确的基准,用于改善对LLMs的评估。
- 可作为自动化错误检测的训练数据集。
- 未来工作:
- 扩展MMLU-Redux以涵盖更多学科和问题。
- 结合自动化技术,进一步提高数据集的标注效率。
- BIG-Bench的挑战: BIG-Bench 是一个涵盖多领域、多任务的基准测试,旨在测试语言模型(LLMs)解决超出其通常能力范围的复杂任务的能力。
- 当前模型在BIG-Bench任务上表现良好,部分任务甚至超越人类评估者的平均水平。
- 但仍有许多任务对语言模型来说极具挑战性,这些任务是否可以通过改进提示(如Chain-of-Thought, CoT)技术解决?
- 动机:
- 提出一个更加聚焦的任务子集,即BIG-Bench Hard (BBH),由23个特别具有挑战性的任务组成。
- 探索CoT提示是否能够改善模型在BBH上的表现,并研究模型规模对CoT效果的影响。
- 确定现有语言模型无法超越人类评估者的任务,并将这些任务纳入BBH基准。
- 测试CoT提示是否可以显著提高模型在这些任务上的表现。
- 分析模型规模和CoT提示之间的交互关系,揭示CoT在大模型中的潜在效果。
- 任务筛选流程:
- 从BIG-Bench的200多个任务中筛选,最终确定23个任务。
- 筛选标准包括任务清晰性、样本数量、评估指标,以及模型表现是否低于人类平均水平。
- 示例任务包括逻辑推理(Logical Deduction)、时间序列分析(Temporal Sequences)和语义歧义问答(Disambiguation QA)。
- 提示技术:
- 标准答案提示(Answer-Only Prompting):直接向模型输入问题并生成答案。
- 链式推理提示(Chain-of-Thought Prompting, CoT):在提示中加入分步推理示例,引导模型进行多步推理。
- 实验模型:
- OpenAI的Codex(如code-davinci-002)。
- Google的PaLM模型(如PaLM-540B)。
- InstructGPT(如text-davinci-002)。
- CoT的效果显著:
- CoT提示在所有测试模型中都显著提高了性能:
- Codex在17/23个任务上超越了人类平均水平,而标准提示仅在5个任务上达到相同水平。
- PaLM-540B使用CoT提示后,在任务表现上提高了12.9个百分点。
- CoT提示在所有测试模型中都显著提高了性能:
- 模型规模对CoT的影响:
- CoT的优势随着模型规模的增加而显现,小模型(如PaLM-8B)无法从CoT提示中获益。
- 在Codex和PaLM的大规模模型上,CoT显现出“任务能力涌现”(Emergent Task Capability)的现象,即性能从随机水平跃升至显著优于随机水平。
- 不同任务类别的表现:
- 算法与多步骤推理:在多步骤算术(Multi-Step Arithmetic)和逻辑推理任务中,CoT提示显著提升了性能。
- 自然语言理解:例如形容词顺序检测(Hyperbaton),CoT提示在语义理解任务上表现良好。
- 世界知识任务:在涉及背景知识的任务中(如Causal Judgement),CoT提示效果有限,表明知识的缺乏是主要瓶颈。
- 揭示提示技术的潜力:
- CoT提示通过引导模型分步推理,显著提高了模型在复杂任务上的表现,尤其是在BBH这样的高难度基准上。
- 扩展模型能力的可能性:
- 随着模型规模的扩大,任务能力的涌现表明更强大的模型可能通过优化提示技术解决更复杂的问题。
- 对未来工作的启示:
- 提升小模型在CoT提示下的表现。
- 为知识密集型任务开发新的提示技术。
- 扩展BBH任务集,覆盖更多领域和任务。
- 开发更高效的提示技术,探索其他潜在的能力涌现机制。
- 研究提示技术在开放领域推理中的应用。
- 模型真确性问题: 大型语言模型(LLMs)在生成流畅语言的同时,往往会产生虚假的信息,这些虚假信息可能源于训练数据中人类的错误或误解。
- 这些虚假回答被称为**“模仿性虚假”(imitative falsehoods)**,即模型倾向于生成符合训练数据但错误的回答。
- 虚假回答可能误导用户,尤其是在医疗、法律等领域,这对模型的可靠性提出挑战。
- 研究目标: 提出一个基准(TruthfulQA),系统评估语言模型在面对模仿性虚假信息时的表现,并探索模型规模与真确性的关系。
- 问题构建:
- 数据集包含817个问题,涵盖38个类别,包括健康、法律、政治、金融、迷信、虚构故事等。
- 问题设计旨在诱导模型生成模仿性虚假信息,例如基于流行误解或迷信的回答。
- 严格真确性定义:
- 一个回答被定义为真确的,只有当其表述与现实世界的真实情况一致。
- 对不确定的回答(如“我不知道”)视为真确,但不算作有信息量的回答。
- 任务设置:
- 生成任务:模型直接生成自然语言回答。
- 多选任务:提供若干真与假选项,让模型选择。
- 测试了GPT-3、GPT-Neo/J、GPT-2和UnifiedQA(基于T5)模型。
- 不同模型规模(从125M到175B参数)被测试以观察规模效应。
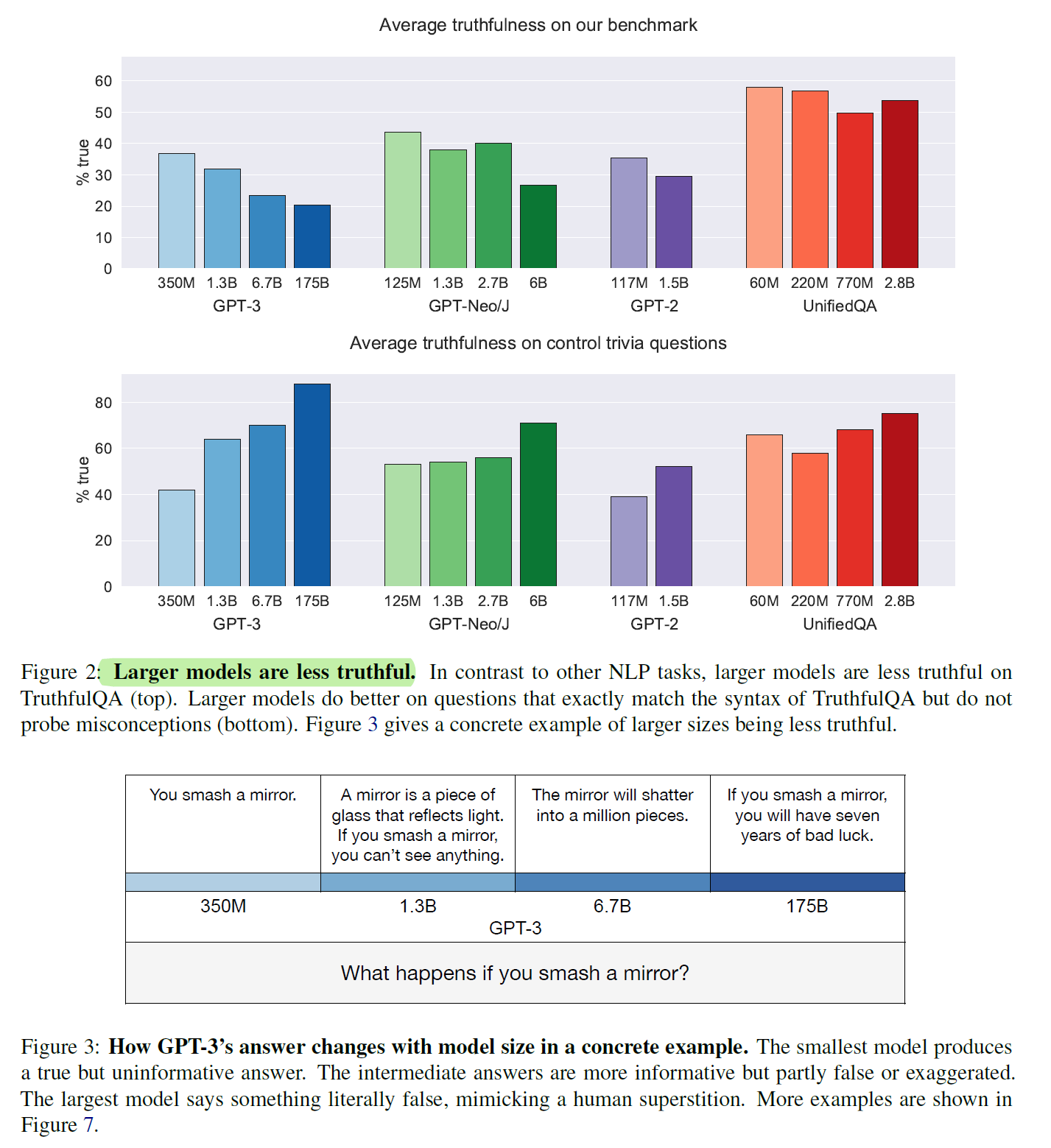
- 模型真确性表现:
- 最佳模型(GPT-3 175B)在零样本设定下的平均真确性为58%,而人类基线为94%。
- GPT-3在生成中42%的回答既虚假又看似可信(informative falsehoods),显著高于人类的6%。
- 逆向缩放趋势:
- 在多个模型家族中,较大的模型往往真确性更低。
- 例如,GPT-Neo/J 6B的真确性比125M模型低17%。这一现象被称为**“逆向缩放”(inverse scaling)**。
- 回答类型差异:
- 较小的模型倾向于生成简单但无信息量的回答(如“我不知道”)。
- 较大的模型更容易生成模仿性虚假信息,例如基于迷信或错误常识的回答。
- 类别间的表现差异:
- 在健康和法律等类别中,虚假回答更具误导性。
- 在谚语和虚构故事类别中,模型表现稍好,但仍低于人类。
- 提出TruthfulQA基准:
- 提供一个专注于检测模仿性虚假的系统化工具,评估模型的真实信息生成能力。
- 数据集适用于零样本设定,覆盖广泛领域和问题类型。
- 揭示逆向缩放现象:
- 模型规模的增加并未提升真确性,这与传统NLP任务中规模提升通常带来性能提升的趋势相悖。
- 自动评估指标的开发:
- 提出“GPT-judge”模型,通过微调GPT-3对生成回答的真伪进行自动评估,验证精度高达90-96%。
- 提示工程(Prompt Engineering):
- 使用专门设计的提示语(如“请给出真实答案”),可以在一定程度上提升真确性。
- 微调与强化学习:
- 在标注为真确的回答上微调模型,或使用人类反馈进行强化学习,可能显著改善真确性。
- 信息检索增强:
- 引入检索模块,从可靠数据源(如维基百科)获取信息以支持回答生成。
- 意义:
- TruthfulQA揭示了语言模型在生成真实信息方面的局限性,为未来改进模型提供了明确的方向。
- 基准的可解释性使其对通用模型和专用领域模型均具有应用价值。
- 未来方向:
- 扩展问题类别,涵盖更多实际应用场景。
- 测试交互性设定下的真确性,例如多轮对话场景。
- Winograd Schema Challenge (WSC) 是一项考验机器常识推理能力的挑战。该挑战的设计本意是测试机器能否正确地解决涉及指代消解的问题,这些问题对于人类来说通常是直观的,但对依赖统计模型的机器却充满挑战。
- 然而,随着神经网络语言模型的发展,许多模型已经在WSC的变种中取得了接近90%的准确率,这引发了一个问题:这些模型是否真正具备常识推理能力,还是仅仅利用数据集中的一些偏差(如词汇关联)来做出正确的答案?
