diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..4c8a046
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,23 @@
+node_modules
+typings
+*.pyc
+.DS_Store
+package-lock.json
+mtp-ai-turing-tumble.iml
+.idea/
+out
+reinforcement_learning/wandb
+reinforcement_learning/tmp
+/out/
+/reinforcement_learning/tmp/
+.idea/*
+reinforcement_learning/wandb/*
+out/*
+reinforcement_learning/tmp/*
+*/META-INF/*
+MANIFEST.MF
+wandb_key_file
+LogFile.txt
+State.txt
+/reinforcement_learning/dataset_generators/rl_training_set.csv
+/reinforcement_learning/environments/envs/bugbit_env_backup.py
diff --git a/LICENSE b/LICENSE
index 7c8f7c8..b621ac1 100644
--- a/LICENSE
+++ b/LICENSE
@@ -18,4 +18,4 @@ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-SOFTWARE.
+SOFTWARE.
\ No newline at end of file
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..d45d938
--- /dev/null
+++ b/README.md
@@ -0,0 +1,64 @@
+# European Master Team Project - AI Turing Tumble
+
+> This repository holds the code that was developed during the European Master Team Project
+> in the spring semester of 2022 (EMTP 22). The project was supervised by
+> [Dr. Christian Bartelt](https://www.uni-mannheim.de/en/ines/about-us/researchers/dr-christian-bartelt/) and
+> [Jannik Brinkmann](https://www.linkedin.com/in/brinkmann-jannik/). The project team was
+> composed of students from the [Babeș-Bolyai University](https://www.ubbcluj.ro/en/)
+> in Cluj-Napoca, Romania, and the [University of Mannheim](https://www.uni-mannheim.de/), Germany.
+
+## Introduction
+
+In the game Turing Tumble, players construct mechanical computers that use the flow of marbles along a board to solve
+logic problems. As the board and its parts are Turing complete, which means that they can be used to express any
+mathematical function, an intelligent agent taught to solve a Turing Tumble challenge essentially learns how to write
+code according to a given specification.
+
+Following this logic, we taught an agent how to write a simple programme according to a minimal specification, using
+an abstracted version of the Turing Tumble board as reinforcement learning training environment. This is related to
+the emerging field of programme synthesis, as is for example applied in
+[GitHub’s CoPilot](https://github.com/features/copilot).
+
+## Participants
+
+### Babeș-Bolyai University
+
+* [Tudor Esan](https://github.com/TudorEsan) - B.Sc. Computer Science
+* [Raluca Diana Chis](https://github.com/RalucaChis) - M.Sc. Applied Computational Intelligence
+
+### University of Mannheim
+
+* [Roman Hess](https://github.com/romanhess98) - M.Sc. Data Science
+* [Timur Carstensen](https://github.com/timurcarstensen) - M.Sc. Data Science
+* [Julie Naegelen](https://github.com/jnaeg) - M.Sc. Data Science
+* [Tobias Sesterhenn](https://github.com/Tsesterh) - M.Sc. Data Science
+
+## Contents of this repository
+
+The project directory is organised in the following way:
+
+| Path | Role |
+|---------------------------|----------------------------------------------|
+| `docs/` | Supporting material to document the project |
+| `reinforcement_learning/` | Everything related to Reinforcement Learning |
+| `src/` | Java sources |
+| `ttsim/` | Source Code of the Turing Tumble Simulator |
+
+## Weights & Biases (wandb)
+We used [Weights & Biases](https://wandb.ai/) to log the results of our training:
+1. [Reinforcement Learning](https://wandb.ai/mtp-ai-board-game-engine/ray-tune-bugbit)
+2. [Pretraining](https://wandb.ai/mtp-ai-board-game-engine/Pretraining)
+3. [Connect Four](https://wandb.ai/mtp-ai-board-game-engine/connect-four)
+
+## Credits
+
+We used third-party software to implement the project. Namely:
+
+- **BugPlus** - [Dr. Christian Bartelt](https://www.uni-mannheim.de/en/ines/about-us/researchers/dr-christian-bartelt/)
+- **Turing Tumble Simulator** - [Jesse Crossen](https://github.com/jessecrossen/ttsim)
+
+## Final Project Presentation
+
+Link to video:
+[](https://www.youtube.com/watch?v=w501gf2MLFM)
+
diff --git a/docs/README.md b/docs/README.md
new file mode 100644
index 0000000..4fdf31c
--- /dev/null
+++ b/docs/README.md
@@ -0,0 +1,111 @@
+# Setup
+
+> **DISCLAIMER: this project is meant to be run on Linux or macOS machines. Windows is not supported
+> due to a scheduler conflict between JPype and Ray.**
+
+## Prerequisites
+
+1. An x86 machine running Linux or macOS (tested on Ubuntu 20.04 and macOS Monterey)
+2. A working, clean (i.e new / separate) conda ([miniconda3](https://docs.conda.io/en/latest/miniconda.html)
+ or [anaconda3](https://docs.anaconda.com/anaconda/install/)) installation
+3. [IntelliJ IDEA](https://www.jetbrains.com/idea/) (CE / Ultimate)
+
+## Installing dependencies
+
+1. Create and activate a new conda environment for python3.8 (`conda create -n mtp python=3.8` & `conda activate mtp`)
+2. Navigate to the project root and run `pip install -r requirements.txt`
+3. Run `pip install "ray[all]"` to install all dependencies for Ray
+
+## Python Setup
+
+1. In IntelliJ, open the project structure dialogue: `File -> Project Structure`
+2. In Modules, select the project and click `Add` and select `Python`
+3. In the `Python` tab, add a new Python interpreter by clicking on `...`
+4. In the newly opened dialogue, click on `+` and click `Add Python SDK...`
+5. In the dialogue, click on `Conda environment` and select the existing environment we created in the previous step
+6. Select the newly registered interpreter as the project interpreter and close out of the dialogue after
+ clicking `apply`
+7. Still in `Project Structure`, navigate to `Modules` and select the project: select the directories `src`
+ and `reinforcement_learning` and mark them as `Sources`. Click `Apply` and close out of the dialogue.
+
+## Compiling the project
+
+1. Make sure that the SDK and Language Level in the Project tab are set to 17 (i.e. openjdk-17)
+2. Open the Project Structure Dialogue in IntelliJ `File -> Project Structure`
+3. Select `Artifacts`
+4. Add a JAR file with dependencies
+5. Click on the folder icon and select `CF_Translated` in the next dialogue and click OK
+6. Click OK again and then in the artifacts overview, in the Output Layout tab, select the Python library and remove it
+7. Click on apply and OK
+8. Build the artifact: `Build -> Build Artifacts`
+9. In `reinforcement_learning/utilities/utilities.py`, make sure that the variable `artifact_directory` is set to the
+ folder that contains the compiled artifact. The variable `artifact_file_name` should be set to the name of the jar
+ file. (cf. image below: `artifact_directory = mtp_testing_jar` and `artifact_file_name = mtp-testing.jar`)
+
+
+
+
+## Weights & Biases
+
+We used [Weights & Biases](https://wandb.ai/) (wandb) to document our training progress and results. All training files
+in this project rely on wandb for logging. For the following you will need a wandb account and your wandb
+[API key](https://docs.wandb.ai/quickstart):
+
+1. Create a file named `wandb_key_file` in the `reinforcement_learning` directory
+2. Paste your wandb API key in the newly created file
+3. In the training files, adjust the wandb configuration to your wandb account (i.e. arguments such as `entity`,
+ `project`, and `group` should be modified accordingly)
+
+## Running the project
+
+> DISCLAIMER: the number of bugs used in pretraining, reinforcement learning, and the environment configuration **must**
+> be the same
+> To run the individual parts of the final project pipeline, follow the steps outlined below.
+
+> DISCLAIMER: the generation of Pretraining and RL training sets may take some time for *num_bugs > 6* and a large
+> number
+> of samples.
+
+### Pretraining
+
+#### Pretraining Sample Generation
+
+Run the `reinforcement_learning/dataset_generators > pretraining_dataset_generation.py` script in the terminal or
+execute the file in IntelliJ.
+The generated dataset(s) will be saved in `data/training_sets/pretraining_training_sets` as different `.pkl` files.
+Each training set is identified by the number of bugs and whether multiple_actions are allowed or not. If multiple
+actions
+are allowed, this means that in the training set there are samples where more then one edge have to be removed from the
+CF Matrix.
+
+#### Model Pretraining
+
+Run the `reinforcement_learning/custom_torch_models > rl_network_pretraining.py` script in the terminal or execute
+the file in IntelliJ.
+The script loads the created training dataset depending on the number of bugs and whether multiple actions are allowed.
+After the pretraining, the model is saved in `data/model_weights`.
+
+### Reinforcement Learning (RL)
+
+The RL part of the project is split up into two components: sample generation and training.
+
+#### Reinforcement Learning Sample Generation
+
+To generate RL samples, adjust the number of bugs and number of samples in the main function of
+`reinforcement_learning/dataset_generators > rl_trainingset_generation.py` and run the file. The generated training set
+will be saved
+as a `.pkl` file in `data/training_sets/rl_training_sets`.
+
+#### Reinforcement Learning Training
+
+Reinforcement learning training is done in `reinforcement_learning > train.py`:
+
+1. Set the path to your RL training set from the previous step in `global_config["training_set_path]`
+2. If you did generate a pretraining set and did pretrain, also adjust `global_config["pretrained_model_path"]`
+3. ***Optional***: if you want to initialise the learner with the pretrained model's weights, set the config parameter
+ in `global_config["pretraining"]` to `True`.
+
+### Connect Four
+
+For Connect Four please refer to the [Connect Four](connect-four.md) documentation.
diff --git a/docs/assets/Example_Challenge.png b/docs/assets/Example_Challenge.png
new file mode 100644
index 0000000..f1da239
Binary files /dev/null and b/docs/assets/Example_Challenge.png differ
diff --git a/docs/assets/TT_architecture_diagram.png b/docs/assets/TT_architecture_diagram.png
new file mode 100644
index 0000000..1b841e2
Binary files /dev/null and b/docs/assets/TT_architecture_diagram.png differ
diff --git a/docs/assets/TT_env_subdiagram.png b/docs/assets/TT_env_subdiagram.png
new file mode 100644
index 0000000..705ea77
Binary files /dev/null and b/docs/assets/TT_env_subdiagram.png differ
diff --git a/docs/assets/TT_transl_diagram.png b/docs/assets/TT_transl_diagram.png
new file mode 100644
index 0000000..d994ac8
Binary files /dev/null and b/docs/assets/TT_transl_diagram.png differ
diff --git a/docs/assets/blue_bit.svg b/docs/assets/blue_bit.svg
new file mode 100644
index 0000000..b73941a
--- /dev/null
+++ b/docs/assets/blue_bit.svg
@@ -0,0 +1,64 @@
+
+
+
+
+
+ image/svg+xml
+
+
+
+
+
+
diff --git a/docs/assets/blue_bits.svg b/docs/assets/blue_bits.svg
new file mode 100644
index 0000000..0c02024
--- /dev/null
+++ b/docs/assets/blue_bits.svg
@@ -0,0 +1 @@
+Control OutData Out Data In Control In 00 0 0 0 1 0 0 In pins Out pins Left 1 Right 1 Left 2 Right 2 In 1 In 2 00 0 0 0 1 0 0 In pins Out pins
+
+
+
+ image/svg+xml
+
+
+
+
+
+
diff --git a/docs/assets/green_edges.svg b/docs/assets/green_edges.svg
new file mode 100644
index 0000000..e54b386
--- /dev/null
+++ b/docs/assets/green_edges.svg
@@ -0,0 +1 @@
+
+
+
+
+ image/svg+xml
+
+
+
+
+
+
diff --git a/docs/assets/orange_edge.svg b/docs/assets/orange_edge.svg
new file mode 100644
index 0000000..4c5b8fa
--- /dev/null
+++ b/docs/assets/orange_edge.svg
@@ -0,0 +1,124 @@
+
+
+
+
+
+ image/svg+xml
+
+
+
+
+
+
diff --git a/docs/assets/out_directory.png b/docs/assets/out_directory.png
new file mode 100644
index 0000000..83c55ee
Binary files /dev/null and b/docs/assets/out_directory.png differ
diff --git a/docs/assets/physical_board.png b/docs/assets/physical_board.png
new file mode 100644
index 0000000..27f82b8
Binary files /dev/null and b/docs/assets/physical_board.png differ
diff --git a/docs/assets/spec.svg b/docs/assets/spec.svg
new file mode 100644
index 0000000..87ae9be
--- /dev/null
+++ b/docs/assets/spec.svg
@@ -0,0 +1 @@
+00 1 1 1 1 0 1 InputsOutputs 01 2 bits 4 bits 3 bits v alid invalid
+
+
+## Table of contents
+
+#### 1. [About](#about)
+
+#### 2. [Setup](#setup)
+
+#### 3. [Training](#training)
+
+#### 4. [GUI / Rollout](#gui--rollout)
+
+## About
+
+
+
+An exemplary challenge
+
+
+#### The BugBit Environment
+
+BugBit is an abstraction of the Turing Tumble board without restrictions like board size or gravity, devised
+by [Dr. Christian Bartelt](https://www.uni-mannheim.de/en/ines/about-us/researchers/dr-christian-bartelt/).
+Bugs represent the blue Bits from the physical game.
+The orange lines indicate the control flow along the BugBit programme, which equates the flow of the marbles along the
+bits on the board.
+Each Bug has a control-in pin at its top where the control flow (marble) can come in and two control-out pins at the
+bottom, where it can leave.
+If a Bug has internal state zero (the blue Bit is flipped to the left) the control flow will leave the Bug via the right
+control
+out pin.
+If it has state one (flipped to the right) the control flow will leave it via the left control-out pin.
+
+
+
+
+
+An Illustration of a Bug.
+The data-in and -out pin may be ignored, as they are only used internally to flip a Bit’s state after the control flow
+(the marble) passes through it
+
+
+Different Bugs can now be connected with each other to define more complex programmes.
+For example, the following physical Turing Tumble board can be represented by setting the connections
+between Bugs as shown below.
+
+
+
+
+
+A Turing Tumble Board and its BugBit abstraction
+
+
+#### The control flow matrix
+
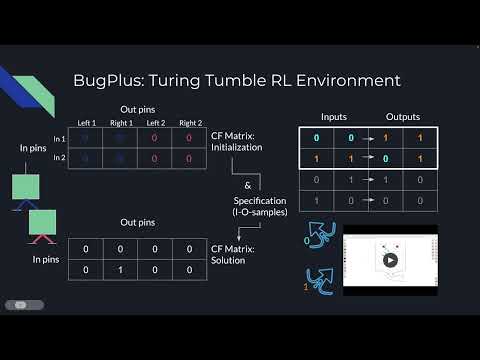
+How the Bugs are connected with each other is stored in the control flow matrix (CF matrix).
+Visualised below is a CF matrix for two Bugs. Rows indicate the control-in pins of the Bits,
+and columns indicate the control-out pins of the Bits. As each Bit has one control-in pin, but two control-out pins,
+we have twice as many columns as rows. If a cell contains a 1 in this matrix, it means that the corresponding in and out
+pins are
+connected. By setting 1s in the CF matrix we can define a programme, which we can later run.
+
+
+
+
+
+The control flow matrix
+
+
+#### Reducing the Problem Size
+
+The Turing Tumble Puzzle Book contains all kinds of challenges for the player. So the first step was to define a
+specific
+subset of the challenges to focus on. For the purpose of this project we limited ourselves to the following problem
+class:
+
+1. *We do not allow loops* We treat the board as if the switches at the bottom did not exist, so a challenge has to be
+ solved with a single marble.
+2. *The waterfall principle* While in the BugBit abstraction gravity does not matter, we only allow Bits’ control flows
+ to go into Bits with a higher indication number, i.e. Bits placed
+ below them on the physical Turing Tumble board. For example, Bit 1 can only be connected to Bit 2 and 3, Bit 2 can
+ only be
+ connected to Bit 3, and from Bit 3 the control flow can not go any further.
+
+This limitation reduces the complexity of valid programmes, making the reinforcement learning task more feasible.
+
+#### The Challenge – What the agent learns
+
+The observation space, i.e. what the agent perceives, is comprised of two components: a CF matrix and a specification.
+As we reduced the problem size to challenges that follow the waterfall principle, the **CF matrix can indeed only have
+non-zero entries in its lower triangular part**. Therefore, we can represent the CF matrix as a vector of length
+*n2 -n*, where n is the number of Bits.
+
+The specification consists of a set of input-output pairs, describing the Bit positions
+(flipped to the left or to the right) before and after the execution of the programme represented by the CF matrix.
+The following specification now defines that when we start our programme and both Bits are flipped to the left
+(state 0,0), after the programme has completed, they should both be pointing to the right (state 1, 1).
+The second row says that when we start our programme with both Bits pointed to the right (state 1, 1), we want the first
+Bit to be pointing to the left now (state 0) while the second Bit
+stays pointed to the right (state 1) after the programme has finished.
+
+
+
+
+
+A specification: Two input output pairs describing Bit positions before and after running the programme
+
+
+In summary, the agent is given a **specification and a CF matrix**, which it then has to modify such that the latter
+describes a programme which fulfills the former. So a programme, that, if we run
+it according to how it is represented in the matrix, will flip the Bits in the way fixed in our specification.
+
+The challenge that was just introduced can be solved by the agent by connecting the first with the second Bit via the
+right control-out pin, which results in the following CF matrix:
+
+
+
+
+
+The control flow matrix solving the specified challenge
+
+
+This results in the following Turing Tumble Board which, as can be seen, fulfils the specification.
+
+
+
+
+
+The solution of the challenge visualised
+
+
+##
+
+## 2. Technical Implementation n *** input-output pairs, we keep half.
+Using
+the expert play algorithm 'solver', we generate CF matrices from these incomplete specifications in a stepwise
+'waterfall principle' fashion as described in section 1.1. To create the final pretraining samples, we take these CF
+matrices and all their
+intermediate versions ('timeline') and randomly flip up to three entries in each, thereby adding or removing edges in
+the BugBit programme. We generate the target policy vector by identifying which changes need to be reverted to come back
+to the original state of the control flow matrix, or to progress in the 'timeline' according to the 'solver' algorithm.
+
+By learning how to delete superfluous edges/add edges which move the state of the CF matrix from one intermediate state
+to the next, the agent learns how to 'reflexively' execute the expert play algorithm.
+
+The reason why we only use half of each specification set as inputs to our training is that for the full set, there
+exists
+only one single correct CF matrix satisfying them. In such a setting, we wouldn't teach the agent creative problem
+solving and reinforcement learning would not make sense methodically.
+
+### 5.2. Generating RL Training Sets
+
+To create the reinforcement trainings data set, we first generate random ***n*** bit programmes and their corresponding
+full
+specification as above. We then randomly keep half of the input-output pairs of the specification. To get training
+examples of one to ***m*** steps away from a valid solution, we iteratively add/remove edges from the original
+programmes,
+that is, we flip entries in the CF matrix. The resulting training set can then be divided into degrees of difficulty by
+the maximum 'distance', i.e. amount of steps needed to reach a known solution, which will still fulfill the
+specification. Moving up in difficulty during the CL training process will then introduce samples with a larger '
+distance' into the RL training process
+
+## 6. Callbacks : Returns the list of seeds used in this env's random
+ number generators. The first value in the list should be the
+ "main" seed, or the value which a reproducer should pass to
+ 'seed'. Often, the main seed equals the provided 'seed', but
+ this won't be true if seed=None, for example.
+ """
+ self.np_random, seed = seeding.np_random(seed)
+ return [seed]
+
+ def close(self):
+ """
+ Close method of the environment. Not implemented for bugbit.
+ :return: None
+ """
+ pass
diff --git a/reinforcement_learning/environments/envs/connectfourmvc_env.py b/reinforcement_learning/environments/envs/connectfourmvc_env.py
new file mode 100644
index 0000000..681af67
--- /dev/null
+++ b/reinforcement_learning/environments/envs/connectfourmvc_env.py
@@ -0,0 +1,122 @@
+"""
+The Connect Four environment Python adaptation of the original Java Implementation (connectfour.ConnectFour.java)
+"""
+# standard library imports
+
+from typing import List
+
+# 3rd party imports
+import gym
+# noinspection PyPackageRequirements
+import jpype
+import numpy as np
+
+# local imports (i.e. our own code)
+# noinspection PyUnresolvedReferences
+from utilities import utilities
+
+
+# noinspection PyAbstractClass
+class ConnectFourMVC(gym.Env):
+ done: bool = False
+ reward: int = None
+ state: List[List[int]] = None
+ connectfour: jpype.JClass = None
+ config: str
+ info: dict = {}
+ view = None
+ winner: int = 0
+
+ metadata = {
+ "render.modes": ["human"]
+ }
+
+ def __init__(self):
+ """
+ Initialises the environment.
+
+ :return: None
+ """
+ self.winner: int = 0
+ self.action_space: gym.spaces.Space = gym.spaces.Discrete(7)
+ self.observation_space: gym.spaces.Space = gym.spaces.Box(0, 2, shape=(6, 7))
+ self.connectfour: jpype.JClass = jpype.JClass("connectfour.ConnectFour")()
+ # noinspection PyTypeChecker
+ self.state: np.ndarray = np.array(self.connectfour.reset())
+
+ def reset(self):
+ """
+ Resets the environment (e.g. after a game has ended)
+
+ :return:
+ """
+ self.reward = 0
+ self.done = False
+ return np.array(self.connectfour.reset())
+
+ def step(self, action: int) -> list:
+ """
+ Step function of the environment.
+
+ :param action: Integer representing the action to take
+ :return: state, reward, done, info
+ """
+ self.state, self.reward, self.done, self.info, winner = self.connectfour.step(action)
+ # noinspection PyTypeChecker
+ self.state = np.array(self.state)
+ self.reward = int(self.reward)
+ self.done = bool(self.done)
+ self.info = {}
+
+ return [self.state, self.reward, self.done, self.info]
+
+ def return_reward(self) -> int:
+ """
+ Returns the reward obtained in the current step
+
+ :return: An Integer describing the reward.
+ """
+ return self.reward
+
+ def return_done(self) -> bool:
+ """
+ Returns whether the game is over or not.
+
+ :return: A Boolean. True = Done, False = Not Done
+ """
+ return self.done
+
+ def return_winner(self) -> int:
+ """
+ Returns the winner of a finished game
+
+ :return: An integer indicating who won the game.
+ """
+ return self.winner
+
+ def get_greedy_action(self, agent_id: int) -> int:
+ """
+ Returns the next action of the greedy player.
+
+ :param agent_id: specifies which ´id´ the greedy agent is (1 or 2)
+ :return: int indicating the next action of the greedy player.
+ """
+ return int(self.connectfour.getGreedyAction(agent_id))
+
+ def interactive_step(self, action: int, agent_id: int) -> list:
+ """
+ Interactive step such that only one action is taken at a time (either RL agent or heuristic/greedy agent)
+
+ :param action: which column to place a token in
+ :param agent_id: which agent is placing the token (either [heuristic/greedy]/human or RL agent; i.e. 1 or 2
+ (some integer))
+ :return: returns the new state after taking the step
+ """
+ self.state, self.reward, self.done, self.info, winner = self.connectfour.step(action, agent_id)
+ # noinspection PyTypeChecker
+ self.state = np.array(self.state)
+ self.reward = int(self.reward)
+ self.done = bool(self.done)
+ self.info = {}
+
+ return [self.state, self.reward, self.done, self.info]
diff --git a/reinforcement_learning/setup.py b/reinforcement_learning/setup.py
new file mode 100644
index 0000000..1981ef3
--- /dev/null
+++ b/reinforcement_learning/setup.py
@@ -0,0 +1,13 @@
+from setuptools import setup
+
+setup(
+ name="bugbit_v0",
+ version="1.0.0",
+ install_requires=["gym"]
+)
+
+setup(
+ name="connectfourmvc_v0",
+ version="1.0.0",
+ install_requires=["gym"]
+)
diff --git a/reinforcement_learning/train.py b/reinforcement_learning/train.py
new file mode 100644
index 0000000..ed6ce94
--- /dev/null
+++ b/reinforcement_learning/train.py
@@ -0,0 +1,108 @@
+"""
+Training file for the BugBit environment.
+"""
+
+# standard library imports
+import os
+
+# 3rd party imports
+import torch
+import ray
+from ray.tune.integration.wandb import WandbLoggerCallback
+from ray import tune
+from ray.tune.schedulers import ASHAScheduler
+import pandas as pd
+
+# local imports (i.e. our own code)
+# noinspection PyUnresolvedReferences
+from utilities import utilities
+# noinspection PyUnresolvedReferences
+from utilities import registration
+from callbacks.custom_metric_callbacks import CustomMetricCallbacks
+
+# training set path and pretrained_model_path must point to the respective files in the data directory
+
+num_bugs: int = 3
+sample_size = int((2 ** num_bugs) / 2)
+rl_training_set_file_name: str = ""
+pretrained_model_file_name: str = ""
+
+global_config = {
+ "training_set_path": f"{os.getenv('REINFORCEMENT_LEARNING_DIR')}/data/training_sets/rl_training_sets/"
+ f"{rl_training_set_file_name}",
+ "pretraining": True,
+ "pretrained_model_path": f"{os.getenv('REINFORCEMENT_LEARNING_DIR')}/data/model_weights"
+ f"/{pretrained_model_file_name}",
+}
+
+if not rl_training_set_file_name or (global_config["pretraining"] and not pretrained_model_file_name):
+ raise ValueError("rl_training_set_file_name and/or pretrained_model_path must be set")
+
+if __name__ == "__main__":
+ # load training set from pickle
+ training_set = pd.read_pickle(global_config["training_set_path"])
+
+ # initialise ray (set local_mode to True for debugging)
+ ray.init()
+
+ # running the experiment
+ tune.run(
+ "PPO",
+ verbose=0, # verbosity of the console output during training
+ # checkpointing settings
+ checkpoint_freq=5, # after every 5 epochs, a checkpoint is created
+ local_dir=f"{os.getenv('REINFORCEMENT_LEARNING_DIR')}/data/agent_checkpoints/bugbit",
+ checkpoint_score_attr="custom_metrics/game_history_mean",
+ keep_checkpoints_num=1, # how many checkpoints to keep in the end
+ num_samples=1, # number of simultaeous agents to train
+ scheduler=ASHAScheduler(
+ metric="custom_metrics/game_history_mean",
+ time_attr="training_iteration",
+ mode="max",
+ max_t=81,
+ reduction_factor=3,
+ brackets=1
+ ), # scheduler for training (i.e. predictive termination)
+ callbacks=[
+ # adjust the entries here to conform to your wandb environment
+ # cf. https://docs.wandb.ai/ and https://docs.ray.io/en/master/tune/examples/tune-wandb.html
+ WandbLoggerCallback(
+ api_key_file="wandb_key_file",
+ project="ray-tune-bugbit",
+ entity="mtp-ai-board-game-engine",
+ group="final-submission-testing",
+ ),
+ ],
+ # trainer config
+ config={
+ "callbacks": CustomMetricCallbacks,
+ "num_envs_per_worker": 1, # how many environments to run in parallel per worker (read: CPU thread)
+ "num_workers": 1, # how many CPU threads are used for training one agent
+ "framework": "torch", # framework to use for training (i.e. PyTorch or TensorFlow)
+ "env": "bugbit-v0", # name of the environment which is used for training
+ # config of the neural network
+ # if pretraining=True: the pretrained model is used for initialisation and hence must have the same config
+ # as below. Else: the model is initialised with random weights and one can modify the model config as needed.