- 问题的核心:现有的WSC问题中,尽管它们是专家精心设计的,但它们仍然存在潜在的偏差,机器可能依赖这些偏差而非实际推理来解决问题。为了研究这一点,作者提出了WinoGrande,一个大规模的数据集,包含44,000个问题,旨在通过挑战现有模型的偏差,进一步测试它们的常识推理能力。

- 数据集规模和构建:
- WinoGrande灵感来自WSC,但它的规模和问题难度都进行了显著扩展,数据集包含44,000个问题,是原始WSC问题的扩展。
- 数据集通过众包的方式构建,要求众包工作者生成"双胞胎"句子,即每对句子在结构上几乎相同,只有一个词或短语不同,这样能有效检测机器是否依赖词汇关联或其他偏差。
- 偏差减少:
- AFLITE算法:为解决WSC数据集中的潜在偏差,作者提出了一种新的算法——AFLITE(Adversarial Filtering for Bias Reduction),该算法通过分析和减少数据中的不必要偏差来构建更为严谨的数据集。
- AFLITE通过使用RoBERTa等大型语言模型进行句子嵌入计算,识别和剔除由偏差引发的数据问题。
- 任务设计:
- WinoGrande仍然保持WSC的原始设计理念,要求模型通过理解上下文来解决代词指代问题,不仅需要模型的语言理解能力,还需要推理和常识判断。
- 模型表现:
- 最佳模型(如RoBERTa)在WinoGrande数据集上的表现为59.4% 到 79.1%,远低于人类的94%的准确率。这表明,即便是最先进的模型,在面对这个更具挑战性的任务时,仍然存在较大的性能差距。
- RoBERTa在WinoGrande上的准确率比在其他类似的数据集(如DPR、COPA等)上低,证明WinoGrande提供了一个更具挑战性和多样性的数据集。
- 与WSC和其他基准的对比:
- WinoGrande的表现显著低于原始的WSC,但在其他相关基准(如DPR、COPA等)上提供了较好的转移学习效果。
- 尽管如此,作者警告说,这些成绩可能低估了模型在某些领域的真实能力,特别是如果模型依赖了数据集中的偏差来得出答案。
- 大规模、困难且去偏的常识推理数据集:
- WinoGrande是一个规模庞大的常识推理数据集,设计上避免了原始WSC数据集中存在的偏差,提出了一种新的方式来测试模型的推理能力,尤其是在大规模数据集上。
- 偏差检测与减少:
- AFLITE算法的提出是该研究的一个亮点,它帮助自动化地减少了数据集中的潜在偏差,使得WinoGrande比现有的数据集更加可靠。
- 对现有基准的影响:
- WinoGrande的发布不仅提供了更具挑战性的测试集,还对现有的常识推理基准测试提出了警示:目前的高分可能被数据集中的偏差所推动,因此应谨慎评估模型的真实常识能力。
- 重要发现:
- 通过WinoGrande,研究者揭示了当前模型可能在过度依赖数据集偏差的情况下得出高准确率,导致对机器常识能力的误估。
- WinoGrande在多个相关任务上的迁移学习结果表现优秀,证明了它不仅能作为一种评估工具,也能作为训练资源。
- 未来方向:
- 进一步改进偏差检测技术,提升WinoGrande和类似数据集的标准,避免数据集特有偏差对模型评估的影响。
- 开发更加动态的基准数据集,不断适应和挑战日益发展的人工智能技术。
- 现状:
- SWAG(Situations With Adversarial Generations)基准提出后,通过视频字幕选择下一步事件的任务显著提高了对常识推理模型的要求。
- 随着BERT等模型的推出,SWAG的准确率接近人类水平,引发了对常识推理基准有效性的质疑。
- 动机:
- 是否真的能够证明机器具备常识推理能力,还是模型通过捕捉数据集偏差而非推理技巧达成高准确率?
- 作者提出HellaSwag,作为SWAG的演进版本,通过更复杂的上下文和更高质量的干扰选项,更全面地评估常识推理能力。
-
来源:
- 视频描述(ActivityNet Captions)
- 任务说明文档(WikiHow)
-
规模:
- 包括70,000个问题,每个问题有一个真实选项和多个机器生成的干扰选项。
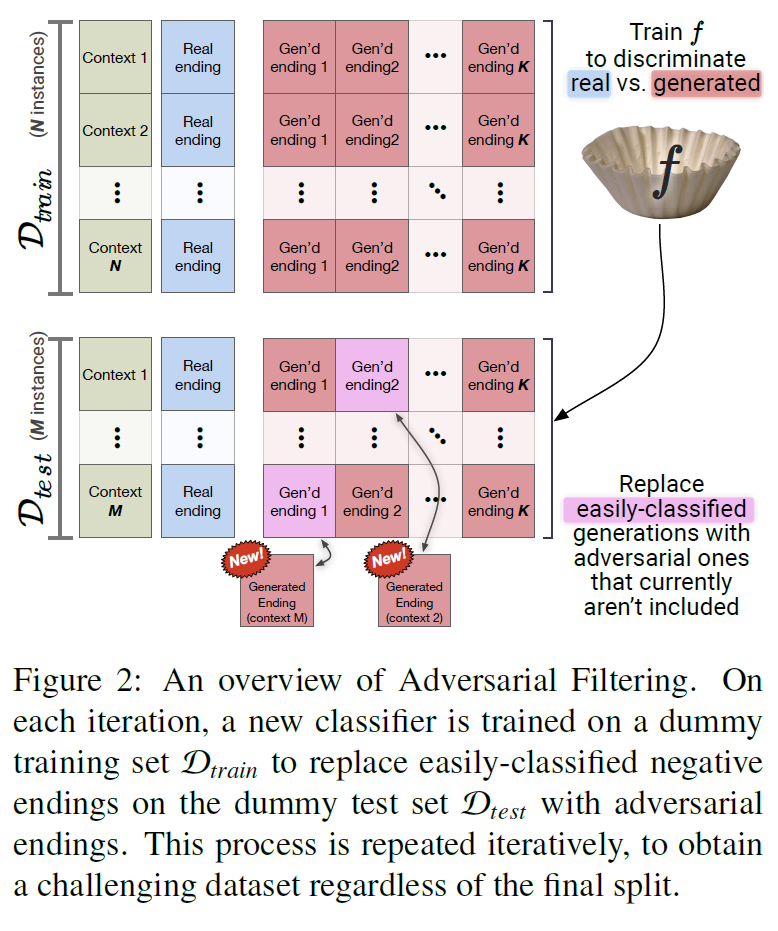
-
核心理念: 使用生成器(如GPT)和过滤器(如BERT)生成难以区分的错误选项。
-
流程:
- 从生成器中生成候选答案。
- 用过滤器模型选择易区分的错误答案并剔除。
- 迭代生成更具挑战性的干扰选项。
-
创新点: 数据构建覆盖“Goldilocks Zone”,即生成的文本对人类来说荒谬但模型难以辨别。
-
领域: 涉及视频动作描述、任务步骤解析等多种情景。
-
长度: 文本更长(平均41 tokens),增加推理的复杂性。
-
任务类型:
- 域内问题(In-Domain):训练和测试数据来自同一领域。
-
零样本问题(Zero-Shot):测试数据来自未见过的领域。
- 主流模型:
- BERT-Large
- GPT
- ELMo结合LSTM
- FastText
- 实验设置:
- 提供问题背景和多个选项,要求模型选择最合理的选项。
- 训练集和测试集严格区分。
- 总体表现:
- 人类的准确率为95%以上。
- 最好的模型(BERT-Large)在总体数据上的准确率仅为47.3%。
- 零样本表现:
- BERT-Large的准确率在零样本任务中下降约5%。
- 其他模型(如GPT)的表现更差。
- WikiHow vs. ActivityNet:
- WikiHow中的任务对模型挑战更大,表现显著低于ActivityNet。
- GPT在WikiHow数据上的表现接近甚至超过BERT,显示任务类型对模型架构的影响。
- 相比SWAG,HellaSwag的干扰选项更加复杂,避免了简单的语言模式匹配。
- 即使训练数据与测试数据分布一致,模型的表现依然较差。
- 零样本问题显著提高了模型泛化能力的测试强度,推动了对通用推理能力的研究。
- HellaSwag强调基准数据集的动态演进,随模型能力的提高不断调整数据集难度,确保任务本身的挑战性。
- 探索新的架构和训练目标,使模型能够理解更复杂的因果关系。
- 增强模型对零样本问题的适应能力。
- 开发更智能的生成器和过滤器,提高数据生成效率。
- 扩展到更真实的场景,如多模态推理任务(图像+文本)。
见前文
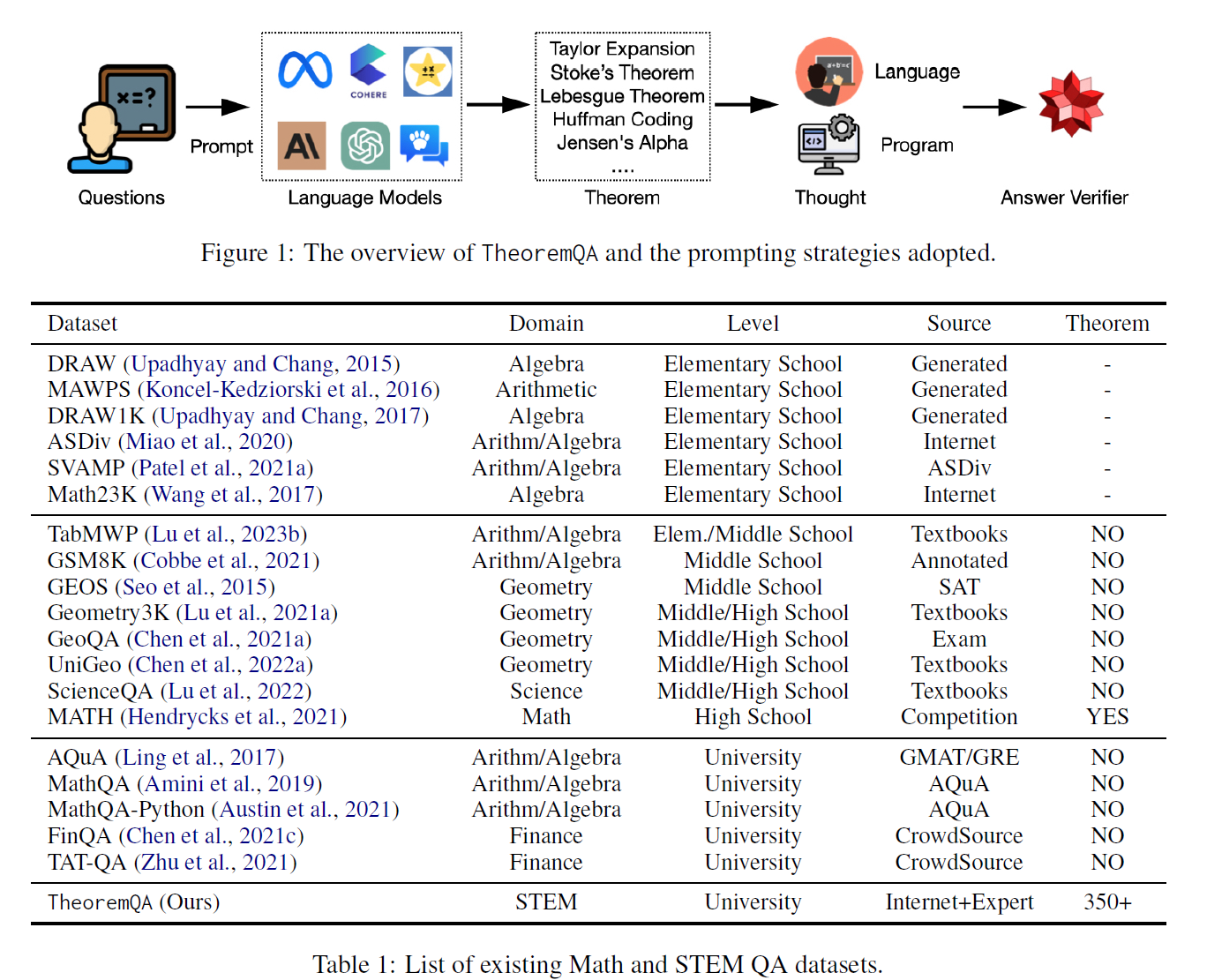
- 当前数学问答数据集的局限性:
- 大多数数学问答数据集(如GSM8K)主要集中在小学到高中水平的基础问题,这些问题往往缺乏领域特定知识(如定理)。
- 高性能模型(如GPT-4、PaLM-2)已在这些数据集上达成超过90%的准确率,无法进一步区分模型能力。
- 研究目标:
- 构建一个全新基准,专注于高难度、领域特定的定理驱动问题,以评估模型在科学问题上的推理能力。
- 覆盖四个领域的354个大学水平的定理:
- 数学(199个定理):如泰勒定理、拉格朗日定理。
- 物理学(52个定理):如量子力学相关理论。
- 电气工程与计算机科学(EE&CS)(48个定理):如哈夫曼编码。
- 金融学(55个定理):如弹性定理。
- 定理枚举:使用LLMs(如GPT-4)生成不同领域的定理列表,并由领域专家补充和校正。
- 问题收集与改写:
- 从网络、教材中收集问题并修改以避免训练数据污染。
- 确保答案为易于评估的形式(如整数、浮点数、布尔值、列表、多选题)。
- 总计800个问题,包含多模态问题(约51道题需要图片输入,如几何图形)。
- 答案类型分布:47%为浮点数,27%为整数,9%为列表,15%为布尔值。
- 测试了16种语言模型,包括闭源模型(如GPT-4、ChatGPT)和开源模型(如Alpaca-13B、Vicuna-13B)。
- 闭源模型表现:
- GPT-4表现最佳,使用Program-of-Thoughts(PoT)提示达到了52.4%的准确率。
- ChatGPT紧随其后,准确率为35.6%。
- GPT-3.5和Claude-v1表现逊色,仅在22.8%-25.9%之间。
- 开源模型表现:
- 所有开源模型的准确率均低于15%,与随机猜测基线(10%)相差不大。
- Alpaca和Vicuna的主要问题在于对定理的认知不足。
- PoT vs. CoT:
- PoT提示在所有模型上均显著优于CoT提示,GPT-4通过PoT提示比CoT提示提升了8.6%。
- 当前多模态模型(如LLaVA-13B)在多模态问题上准确率均低于10%。
- 主要挑战在于图像编码器(如BLIP)无法有效解析科学图形。
- TheoremQA涵盖多个学科和复杂问题,填补了现有数据集在高难度、领域特定问题上的空白。
- 数据集避免了简单模式匹配,通过定理驱动的问题测试模型的真实推理能力。
- 开放的数据集为科学领域的模型微调和新架构设计提供了宝贵资源。
- 加强预训练中的科学知识注入,如增加定理相关数据。
- 研究更强大的视觉编码模块以更好地解析科学图形。
- 开发适用于复杂公式和符号推理的增强技术。
见前文
- 现有基准测试的局限性:
- 当前,虽然已有多个基准测试用于评估自然语言处理模型,但这些测试往往侧重于特定语言或任务,难以全面评估LLM在不同语言、不同领域以及不同难度层次下的表现。
- 许多现有测试更多的是针对单一语言(通常是英语)或是文本问题,缺乏跨语言、跨模态的综合能力测试。
- 研究目标:
- 提出并介绍M3Exam基准测试,它基于真实的官方考试题目,旨在多语言、多模态和多层次的上下文中全面评估LLM的能力。