+ "model": {
+ "custom_model": "custom_torch_fcnn",
+ "custom_model_config": {
+ "fcnet_hiddens": [256, 256, 256],
+ "fcnet_activation": torch.nn.ReLU,
+ "no_final_layer": False,
+ "vf_share_layers": False,
+ "free_log_std": False,
+ "pretraining": global_config["pretraining"],
+ "pretrained_model_path": global_config["pretrained_model_path"],
+ },
+ },
+ # bugbit gym environment config
+ "env_config": {
+ "n_bugs": num_bugs, # number of bugs
+ "training_set": training_set,
+ "max_steps": 3, # the maximum number of steps before the game is terminated
+ "sample_size": sample_size, # MUST be set to (n_bugs^2)/2
+ "pretraining": global_config["pretraining"],
+ "pretrained_model_path": global_config["pretrained_model_path"],
+ }
+ },
+ )
diff --git a/reinforcement_learning/translators/__init__.py b/reinforcement_learning/translators/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/reinforcement_learning/translators/assets/defaultState.png b/reinforcement_learning/translators/assets/defaultState.png
new file mode 100644
index 0000000..41cff1e
Binary files /dev/null and b/reinforcement_learning/translators/assets/defaultState.png differ
diff --git a/reinforcement_learning/translators/assets/long_board.png b/reinforcement_learning/translators/assets/long_board.png
new file mode 100644
index 0000000..07e5e6a
Binary files /dev/null and b/reinforcement_learning/translators/assets/long_board.png differ
diff --git a/reinforcement_learning/translators/assets/newDefaultState.png b/reinforcement_learning/translators/assets/newDefaultState.png
new file mode 100644
index 0000000..8cf4617
Binary files /dev/null and b/reinforcement_learning/translators/assets/newDefaultState.png differ
diff --git a/reinforcement_learning/translators/assets/newDefaultState2.png b/reinforcement_learning/translators/assets/newDefaultState2.png
new file mode 100644
index 0000000..b81f335
Binary files /dev/null and b/reinforcement_learning/translators/assets/newDefaultState2.png differ
diff --git a/reinforcement_learning/translators/aux_image_to_code.py b/reinforcement_learning/translators/aux_image_to_code.py
new file mode 100644
index 0000000..7d3997f
--- /dev/null
+++ b/reinforcement_learning/translators/aux_image_to_code.py
@@ -0,0 +1,776 @@
+"""
+This file contains the translator (T2) from a matrix representation of a Turing Tumble Board (as can be obtained from
+the Turing Tumble Simulator as a png image) to BugBit code that is executed via jpype.
+
+"""
+
+# standard library imports
+import os
+from typing import List
+import json
+import pickle
+
+# 3rd party imports
+# noinspection PyPackageRequirements
+import jpype
+import numpy as np
+
+# local imports
+# noinspection PyUnresolvedReferences
+from utilities import utilities
+
+# get java classes
+NegBugsBasicArithmetic = jpype.JClass(
+ "de.bugplus.examples.development.NegBugsBasicArithmetic"
+)
+BugplusLibrary = jpype.JClass("de.bugplus.specification.BugplusLibrary")
+BugplusProgramSpecification = jpype.JClass(
+ "de.bugplus.specification.BugplusProgramSpecification"
+)
+BugplusProgramImplementation = jpype.JClass(
+ "de.bugplus.development.BugplusProgramImplementation"
+)
+BugplusProgramInstanceImpl = jpype.JClass(
+ "de.bugplus.development.BugplusProgramInstanceImpl"
+)
+BugplusThread = jpype.JClass("de.bugplus.development.BugplusThread")
+BugplusDevelopment = jpype.JPackage("de.bugplus.development")
+
+logfile = open('logfile.txt', "w")
+
+
+class Translator:
+ # The identifying number for each piece and field
+ _left_edge_rep: int = 1
+ _right_edge_rep: int = 2
+ _bidir_edge_rep: int = 3
+ _gear_rep: int = 4
+ _zero_bit_rep: int = 5
+ _stopping_pin_rep: int = 6
+ _zero_gearbit_rep: int = 7
+ _one_gearbit_rep: int = 8
+ _one_bit_rep: int = 9
+
+ # fields
+ _invalid_field: int = -100
+
+ # board size
+ _board_shape: tuple = (11, 11)
+
+ # other class variables
+ matrix: np.ndarray = np.zeros(shape=_board_shape)
+ function_library: None = None
+ bug_counter: int = 0
+ specification: BugplusProgramSpecification = None
+ challenge_implementation: BugplusProgramImplementation = None
+ bug_matrix: np.array = np.zeros(shape=_board_shape, dtype=object)
+ file_write: bool = False
+
+ bugplus_development_path: str = f"{os.getenv('REINFORCEMENT_LEARNING_DIR')}/../src/de/bugplus/examples/development/"
+
+ # for the translation into a simple CF-Matrix
+ num_bugs: int = 0
+
+ def matrix_to_bugbit_code(self, mtrx: str):
+ """
+ Takes a matrix representing the board and turns it into executable BugBit code
+
+ :param mtrx: A representation of a Turing Tumble board
+ :return: None
+ """
+ # decode the matrix
+ mtrx = json.loads(mtrx)
+ mtrx = np.array(mtrx["array"])
+
+ # the blueprint of the java file that can run a BugPlus program is copied into the Challenge.java file
+ with open(self.bugplus_development_path + "Blueprint.txt", "r") as template:
+ blueprint = template.readlines()
+ with open(
+ self.bugplus_development_path + "Challenge.java", "w"
+ ) as challenge:
+ for b in blueprint:
+ challenge.write(b)
+ # run the blueprint in python via JPype
+ self.matrix: np.array = mtrx
+ # self.write_to_file(f"Matrix: {self.matrix}")
+ self.function_library = BugplusLibrary.getInstance()
+ negation_bug_implementation = (
+ BugplusDevelopment.BugplusNEGImplementation.getInstance()
+ )
+ self.function_library.addSpecification(
+ negation_bug_implementation.getSpecification()
+ )
+
+ self.specification = BugplusProgramSpecification.getInstance(
+ "T2_Code", 0, 2, self.function_library
+ )
+
+ # additionally, write to file
+ self.write_to_file(
+ 'BugplusProgramSpecification T2_Code_specification = BugplusProgramSpecification.getInstance'
+ '("T2_Code_Instance", 0, 2, myFunctionLibrary); '
+ )
+
+ self.challenge_implementation = self.specification.addImplementation()
+ self.write_to_file(
+ "BugplusProgramImplementation T2_Code_Implementation = T2_Code_specification.addImplementation();"
+ )
+ # add a negation bug for each bit on the board
+ for i in self.find_bits():
+ self.bug_matrix[i[0], i[1]] = self.addNegBug()
+ self.num_bugs += 1
+
+ # create CF Matrix:
+ self.cf_matrix = np.zeros(shape=(self.num_bugs, 2 * self.num_bugs), dtype=np.int)
+
+ # connect the control in flow of the framework program to the first bit that will be active when starting a game
+ try:
+ self.connect_starting_bit()
+ except Exception:
+ self.write_to_file("An error happened when connecting the ControlInInterface")
+
+ # control flow: connect the bugs with each other
+ try:
+ self.connect_bits()
+ except Exception:
+ self.write_to_file("Bug in Connect Blue bits")
+
+ # data flow: connect the bugs with each other
+ try:
+ self.synchronize_connected_gear_bits()
+ except Exception as e:
+ self.write_to_file("Bug in Connect Coherent Components")
+ self.write_to_file(str(e))
+
+ # implement an instance of our BugPlus program
+ challenge_instance = self.challenge_implementation.instantiate()
+ self.write_to_file(
+ "BugplusInstance challengeInstance = T2_Code_Implementation.instantiate();"
+ )
+
+ t2_code_instance_impl = challenge_instance.getInstanceImpl()
+ self.write_to_file(
+ "BugplusProgramInstanceImpl T2_Code_Instance_Impl = challengeInstance.getInstanceImpl();"
+ )
+
+ # flip each bit corresponding to its starting state
+ bug_pos = self.find_bits()
+ for pos in bug_pos:
+ id = self.bug_matrix[pos]
+ value = 0
+
+ if self.matrix[pos] in [self._one_bit_rep, self._one_gearbit_rep]:
+ value = 1
+ t2_code_instance_impl.getBugs().get(id).setInternalState(value)
+ self.write_to_file(
+ f'T2_Code_Instance_Impl.getBugs().get("{id}").setInternalState({value});'
+ )
+
+ # create a thread that can run the program via JPype
+ new_thread = BugplusThread.getInstance()
+ self.write_to_file("BugplusThread newThread = BugplusThread.getInstance();")
+ new_thread.connectInstance(challenge_instance)
+ self.write_to_file("newThread.connectInstance(challengeInstance);")
+
+ # run the program via JPype
+ self.write_to_file("newThread.start();")
+
+ # print information regarding the bits' states and call counters
+ ids = []
+ for pos in bug_pos:
+ ids.append(self.bug_matrix[pos])
+
+ self.write_to_file(
+ "LinkedList challengeBugs = new LinkedList();"
+ )
+
+ for id in ids:
+ print(
+ f"Internal State: {id} : \t {t2_code_instance_impl.getBugs().get(id).getInternalState()}"
+ )
+ print(
+ f"Call Counter: {id} : \t {t2_code_instance_impl.getBugs().get(id).getCallCounter()}"
+ )
+
+ self.write_to_file(
+ f'System.out.println("Internal State " + "{id}" + ": \t" + T2_Code_Instance_Impl.getBugs().get("{id}")'
+ f'.getInternalState());'
+ )
+ self.write_to_file(
+ f'System.out.println("Call Counter " + "{id}" + ": \t" + T2_Code_Instance_Impl.getBugs().get("{id}")'
+ f'.getCallCounter() + "\\n");'
+ )
+
+ with open('CF_Matrix.pkl', 'wb') as handle:
+ pickle.dump(self.cf_matrix, handle, protocol=pickle.HIGHEST_PROTOCOL)
+
+ def connect_bits(self):
+ """
+ Connects the control flow of the bits.
+
+ :return: None
+ """
+
+ # get all positions with bits
+ bit_positions = self.find_bits()
+
+ # using 2 individual buckets (one red one blue)
+ # blue_bucket_out = (0, int((self._BOARD_SHAPE[1] + 1) / 4))
+ # red_bucket_out = (0, int(self._BOARD_SHAPE[1] - (self._BOARD_SHAPE[1] + 1) / 4 - 1))
+
+ # using 1 single shared bucket in the top center of the board
+ blue_bucket_out = (0, int(self._board_shape[1] / 2))
+ red_bucket_out = blue_bucket_out
+
+ # for each bit
+ for current_pos in bit_positions:
+
+ # the current momentum
+ momentum_right_next_l = False
+ momentum_right_next_r = True
+
+ # assign coordinates for bottom left and bottom right of bit
+ next_l = (current_pos[0] + 1, current_pos[1] - 1)
+ next_r = (current_pos[0] + 1, current_pos[1] + 1)
+
+ # check if next position is out of bounds
+ if next_l[1] < 0 or next_l[1] > self._board_shape[1] - 1:
+ next_l = None
+ if next_r[1] < 0 or next_r[1] > self._board_shape[1] - 1:
+ next_r = None
+ if self.matrix[next_l[0], next_l[1]] == -100:
+ next_l = None
+ if self.matrix[next_r[0], next_r[1]] == -100:
+ next_r = None
+
+ # all bits that will be implemented as bugs
+ mask_list = [
+ self._one_bit_rep,
+ self._zero_bit_rep,
+ self._one_gearbit_rep,
+ self._zero_gearbit_rep,
+ self._stopping_pin_rep,
+ ]
+
+ # exit bit to the left
+ if next_l:
+ # as long as we don't arrive at the next bit
+ while self.matrix[next_l] not in mask_list:
+ # check if we are in second to last row
+ if next_l[0] == self._board_shape[0] - 2:
+ # specify which switch will be activated
+ if next_l[1] in [0, 2]:
+ next_l = blue_bucket_out
+ momentum_right_next_l = True
+ continue
+ elif next_l[1] in [6, 8]:
+ next_l = red_bucket_out
+ momentum_right_next_l = True
+ continue
+ elif (
+ next_l[1] == 4
+ and self.matrix[next_l] == self._left_edge_rep
+ ):
+ next_l = blue_bucket_out
+ momentum_right_next_l = True
+ continue
+ elif (
+ next_l[1] == 6
+ and self.matrix[next_l] == self._right_edge_rep
+ ):
+ next_l = red_bucket_out
+ momentum_right_next_l = True
+ continue
+
+ # check if we are in last row
+ elif next_l[0] == self._board_shape[0] - 1:
+ # assign which switch will be activated
+ if next_l[1] != 5:
+ next_l = None
+ raise AssertionError(
+ "This is an error. This coordinate should never appear (next_l)."
+ )
+
+ elif self.matrix[next_l] == self._left_edge_rep:
+ next_l = blue_bucket_out
+ momentum_right_next_l = True
+ continue
+ elif self.matrix[next_l] == self._right_edge_rep:
+ next_l = red_bucket_out
+ momentum_right_next_l = False
+ continue
+ # normal case: check what next edge will be
+ # green edges
+ if self.matrix[next_l] == self._right_edge_rep:
+ next_l = (next_l[0] + 1, next_l[1] + 1)
+ momentum_right_next_l = True
+ elif self.matrix[next_l] == self._left_edge_rep:
+ next_l = (next_l[0] + 1, next_l[1] - 1)
+ momentum_right_next_l = False
+ # orange bidirectional edge
+ elif self.matrix[next_l] == self._bidir_edge_rep:
+ if momentum_right_next_l:
+ next_l = (next_l[0] + 1, next_l[1] + 1)
+ else:
+ next_l = (next_l[0] + 1, next_l[1] - 1)
+ # check if next position will be out of bounds (if we follow edge)
+ if next_l[1] < 0 or next_l[1] > self._board_shape[1] - 1:
+ next_l = None
+ raise AssertionError(
+ "This is an error. Next next_l position is out of bounds."
+ )
+
+ if self.matrix[next_l[0], next_l[1]] == -100:
+ next_l = None
+ raise AssertionError(
+ "This is an error. Next next_l position is out of bounds."