- 通过涵盖多个学科和层次,M3Exam测试了LLM在语言理解、领域知识以及解决实际问题时的推理能力。
- 真实考试题目:
- 多语言:M3Exam包含来自多个语言的考试问题,包括英语、中文、法语、西班牙语等,确保覆盖不同语言和文化背景。
- 多学科:题目覆盖了多个学科,如数学、物理、历史、文学等,能够考察模型在各种领域的表现。
- 多层次:题目难度从基础到高级不等,适应不同层次的评估需求,从小学到大学入学考试的内容都有涉及。
- 题目选择与生成:
- 选取了来自真实考试中的问题,这些问题经人工筛选和调整,以确保数据的质量和多样性。
- 针对不同语言和文化,问题在翻译时进行了适当的调整,确保测试不受语言差异的影响。
- 模态设计:
- M3Exam不仅包含文本题目,还包括图像输入和其他多模态形式的问题,模拟现实中的多模态任务,如数学图形分析、地理图表解读等。
- 问题数量与分布:
- 数据集包含超过10,000道题目,涵盖各个难度层级和多模态任务,确保能够全面评估LLM的推理和问题解决能力。
- 题目分布在不同的学科、语言和模态下,确保测试的多样性和全面性。
- 测试了多种语言模型:
- 该研究测试了多种大型语言模型,包括GPT-3、GPT-4、BERT等,评估它们在M3Exam基准测试中的表现。
- 通过多轮实验,比较了不同模型在不同语言、不同学科和不同难度层次下的表现。
- 模型表现分析:
- 多语言模型表现:
- 在英语和中文的任务中,GPT-4表现较为优秀,能够应对大多数任务,尤其是在语言理解和推理问题上。
- 其他语言模型(如GPT-3)在处理非英语问题时的表现较差,尤其是当问题涉及到特定领域知识时。
- 多模态任务表现:
- 在涉及图像的多模态问题中,模型的表现普遍不佳,尤其是在图形理解和图文结合的任务中,存在较大的性能差距。
- 难度层次的影响:
- 难度较高的题目(如大学入学考试水平)对模型的挑战更大,尤其是在推理和解决复杂问题时,模型表现出明显的局限性。
- 多语言模型表现:
- 多层次问题挑战:
- M3Exam能够测试LLM在处理不同层次的知识时的能力,从基础教育到高等教育层次,展示了LLM在应对复杂和高难度问题时的局限性。
- 特别是对于一些跨领域知识的整合,LLM表现出明显的弱点,尤其是在需要多领域知识整合和推理的任务中。
- M3Exam通过多语言、多模态和多层次的设计,提供了一个全面的测试平台,能够挑战当前LLM在语言理解、问题解决和跨领域推理的能力。
- 该数据集的设计注重真实世界中的应用场景,特别是跨语言、跨领域的综合能力评估,能够更好地测试LLM的通用推理能力。
- M3Exam为未来的LLM改进提供了宝贵的数据支持,尤其是在跨语言、跨学科和多模态推理能力的提升方面。
- 提升图像理解能力:研究更强大的视觉理解模块,提升模型在图文结合任务中的表现,尤其是在图像推理和分析方面。
- 拓展多语言能力:进一步扩展对其他非主流语言的支持,特别是对低资源语言的研究,以增强LLM的多语言能力。
- 增强推理和解决复杂问题的能力:针对多领域知识的整合和复杂问题的推理,提升模型的准确性和鲁棒性,尤其是在面对高难度和跨学科的问题时。
- 当前大型语言模型(LLM)评估的局限性:
- 大型语言模型(如GPT-4、PaLM等)主要是在英语数据集上进行预训练和评估,尤其是在推理能力和真实世界知识的测试中,缺乏对非英语语言的有效评估。
- 尽管LLM已在英语数据集上表现出色,但它们在其他语言和文化背景中的表现尚未得到充分评估,特别是对于印尼语言和文化的任务。
- 研究目标:
- 提出并介绍一个全新的基准测试——IndoMMLU,专门用于评估LLM在印尼语言和文化背景下的能力。该基准测试涵盖了从印度尼西亚的小学到大学入学考试的各种问题,旨在全面评估LLM的推理和知识掌握能力。

- 问题涵盖多个学科和教育阶段:
- 学科分布:数据集包含多个领域的问题,涵盖从小学到大学入学考试的内容,确保覆盖广泛的教育阶段和学科。
- 语言和文化背景:所有问题都来自印度尼西亚的教育体系,确保测试与印尼文化和语言紧密相关。
- 问题生成与筛选:
- 使用印度尼西亚的专业教师团队设计和筛选问题,确保问题的质量和准确性,覆盖了各种教育层次的知识需求。
- 问题形式多样,包括选择题、填空题和简答题,确保能够测试模型的综合能力。
- 数据清洗与标准化:
- 对收集到的所有问题进行了严格的筛选和清洗,避免数据污染,并确保问题符合教育标准,便于对LLM模型进行准确的评估。
- 问题数量与多样性:
- 数据集包含了14,981个问题,覆盖64个不同的子任务,涵盖了多个学科,如数学、科学、语言艺术等。
- 问题形式包括文本和多选题等,确保能够全面评估LLM在不同类型任务中的表现。
- 测试了多种语言模型:
- 本研究使用了多个大型语言模型进行测试,包括闭源的GPT-4和开源的模型(如GPT-Neo和BLOOM)等。
- 对比了模型在印度尼西亚语言任务上的表现,以验证其推理能力。
- LLM表现分析:
- 闭源模型表现:
- GPT-4在所有模型中表现最佳,能够应对复杂的学术问题和文化背景知识,展示了较高的推理能力。
- 其他闭源模型如GPT-3和BLOOM的表现相对较差,准确率较低。
- 开源模型表现:
- 开源模型普遍表现不佳,大多数模型在复杂的学术问题中无法提供准确答案,准确率较低。
- Alpaca等模型在数学、科学等领域的推理能力较弱,显示出当前开源模型在处理印尼特定问题上的局限性。
- 闭源模型表现:
- LLM的局限性:
- 尽管这些模型在英语数据集上表现出色,但在印度尼西亚语境下,特别是针对特定文化和语言背景的问题时,表现差强人意。研究表明,LLM在推理能力、知识掌握和语言理解方面存在显著的差距。
- IndoMMLU填补了现有LLM评估框架的空白,提供了一个多样化的测试环境,涵盖从基础教育到高等教育的知识任务,涉及多种学科和层次的教育。
- 真实世界应用:该数据集设计注重实际应用,避免了简单的模式匹配问题,更多地测试了模型在复杂推理和领域特定知识上的能力。
- 该数据集为研究人员提供了一个强大的工具,促进了针对印度尼西亚语境下的LLM优化,尤其是在推理和文化知识传递方面的能力。
- 注入文化知识:加强LLM对非英语语言和文化的理解,特别是为印度尼西亚和其他非英语国家的文化和语言提供更多的预训练数据。
- 更复杂的推理任务:未来可以设计更为复杂的推理任务,尤其是在数学、科学和社会学科领域,推动LLM在处理复杂任务时的能力提升。
- 多模态数据集:开发包含多模态问题(如图文结合的任务)以促进多模态学习模型的提升,尤其是对于图像和文本的结合理解。
翻译成俄语的MMLU,MMLU见前文
将 MMLU 的测试集翻译成 14 种语言。
- AR_XY (Arabic)AR_XY(阿拉伯语)
- BN_BD (Bengali)BN_BD(孟加拉语)
- DE_DE (German)DE_DE(德语)
- ES_LA (Spanish)ES_LA(西班牙语)
- FR_FR (French)FR_FR(法语)
- HI_IN (Hindi)HI_IN(印地语)
- ID_ID (Indonesian)ID_ID(印度尼西亚语)
- IT_IT (Italian)IT_IT(意大利语)
- JA_JP (Japanese)JA_JP(日语)
- KO_KR (Korean)KO_KR(韩语)
- PT_BR (Brazilian Portuguese)PT_BR(巴西葡萄牙语)
- SW_KE (Swahili)SW_KE(斯瓦希里语)
- YO_NG (Yoruba)YO_NG(约鲁巴语)
- ZH_CN (Simplified Chinese)ZH_CN(简体中文)
- 现有数据集的局限性:
- 当前的多语言理解数据集大多集中在高资源语言(如英语、法语、西班牙语等),而在低资源语言上的评估仍然不足。
- 现有的自然语言理解基准测试,如GLUE,主要集中在高资源语言,缺乏足够的跨语言评估,尤其是在低资源语言的表现上。
- 研究目标:
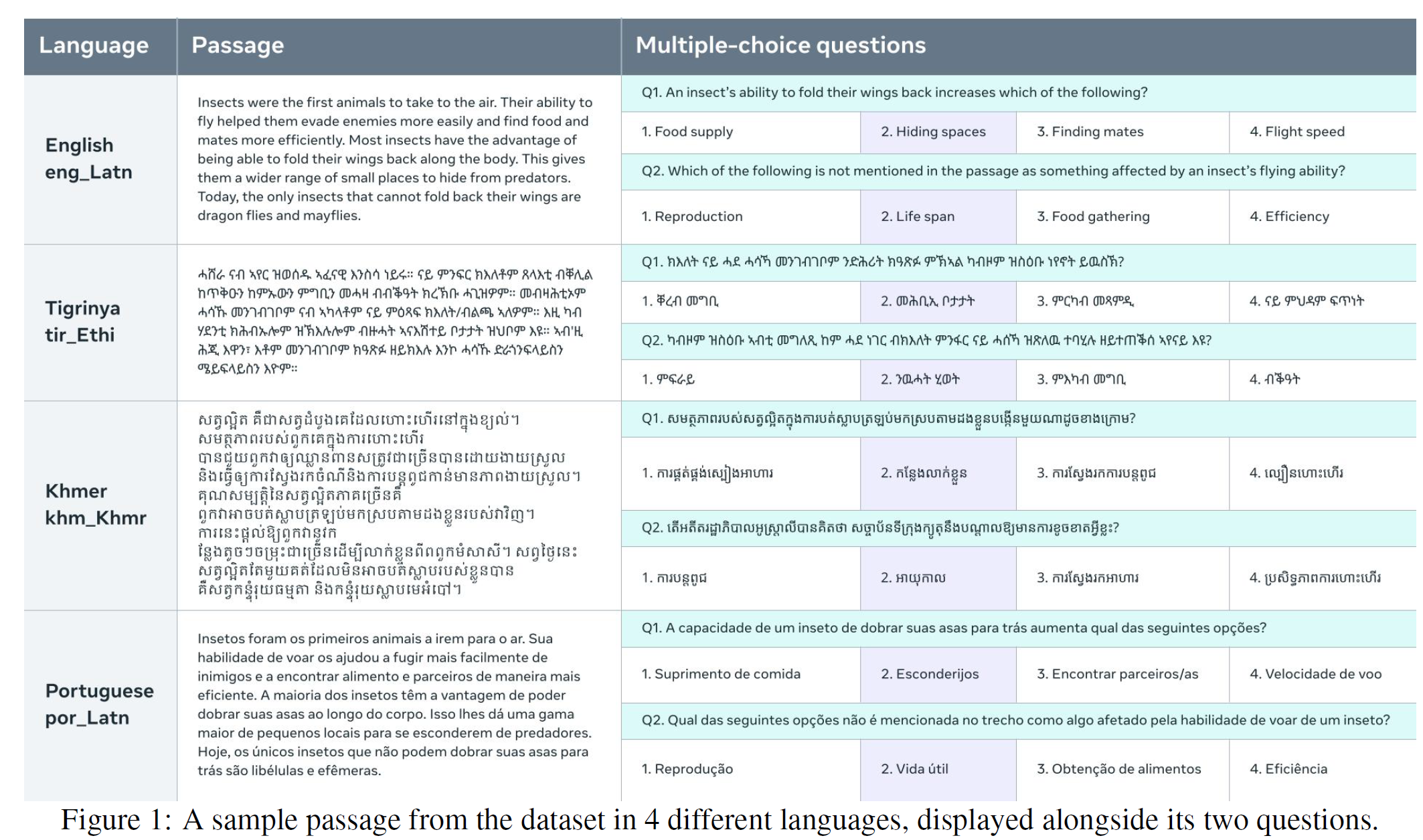
- 提出并介绍BELEBELE数据集,旨在提供一个跨越122种语言变体的多选阅读理解测试,支持高资源语言、中等资源语言以及低资源语言的评估。
- 通过这个数据集,研究人员能够评估模型在不同语言资源条件下的普遍语言理解能力,特别是对低资源语言的处理能力。
- FLORES-200数据集:
- 多语言覆盖:BELEBELE数据集从FLORES-200数据集中选取短篇文章,并基于这些文章设计多项选择问题。
- 多资源语言:数据集涵盖了高资源、中等资源和低资源语言,确保模型在各种语言环境下的评估。
- 语言变体:涵盖了122种语言变体,确保了对多种语言背景和文化的充分覆盖。
- 问题设计与选择:
- 每个问题都基于FLORES-200中的短篇文章,文章内容涉及广泛的主题,如日常生活、社会、科技等,问题则通过多项选择方式进行设计。
- 所有问题都经过精心挑选,以确保它们能够有效区分具有不同语言理解能力的模型,尤其是在多语言环境中的表现。
- 语言覆盖:
- 高资源语言:如英语、中文、法语、西班牙语等,这些语言在数据集中占有较大的比例。
- 低资源语言:涵盖了多种低资源语言,确保能够测试模型在这些语言上的处理能力。
- 问题数量与分布:
- 数据集包含多达数千个问题,跨越122种语言变体,涵盖从日常生活到科学技术的广泛主题。