+ )
+
+ # we reached the next bit
+ if next_l:
+
+ # assign ids of the bits to connect
+ id_1 = self.bug_matrix[current_pos]
+ id_2 = self.bug_matrix[next_l]
+
+ if type(id_2) != str:
+ self.challenge_implementation.connectControlOutInterface(id_1, 0, 0)
+ self.challenge_implementation.connectControlOutInterface(id_1, 0, 1)
+ self.write_to_file(
+ f'T2_Code_Implementation.connectControlOutInterface("{id_1}", 0, 0);'
+ )
+ self.write_to_file(
+ f'T2_Code_Implementation.connectControlOutInterface("{id_1}", 0, 1);'
+ )
+
+ else:
+ self.challenge_implementation.addControlFlow(id_1, 0, id_2)
+ self.write_to_file(
+ f'T2_Code_Implementation.addControlFlow("{id_1}", 0, "{id_2}");'
+ )
+
+ # reparse ids:
+ i1 = int(id_1.split("_")[1])
+ i2 = int(id_2.split("_")[1])
+
+ # set 1 in CF Matrix
+ self.cf_matrix[i2, 2 * i1] = 1
+
+ # exit bit to the right
+ if next_r:
+ # as long as we don't arrive at the next bit
+ while self.matrix[next_r] not in mask_list:
+ # specify which switch will be activated
+ if next_r[0] == self._board_shape[0] - 2:
+ if next_r[1] in [0, 2]:
+ next_r = blue_bucket_out
+ momentum_right_next_r = True
+ continue
+ elif next_r[1] in [6, 8]:
+ next_r = red_bucket_out
+ momentum_right_next_r = True
+ continue
+ elif (
+ next_r[1] == 4
+ and self.matrix[next_r] == self._left_edge_rep
+ ):
+ next_r = blue_bucket_out
+ momentum_right_next_r = True
+ continue
+ elif (
+ next_r[1] == 6
+ and self.matrix[next_r] == self._right_edge_rep
+ ):
+ next_r = red_bucket_out
+ momentum_right_next_r = True
+ continue
+
+ # check if we are in last row
+ elif next_r[0] == self._board_shape[0] - 1:
+ # assign which swith will be activated
+ if next_r[1] != 5:
+ next_r = None
+ raise AssertionError(
+ "This is an error. This coordinate should never appear (next_r)."
+ )
+ elif self.matrix[next_r] == self._left_edge_rep:
+ next_r = blue_bucket_out
+ momentum_right_next_r = True
+ continue
+ elif self.matrix[next_r] == self._right_edge_rep:
+ next_r = red_bucket_out
+ momentum_right_next_r = False
+ continue
+
+ # usual case: check what next edge will be
+ # green edges
+ elif self.matrix[next_r] == self._right_edge_rep:
+ next_r = (next_r[0] + 1, next_r[1] + 1)
+ momentum_right_next_r = True
+ elif self.matrix[next_r] == self._left_edge_rep:
+ next_r = (next_r[0] + 1, next_r[1] - 1)
+ momentum_right_next_r = False
+
+ # orange bidirectional edge
+ elif self.matrix[next_r] == self._bidir_edge_rep:
+ if momentum_right_next_r:
+ next_r = (next_r[0] + 1, next_r[1] + 1)
+ else:
+ next_r = (next_r[0] + 1, next_r[1] - 1)
+
+ # check if next position will be out of bounds (if we follow edge)
+ if next_r[1] < 0 or next_r[1] > self._board_shape[1] - 1:
+ next_r = None
+ raise AssertionError(
+ "This is an error. Next next_r position is out of bounds."
+ )
+ if self.matrix[next_r[0], next_r[1]] == -100:
+ next_r = None
+ raise AssertionError(
+ "This is an error. Next next_r position is out of bounds."
+ )
+
+ # we reached the next bit
+ if next_r:
+ id_1 = self.bug_matrix[current_pos]
+ id_2 = self.bug_matrix[next_r]
+ # assign ids of the bits to connect
+ if type(id_2) != str:
+ self.challenge_implementation.connectControlOutInterface(id_1, 1, 0)
+ self.challenge_implementation.connectControlOutInterface(id_1, 1, 1)
+ self.write_to_file(
+ f'T2_Code_Implementation.connectControlOutInterface("{id_1}", 1, 0);'
+ )
+ self.write_to_file(
+ f'T2_Code_Implementation.connectControlOutInterface("{id_1}", 1, 1);'
+ )
+ else:
+ self.challenge_implementation.addControlFlow(id_1, 1, id_2)
+ # self.addControlFlow(id_1, 1, id_2)
+ self.write_to_file(
+ f'T2_Code_Implementation.addControlFlow("{id_1}", 1, "{id_2}");'
+ )
+ # reparse ids:
+ i1 = int(id_1.split("_")[1])
+ i2 = int(id_2.split("_")[1])
+ # set 1 in CF Matrix
+ self.cf_matrix[i2, 2 * i1 + 1] = 1
+
+ def connect_starting_bit(self):
+ """
+ Connects the initial control flow of the interface with the first bit
+
+ :return: None
+ """
+
+ # define the position just below the blue bucket
+ starting_pos = (0, int(self._board_shape[1] / 2))
+ next_pos = starting_pos
+ momentum_right = True
+
+ # follow the edges until we encounter a bit
+ while next_pos not in self.find_bits():
+
+ # follow green edges
+ if self.matrix[next_pos] == self._right_edge_rep:
+ next_pos = (next_pos[0] + 1, next_pos[1] + 1)
+ momentum_right = True
+ elif self.matrix[next_pos] == self._left_edge_rep:
+ next_pos = (next_pos[0] + 1, next_pos[1] - 1)
+ momentum_right = False
+
+ # follow orange edges
+ elif self.matrix[next_pos] == self._bidir_edge_rep:
+ if momentum_right:
+ next_pos = (next_pos[0] + 1, next_pos[1] + 1)
+ else:
+ next_pos = (next_pos[0] + 1, next_pos[1] - 1)
+
+ # connect the control flow of the interface with the bit that will be activated first when starting the program
+ start_id = self.bug_matrix[next_pos]
+ self.connectControlInInterface(start_id)
+
+ def connect_gear_bits(self, gear_bit_pos: tuple) -> List[tuple]:
+ """
+ Identifies gear bits that are connected via gears
+
+ :param gear_bit_pos: The position of a single gearbit on the board
+ :return: a list of the gear bits that are connected via gears
+ """
+
+ # check for gears and gear bits directly connected with input gear bit
+ connected_components = [gear_bit_pos]
+ list_size_increase = True
+
+ # as long as we keep finding neighbouring gears or gear bits
+ while list_size_increase:
+ list_size_increase = False
+
+ # for all gears and gear bits already in the list
+ for component in connected_components:
+
+ # check in all four directions for neighboring gears or gearbits
+ above_pos = (component[0] - 1, component[1])
+ below_pos = (component[0] + 1, component[1])
+ right_pos = (component[0], component[1] + 1)
+ left_pos = (component[0], component[1] - 1)
+
+ # if a gear or gear bit is found, add it to the list
+ if self.check_gear_or_gearbit(above_pos):
+ if above_pos not in connected_components:
+ connected_components.append(above_pos)
+ list_size_increase = True
+
+ if self.check_gear_or_gearbit(below_pos):
+ if below_pos not in connected_components:
+ connected_components.append(below_pos)
+ list_size_increase = True
+
+ if self.check_gear_or_gearbit(right_pos):
+ if right_pos not in connected_components:
+ connected_components.append(right_pos)
+ list_size_increase = True
+
+ if self.check_gear_or_gearbit(left_pos):
+ if left_pos not in connected_components:
+ connected_components.append(left_pos)
+ list_size_increase = True
+
+ # filter out the gear bits in the list connecting gear bits and gears
+ connected_gear_bits: List[tuple] = []
+ gear_bits = self.find_gear_bits()
+ for comp in connected_components:
+ if comp in gear_bits:
+ connected_gear_bits.append(comp)
+
+ # return the list of gear_bits whose data flows have to be connected
+ return connected_gear_bits
+
+ def synchronize_connected_gear_bits(self):
+ """
+ Connects the data flows of all gear bits that are connected via gears
+
+ :return:None
+ """
+
+ all_gear_bits_until_now = []
+
+ # for each gear bit on the board:
+ for gear_bit_pos in self.find_gear_bits():
+ # self.write_to_file(f"GearbitPos: {gear_bit_pos}")
+
+ # if the gear bit is not already in the list
+ if gear_bit_pos not in all_gear_bits_until_now:
+ try:
+ # find all gear bits connected to current gear bit
+ connected_comps = self.connect_gear_bits(gear_bit_pos)
+ except Exception as e:
+ self.write_to_file("Bug in connect_gear_bits")
+ self.write_to_file(str(e))
+ raise UserWarning(e)
+
+ # add all identified gear bits connected to current gear bit to the list
+ for pos in connected_comps:
+ try:
+ all_gear_bits_until_now.append(pos)
+ except Exception as e:
+ self.write_to_file(str(e))
+ try:
+
+ # obtain the ids of the connected gear bit-bugs
+ ids = [self.bug_matrix[conn_comps] for conn_comps in connected_comps]
+ except Exception as e:
+ self.write_to_file("Error in ids = self.bugMatrix(...)")
+ self.write_to_file(str(e))
+ raise UserWarning(e)
+
+ # connect the connected gear bit-bugs
+ for id1 in ids:
+ for id2 in ids:
+ self.challenge_implementation.addDataFlow(id1, id2, 0)
+ self.write_to_file(
+ f'T2_Code_Implementation.addDataFlow("{id1}", "{id2}", 0);'
+ )
+
+ def check_gear_or_gearbit(self, pos: tuple) -> bool:
+ """
+ checks if a position contains a gear or a gear bit
+
+ :param pos: a position on the board
+ :return: A Boolean: True if position contains a gear or a gear bit, otherwise False
+ """
+
+ # check if the position to check is out of bounds
+ if pos[1] < 0 or pos[1] > self._board_shape[1] - 1 or pos[0] < 0 or pos[0] > self._board_shape[0] - 1:
+ return False
+
+ # check if the position contains a gear or a gear bit
+ elif self.matrix[pos] in [
+ self._one_gearbit_rep,
+ self._zero_gearbit_rep,
+ self._gear_rep,
+ ]:
+ return True
+ else:
+ return False
+
+ def find_bits(self) -> List[tuple]:
+ """
+ Finds the positions of all bits on the board (normal bits AND gear bits).
+
+ :return: a list containing the positions of all bits on the board
+ """
+
+ indices = np.where(
+ (
+ (self.matrix == self._zero_bit_rep)
+ | (self.matrix == self._one_bit_rep)
+ | (self.matrix == self._one_gearbit_rep)
+ | (self.matrix == self._zero_gearbit_rep)
+ )
+ )
+ ind_list: List[tuple] = []
+ for i in range(len(indices[0])):
+ ind_list.append((indices[0][i], indices[1][i]))
+ return ind_list
+
+ def find_gear_bits(self) -> List[tuple]:
+ """
+ Finds the positions of all gear bits on the board (ONLY gear bits).
+
+ :return: the positions of all gear bits on the board
+ """
+ indices = np.where(
+ (
+ (self.matrix == self._one_gearbit_rep)
+ | (self.matrix == self._zero_gearbit_rep)
+ )
+ )
+ ind_list: List[tuple] = []
+ for i in range(len(indices[0])):
+ ind_list.append((indices[0][i], indices[1][i]))
+ return ind_list
+
+ def write_to_file(self, text: str):
+ """
+ Writes a string into a java file that can then be executed later.
+
+ :param text: Java Code as a string
+ :return: None
+ """
+
+ # read the content of the java file
+ with open(self.bugplus_development_path + "Challenge.java", "r") as f:
+ contents = f.readlines()
+
+ # add the new text to the lower end of the java file content
+ contents[-3] = contents[-3] + "\t\t" + text + "\n"
+
+ # write the modified content back into the java file
+ with open(self.bugplus_development_path + "Challenge.java", "w") as f:
+ for c in contents:
+ f.write(c)
+
+ def addNegBug(self) -> str:
+ """
+ Adds a negation bug to the program.
+
+ :return: The ID of the newly added bug as a string
+ """
+
+ # add a new bug
+ self.challenge_implementation.addBug("!", f"!_{self.bug_counter}")
+ self.write_to_file(
+ f'T2_Code_Implementation.addBug("!", "!_{self.bug_counter}");'
+ )
+
+ # connect the data flow of the bug with itself
+ self.challenge_implementation.addDataFlow(
+ f"!_{self.bug_counter}", f"!_{self.bug_counter}", 0
+ )
+ self.write_to_file(
+ f'T2_Code_Implementation.addDataFlow("!_{self.bug_counter}", "!_{self.bug_counter}", 0);'
+ )
+
+ # return the id of the newly added bug
+ self.bug_counter += 1
+ return f"!_{self.bug_counter - 1}"
+
+ def addDataFlow(
+ self,
+ id_source_bug: str,
+ id_target_bug: str,
+ index_data_in: int
+ ):
+ """
+ Adds a data flow from a given source bug to a given target bug
+
+ :param id_source_bug: the id of the source bug
+ :param id_target_bug:the id of the target bug
+ :param index_data_in: the index of the data in pin that should be used to connect the bugs (0 or 1)
+ :return: None
+ """
+ self.challenge_implementation.addDataFlow(id_source_bug, id_target_bug, index_data_in)
+
+ def connectDataInInterface(
+ self,
+ id_internal_bug: str,
+ index_internal_data_in: int,
+ index_external_data_in_interface: int,
+ ):
+ """
+ Connects a data in pin of an internal bug to the data in pin of the external interface
+
+ :param id_internal_bug: the id of the internal bug as it is defined for the Java Bugplus Code (e.g. "!_2")
+ :param index_internal_data_in: defines the data in pin of the internal bug that should be connected to the
+ DataInInterface. 0 or 1
+ :param index_external_data_in_interface: defines the index of the data in pin of the external bug
+ (DataInInterface) that should be connected to the internal Bug. 0 or 1
+ :return: None
+ """
+ self.challenge_implementation.connectDataInInterface(
+ id_internal_bug, index_internal_data_in, index_external_data_in_interface
+ )
+
+ def connectDataOutInterface(self, id_internal_bug: str):
+ """
+ Connects a data out pin of an internal bug to the data out pin of the external interface
+
+ :param id_internal_bug: id_internal_bug: the id of the internal bug as it is defined for the Java Bugplus Code
+ (e.g. "!_2")
+ """
+ self.challenge_implementation.connectDataOutInterface(id_internal_bug)
+
+ def connectControlInInterface(self, id_internal_bug: str):
+ """
+ Connects the control flow of the interface with the bit that will be activated first when starting the program.
+
+ :param id_internal_bug: the id of the bug that should be activated first when starting the program.
+ :return: None
+ """
+ self.write_to_file(
+ f'T2_Code_Implementation.connectControlInInterface("{id_internal_bug}");'
+ )
+ self.challenge_implementation.connectControlInInterface(id_internal_bug)
+
+ def addControlFlow(
+ self,
+ id_source_bug: str,
+ index_control_out: int,
+ id_target_bug: str
+ ):
+ """
+ Adds a control flow from a given source bug to a given target bug.
+
+ :param id_source_bug: the id of the source bug
+ :param index_control_out: the index of the control out pin that should be used to connect the bugs (0 or 1)
+ :param id_target_bug: the id of the target bug
+ :return:
+ """
+ self.write_to_file(
+ f'T2_Code_Implementation.addControlFlow("{id_source_bug}", 1, "{id_target_bug}");'
+ )
+
+ self.challenge_implementation.addControlFlow(
+ id_source_bug, index_control_out, id_target_bug
+ )
diff --git a/reinforcement_learning/translators/aux_matrix_to_image.py b/reinforcement_learning/translators/aux_matrix_to_image.py
new file mode 100644
index 0000000..16ad9f6
--- /dev/null
+++ b/reinforcement_learning/translators/aux_matrix_to_image.py
@@ -0,0 +1,144 @@
+"""
+Auxiliary function: uploads auxiliary TT matrix to Jesse Crossen simulator.
+"""
+
+# standard library imports
+import base64
+import webbrowser
+from io import BytesIO
+from typing import List
+
+# 3rd party imports
+from PIL import Image
+import numpy as np
+
+parts = {
+ "NotValid": -100,
+ "Valid": 0,
+ "GreenLeft": 1,
+ "GreenRight": 2,
+ "Orange": 3,
+ "Red": 4,
+ "BlueLeft": 5,
+ "Black": 6,
+ "BlueWheelLeft": 7,
+ "BlueWheelRight": 8,
+ "BlueRight": 9,
+ "LightGrey": -99,
+ "DarkGrey": -98
+}
+colors = {
+ "notValid": [32, 32, 32, 254],
+ "red": [255, 0, 0, 255],
+ "greenRight": [0, 255, 0, 255],
+ "greenLeft": [0, 189, 0, 255],
+ "orange": [255, 128, 0, 255],
+ "blueLeft": [0, 255, 255, 255],
+ "blueWheelLeft": [128, 0, 255, 255],
+ "black": [0, 0, 0, 255],
+ "white": [255, 255, 255, 255],
+ "blueWheelRight": [96, 0, 189, 255],
+ "blueRight": [0, 189, 189, 255],
+ "lightGrey": [128, 128, 128, 254],
+ "darkGrey": [96, 96, 96, 254]
+}
+
+
+def translate_value_to_color(val: int) -> List:
+ """
+ Auxiliary function to assign RGBA values to TT board pieces;
+ needed to generate picture for upload to Jesse Crossen TT simulator.
+
+ :param val: integer representing TT piece
+ :return: colors: list of RGBA values
+ """
+ if val == parts["NotValid"]:
+ return colors["notValid"]
+
+ if val == parts["GreenLeft"]:
+ return colors["greenLeft"]
+
+ if val == parts["Black"]:
+ return colors["black"]
+
+ if val == parts["BlueLeft"]:
+ return colors["blueLeft"]
+
+ if val == parts["BlueRight"]:
+ return colors["blueRight"]
+
+ if val == parts["BlueWheelLeft"]:
+ return colors["blueWheelLeft"]
+
+ if val == parts["BlueWheelRight"]:
+ return colors["blueWheelRight"]
+
+ if val == parts["DarkGrey"]:
+ return colors["darkGrey"]
+
+ if val == parts["GreenRight"]:
+ return colors["greenRight"]
+
+ if val == parts["LightGrey"]:
+ return colors["lightGrey"]
+
+ if val == parts["Orange"]:
+ return colors["orange"]
+
+ if val == parts["Red"]:
+ return colors["red"]
+
+ return colors["white"]
+
+
+def translate_matrix_to_board(mat: np.ndarray) -> str:
+ """
+ Takes matrix indicating placement of TT pieces and returns link for Jesse Crossen TT simulator.
+
+ :param mat: auxiliary matrix indicating position of TT pieces on board.
+ :return: formatted_str: image for upload to Jesse Crossen TT simulator in base 64.
+ """
+ mat = np.array(mat)
+ img = Image.open('assets/long_board.png')
+ pixel_map = img.load()
+
+ rows = len(mat)
+ cols = len(mat[0])
+ z = int((cols - 1) / 2)
+ for i in range(z):
+ for j in range(z - i):
+ mat[i, j] = parts["NotValid"]
+ mat[i, cols - j - 1] = parts["NotValid"]
+ z2 = int((cols - 3) / 2)
+ for j in range(z2):
+ mat[rows - 1, j] = parts["LightGrey"]
+ mat[rows - 1, cols - j - 1] = parts["DarkGrey"]
+ # testing:
+ mat[rows - 2, 0] = parts["LightGrey"]
+ mat[rows - 2, cols - 1] = parts["DarkGrey"]
+ print(mat)
+
+ for i in range(1, rows + 1):
+ for j in range(2, cols + 2):
+ # translates the value from the matrix into an rgba value (r, g, b, a)
+ color = tuple(translate_value_to_color(mat[i - 1][j - 2]))
+ pixel_map[j - 1, i + 1] = color
+
+ buffered = BytesIO()
+ img.save(buffered, format="PNG")
+ img_str = base64.b64encode(buffered.getvalue())
+ print(img_str)
+ formatted_str = f"data:image/png;base64,{str(img_str)[2:-1]}"
+ return formatted_str
+
+
+def open_new_board(mat: np.ndarray):
+ """
+ Opens base-64 representation of TT board in browser.
+
+ :param mat: numpy array indicating positioning of TT pieces on board
+ :return: (nothing): displays TT board in browser.
+ """
+ ttsim_link = "https://jessecrossen.github.io/ttsim/#s=17,33&z=32&cc=8&cr=16&t=2&sp=1&sc=0&b="
+ board = translate_matrix_to_board(mat)
+ webbrowser.open(ttsim_link + board, new=2)
diff --git a/reinforcement_learning/translators/aux_partial_orderer.py b/reinforcement_learning/translators/aux_partial_orderer.py
new file mode 100644
index 0000000..0e147fb
--- /dev/null
+++ b/reinforcement_learning/translators/aux_partial_orderer.py
@@ -0,0 +1,72 @@
+"""
+Generate page rank scores and a list of connected bits from CF matrix.
+"""
+# standard library imports
+from typing import List
+
+# 3rd party imports
+import numpy as np
+from igraph import *
+
+
+class PartialOrderer:
+ @classmethod
+ def order(cls, cf_matrix: np.ndarray) -> List[List]:
+ """
+ For n (bug)bits in the CF matrix, return IDs of node connected to control-out pins.
+
+ :param cf_matrix: a matrix of dimensions n x 2n
+ :return: fathers: a list of n sub-lists.
+ """
+ num_bugs = len(cf_matrix)
+ fathers = []
+ for column in range(num_bugs):
+ following_nodes = []
+ for row in range(num_bugs):
+ if cf_matrix[row][2 * column] == 1:
+ following_nodes.append(row)
+ for row in range(num_bugs):
+ if cf_matrix[row][2 * column + 1] == 1:
+ following_nodes.append(row)
+ fathers.append(following_nodes)
+
+ return fathers
+
+ @classmethod
+ def calc_rank(cls, fathers: list) -> List:
+ """
+ Calculate the page rank of each bit
+
+ :param fathers: List of n sub-lists
+ :return: ranking: List of page ranks of length n
+ """
+ print(f"Children: {fathers}")
+ all_nodes = [i for i in range(len(fathers))]
+ ranking = []
+
+ # create Graph
+ g = Graph(directed=True)
+ g.add_vertices(len(all_nodes), attributes={"label": range(len(all_nodes))})
+ for parent in range(len(fathers)):
+ for child in fathers[parent]:
+ if child == 0:
+ continue
+ g.add_edges([(parent, child)])
+ plot(g)
+
+ ranks = g.pagerank(directed=True)
+
+ added_to_rank_count = 0
+ while added_to_rank_count != len(all_nodes):
+ max_rank = min(ranks)
+ current_rank_bits = []
+ for i in range(len(ranks)):
+ if ranks[i] == max_rank:
+ current_rank_bits.append(i)
+ added_to_rank_count += 1
+ ranks[i] = np.inf
+ # ranks.remove(maxrank)
+ ranking.append(current_rank_bits)
+
+ print(ranking)
+ return ranking
diff --git a/reinforcement_learning/translators/startup_translatorT2_server.py b/reinforcement_learning/translators/startup_translatorT2_server.py
new file mode 100644
index 0000000..e5a7915
--- /dev/null
+++ b/reinforcement_learning/translators/startup_translatorT2_server.py
@@ -0,0 +1,85 @@
+"""
+Opens a Jesse Crossen GUI (TT board) on a local server.
+Board can then be set up in GUI and downloaded as image via specific button.
+This image is then used translator_image_to_code.py
+
+"""
+
+# start script with the following arguments in command line
+# ray start --head
+# serve start --http-host=127.0.0.1
+
+# standard library imports
+import os
+
+# 3rd party imports
+import ray
+from ray import serve
+from fastapi import FastAPI, Request
+from fastapi.middleware.cors import CORSMiddleware
+
+# local imports (i.e. our own code)
+from aux_image_to_code import Translator
+# noinspection PyUnresolvedReferences
+from utilities import utilities
+
+# initialise FastAPI API instance
+app = FastAPI()
+
+
+@serve.deployment
+@serve.ingress(app)
+class TranslationLayer:
+ translator: Translator
+
+ def __int__(self):
+ app.add_middleware(
+ CORSMiddleware,
+ allow_origins=['*', "http://localhost", "http://localhost:8080"],
+ allow_credentials=True,
+ allow_methods=["*"],
+ allow_headers=["*"],
+ )
+ pass
+
+ @app.get("/t2/{matrix}")
+ def translation2(self, matrix: str):
+ """
+ Route that accepts a matrix encoded as a string and calls the appropriate Translator function to convert it
+ to bugbit code.
+
+ :param matrix: matrix coded as string
+ :return: None
+ """
+ self.translator = Translator()
+ self.translator.matrix_to_bugbit_code(matrix)
+ return None
+
+ @app.post("/t2")
+ async def get_body(self, request: Request):
+ """
+ Alternative route to translate a matrix coded as string to bugbit code.
+
+ :param request: request object
+ :return: None
+ """
+
+ self.translator = Translator()
+ var = await request.json()
+ self.translator.matrix_to_bugbit_code(var)
+
+
+if __name__ == "__main__":
+ # start ray server
+ os.system("ray stop")
+ os.system("ray start --head")
+ os.system("serve start --http-host=127.0.0.1 --http-port=8000")
+
+ ray.init(address="auto", ignore_reinit_error=True, namespace="serve")
+ serve.start(detached=True) # or False
+
+ TranslationLayer.deploy()
+ # start TTSIM GUI
+ os.chdir(os.environ['TTSIM_PATH'])
+ os.system("make server")
+ os.chdir(os.getcwd())
diff --git a/reinforcement_learning/translators/translatorT1_cf_matrix_to_image.py b/reinforcement_learning/translators/translatorT1_cf_matrix_to_image.py
new file mode 100644
index 0000000..840a67c
--- /dev/null
+++ b/reinforcement_learning/translators/translatorT1_cf_matrix_to_image.py
@@ -0,0 +1,315 @@
+"""
+Translator (T1) from CF matrix to graphical TT board
+with help of functions defined in aux_partial_orderer.py
+and aux_matrix_to_image.py
+"""
+
+# standard library imports
+from typing import Optional, Tuple
+
+# 3rd party imports
+from igraph import *
+
+# local imports (i.e. our own code)
+from aux_partial_orderer import PartialOrderer
+from aux_matrix_to_image import *
+
+
+# noinspection PyShadowingNames
+class RankBasedTranslator:
+ num_bits = None
+ rows = None
+ columns = None
+ matrix = None
+ g = None
+ colors = None
+
+ def __init__(
+ self,
+ rows: Optional[int] = 20,
+ columns: Optional[int] = 20
+ ):
+ """
+ Builds empty TT board (of dimension rows x columns) as graph.
+ Graph is diamond grid-shaped: each node is only connected to its direct diagonal neighbours.
+
+ :param rows: number of rows in the TT grid
+ :param columns: number of columns in the TT grid
+ """
+ self.rows = rows
+ self.columns = columns
+ self.matrix = np.zeros(shape=(rows, columns), dtype=np.int64)
+
+ coordinates = []
+ self.edges = []
+ count = 0
+ for i in range(self.rows):
+ for j in range(self.columns):
+ coordinates.append((i, j))
+ if i % 2 != j % 2:
+ if i < self.rows - 1:
+
+ if j != 0:
+ self.edges.append((count, count + self.columns - 1))
+ if j != self.columns - 1:
+ self.edges.append((count, count + self.columns + 1))
+
+ if j != 0 and j != self.columns - 1:
+ pass
+ else:
+ pass
+ else:
+ self.edges.append((count, self.rows * self.columns))
+
+ count += 1
+ coordinates.append((self.rows, self.columns))
+
+ self.g = Graph(directed=True)
+
+ self.g.add_vertices(self.rows * self.columns + 1, attributes={"coordinates": coordinates})
+ self.g.vs["name"] = coordinates
+ self.g.vs["label"] = self.g.vs["name"]
+ self.colors = ["lightgrey"] * (self.rows * self.columns + 1)
+
+ # print(f"Edges: {edges}")
+ self.g.add_edges(self.edges)
+
+ def place_bits(self, rankings: list) -> List[Tuple]:
+ """
+ Generates coordinates to place pieces on from page ranks.
+
+ :param rankings: list of page ranks
+ :return: coordinates: list of position of TT bits on board.