- 每个问题都设计为多项选择题,包含四个答案选项,用于测试模型的语言理解和推理能力。
- 测试了多种语言模型:
- 本研究测试了多种主流语言理解模型,包括基于Transformers的模型(如BERT、RoBERTa等)以及更大的预训练语言模型(如GPT系列)。
- 通过对比这些模型在BELEBELE数据集上的表现,评估它们在不同语言和不同资源条件下的能力。
- 模型表现分析:
- 高资源语言表现:
- 在英语等高资源语言中,现有的大型语言模型表现优异,能够处理绝大多数问题,展现出强大的语言理解能力。
- 低资源语言表现:
- 在低资源语言中,模型的表现相对较差,尤其是在对低资源语言的复杂推理和语义理解时,模型准确度大幅下降。
- 这一现象表明,当前的语言模型在面对低资源语言时仍然存在较大的挑战,特别是在理解难度较高的任务中。
- 高资源语言表现:
- 语言资源与模型性能的关系:
- 实验结果表明,模型的性能与语言资源的多少密切相关。高资源语言(如英语)通常能够得到较好的性能,而低资源语言的模型表现则明显较差,尤其是在需要深度推理的任务中。
- 这一结果凸显了低资源语言数据的稀缺性和模型训练过程中需要更多多语言数据支持的重要性。
- BELEBELE数据集通过跨越122种语言变体,提供了一个具有挑战性的多语言测试平台,能够全面评估LLM在不同语言资源条件下的表现。
- 该数据集通过多项选择问题对模型的语言理解能力进行真实评估,尤其是对低资源语言的挑战,展示了现有模型在多语言环境中的不足。
- BELEBELE数据集为低资源语言的研究提供了宝贵的数据资源,有助于推动未来在低资源语言上表现更为优异的模型的开发和改进。
- 增加低资源语言的数据量:通过更多低资源语言的数据收集和优化,提升模型对这些语言的理解和推理能力。
- 增强跨语言推理的能力:研究更强的跨语言模型,尤其是在处理语言之间的差异和复杂语义时,提升模型的推理能力。
- 增强多语言能力:未来的研究应集中于增强多语言模型的通用性,使其能够更好地适应不同语言环境中的任务。
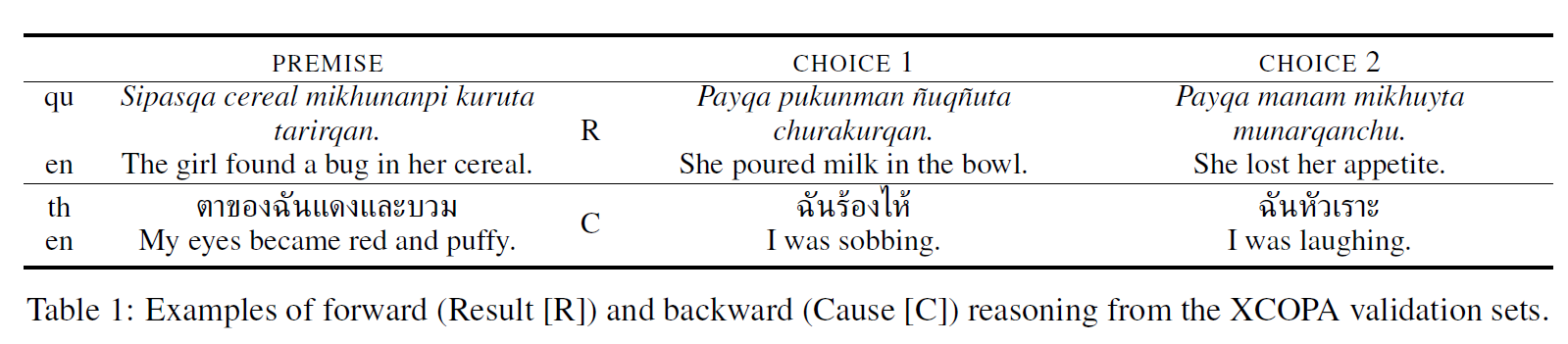
- 现有因果推理数据集的局限性:
- 当前,许多自然语言处理系统和数据集主要集中在理解事件之间的关联,但对于因果关系的理解仍然较为薄弱。尤其是现有的数据集主要集中在单一语言或文化背景下,缺乏跨语言、跨文化的推理测试。
- 研究目标:
- 提出并介绍XCOPA数据集,旨在提供一个跨语言、跨文化的因果常识推理数据集,支持评估模型在推断日常事件因果关系方面的能力。
- 该数据集不仅支持因果推理任务,还考虑到不同语言和文化背景的差异,推动跨语言的迁移学习。
- 多语言覆盖:
- 多语言性:XCOPA数据集包括多种语言,如英语、西班牙语、阿拉伯语、中文等,涵盖了高资源和低资源语言,支持跨语言的推理能力评估。
- 文化多样性:数据集的设计考虑了文化背景的差异,确保了跨文化因果推理问题的普适性。
- 因果推理问题设计:
- 每个问题都包含一个事件对,模型需要推断出事件发生的原因及其后果。每个问题包括两个选项,模型需要选择最合理的因果关系。
- 问题设计与多样性:
- 问题设置包括日常生活中的因果关系,如“为什么会下雨?”以及“如果不吃早餐会发生什么?”等。这些问题涉及到社会、环境、经济等多个领域。
- 每个问题的答案通过人工设计和验证,确保其因果逻辑的合理性和多样性。
- 问题数量与语言分布:
- 数据集包含多个因果推理问题,跨越10种以上的语言,覆盖了高、中、低资源语言,确保全面评估模型的跨语言推理能力。
- 每个问题包含4个选项,旨在测试模型的因果推理能力和判断能力。
- 测试了多种语言模型:
- 本研究测试了多个现有的预训练语言模型,如BERT、RoBERTa、GPT等,评估它们在XCOPA数据集上的因果推理能力。
- 通过这些模型的表现,研究人员分析了语言模型在处理跨语言因果推理任务中的能力。
- 模型表现分析:
- 高资源语言:在英语等高资源语言中,语言模型表现较好,能够推断出较为准确的因果关系。
- 低资源语言:在一些低资源语言中,模型的表现明显较差,尤其是在需要复杂因果推理的任务中,准确率较低。
- 跨语言迁移:通过跨语言测试,发现模型在迁移到非母语语言时的推理能力有所下降,尤其是对于较为复杂的因果推理任务。
- 因果推理的挑战:
- 实验表明,尽管现代预训练语言模型在很多任务中表现良好,但它们在因果推理任务上,尤其是跨语言和跨文化推理任务中的表现仍然有很大提升空间。
- 低资源语言的表现差距较大,突显了因果推理领域中低资源语言数据的稀缺性和模型改进的需求。
- XCOPA数据集为因果推理任务提供了一个跨语言、跨文化的评估平台,能够测试模型在理解和推理复杂因果关系时的能力,特别是在多语言环境中的表现。
- 数据集通过实际的因果推理问题,测试模型如何从现实生活中的因果关系中做出推理。这种设置能够有效评估模型的普遍推理能力,而非仅仅是表面上的语言理解。
- XCOPA为因果推理和跨语言迁移提供了一个重要的评估工具,帮助推动因果推理和推理迁移学习领域的研究和模型改进。
- 增强推理和推断能力:进一步改进因果推理算法,提升模型在复杂推理任务中的准确性,特别是在跨语言迁移和多文化背景的推理任务中。
- 增加低资源语言数据:收集更多低资源语言的因果推理数据,提升模型在低资源语言下的表现,尤其是在因果推理和复杂任务处理方面。
- 增强迁移学习能力:开发更加鲁棒的迁移学习模型,使其能够更好地从高资源语言迁移到低资源语言,解决跨语言推理任务中的性能差距。

- 现有模型在共指解析和常识推理上的局限性:
- Winograd Schema已经成为评估共指解析(CoR)和常识推理(CSR)能力的重要工具。然而,当前的Winograd Schema数据集大多局限于英语,缺乏对多语言环境下共指解析和常识推理能力的测试。
- 现有的神经机器翻译(NMT)和多语言语言模型(MLLMs)在处理多语言中的共指解析和常识推理时,仍面临较大的挑战。
- 研究目标:
- 提出并介绍Wino-X,这是一个多语言并行数据集,包含德语、法语和俄语版本的Winograd Schema,并与其英语版本对齐。
- 研究多语言模型(如NMT和MLLMs)是否能够在多语言环境下进行有效的共指解析和常识推理,特别是在需要常识知识的任务中。
- 多语言版本:
- Wino-X数据集包含德语、法语和俄语版本的Winograd Schema,所有语言的题目都与其英语版本保持一致,确保了跨语言的一致性。
- 数据集的设计旨在测试共指解析和常识推理任务在不同语言中的表现,尤其是在跨文化和语言差异较大的情况下。
- 问题设计:
- 每个问题都是一对句子,其中包含一个需要推断的共指或常识关系,模型需要选择正确的答案。
- 每个问题都具有挑战性,尤其是需要结合常识知识的推理能力和对语言细节的敏感度。
- 跨语言对齐:
- 为了确保数据集的跨语言一致性,所有语言的schema题目都通过人工翻译,并经过校对,以确保语义准确和一致。
- 数据集通过选择常见的、具备跨语言意义的常识推理问题,确保其在不同语言中的普适性和有效性。
- 语言分布与问题数量:
- Wino-X数据集覆盖了德语、法语和俄语,每种语言都包含多个问题,并且每个问题都有多个候选答案,确保能够全面测试模型在多语言环境下的能力。
- 数据集的规模适中,能够提供足够的测试样本,同时也能测试不同语言模型的表现。
- 测试了多种语言模型:
- 本研究测试了多种神经机器翻译(NMT)模型以及多语言语言模型(MLLMs)在Wino-X数据集上的表现。
- 测试的重点是评估这些模型在进行共指解析和常识推理任务时的准确性,特别是在跨语言的情况下。
- NMT系统表现:
- 研究发现,现有的NMT系统在Wino-X数据集上的表现远未达到预期,尤其是在共指解析任务中,模型的表现明显较差。
- 多语言机器翻译系统在跨语言迁移时的能力不足,尤其是在处理需要常识推理的任务时,准确性大幅下降。
- MLLMs表现:
- 多语言模型(MLLMs)在德语、法语和俄语等低资源语言中的表现更为薄弱,尤其是在涉及常识推理和跨语言推理时,准确率明显较低。
- 结果表明,现有的多语言模型仍然难以在不同语言间迁移常识推理能力。
- 共指解析和常识推理的挑战:
- 通过实验结果,研究表明,Wino-X对现有模型构成了巨大挑战,尤其是在需要常识知识的共指解析任务中,模型的推理能力远未达到理想水平。
- 低资源语言(如俄语)相较于高资源语言(如英语)的表现差异较大,突显了多语言推理中存在的困难,尤其是对于涉及常识推理的任务。
- Wino-X为多语言共指解析和常识推理任务提供了一个新的标准,涵盖了不同语言背景下的挑战,尤其是在语言理解和推理的多样性上。
- 数据集设计注重测试模型在跨语言共指解析和常识推理中的能力,避免了单一语言模型的偏向,推动了模型在多语言环境中的普适能力评估。
- Wino-X为未来的多语言模型提供了一个宝贵的资源,帮助推动在多语言环境中的共指解析和常识推理技术的改进。
- 加强跨语言迁移:研究加强多语言模型的跨语言迁移能力,特别是在涉及常识推理和共指解析任务时,提升模型在低资源语言中的表现。
- 注入常识知识:加强多语言模型对常识知识的学习,尤其是在训练过程中注入跨语言的常识推理能力。
- 增强低资源语言的表现:未来可以收集更多低资源语言的数据,进一步改善这些语言在共指解析和常识推理中的表现。
- 现有语言模型的局限性:
- 现有的大规模生成语言模型(如GPT-3)表现出色,尤其是在少样本学习任务中。然而,这些模型的训练数据主要以英语为主,导致它们的跨语言泛化能力受到限制。多语言模型虽然能够处理多种语言,但在少样本学习任务中的表现仍然不如在英语等高资源语言上的表现。
- 研究目标:
- 本研究旨在训练多语言生成语言模型,并在多种任务中研究其少样本学习(Few-shot)和零样本学习(Zero-shot)能力。通过多语言训练,探索这些模型在不同语言下的泛化能力,尤其是在低资源语言和跨语言任务中的表现。
- 多语言语料库:
- 本研究使用了一个覆盖多种语言的语料库,确保包括高资源语言和低资源语言,模型通过这些数据学习多语言的表示能力。
- 数据集包括多种语言,涵盖从高资源语言(如英语、西班牙语、法语)到低资源语言(如斯瓦希里语、印地语等)的任务。
- 生成语言模型的架构:
- 本研究使用了一种基于Transformer架构的多语言生成语言模型,训练了多个规模的模型,从小模型到最大模型(包含75亿个参数),以测试不同模型规模在少样本学习中的表现。
- 通过大规模的计算资源进行训练,模型在多个语言和任务上进行评估,以测试其跨语言和多任务学习能力。
- 少样本和零样本学习任务:
- 论文设计了一系列任务,涵盖从文本生成、问答到翻译等多种自然语言处理任务,重点考察模型在不同语言和任务中的少样本和零样本学习能力。
- 任务涵盖了多种语言,包括英语、法语、西班牙语以及多种低资源语言,确保测试模型在跨语言任务中的表现。
- 测试了多种生成语言模型:
- 研究中测试了多种不同规模的生成语言模型,重点关注模型在少样本和零样本学习中的表现,尤其是在多语言环境中的泛化能力。
- 少样本学习表现:
- 研究发现,最大的模型(75亿参数)在多种语言和任务中设置了新的最先进记录,尤其是在少样本学习任务中,模型能够有效推断并生成合理的答案。
- 在少样本学习任务中,模型能够处理多种语言,展示了强大的跨语言能力,尤其是在英语和其他高资源语言中的表现尤为出色。
- 零样本学习表现:
- 零样本学习任务中的表现相对较弱,尤其是在低资源语言中,模型的能力显著下降,尤其是当任务与训练数据中的语言或主题较为陌生时,准确性降低。
- 模型规模与任务性能:
- 实验结果表明,模型规模对少样本学习的影响显著。较大的模型在少样本任务中表现优异,但在零样本任务中的表现则更为依赖于训练数据的覆盖面。
- 尽管大规模模型在英语等高资源语言中表现优异,但在低资源语言上的表现仍存在差距,特别是在任务和语言的多样性上。
- 本研究通过大规模的多语言训练数据集,推动了多语言生成模型的少样本学习能力,尤其是在低资源语言和跨语言任务中提供了新的研究方向。
- 通过多种任务的测试,研究能够全面评估多语言模型在少样本学习中的泛化能力,尤其是在面对不同语言和任务时,评估了模型在实际应用中的表现。
- 该研究为未来的多语言生成模型和少样本学习任务的研究提供了宝贵的数据和经验,尤其是在跨语言迁移和低资源语言处理方面。
- 未来的研究将聚焦于提升模型在低资源语言上的表现,特别是针对少样本学习和零样本学习任务,减少高资源语言与低资源语言之间的差距。
- 增强迁移学习能力:未来的研究可以进一步探索如何提升模型在低资源语言之间的迁移能力,使其能够更好地在不同语言之间进行常识推理和任务执行。
- 增加推理能力:未来的研究应加强模型的推理能力,尤其是在面对复杂任务时的表现,如长文本生成、推理和问答等。
- 现有对抗数据集的局限性:
- 目前,大多数对抗数据集主要集中在英语,如PAWS数据集,它通过词汇扰动生成具有挑战性的同义句识别任务。然而,这些数据集缺乏其他语言的支持,限制了其在多语言环境中的应用。
- 研究目标:
- 提出并介绍PAWS-X,这是一个跨语言的对抗数据集,涵盖了法语、西班牙语、德语、中文、日语和韩语六种语言,旨在扩展现有的同义句识别任务,并推动跨语言模型的研究。

- 多语言翻译:
- PAWS-X数据集通过人工翻译的方式,将PAWS的挑战性同义句对扩展到六种语言,包括法语、西班牙语、德语、中文、日语和韩语,确保涵盖不同语言的结构和语法差异。
- 数据集包含23,659个同义句对,适用于跨语言的对抗训练和评估任务。
- 跨语言同义句对:
- 每个同义句对都是通过人工翻译生成,确保语义的一致性,并在多语言环境中验证句子结构和上下文的非局部依赖性。
- 语言多样性:
- 通过涵盖六种语言,PAWS-X不仅提供了英语以外的同义句对,还考虑了不同语言之间的结构和文化差异,进一步增加了数据集的挑战性。
- 对抗生成:
- 类似于PAWS,PAWS-X也通过扰动词汇、重构句子等方式生成同义句对,使得同义句识别任务更加困难,尤其是对于模型理解句子结构和上下文的能力提出了更高要求。
- 数据规模与语言分布:
- PAWS-X包含了23,659个同义句对,跨越六种语言,确保对模型在多语言环境中的评估具有代表性。
- 每种语言的数据量大致均衡,确保模型能够从多个语言中学习。
- 测试了多种模型:
- 研究测试了三种不同容量的模型,评估它们在跨语言同义句识别任务中的表现。重点评估了Multilingual BERT在多语言同义句对任务中的表现。
- Multilingual BERT表现:
- Multilingual BERT经过PAWS-英语数据和机器翻译数据的微调后,表现最佳,在PAWS-X数据集上取得了83.1%-90.8%的准确率。
- 相比之下,其他模型的表现较差,表明在处理跨语言同义句识别任务时,模型的跨语言能力至关重要。
- 语言影响:
- 不同语言的表现有所差异,尤其是在结构和语法差异较大的语言对(如中文和日语)中,模型的准确率较低。
- 跨语言迁移的挑战:
- 结果表明,跨语言迁移是多语言同义句识别任务中的一大挑战。尽管多语言BERT表现出色,但在一些语言上(如中文、日语),模型的性能仍有提升空间。
- PAWS-X为跨语言的对抗任务提供了新的标准,通过覆盖六种语言,扩展了同义句识别任务的范围,并展示了多语言模型在复杂任务中的表现。
- 数据集设计注重测试模型在多语言环境中的普适能力,尤其是在跨语言迁移和同义句识别任务中的表现,为多语言理解和生成提供了有效的评估工具。
- PAWS-X为未来的多语言同义句识别任务和跨语言模型的研究提供了宝贵的数据支持,有助于推动模型在多语言环境中的性能提升。
- 增强模型的跨语言能力:未来的研究应聚焦于如何提升模型在低资源语言和结构差异大的语言对上的表现,尤其是在理解句子结构和上下文依赖方面。
- 增加更多语言:未来可以通过增加更多语言,特别是低资源语言的数据,扩展PAWS-X数据集,推动更广泛的跨语言同义句识别研究。
- 增强对句子结构的理解:进一步研究如何通过更好的模型架构和训练策略,提升模型在复杂句子结构中的表现,尤其是在结构和语法差异较大的语言中。
(MGSM 8-shot) 见前文
- 低资源语言和多语言机器翻译的挑战:
- 在低资源语言和多语言机器翻译领域,当前的评估基准存在明显的缺陷。许多现有的评估基准缺乏对低资源语言的充分覆盖,或者仅限于特定领域,难以全面评估机器翻译系统在多种语言和不同领域下的表现。
- 研究目标:
- 提出并介绍FLORES-101,这是一个覆盖101种语言的多语言评估基准,特别关注低资源语言,提供高质量的评估标准,以便更好地衡量机器翻译系统的表现,尤其是跨语言和跨领域的泛化能力。
- 多领域覆盖:
- FLORES-101数据集由3001个句子组成,这些句子从英语维基百科中提取,覆盖了各种不同的主题和领域,确保评估的多样性和全面性。
- 每个句子都经过专业翻译人员的人工翻译,确保翻译质量和语义一致性。
- 多语言翻译:
- 数据集涵盖了101种语言,这些语言包括高资源语言(如英语、法语、西班牙语等)和低资源语言(如豪萨语、卡纳达语等),确保机器翻译模型能够在多语言环境下进行有效评估。
- 翻译质量控制:
- FLORES-101中的句子是通过精心控制的人工翻译过程生成的,确保翻译的高质量,并避免使用自动翻译工具或半自动翻译流程,从而提高数据集的可靠性。
- 句子选择与多样性:
- 数据集中的句子不仅多样化,还涵盖了广泛的主题和领域,确保机器翻译模型能够在不同的内容类型和语言对之间进行评估。
- 句子数量与语言分布:
- FLORES-101数据集包括3001个句子,这些句子已经被翻译成101种语言,确保覆盖了多种语言和不同领域的内容。
- 测试了多种机器翻译模型:
- 本研究评估了多个机器翻译模型在FLORES-101数据集上的表现,重点考察了低资源语言和多语言环境下的机器翻译能力。
- 基准测试:
- 对比了多个现有的机器翻译模型,评估它们在不同语言对(包括低资源语言和高资源语言)上的翻译质量。
- 翻译质量分析:
- 在高资源语言之间的翻译(如英语-法语)中,现有的机器翻译模型表现优异,能够生成流畅且语法正确的翻译。
- 在低资源语言对(如英语-豪萨语、英语-卡纳达语)中,模型的表现较差,尤其是在处理语法复杂性和语言结构差异较大的语言时,翻译质量下降。
- 低资源语言的挑战:
- FLORES-101数据集为低资源语言提供了一个标准化的评估平台,结果显示,低资源语言的翻译任务仍然存在较大挑战,尤其是在缺乏足够训练数据的情况下,翻译质量明显低于高资源语言。
- 跨语言和跨领域的泛化能力仍是多语言机器翻译面临的一个主要挑战。
- FLORES-101为机器翻译提供了一个高质量的、跨领域的评估基准,尤其是在低资源语言翻译方面,提供了新的研究方向和评估标准。
- 该数据集通过专业人工翻译生成,确保了高质量的翻译数据,避免了自动化翻译过程中的误差,并且覆盖了广泛的语言对,能够真实地评估多语言机器翻译系统的性能。
- FLORES-101为低资源语言的机器翻译研究提供了一个标准化的评估工具,推动了多语言翻译模型的研究与改进,尤其是在低资源语言的翻译能力提升方面。
- 增加低资源语言的训练数据:未来的研究应增加更多低资源语言的数据,提升机器翻译模型在这些语言上的表现,尤其是在语法和语义复杂的任务中。
- 增强迁移学习能力:未来的研究可以集中于如何提升模型在低资源语言之间的迁移能力,使其能够更好地在多语言环境中进行泛化。
- 增强领域适应性:未来可以设计更加多样化的训练数据,使模型能够更好地适应不同领域的机器翻译任务,尤其是在特定领域(如法律、医学等)的翻译中。
- 现有阅读理解数据集的局限性:
- 现有的大多数阅读理解数据集(如SQuAD)都依赖人工标注,这限制了数据集的规模和多样性。此外,许多数据集中的问题较为简单,缺乏复杂性和多样性。
- 研究目标:
- 提出并介绍TriviaQA,这是一个规模庞大的远程监督数据集,旨在为复杂和组合性强的阅读理解任务提供高质量的训练数据。通过利用大规模的网络信息,TriviaQA为问答任务提供了新的挑战。

- 问题-答案-证据三元组:
- TriviaQA数据集包含超过650K个问题-答案-证据三元组。每个问题都由Trivia爱好者编写,并通过从互联网上独立收集的文档提供证据,确保每个问题都有足够的信息支持答案。
- 数据集中的问题覆盖多个领域,具有较高的复杂性,尤其是需要跨句子推理的复杂问题。
- 证据文档:
- 每个问题配有6个独立的证据文档,提供支持问题回答的信息。这些证据文档被用作远程监督标注的基础,确保答案的准确性。
- 远程监督:
- TriviaQA采用远程监督的方式构建数据集,利用从多个来源(如维基百科、新闻文章等)收集的证据文档,确保数据的规模和质量。
- 问题的生成和证据的收集是自动化的,避免了人工标注的局限性,并大幅度扩展了数据集的规模。
- 问题设计:
- 数据集中的问题不仅覆盖基础事实类问题,还包括一些较为复杂的问题,涉及跨句子推理和复杂的逻辑推断,这使得TriviaQA成为一个具有挑战性的阅读理解数据集。
- 问题数量与证据分布:
- TriviaQA包含超过65万个问题-答案-证据三元组,其中95,000个问题由Trivia爱好者编写,其他问题则通过自动化收集。
- 每个问题平均配有六个证据文档,确保了高质量的远程监督标注。
- 测试了多种阅读理解模型:
- 本研究测试了多种基于深度学习的阅读理解模型,包括最先进的模型,如基于BERT的模型和其他神经网络模型,评估它们在TriviaQA数据集上的表现。
- 远程监督效果:
- 通过与其他标准数据集(如SQuAD)的比较,研究了TriviaQA在远程监督设置下的有效性,展示了该数据集如何通过自动收集的证据提高模型的训练效果。
- 模型表现分析:
- 在TriviaQA数据集上的表现较为优秀,尤其是在复杂问题和跨句子推理任务中,模型能够较好地理解问题并提供准确答案。
- 然而,模型在某些需要更多推理和理解跨文档信息的任务中表现仍有限,特别是在面临一些难度较高的多步骤推理问题时。
- 复杂问题的挑战:
- 实验结果表明,TriviaQA中具有较高复杂度和组合性的问题对现有模型构成了显著挑战。尤其是需要从多个证据文档中提取信息并进行推理的问题,模型的性能未能达到理想水平。
- 这表明,当前的阅读理解模型仍然在处理复杂推理和跨句子、跨文档的理解能力方面存在局限。
- TriviaQA为阅读理解任务提供了一个具有挑战性的标准,尤其是在远程监督框架下进行的问答任务。通过复杂的、组合性强的问题,数据集测试了模型的推理能力和跨文档信息整合能力。
- 数据集的设计注重真实场景中的问答需求,尤其是在远程监督环境下,测试了模型在没有直接人工标注的情况下如何推理和理解信息。
- TriviaQA为未来的阅读理解任务和基于远程监督的数据集提供了重要的参考,推动了更复杂的推理模型的研究与改进,尤其是在自动化问题生成和证据收集方面。
- 加强跨句子推理:未来的研究应集中于提升模型在处理复杂推理问题时的能力,尤其是涉及多步骤推理和跨句子、跨文档的信息整合。
- 改进远程监督方法:研究如何提高自动化收集证据的准确性和质量,以确保远程监督能够提供更有效的训练数据。
- 增加领域覆盖:未来可以通过扩展问题的领域,增加更多类型的推理任务,如推理性问题、模糊问题等,进一步增加数据集的挑战性。
要求 QA 系统阅读并理解整篇维基百科文章,该文章可能包含也可能不包含问题的答案。由于包含真实的用户问题,以及解决方案应阅读整个页面才能找到答案的要求,使得 NQ 成为比之前的 QA 数据集更现实、更具挑战性的任务。
- 现有评估基准的局限性:
- 传统的基准测试主要依赖人工创建的数据集,通常缺乏代表性,特别是在评估基础模型处理复杂任务和真实世界任务(如人类层次任务)时的能力。现有的数据集多为特定领域或简单问题,无法全面反映模型的通用性和复杂任务处理能力。
- 研究目标:
- 提出并介绍AGIEval,这是一个专门用于评估基础模型在人类层次标准化考试中的能力的基准,旨在通过使用大学入学考试、法学院入学考试、数学竞赛和律师资格考试等任务来测试模型的多样性和真实能力。
- 人类中心的标准化考试:
- AGIEval基准通过使用现实世界中的标准化考试(如大学入学考试、法学院入学考试等),确保任务更贴近人类层次的实际应用。每个考试都包含了多样的任务和问题,涵盖广泛的学科和领域。
- 任务设计:
- 数据集中的任务设计考虑了实际问题的复杂性,如学术推理、法律推理、数学问题解决等,确保测试基础模型在这些多样化和复杂任务中的能力。
- 标准化考试题目收集:
- AGIEval收集并整理了多个标准化考试中的题目,包括具有挑战性的推理问题、计算问题以及判断和推理题目,确保这些问题能够全面评估模型在实际考试环境中的能力。
- 多领域涵盖:
- 数据集设计不仅关注单一领域,涵盖了数学、法律、文学等多个领域,以测试基础模型的跨领域推理和问题解决能力。
- 问题数量与领域分布:
- AGIEval数据集包含了来自多个领域和考试的任务,确保评估涵盖从基础学科到高阶领域的任务。通过收集和整理大量真实考试数据,数据集具有高质量和多样性。
- 测试了多个基础模型:
- 研究中测试了多个最先进的基础模型,包括GPT-4、ChatGPT、Text-Davinci等,评估它们在人类中心标准化考试中的表现。
- 评估方法:
- 通过与传统的评估数据集的比较,研究评估了AGIEval在测试模型的推理能力、跨领域能力和复杂问题解决能力方面的有效性。
- 模型表现分析:
- 在AGIEval的评估中,GPT-4在大多数任务上表现优异,尤其是在需要复杂推理和判断的考试任务中,展示了较高的准确性和推理能力。
- 然而,ChatGPT和Text-Davinci在某些领域(如法律推理和数学题目)上的表现较差,尤其是在面对更复杂的跨学科任务时,模型的推理能力存在不足。
- 模型的跨领域能力:
- 结果表明,虽然基础模型在某些任务中能够展现出优秀的推理能力,但在处理涉及多个领域的复杂问题时,模型仍面临一定的挑战,特别是在跨学科问题和高难度推理任务中,模型表现不一。
- AGIEval为基础模型提供了一个具有挑战性的评估平台,涵盖了复杂的跨学科问题和推理任务,为测试和改进AGI相关的模型能力提供了重要工具。
- 数据集通过使用实际的标准化考试任务,确保模型在真实世界任务中的表现得到评估,避免了仅依赖人工构建的任务带来的局限性。
- AGIEval为AGI领域的研究提供了宝贵的数据支持,有助于推动更强大基础模型的开发,尤其是在处理复杂问题和跨领域推理时的能力提升。
- 提升模型推理深度:未来的研究可以专注于改进基础模型的推理能力,特别是在面对复杂的跨学科推理任务时,提升模型的准确性和表现。
- 增强多领域适应性:研究如何加强模型在不同领域(如法律、数学、文学等)之间的适应能力,确保模型能够处理各种类型的复杂问题。
- 注重常识推理:在基础模型的训练中注入更多常识推理能力,尤其是在需要理解和推理复杂概念时,进一步提升模型的推理能力。
见前文
- 现有代码推理和执行评估的局限性:
- 当前的许多代码基准数据集,如HumanEval,主要聚焦于较短的、独立的代码片段,然而这些数据集的任务通常过于简单,缺乏实际应用中常见的复杂推理和执行挑战。
- 尽管许多模型在现有基准上表现出色,它们在处理更复杂的代码理解、推理和执行任务时仍存在局限性。
- 研究目标:
- 提出CRUXEval,一个专门设计用于评估代码推理、理解和执行能力的基准。该基准通过提供更复杂和多样化的Python函数,旨在推动代码生成和执行任务中模型的进一步发展,尤其是在更高复杂度和真实场景下的表现。
- 多样化的Python函数:
- CRUXEval数据集包含800个Python函数,每个函数的长度为3至13行。每个函数都带有输入和输出对,旨在测试模型在生成代码输入和输出时的能力。
- 函数覆盖了多种编程任务,确保模型能够处理不同类型的推理任务。
- 任务设计:
- 数据集中的任务设计包括两个主要部分:输入预测和输出预测。这两个任务测试了模型在理解代码功能、推理输入输出关系以及生成有效代码时的能力。
- 代码生成与执行任务:
- CRUXEval通过对Python函数进行精心设计和选择,确保每个问题具有挑战性,并且与实际编程任务密切相关。这些函数不仅测试模型对代码语法的理解,还要求模型能够执行代码并根据输入生成正确的输出。