+ """
+ coordinates = []
+ print(f"Ranks: {rankings}")
+ levels = len(rankings)
+ # we have to leave the last rows open to possibly add intercept tokens
+ placing_rows = np.ceil(np.linspace(start=0, stop=self.rows - 3, num=levels))
+ print(placing_rows)
+ for i in range(levels):
+ length = 1
+ try:
+ length = len(rankings[i])
+ except:
+ length = 1
+ if length != 1:
+ print(f"Linspace {(np.linspace(0, self.columns, num=length))}")
+ columns = np.ceil(np.linspace(0, self.columns, num=length + 2))[1:-1]
+ else:
+ columns = [np.ceil(np.linspace(0, self.columns, num=length + 2))[1]]
+ print(f"f Columns: {columns}")
+ for j in range(length):
+ if placing_rows[i] % 2 == columns[j] % 2:
+ columns[j] -= 1
+ coordinates.append((placing_rows[i], columns[j]))
+
+ # place Bits in Matrix
+ for (x, y) in coordinates:
+ self.matrix[int(x)][int(y)] = parts["BlueLeft"]
+ return coordinates
+
+ def find_shortest_paths(
+ self,
+ bit_coordinates: List[Tuple],
+ matrix: np.ndarray
+ ) -> List[List]:
+ """
+ Identifies placement of connecting pieces between bits.
+
+ :param bit_coordinates: placement of bits on TT board.
+ :param matrix: adjacency matrix of graph acting as empty TT board.
+ :return: shortest_paths: IDs of nodes traversed on shortest paths between bits.
+ """
+ bit_ids = []
+ for (i, j) in bit_coordinates:
+ bit_ids.append(i * self.columns + j)
+ print(f"Bit IDS: {bit_ids}")
+
+ for bid in bit_ids:
+ self.colors[int(bid)] = "blue"
+ self.g.vs["color"] = self.colors
+
+ print(f"Bit Coordinates {bit_coordinates}")
+ children = PartialOrderer.order(matrix)
+
+ for i in range(len(bit_ids)):
+ for j in children[i]:
+ shortest_paths = []
+ all_ids_without_ij = []
+ for b in bit_ids:
+ if b != bit_ids[i] and b != bit_ids[j]:
+ all_ids_without_ij.append(int(b))
+
+ delete_edges = []
+ for edge in self.edges:
+ for id in all_ids_without_ij:
+ if edge[0] == id or edge[1] == id:
+ delete_edges.append(edge)
+
+ self.g.delete_edges(delete_edges)
+
+ j = int(j)
+ i = int(i)
+ print(f"I {i}, {j}")
+ left_child_id = int(bit_ids[i] + self.columns - 1)
+ right_child_id = int(bit_ids[i] + self.columns + 1)
+ left_child_coord = self.get_coordinate(left_child_id)
+ right_child_coord = self.get_coordinate(right_child_id)
+ print(f"COORDS: {left_child_coord}")
+ if j == 0:
+ print("Link to Sink Node")
+ print(f"Path from {i}({bit_ids[i]}) to Sink Node)")
+
+ if self.matrix[left_child_coord[0]][left_child_coord[1]] == 0:
+ shortest_paths.append(self.g.get_shortest_paths(left_child_id, self.rows * self.columns)[0])
+ self.create_board(shortest_paths)
+ else:
+ shortest_paths.append(self.g.get_shortest_paths(right_child_id, self.rows * self.columns)[0])
+ self.create_board(shortest_paths)
+ self.g.add_edges(delete_edges)
+ continue
+ print(f"f Path from {i}({bit_ids[i]}) to {j}({bit_ids[j]})")
+ if self.matrix[left_child_coord[0]][left_child_coord[1]] == 0:
+ shortest_paths.append(self.g.get_shortest_paths(left_child_id, int(bit_ids[j]))[0])
+
+ else:
+ shortest_paths.append(self.g.get_shortest_paths(right_child_id, int(bit_ids[j]))[0])
+
+ self.create_board(shortest_paths)
+ self.g.add_edges(delete_edges)
+ return shortest_paths
+
+ def create_board(self, shortest_paths: List[List]):
+ """
+ Auxiliary function to generate auxiliary matrix for Jesse Crossen simulator
+
+ :param shortest_paths: nodes on shortest paths between bits on TT board graph.
+ """
+ print(f"SHORTEST PATHS: {shortest_paths}")
+ for path in shortest_paths:
+ coordinates = [(int(i / self.columns), i % self.columns) for i in path]
+ print(coordinates)
+ for i in range(0, len(coordinates) - 1):
+ print(f"1. {coordinates[i]} , 2. {coordinates[i + 1]}")
+ if coordinates[i][1] > coordinates[i + 1][1]:
+ if self.matrix[coordinates[i]] == parts["BlueLeft"]: # there are only zeros
+ continue
+ if self.matrix[coordinates[i]] == parts["GreenRight"]:
+ self.matrix[coordinates[i]] = parts["Orange"]
+ self.colors[self.get_id(coordinates[i])] = "orange"
+
+ else:
+ self.matrix[coordinates[i]] = parts["GreenLeft"]
+ self.colors[self.get_id(coordinates[i])] = "darkgreen"
+ self.g.vs["color"] = self.colors
+ else:
+ if self.matrix[coordinates[i]] == parts["BlueLeft"]:
+ continue
+
+ if self.matrix[coordinates[i]] == parts["GreenLeft"]:
+ self.matrix[coordinates[i]] = parts["Orange"]
+ self.colors[self.get_id(coordinates[i])] = "orange"
+
+ else:
+ self.matrix[coordinates[i]] = parts["GreenRight"]
+ self.colors[self.get_id(coordinates[i])] = "lightgreen"
+ self.g.vs["color"] = self.colors
+
+ print(self.matrix)
+
+ def set_intercepts(
+ self,
+ matrix: np.ndarray,
+ bit_coordinates: List[Tuple]
+ ) -> List[Tuple]:
+ """
+ Add intercepting pieces on board below bits that connect to none.
+
+ :param matrix: unfinished auxiliary matrix for Jesse Crossen simulator
+ :param bit_coordinates: position of bits on TT board.
+ :return: intercept_coords: position of intercepting pieces on TT board.
+ """
+ count = 0
+ intercept_coords = []
+ for col in range(len(matrix[0])):
+ only_zeros = True
+ for row in range(len(matrix)):
+ if matrix[row][col] != 0:
+ only_zeros = False
+ break
+ if only_zeros:
+ if col % 2 == 0:
+ index = int(col / 2)
+ coord = (bit_coordinates[index][0] + 1, bit_coordinates[index][1] - 1)
+ intercept_coords.append(coord)
+ else:
+ # print(bit_coordinates)
+ index = int(col / 2)
+ coord = (bit_coordinates[index][0] + 1, bit_coordinates[index][1] + 1)
+ intercept_coords.append(coord)
+
+ # print(interceptCoords)
+ for ic in intercept_coords:
+ self.matrix[int(ic[0])][int(ic[1])] = parts["Black"]
+ self.colors[self.get_id(ic)] = "Black"
+ self.g.vs["color"] = self.colors
+ return intercept_coords
+
+ def get_coordinate(self, identifier: int) -> Tuple[int, int]:
+ """
+ Auxiliary function to transform node ID in aux. graph into coordinates in aux. matrix
+
+ :param identifier: node ID in graph
+ :return: tuple of row and column number in aux. matrix
+ """
+ return int(identifier / self.columns), int(identifier % self.columns)
+
+ def get_id(self, coordinate: Tuple[int, int]) -> int:
+ """
+ Auxiliary function to transform coordinate in aux. TT matrix into ID in aux. graph
+
+ :param coordinate: tuple of row and column number in aux. matrix
+ :return: node ID in graph
+ """
+ return int(coordinate[0]) * self.columns + int(coordinate[1])
+
+
+def cf_matrix_to_board(mat):
+ ranking = PartialOrderer.calc_rank(PartialOrderer.order(mat))
+ translator = RankBasedTranslator(27, 15)
+
+ bit_coordinates = translator.place_bits(ranking)
+ translator.set_intercepts(mat, bit_coordinates)
+
+ shortest_paths = translator.find_shortest_paths(bit_coordinates, mat)
+ translator.create_board(shortest_paths)
+
+ print("MAT:")
+ print(translator.matrix)
+
+ layout = translator.g.layout_grid(width=translator.columns)
+ plot(translator.g, layout=layout)
+ print("NEW BOARD")
+ open_new_board(translator.matrix)
+
+
+if __name__ == "__main__":
+ matrix = [[0, 1, 0, 0, 0, 1],
+ [1, 0, 0, 0, 0, 0],
+ [0, 0, 1, 1, 0, 0]]
+
+ matrix_2 = [[0, 0, 0, 0, 0, 1],
+ [0, 1, 0, 0, 0, 0],
+ [0, 0, 1, 0, 0, 0]]
+
+ matrix_3 = [
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
+ [0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0]
+ ]
+
+ cf_matrix_to_board(matrix_3)
diff --git a/reinforcement_learning/utilities/__init__.py b/reinforcement_learning/utilities/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/reinforcement_learning/utilities/registration.py b/reinforcement_learning/utilities/registration.py
new file mode 100644
index 0000000..e91c54a
--- /dev/null
+++ b/reinforcement_learning/utilities/registration.py
@@ -0,0 +1,31 @@
+"""
+This file is a helper file which just registers our custom environments and models with the ray registry.
+"""
+
+# 3rd party imports
+from ray.tune.registry import register_env
+from ray.rllib.models import ModelCatalog
+
+# local imports (i.e. our own code)
+from custom_torch_models.rl_fully_connected_network import FullyConnectedNetwork
+from environments.envs.bugbit_env import BugBit
+from environments.envs.connectfourmvc_env import ConnectFourMVC
+
+
+# registering the BugBit environment
+def bugbit_env_creator(env_config):
+ return BugBit(env_config)
+
+
+register_env("bugbit-v0", bugbit_env_creator)
+
+
+# registering the ConnectFour environment
+def connect_four_env_creator(env_config):
+ return ConnectFourMVC()
+
+
+register_env("connectfour-v0", connect_four_env_creator)
+
+# registering the custom fully connected network model
+ModelCatalog.register_custom_model("custom_torch_fcnn", FullyConnectedNetwork)
diff --git a/reinforcement_learning/utilities/utilities.py b/reinforcement_learning/utilities/utilities.py
new file mode 100644
index 0000000..17082b5
--- /dev/null
+++ b/reinforcement_learning/utilities/utilities.py
@@ -0,0 +1,60 @@
+"""
+utilities
+=========
+This file contains various utility functions. The primary purpose is to set the environment variable
+JAR_PATH to the path to the jar file that contains the java classes needed for the various environments in this project.
+"""
+
+# standard library imports
+import os
+import pathlib
+import warnings
+
+# 3rd party imports
+# noinspection PyPackageRequirements
+import jpype
+
+# setting environment variables for the path to the JAR file and the data directory
+artifact_directory: str = ""
+artifact_file_name: str = ""
+
+# throw ValueError if the user did not fill in artifact_directory or artifact_file_name during setup process
+if not artifact_directory or not artifact_file_name:
+ raise ValueError("artifact_directory and artifact_file_name must be set")
+
+relative_jar_path = f"/../../out/artifacts/{artifact_directory}/{artifact_file_name}"
+
+# path to jar file
+os.environ["JAR_PATH"] = f"{pathlib.Path(__file__).parent.resolve()}" \
+ f"{relative_jar_path}"
+
+# path to openai-gym-environments module
+os.environ["REINFORCEMENT_LEARNING_DIR"] = f"{pathlib.Path(__file__).parent.resolve()}/../../reinforcement_learning"
+
+# path to Turing Tumble simulator
+os.environ["TTSIM_PATH"] = f"{pathlib.Path(__file__).parent.resolve()}/../../ttsim"
+
+# check if wandb_key_file exists
+if not os.path.exists(f"{os.getenv('REINFORCEMENT_LEARNING_DIR')}/wandb_key_file"):
+ raise FileNotFoundError(f"wandb_key_file not found in.\n"
+ f"Please create a file called wandb_key_file in {os.getenv('REINFORCEMENT_LEARNING_DIR')} "
+ f"and put your wandb api key in it (cf. https://docs.wandb.ai/quickstart).")
+
+# check if the wandb_key_file is empty
+if os.stat(f"{os.getenv('REINFORCEMENT_LEARNING_DIR')}/wandb_key_file").st_size == 0:
+ raise ValueError("wandb_key_file is empty; please set the wandb key in the wandb_key_file"
+ " (cf. https://docs.wandb.ai/quickstart).")
+
+# export wandb key to WANDB_API_KEY environment variable
+os.environ["WANDB_API_KEY"] = open(f"{os.getenv('REINFORCEMENT_LEARNING_DIR')}/wandb_key_file", "r").read()
+
+# start JVM
+
+# noinspection PyUnresolvedReferences
+if not jpype.isJVMStarted():
+ # noinspection PyUnresolvedReferences
+ jpype.startJVM(classpath=os.getenv("JAR_PATH"))
+
+# filter UserWarnings, FutureWarnings
+warnings.filterwarnings("ignore", category=UserWarning)
+warnings.filterwarnings("ignore", category=FutureWarning)
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000..d7274f3
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,17 @@
+pillow~=9.1.0
+numpy~=1.22.3
+ray~=1.13.0
+fastapi~=0.77.1
+setuptools~=62.2.0
+gym~=0.21.0
+wandb~=0.12.11
+torchinfo~=1.6.3
+pysimplegui~=4.60.0
+igraph~=0.9.10
+matplotlib~=3.5.2
+pandas~=1.4.2
+jpype1>=1.3.0
+igraph>=0.9.10
+tqdm>=4.64.0
+ipython>=8.3.0
+torch>=1.11.0
\ No newline at end of file
diff --git a/src/connectfour/ConnectFour.java b/src/connectfour/ConnectFour.java
new file mode 100644
index 0000000..a86d7b4
--- /dev/null
+++ b/src/connectfour/ConnectFour.java
@@ -0,0 +1,644 @@
+/**
+ * Implementation of the ConnectFour Environment.
+ */
+
+package connectfour;
+
+import java.util.*;
+import java.util.concurrent.ThreadLocalRandom;
+
+
+public class ConnectFour {
+
+
+ private final int WIDTH = 7;
+ private final int HEIGHT = 6;
+ private boolean done = false;
+ private int winner = 0;
+ private String game_mode = "no_interaction";
+
+ private int[][] board = new int[HEIGHT][WIDTH];
+
+ public ConnectFour() {
+ this.reset();
+ }
+
+ public int[][] reset() {
+ for (int i = 0; i < this.HEIGHT; i++) {
+ for (int j = 0; j < this.WIDTH; j++) {
+ this.board[i][j] = 0;
+ }
+ }
+ this.done = false;
+ return this.board;
+ }
+
+ public static void main(String[] args) {
+
+ }
+
+ public LinkedList selfplay_step(int action, int player) {
+ int reward = 0;
+// unless the board is full...