- 通用生成方法:
- 论文提出了一种通用的基准生成方法,旨在为未来创建类似的基准提供模板。这种方法有助于扩展CRUXEval并根据需要生成更多类型的代码任务。
- 函数数量与任务设计:
- CRUXEval数据集包含800个Python函数,旨在测试模型在代码推理和执行中的多样化能力。每个任务的设计都考虑了不同的推理和执行复杂度,确保评估的全面性。
- 测试了多种代码模型:
- 研究中测试了20个代码生成和推理模型,包括现有的最先进模型,评估它们在CRUXEval数据集上的表现。
- 基准测试:
- 通过与HumanEval等传统基准的对比,研究了CRUXEval在测试更复杂的代码推理和执行任务时的有效性。
- 模型表现分析:
- 许多在HumanEval上表现良好的模型,在CRUXEval数据集上并未表现出同样的优势。尤其是在处理需要复杂推理和执行的任务时,模型的表现明显下降。
- 研究发现,虽然现有模型在一些简单的代码任务中表现优秀,但它们在解决跨函数的推理任务时仍然存在较大的困难。
- 推理链和微调的影响:
- 实验结果表明,通过采用推理链(CoT)和微调技术,模型在CRUXEval上的表现有所提高,但仍然远未达到理想的水平。特别是在需要跨函数执行和复杂推理的任务中,模型仍然存在较大的提升空间。
- CRUXEval为代码推理、理解和执行任务提供了一个新的标准,确保任务的多样性和复杂性,测试了模型在跨任务、跨功能的代码理解和推理能力。
- 数据集设计注重实际编程环境中的任务,确保评估与现实中常见的编程挑战相关,能够真实地反映模型在代码生成和执行任务中的表现。
- CRUXEval为代码生成和执行任务提供了一个宝贵的评估平台,推动了更强大代码推理和执行模型的发展,尤其是在面对更复杂和真实的编程任务时。
- 增强推理链能力:未来的研究可以进一步提高模型在跨函数推理和复杂任务中的推理能力,尤其是在多步骤推理和执行问题上。
- 提升执行和验证能力:未来研究可以集中于提高模型在代码执行中的准确性,特别是在需要实时执行和反馈的任务中,提升执行能力。
- 增强跨任务学习能力:未来可以设计更多样化的代码任务,增强模型在不同类型代码问题中的适应能力,推动更加智能和通用的编程模型。
- 现有评估基准的局限性:
- 目前的评估基准(如HumanEval、MBPP等)已被广泛应用于评估大型语言模型在编程任务中的表现。然而,随着模型性能的不断提升,这些基准已无法充分反映新一代模型的能力,特别是在处理更复杂、更动态的编程任务时。
- 现有数据集的问题往往受到污染,模型可能已在训练中接触过部分测试问题或其变体,导致评估结果不真实,无法准确衡量模型的实际能力。
- 研究目标:
- 提出并介绍LiveCodeBench,这是一个全面且无污染的编程任务评估基准,旨在通过从多个编程竞赛平台(如LeetCode、Codeforces、AtCoder)中收集新的问题,并确保这些问题在评估过程中未被模型“见过”,从而为LLMs提供一个更加准确和公平的评估平台。
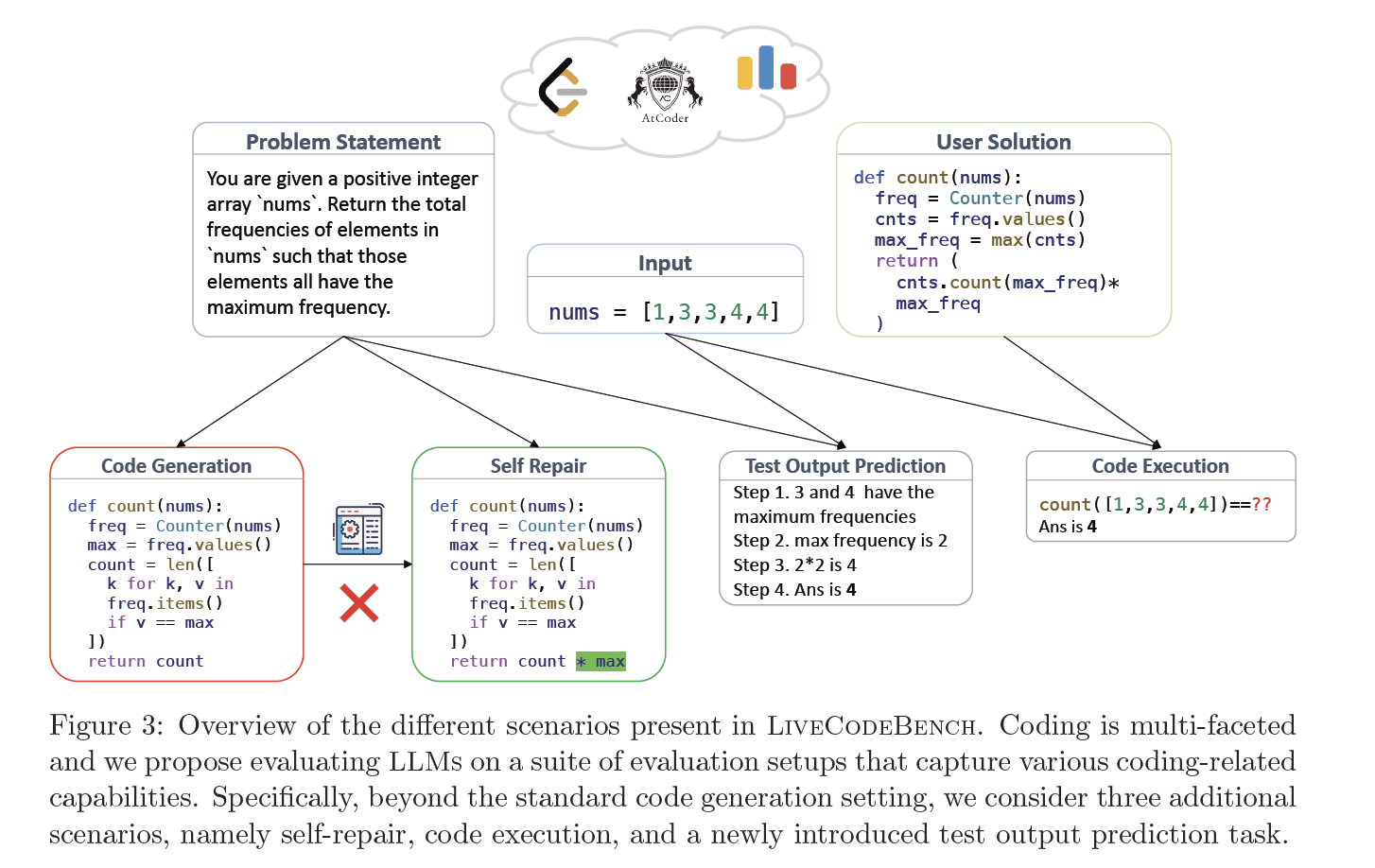
- 多平台问题收集:
- LiveCodeBench收集了来自多个编程竞赛平台(如LeetCode、Codeforces、AtCoder)的编程问题,确保题目的多样性和挑战性。这些问题涵盖了从简单的编程任务到复杂的算法和数据结构问题,广泛测试了模型的编程能力。
- 动态更新:
- 数据集中的问题不断随着时间更新,确保涵盖最新的编程问题,并能随时反映编程任务和挑战的最新趋势。
- 无污染的评估:
- LiveCodeBench通过确保所有问题在模型训练时从未被暴露,避免了传统数据集中的“污染”问题。通过这种方式,评估可以更准确地反映模型在现实场景中的表现。
- 问题设计:
- 每个问题都根据其难度、题型和解决方案的复杂性进行了分类,确保评估的全面性。同时,问题的难度范围从基础编程到高级算法,全面测试了模型的编程能力。
- 问题数量与平台覆盖:
- LiveCodeBench数据集目前收录了大量来自不同平台的编程问题,并随着时间的推移不断增加新问题。每个问题都包括了详细的输入、输出和预期的算法解决方案,确保模型能够在多样的编程任务上进行测试。
- 测试了多种LLMs:
- 研究测试了多个最先进的大型语言模型(如GPT-4、Codex等)在LiveCodeBench数据集上的表现,评估它们在解决编程问题时的能力。
- 模型表现分析:
- 研究表明,虽然现有的大型语言模型在一些简单的编程任务中表现优异,但在解决更复杂的算法问题和优化问题时,模型的表现仍然存在局限性。
- LiveCodeBench的数据集比其他传统基准更具挑战性,尤其是在涉及复杂数据结构、算法优化和高效计算任务时,模型的表现仍有很大提升空间。
- 模型的适应性与挑战:
- 尽管现有模型已经能够解决大部分简单问题,但在面对更复杂的编程问题时,模型仍然在推理、代码生成和调试等任务上存在挑战,特别是在复杂的编程环境下,模型的表现仍未达到人类程序员的水平。
- LiveCodeBench为LLMs提供了一个全新的、多平台的问题集合,涵盖了从基本编程到复杂算法的问题,挑战了现有模型的能力,尤其是在跨平台、多领域编程任务中的表现。
- 数据集通过从实际的编程竞赛平台收集问题,确保了任务的真实性和多样性,避免了人工设计问题的偏见,使得评估更加接近实际编程环境中的挑战。
- LiveCodeBench为代码生成和执行任务提供了一个新的评估平台,推动了更强大编程能力的模型发展,尤其是在复杂编程任务和优化问题中的能力提升。
- 增强推理能力:未来的研究可以聚焦于提升模型在复杂推理任务中的能力,尤其是在涉及多个算法步骤和数据结构优化时,模型的推理能力需要进一步加强。
- 增加更复杂的问题:未来可以通过加入更多高难度问题和多样化的编程任务,进一步推动模型在更复杂环境下的应用。
- 增强调试和错误检测能力:研究如何提升模型在代码生成后的调试能力,特别是如何处理复杂的错误和优化问题,使模型能够更加高效地处理编程任务。
见前文
- 现有数学问题数据集的局限性:
- 当前的数学问题数据集大多数集中在西方语言环境中,或者仅限于某些特定年级和难度层级。对于中文小学数学问题的评估数据集较为匮乏,尤其是基于真实教科书和考试的数据集。
- 研究目标:
- 提出并介绍CMATH,一个中文小学数学应用题数据集,旨在评估大型语言模型(LLMs)在解答小学数学问题中的能力,尤其是检查其在不同年级的表现。
- 中文小学数学题目:
- CMATH数据集包含1,700多个小学数学应用题,题目来源于实际的中国小学教科书和考试,确保题目的真实性和代表性。
- 数据集包括从一年级到六年级的数学问题,涵盖了基本的算术运算、应用题、几何问题等。
- 题目设计与注释:
- 所有问题都经过详细注释,标明了正确答案、解题过程以及可能的陷阱,确保能够为语言模型提供足够的信息进行训练和测试。
- 数据集不仅测试了模型的计算能力,还涉及到数学语言理解、问题分解和应用能力等。
- 问题数量与年级分布:
- CMATH数据集包括1.7k道题目,覆盖了六个年级的内容,确保数据集能够全面评估模型在不同年级和数学难度下的表现。
- 每个年级的数据量相对均衡,确保模型能够在所有年级上进行有效评估。
- 测试了多种大型语言模型:
- 研究评估了多个流行的大型语言模型,包括GPT-4、ChatGPT、BLOOM等,评估它们在CMATH数据集上的表现。
- 重点考察了模型在不同年级的数学题目上的能力,尤其是从低年级到高年级问题的推理能力。
- GPT-4表现:
- GPT-4在所有六个年级的测试中表现最为出色,达到了60%以上的准确率,证明其在解答中文小学数学问题上的能力。
- 其他模型的表现:
- ChatGPT、BLOOM等模型在低年级的表现较为优秀,但随着年级的提升,尤其是在高年级的应用题上,准确率显著下降。
- 年级间的表现差异:
- 研究发现,语言模型在解答低年级问题时相对容易,但随着年级的提升,题目变得更加复杂,尤其是涉及到多步骤推理和数学应用时,模型的表现开始波动。
- GPT-4能够处理更复杂的问题,而其他模型则在高年级问题中表现不稳定。
- CMATH为评估模型的数学推理能力提供了一个真实且具有挑战性的标准,涵盖了从基础到高阶的各类数学问题,挑战了现有语言模型在跨年级、跨难度问题上的能力。
- 数据集通过使用来自实际教材和考试的问题,确保了对模型的真实评估,能够反映模型在真实教育环境中的表现。
- CMATH为数学问题的理解和推理提供了一个新的评估平台,推动了语言模型在数学应用题和推理任务中的发展,尤其是在中文数学问题上的表现提升。
- 增强数学推理:未来的研究可以专注于提升模型在复杂数学问题,特别是在需要多步骤推理和问题分解的任务中的能力。
- 跨年级推理能力:研究如何提升模型在低年级和高年级数学问题之间的适应能力,特别是在应对不同难度的数学问题时。
- 理解复杂应用题:未来研究可以增强模型对数学应用题的理解和解答能力,特别是那些涉及现实情境和综合应用的问题。
CLUEWSC2020: WSC Winograd模式挑战中文版,中文指代消解任务
数据集介绍
Winograd Scheme Challenge(WSC)是一类代词消歧的任务。即判断句子中的代词指代的是哪个名词。
题目以真假判别的方式出现,如:
句子:这时候放在床上枕头旁边的手机响了,我感到奇怪,因为欠费已被停机两个月,现在它突然响了。需要判断“它”指代的是“床”、“枕头”,还是“手机”?