+ if (!boardFull()) {
+// if the action is valid...
+ if (actionValid(action)) {
+// place the token at the indicated column for player 1 (i.e. the agent)
+ placeToken(action, player);
+// if player 1 one won after the last move, set the reward to 1000
+ if (checkWinner(this.board)[0] == 1) {
+ if (checkWinner(this.board)[1] == 2) {
+ reward = 50;
+ } else {
+ reward = 50;
+ }
+ this.done = true;
+ this.winner = 1;
+// else if player 2 now won, (which should not happen since player 2 has not made a move yet), set the reward to -1000
+ } else if (checkWinner(this.board)[0] == 2) {
+ reward = -50;
+ this.done = true;
+ this.winner = 2;
+// else if none of them have won, sample a greedy action of player 2 to take and place it
+ } else if (checkWinner(this.board)[0] == 0) {
+ if (boardFull()) {
+ this.done = true;
+ this.winner = 0;
+ reward = -10;
+// if player 1 and 2 have made their move and none of them have won, let the reward for this action (by player) be -1;
+ } else {
+ reward = -1;
+ }
+ }
+// if the action (by player 1) is invalid, let the reward be -200
+ } else {
+ reward = -1000;
+ this.done = true;
+ this.winner = 2;
+ }
+// if the board is full and none of them have won, the reward will be -1000;
+ } else {
+ this.done = true;
+ this.winner = 0;
+ reward = -10;
+ }
+
+ LinkedList output = new LinkedList();
+ output.add(this.board);
+ output.add(reward);
+ output.add(this.done);
+ output.add(null);
+ System.out.println("EOS");
+ return output;
+ }
+
+ public LinkedList step(int action, int player) {
+ int reward = 0;
+ LinkedList output = new LinkedList();
+
+ if (!boardFull()) {
+ if (actionValid(action)) {
+ placeToken(action, player);
+ int winner = checkWinner(this.board)[0];
+ if (winner == 1 || winner == 2) {
+ output.add(this.board);
+ output.add(reward);
+ output.add(true);
+ output.add(null);
+ output.add(winner);
+ return output;
+ } else if (winner == 0) {
+ output.add(this.board);
+ output.add(reward);
+ output.add(false);
+ output.add(null);
+ output.add(winner);
+ return output;
+ }
+
+ }
+ }
+ output.add(this.board);
+ output.add(0); // reward
+ output.add(true); // done
+ output.add(null);
+ output.add(0);
+ return output;
+ }
+
+ public LinkedList interactive_step(int agentAction) {
+ int reward = 0;
+// unless the board is full...
+ if (!boardFull()) {
+// if the action is valid...
+ if (actionValid(agentAction)) {
+// place the token at the indicated column for player 1 (i.e. the agent)
+ placeToken(agentAction, 1);
+// if player 1 one after the last move, set the reward to 1000
+ if (checkWinner(this.board)[0] == 1) {
+ if (checkWinner(this.board)[1] == 2) {
+ reward = 50;
+ } else {
+ reward = 50;
+ }
+ this.winner = 1;
+ this.done = true;
+// else if player 2 now won, (which should not happen since player 2 has not made a move yet), set the reward to -1000
+ } else if (checkWinner(this.board)[0] == 2) {
+ reward = -50;
+ this.winner = 2;
+ this.done = true;
+// else if none of them have won, sample a random action of player 2 to take and place it
+ } else if (checkWinner(this.board)[0] == 0) {
+// if after player 2 has made their move, the board is either full or player 2 won, set the reward to -1000
+ if (checkWinner(this.board)[0] == 2) {
+ this.done = true;
+ this.winner = 2;
+ reward = -50;
+ } else if (boardFull()) {
+ this.done = true;
+ this.winner = 0;
+ reward = -50;
+// if player 1 and 2 have made their move and none of them have won, let the reward for this action (by player) be -1;
+ } else {
+ reward = -1;
+ }
+ }
+// if the action (by player 1) is invalid, let the reward be -200
+ } else {
+ reward = -10;
+ this.winner = 0;
+ this.done = true;
+ }
+// if the board is full and none of them have won, the reward will be -1000;
+ } else {
+ this.done = true;
+ this.winner = 0;
+ reward = -10;
+ }
+
+ LinkedList output = new LinkedList();
+ output.add(this.board);
+ output.add(reward);
+ output.add(this.done);
+ output.add(null);
+ return output;
+ }
+
+ public LinkedList step(int action) {
+ int reward = 0;
+// unless the board is full...
+ if (!boardFull()) {
+// if the action is valid...
+ if (actionValid(action)) {
+// place the token at the indicated column for player 1 (i.e. the agent)
+ placeToken(action, 1);
+// if player 1 one won after the last move, set the reward to 1000
+ if (checkWinner(this.board)[0] == 1) {
+ if (checkWinner(this.board)[1] == 2) {
+ reward = 50;
+ } else {
+ reward = 50;
+ }
+ this.done = true;
+ this.winner = 1;
+// else if player 2 now won, (which should not happen since player 2 has not made a move yet), set the reward to -1000
+ } else if (checkWinner(this.board)[0] == 2) {
+ reward = -50;
+ this.done = true;
+ this.winner = 2;
+// else if none of them have won, sample a greedy action of player 2 to take and place it
+ } else if (checkWinner(this.board)[0] == 0) {
+
+ greedyAction(2);
+// if after player 2 has made their move, the board is either full or player 2 won, set the reward to -1000
+ if (checkWinner(this.board)[0] == 2) {
+ this.done = true;
+ this.winner = 2;
+ reward = -50;
+ } else if (boardFull()) {
+ this.done = true;
+ this.winner = 0;
+ reward = -10;
+// if player 1 and 2 have made their move and none of them have won, let the reward for this action (by player) be -1;
+ } else {
+ reward = -1;
+ }
+ }
+// if the action (by player 1) is invalid, let the reward be -200
+ } else {
+ reward = -1000;
+ this.done = true;
+ this.winner = 2;
+ }
+// if the board is full and none of them have won, the reward will be -1000;
+ } else {
+ this.done = true;
+ this.winner = 0;
+ reward = -10;
+ }
+
+ LinkedList output = new LinkedList();
+ output.add(this.board);
+ output.add(reward);
+ output.add(this.done);
+ output.add(null);
+ output.add(this.winner);
+ return output;
+ }
+
+ private int sampleRandomAction() {
+ return ThreadLocalRandom.current().nextInt(0, this.WIDTH);
+ }
+
+ private boolean boardFull() {
+ for (int height = 0; height < this.HEIGHT; height++) {
+ for (int width = 0; width < this.WIDTH; width++) {
+ if (this.board[height][width] == 0) {
+ return false;
+ }
+ }
+ }
+ System.out.println("GAME OVER: The board is full");
+ return true;
+ }
+
+ /***
+ * @return true if the second player has not made a move yet
+ */
+ /* private boolean noTokensFrom2ndPlayer() {
+ for (int height = 0; height < this.HEIGHT; height++) {
+ for (int width = 0; width < this.WIDTH; width++) {
+ if (this.board[height][width] == 2) {
+ return false;
+ }
+ }
+ }
+ return true;
+ }*/
+ public void placeToken(int action, int player) {
+ try {
+ for (int i = this.HEIGHT - 1; i >= 0; i--) {
+ if (this.board[i][action] == 0) {
+ this.board[i][action] = player;
+ break;
+ }
+ }
+ } catch (ArrayIndexOutOfBoundsException e) {
+ System.out.println("Caught the array exception in placeToken()");
+ }
+ }
+
+ private boolean actionValid(int action) {
+ try {
+ for (int i = this.HEIGHT - 1; i >= 0; i--) {
+ if (this.board[i][action] == 0) {
+ return true;
+ }
+ }
+ return false;
+ } catch (ArrayIndexOutOfBoundsException exception) {
+ //System.out.println("Caught ArrayIndexOutOfBoundsException");
+ return false;
+ }
+ }
+
+ private int[] checkWinner(int[][] board) {
+ final int EMPTY_SLOT = 0;
+
+ for (int r = 0; r < this.HEIGHT; r++) { // iterate rows, bottom to top
+ for (int c = 0; c < this.WIDTH; c++) { // iterate columns, left to right
+ int player = board[r][c];
+ if (player == EMPTY_SLOT)
+ continue; // don't check empty slots
+
+ if (c + 3 < WIDTH &&
+ player == board[r][c + 1] && // look right
+ player == board[r][c + 2] &&
+ player == board[r][c + 3])
+ return new int[]{player, 1};
+ if (r + 3 < HEIGHT) {
+ if (player == board[r + 1][c] && // look up
+ player == board[r + 2][c] &&
+ player == board[r + 3][c])
+ return new int[]{player, 1};
+ if (c + 3 < WIDTH &&
+ player == board[r + 1][c + 1] && // look up & right
+ player == board[r + 2][c + 2] &&
+ player == board[r + 3][c + 3])
+ return new int[]{player, 2};
+ if (c - 3 >= 0 &&
+ player == board[r + 1][c - 1] && // look up & left
+ player == board[r + 2][c - 2] &&
+ player == board[r + 3][c - 3])
+ return new int[]{player, 2};
+ }
+ }
+ }
+
+ return new int[]{EMPTY_SLOT, 0}; // no winner found
+ }
+
+ public int[][] getState() {
+ return this.board;
+ }
+
+ private void greedyAction(int playerID) {
+ placeToken(getGreedyAction(playerID), playerID);
+ }
+
+ public int getGreedyAction(int playerID) {
+ // if there are 3 pieces of the same colour in the same row, column or diagonal, place this piece next to them,..
+ // ..in order to win or to stop the other player from winning
+
+ float rand = new Random().nextFloat();
+ if (rand < 0.1) {
+ while (true) {
+ int actionPlayer2 = sampleRandomAction();
+ if (actionValid(actionPlayer2)) {
+ //placeToken(actionPlayer2, 2);
+ return actionPlayer2;
+ }
+ }
+ }
+
+ for (int r = 0; r < this.HEIGHT; r++) {
+ for (int c = 0; c < this.WIDTH; c++) {
+ int field = this.board[r][c];
+
+ //make copy of the board
+ if (checkValidPosition(r, c)) {
+ int[][] boardcopy = new int[this.HEIGHT][this.WIDTH];
+ for (int r2 = 0; r2 < this.HEIGHT; r2++) {
+ for (int c2 = 0; c2 < this.WIDTH; c2++) {
+ boardcopy[r2][c2] = this.board[r2][c2];
+ }
+ }
+
+ //can greedy agent win the game?
+ boardcopy[r][c] = playerID;
+ int winner = checkWinner(boardcopy)[0];
+ if (winner == playerID) {
+ //placeToken(c, 2);
+ return c;
+ }
+ }
+ }
+ }
+ for (int r = 0; r < this.HEIGHT; r++) {
+ for (int c = 0; c < this.WIDTH; c++) {
+ int field = this.board[r][c];
+
+ //make copy of the board
+ if (checkValidPosition(r, c)) {
+ int[][] boardcopy = new int[this.HEIGHT][this.WIDTH];
+ for (int r2 = 0; r2 < this.HEIGHT; r2++) {
+ for (int c2 = 0; c2 < this.WIDTH; c2++) {
+ boardcopy[r2][c2] = this.board[r2][c2];
+ }
+ }
+
+ //can agent win the game?