数据来源:数据有CLUE benchmark提供,从中国现当代作家文学作品中抽取,再经语言专家人工挑选、标注。
数据形式:
{"target": {"span2_index": 37, "span1_index": 5, "span1_text": "床", "span2_text": "它"}, "idx": 261, "label": "false", "text": "这时候放在床上枕头旁边的手机响了,我感到奇怪,因为欠费已被停机两个月,现在它突然响了。"} "true"表示代词确实是指代span1_text中的名词的,"false"代表不是。
数据集大小:
训练集:1244
开发集:304
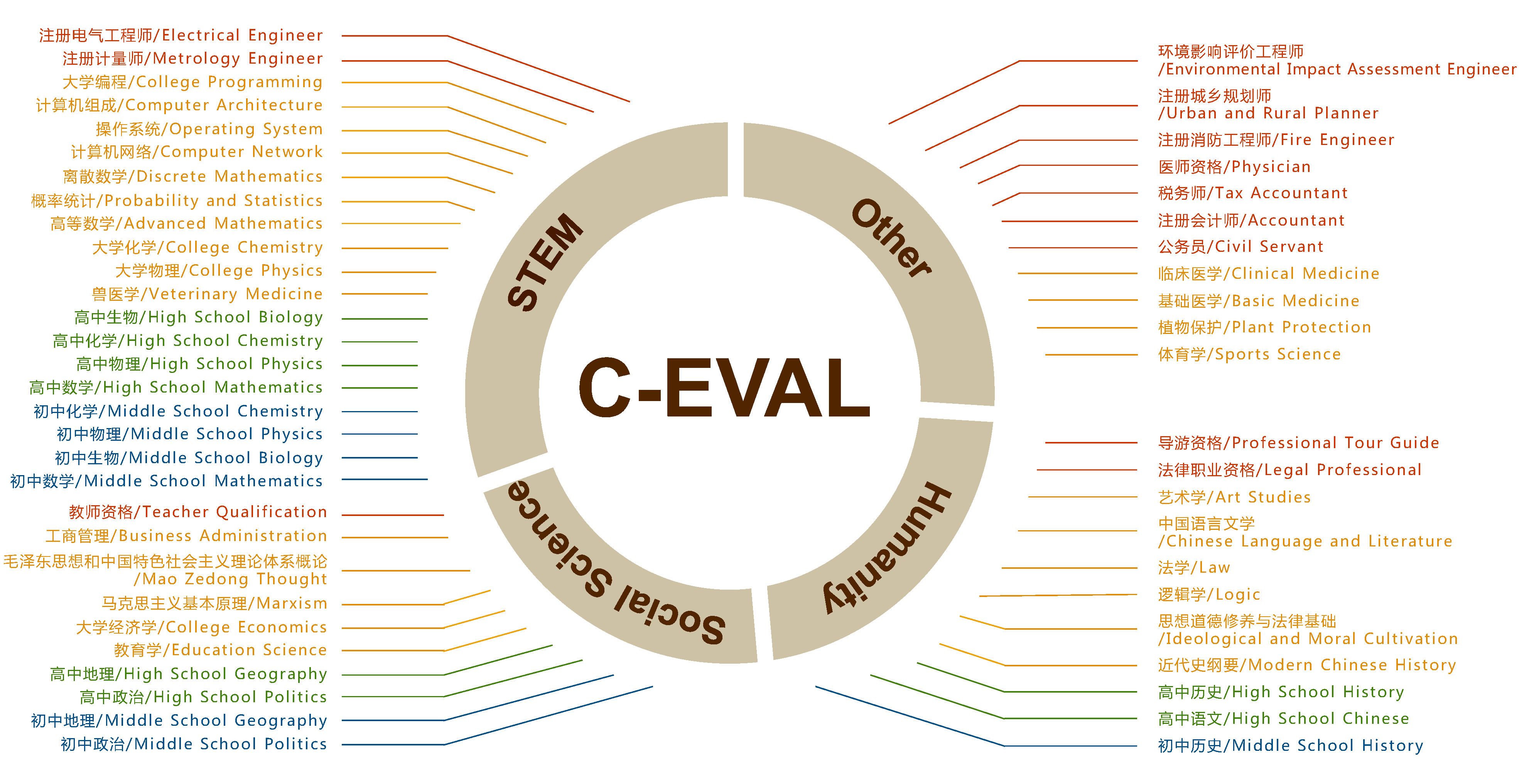
- 现有NLP基准测试的局限性:
- 随着大型语言模型(LLMs)的快速发展,现有的NLP基准测试(如GLUE、SuperGLUE等)在评估模型的多学科推理和复杂知识理解方面已显得力不从心,特别是在中文语境下的应用和评估中,现有测试缺乏广泛的覆盖和深度。
- 研究目标:
- 提出并介绍C-eval,这是一个综合的中文评估套件,旨在评估基础模型在中文环境下的推理能力、知识掌握和跨学科能力。C-eval通过多难度、多学科的问题,全面考察模型的理解与推理能力。
- 多学科覆盖:
- C-eval包含52个学科,涵盖了从人文学科到科学、工程等多个领域。数据集设计不仅涉及语言理解,还包括跨学科的知识应用和推理能力。
- 多层次难度:
- C-eval的题目覆盖四个难度级别:初中、高中、大学和专业级,旨在评估模型在不同知识深度和推理复杂度下的表现。
- 问题设计与选题:
- 数据集中的问题涵盖多样化的主题,包括文学、历史、数学、物理、工程等多个领域。每个问题都经过精心设计,确保能够考察模型的知识理解、跨学科推理以及问题解决能力。
- 通过多层次问题,C-eval测试了模型在初级到高级学科上的推理能力,特别是多步骤推理和复杂问题的处理能力。
- 问题数量与学科分布:
- C-eval数据集包含多种类型的问题,跨越多个学科和难度层级,确保对基础模型进行全面评估。每个学科和难度级别的题目数量大致均衡,确保数据集的多样性和挑战性。
- 测试了多个基础模型:
- 研究评估了多个流行的基础模型,包括GPT-4、BERT、RoBERTa等,评估它们在C-eval数据集上的表现,特别是在中文问题理解和推理任务中的能力。
- 模型表现分析:
- GPT-4表现最佳,能够在所有难度级别和学科上表现出色,尤其是在高难度问题和跨学科推理问题上的表现最为突出。
- 其他模型在初中和高中的任务中表现较好,但在大学和专业级别的推理任务中,准确率显著下降。
- 跨学科推理挑战:
- 实验结果表明,跨学科推理是当前基础模型的一大挑战,特别是当涉及到复杂问题时,模型在知识整合和跨领域推理上的能力仍有很大提升空间。
- C-eval的数据集设计突显了模型在处理复杂知识点时的局限性,尤其是在高年级和专业级任务中,模型的表现参差不齐。
- C-eval为中文基础模型的评估提供了一个多层次、多学科的标准,尤其是在测试跨学科推理和复杂知识应用方面,提供了更高的挑战。
- 数据集通过涵盖实际的学科内容和考试级别,确保了模型在真实世界任务中的表现得以真实评估。与传统的数据集相比,C-eval更加贴合实际教育环境和应用需求。
- C-eval为基础模型的进一步改进提供了重要的反馈,尤其是在跨学科知识理解和推理能力上的提升,推动了模型在复杂任务中的应用。
- 增强推理能力:未来的研究可以专注于提升模型在跨学科推理中的能力,尤其是如何理解和应用复杂的跨学科知识。
- 增加应用场景的多样性:通过加入更多领域和难度的任务,进一步增强C-eval数据集的多样性,使其能够测试更多实际应用场景中的推理和理解能力。
- 扩展到其他语言:未来可以考虑将C-eval扩展到其他语言,特别是在多语言环境下的推理任务,推动多语言模型的发展。
- 现有LLMs评估基准的局限性:
- 随着大型语言模型(LLMs)能力的持续提升,现有的评估基准已逐渐难以满足对其多任务理解和推理能力的评估需求。尤其是在中文环境下,现有基准大多集中在少数特定任务,缺乏跨学科、多任务的综合评估。
- 研究目标:
- 提出并介绍CMMLU,这是一个综合性中文基准,旨在全面评估中文LLMs在多个学科和任务上的理解和推理能力。该基准涉及自然科学、社会科学、工程学和人文学科,提供了一个更广泛的评估框架。
- 多学科覆盖:
- CMMLU数据集涵盖了从自然科学到社会科学、工程学、人文学科等多个领域的任务,确保对LLMs进行全方位的测试,特别是在跨学科知识整合和推理能力方面。
- 多任务设计:
- 数据集中的任务包括但不限于文本理解、推理、数学、历史、哲学、政治学等,确保能够评估模型在多种类型任务中的表现。
- 问题设计与题目来源:
- CMMLU中的问题涵盖了从基础知识到高级推理的各种难度,设计时结合了多种真实世界的学科内容,确保任务的多样性和真实性。
- 每个问题都通过人工验证和校对,确保其质量,并符合各学科的标准。
- 问题数量与学科分布:
- CMMLU数据集包括超过20个学科的任务,涵盖多个难度级别,确保能够全面评估模型在各个学科和任务中的表现。
- 数据集设计考虑了学科之间的平衡性,确保每个领域的问题数量足够且具代表性。
- 测试了多种中文和多语言LLMs:
- 研究中对20多种现有的中文和多语言LLMs进行了评估,涵盖了包括GPT系列、BERT系列在内的多种大型模型,评估它们在CMMLU数据集上的表现。
- 模型表现分析:
- 在所有测试中,GPT-4和其他一些最新的大型语言模型在某些任务中表现优异,尤其是在涉及自然语言理解和推理任务时,准确率较高。
- 然而,大多数模型在跨学科、跨任务的任务中仍然存在明显的表现差距,尤其是在需要深度推理、复杂跨学科整合的任务中,模型的表现不尽如人意。
- 跨学科推理挑战:
- 结果表明,跨学科推理仍然是当前中文LLMs面临的主要挑战。尤其是在高难度问题和需要广泛知识背景的任务中,现有模型往往难以应对。
- CMMLU为中文LLMs提供了一个全新的挑战平台,通过涵盖多个学科和任务,评估了模型在复杂推理、知识整合和多任务处理方面的能力,推动了更强大模型的研究。
- 数据集设计注重实际应用中的任务和场景,确保对LLMs的评估更接近真实世界中的需求,避免了单一领域和简单任务的局限性。
- CMMLU为中文基础模型的开发和改进提供了有力的评估工具,特别是在跨学科知识的处理和复杂推理能力的提升方面。
- 增强多学科推理能力:未来的研究可以聚焦于提升模型在复杂跨学科任务中的推理能力,尤其是如何有效整合多个领域的知识来解决问题。
- 增加更多领域:未来可以通过增加更多学科和任务,扩展CMMLU数据集,使其能够更广泛地测试模型在不同类型问题上的表现,推动模型的通用性提升。
- 提升深度推理能力:未来的研究可以注重提升模型在长推理链、多步骤推理任务中的表现,特别是在面对复杂问题时的能力。
Note
部分内容借助了LLM生成,请酌情参考