+ boardcopy[r][c] = playerID == 1 ? 2 : 1;
+ int winner = checkWinner(boardcopy)[0];
+ if (winner == (playerID == 1 ? 2 : 1)) {
+ //placeToken(c, 2);
+ return c;
+ }
+ }
+ }
+ }
+
+ int[] checkTrap = checkArisingTrap(playerID);
+ if (checkTrap[2] != 0) {
+ //int column = checkTrap[1];
+ //int row = check2InARow(playerID)[0];
+ //placeToken(column+check2InARow -2, 2);
+ return checkTrap[1];
+ }
+
+ // same as above, but just for 2 pieces
+ int[] check2InARow = check2InARow(playerID);
+ if (check2InARow[2] != 0) {
+ //int column = check2InARow[1];
+ //int row = check2InARow[0];
+ //placeToken(column+check2InARow -2, 2);
+ return check2InARow[1];
+ }
+
+
+ // look for "alone" pieces
+ int[] checkAlonePiece = checkAlonePiece(playerID);
+ if (checkAlonePiece[2] != 0) {
+ //int column = checkAlonePiece(playerID)[1];
+ //placeToken(column+checkAlonePiece -2, 2);
+ return checkAlonePiece[1];
+ }
+
+ // if none of the previous cases apply, make a random choice :(
+ while (true) {
+ int actionPlayer2 = sampleRandomAction();
+ if (actionValid(actionPlayer2)) {
+ //placeToken(actionPlayer2, 2);
+ return actionPlayer2;
+ }
+ }
+ }
+
+
+ /**
+ * this function checks if a token can be placed on an exact position
+ * @param row: the row we want to place the token on
+ * @param column: the column we want to place the token on
+ * @return
+ */
+ private boolean checkValidPosition(int row, int column) {
+ try {
+ //check if field is empty
+ if (this.board[row][column] == 0) {
+ //check if we are in lowest row
+ if (row == this.HEIGHT - 1) {
+ return true;
+ }
+ //check if there is another piece BELOW the position, s.t. a token can be placed exactly there
+ if (this.board[row + 1][column] != 0) {
+ return true;
+ }
+ } else {
+ return false;
+ }
+ return false;
+ //check if positio is out of bounds
+ } catch (ArrayIndexOutOfBoundsException exception) {
+ //System.out.println("Caught ArrayIndexOutOfBoundsException");
+ return false;
+ }
+ }
+
+ /***
+ * this function checks if there are 3 pieces of the same colour in the same row, column or diagonal
+ * @return 1, place left
+ * 2, place in current column
+ * 5, place three to the right
+ * 0, if no valid position
+ */
+
+ private int[] check3InARow() {
+ for (int r = 0; r < this.HEIGHT; r++) { // iterate rows, bottom to top
+ for (int c = 0; c < this.WIDTH; c++) { // iterate columns, left to right
+ int player = this.board[r][c];
+ if (player == 0)
+ continue; // don't check empty slots
+
+ if (c + 2 < WIDTH &&
+ player == this.board[r][c + 1] && // look right
+ player == this.board[r][c + 2])
+ return new int[]{r, c, 1};
+ if (r + 2 < HEIGHT) {
+ if (player == this.board[r + 1][c] && // look up
+ player == this.board[r + 2][c])
+ return new int[]{r, c, 2};
+ if (c + 2 < WIDTH &&
+ player == this.board[r + 1][c + 1] && // look up & right
+ player == this.board[r + 2][c + 2])
+ return new int[]{r, c, 3};
+ if (c - 2 >= 0 &&
+ player == this.board[r + 1][c - 1] && // look up & left
+ player == this.board[r + 2][c - 2])
+ return new int[]{r, c, 4};
+ }
+ }
+ }
+ return new int[]{0, 0, 0};
+ }
+
+ private int[] checkArisingTrap(int playerID) {
+ /**
+ * Checks if the greedy agent can possibly run into a trap:
+ * this happens for the following scenario:
+ * __OO__
+ *
+ */
+ for (int r = 0; r < this.HEIGHT; r++) { // iterate rows, bottom to top
+ for (int c = 0; c < this.WIDTH; c++) { // iterate columns, left to right
+ int player = this.board[r][c];
+ if (player == playerID || player == 0) //we want to look for the enemy
+ continue; // don't check empty slots
+
+ if (c + 1 < WIDTH &&
+ player == this.board[r][c + 1]) {
+ if (checkValidPosition(r, c - 1) && checkValidPosition(r, c - 2) && checkValidPosition(r, c + 2)) {
+ return new int[]{r, c - 1, 1};
+ }
+ if (checkValidPosition(r, c + 2) && checkValidPosition(r, c - 1) && checkValidPosition(r, c + 3)) {
+ return new int[]{r, c + 2, 4};
+ }
+ }
+ }
+ }
+ return new int[]{0, 0, 0};
+ }
+
+ /***
+ * this function checks if there are 2 pieces of the same colour in the same row or column
+ * @return 1, place left
+ * 2, place in current column
+ * 4, place two to the right
+ * 0, if no valid position
+ */
+ private int[] check2InARow(int playerID) {
+
+ LinkedList possibleMoves = new LinkedList();
+ for (int r = 0; r < this.HEIGHT; r++) { // iterate rows, bottom to top
+ for (int c = 0; c < this.WIDTH; c++) { // iterate columns, left to right
+ int player = this.board[r][c];
+ if (player != playerID)
+ continue; // don't check empty slots
+
+ if (c + 1 < WIDTH &&
+ player == this.board[r][c + 1]) {
+ if (checkValidPosition(r, c - 1)) {
+ possibleMoves.add(new int[]{r, c - 1, 1});
+ }
+ if (checkValidPosition(r, c + 2)) {
+ possibleMoves.add(new int[]{r, c + 2, 4});
+ }
+ }
+
+ if (r + 1 < HEIGHT && player == this.board[r + 1][c])
+ if (checkValidPosition(r - 1, c))
+ possibleMoves.add(new int[]{r, c, 2});
+ }
+ }
+ if (possibleMoves.size() > 0) {
+ Random rand = new Random();
+ return possibleMoves.get(rand.nextInt(possibleMoves.size()));
+ } else {
+ return new int[]{0, 0, 0};
+ }
+ }
+
+ /***
+ * this function checks where next to an alone piece of the computer player another piece can be thrown
+ * @return 1, if left
+ * 2, if on top
+ * 3, if right
+ * 0, if nowhere
+ */
+ private int[] checkAlonePiece(int playerID) {
+ LinkedList possibleMoves = new LinkedList();
+ for (int r = 0; r < this.HEIGHT; r++) { // iterate rows, bottom to top
+ for (int c = 0; c < this.WIDTH; c++) { // iterate columns, left to right
+ int player = this.board[r][c];
+ if (player != playerID)
+ continue; // don't check empty slots
+
+ if (c - 1 > 0 && checkValidPosition(r, c - 1)) {
+
+ possibleMoves.add(new int[]{r, c - 1, 1});
+ }
+ if (c + 1 < WIDTH && checkValidPosition(r, c + 1))
+ possibleMoves.add(new int[]{r, c + 1, 3});
+ if (r - 1 > 0 && checkValidPosition(r - 1, c))
+ possibleMoves.add(new int[]{r, c, 2});
+ }
+ }
+ if (possibleMoves.size() > 0) {
+ Random rand = new Random();
+ return possibleMoves.get(rand.nextInt(possibleMoves.size()));
+ } else {
+ return new int[]{0, 0, 0};
+ }
+ }
+
+ private int[] check3Enemy() {
+
+ for (int r = 0; r < this.HEIGHT; r++) { // iterate rows, top to bottom
+ for (int c = 0; c < this.WIDTH; c++) { // iterate columns, left to right
+ int player = this.board[r][c];
+ if (player != 1)
+ continue; // don't check empty spots or player 2
+
+ if (c + 2 < WIDTH &&
+ player == this.board[r][c + 1] && // look right
+ player == this.board[r][c + 2])
+ return new int[]{r, c, 1};
+ if (r + 2 < HEIGHT) {
+ if (player == this.board[r + 1][c] && // look up
+ player == this.board[r + 2][c])
+ return new int[]{r, c, 2};
+ if (c + 2 < WIDTH &&
+ player == this.board[r + 1][c + 1] && // look up & right
+ player == this.board[r + 2][c + 2])
+ return new int[]{r, c, 3};
+ if (c - 2 >= 0 &&
+ player == this.board[r + 1][c - 1] && // look up & left
+ player == this.board[r + 2][c - 2])
+ return new int[]{r, c, 4};
+ }
+ }
+ }
+ return new int[]{0, 0, 0};
+ }
+
+}
diff --git a/src/de/bugplus/development/AbstractBugplusDataPin.java b/src/de/bugplus/development/AbstractBugplusDataPin.java
new file mode 100644
index 0000000..58850c8
--- /dev/null
+++ b/src/de/bugplus/development/AbstractBugplusDataPin.java
@@ -0,0 +1,105 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+abstract class AbstractBugplusDataPin implements BugplusDataPin {
+
+ private BugplusVariable variable;
+ protected boolean connected = false;
+
+ @Override
+ public void setConnected() {
+ this.connected = true; }
+
+ @Override
+ public boolean isConnected() {
+
+ return this.connected;
+ }
+
+
+ static void connect(BugplusDataInPin dataInPin, BugplusDataOutPin dataOutPin) {
+
+ BugplusVariable variableTarget = dataInPin.getVariable();
+ BugplusVariable variableSource = dataOutPin.getVariable();
+
+
+ if (variableTarget != null) {
+ if (variableSource != null) {
+
+ dataOutPin.getVariable().addAllReaders(variableTarget.getReaders());
+ dataOutPin.getVariable().addAllWriters(variableTarget.getWriters());
+
+ for (BugplusDataInPin dataInReader : variableTarget.getReaders()) {
+ dataInReader.setVariable(dataOutPin.getVariable()); }
+
+ for (BugplusDataOutPin dataInWriter : variableTarget.getWriters()) {
+ dataInWriter.setVariable(dataOutPin.getVariable()); }
+
+ dataInPin.setVariable(dataOutPin.getVariable());
+ }
+
+ dataOutPin.setVariable(dataInPin.getVariable()); }
+
+ else {
+ if (variableSource != null) {
+ dataInPin.setVariable(dataOutPin.getVariable()); }
+
+ else {
+ dataInPin.setVariable(new BugplusVariableImpl(dataInPin, dataOutPin));
+ dataOutPin.setVariable(dataInPin.getVariable()); }
+ }
+
+ dataInPin.setConnected();
+
+ }
+
+ /*Maybe unnecessary because automatically processed by the garbage collection*/
+ abstract public void unsubscribe();
+
+ public void disconnect() {
+ /*Maybe unnecessary because automatically processed by the garbage collection*/
+ this.unsubscribe();
+
+ this.variable = null;
+ }
+
+ @Override
+ public BugplusVariable getVariable() {
+ return this.variable;
+ }
+
+ @Override
+ public void setVariable(BugplusVariable variable) {
+ this.variable = variable;
+ }
+
+}
diff --git a/src/de/bugplus/development/AbstractBugplusInstance.java b/src/de/bugplus/development/AbstractBugplusInstance.java
new file mode 100644
index 0000000..18a3492
--- /dev/null
+++ b/src/de/bugplus/development/AbstractBugplusInstance.java
@@ -0,0 +1,154 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import de.bugplus.specification.BugplusSpecification;
+
+import java.util.List;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 25.01.22 18:55
+ * @Version 0.0.1
+ */
+abstract class AbstractBugplusInstance implements BugplusInstance {
+
+ private BugplusImplementation impl;
+ private BugplusInterface bugplusIF;
+
+
+ protected void createInterface(int numDataIn, int numControlOut) {
+ this.bugplusIF = BugplusInterface.getInstance(numDataIn, numControlOut, this);
+ }
+
+
+ @Override
+ final public BugplusImplementation getImplementation() {
+ return this.impl;
+ }
+
+ @Override
+ final public void setImplementation(BugplusImplementation implementation) {
+ this.impl = implementation;
+ }
+
+ @Override
+ public BugplusSpecification getSpecification() {
+ return this.getImplementation().getSpecification();
+ }
+
+
+ @Override
+ public BugplusInterface getInterface() {
+ return this.bugplusIF;
+ }
+
+ @Override
+ public BugplusControlInPin getControlIn() {
+ return this.getInterface().getControlInput();
+ }
+
+ @Override
+ public List getControlOuts() {
+
+ return this.getInterface().getControlOutputs();
+ }
+
+ @Override
+ public List getDataInputs() {
+ return this.getInterface().getDataInputs();
+ }
+
+ @Override
+ public BugplusDataOutPin getDataOut() {
+ return this.getInterface().getDataOutput();
+ }
+
+ @Override
+ public void setInputValue(int indexDataInPinIF, int value) {
+
+ List dataInPins = this.getInterface().getDataInputs();
+
+ if (dataInPins.size() > indexDataInPinIF) {
+
+ BugplusDataInPin pin = dataInPins.get(indexDataInPinIF);
+ BugplusVariable var = pin.getVariable();
+
+ if (var != null) {
+ var.setValue(value);
+ } else {
+ pin.setVariable(BugplusVariable.getInstance(value));
+ }
+
+ pin.updateInterfaceInputs();
+ //this.getInterface().setInternalState(value);
+ } else {
+ System.out.println("Error: Cannot set interface input because of index is out of bounds.");
+ }
+ }
+
+ @Override
+ public int getOutputValue() {
+
+ BugplusVariable var = this.getInterface().getDataOutput().getVariable();
+
+ if (var == null) {
+ System.out.println("Error: Cannot return an output value because no output value was connected by the interface.");
+ }
+
+ return var.getValue();
+ }
+
+
+ //Tobi
+ @Override
+ public int getInternalState() {
+ return this.getInterface().getInternalState();
+ }
+
+ @Override
+ public void setInternalState(int internalState) {
+ this.getInterface().setInternalState(internalState);
+ this.getInterface().getDataInputs().get(0).getVariable().setValue(internalState);
+ //System.out.println("Internal State " + internalState);
+ }
+ @Override
+ public BugplusProgramInstanceImpl getInstanceImpl(){
+ return (BugplusProgramInstanceImpl) this;
+ }
+
+ @Override
+ public int getCallCounter() {
+ return this.getInterface().getCallCounter();
+ }
+
+ @Override
+ public void setCallCounter(int callCounter) {
+ this.getInterface().setCallCounter(callCounter);
+ }
+
+
+}
diff --git a/src/de/bugplus/development/AbstractBugplusProgram.java b/src/de/bugplus/development/AbstractBugplusProgram.java
new file mode 100644
index 0000000..4816e0c
--- /dev/null
+++ b/src/de/bugplus/development/AbstractBugplusProgram.java
@@ -0,0 +1,53 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import de.bugplus.specification.BugplusSpecification;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 04.02.22 20:36
+ * @Version 0.0.1
+ */
+abstract public class AbstractBugplusProgram implements BugplusImplementation {
+
+ BugplusSpecification specification;
+
+ @Override
+ public BugplusSpecification getSpecification() {
+ return this.specification;
+ }
+
+ @Override
+ public void setSpecification(BugplusSpecification specification) {
+ this.specification = specification;
+ }
+
+ @Override
+ public BugplusInstance instantiate() {
+ return null;
+ }
+}
diff --git a/src/de/bugplus/development/AbstractBugplusStatement.java b/src/de/bugplus/development/AbstractBugplusStatement.java
new file mode 100644
index 0000000..e808564
--- /dev/null
+++ b/src/de/bugplus/development/AbstractBugplusStatement.java
@@ -0,0 +1,41 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 03.02.22 17:29
+ * @Version 0.0.1
+ */
+abstract class AbstractBugplusStatement implements BugplusStatement {
+
+ BugplusProgramImplementation programmable;
+
+ void initialize(BugplusProgramImplementation programmable) { this.programmable = programmable; }
+
+ @Override
+ public void apply(BugplusProgramInstance instance) {}
+}
diff --git a/src/de/bugplus/development/BugplusADDImplementation.java b/src/de/bugplus/development/BugplusADDImplementation.java
new file mode 100644
index 0000000..a948393
--- /dev/null
+++ b/src/de/bugplus/development/BugplusADDImplementation.java
@@ -0,0 +1,38 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 04.02.22 17:48
+ * @Version 0.0.1
+ */
+public interface BugplusADDImplementation extends BugplusImplementation {
+
+ static BugplusADDImplementation getInstance(){
+ return new BugplusADDImplementationImpl();
+ }
+}
diff --git a/src/de/bugplus/development/BugplusADDImplementationImpl.java b/src/de/bugplus/development/BugplusADDImplementationImpl.java
new file mode 100644
index 0000000..38845fd
--- /dev/null
+++ b/src/de/bugplus/development/BugplusADDImplementationImpl.java
@@ -0,0 +1,55 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+import de.bugplus.specification.BugplusADDSpecification;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 04.02.22 17:50
+ * @Version 0.0.1
+ */
+final class BugplusADDImplementationImpl extends AbstractBugplusProgram implements BugplusADDImplementation {
+
+ BugplusADDImplementationImpl() {
+
+ this.specification = BugplusADDSpecification.getInstance(this);
+ }
+
+ @Override
+ public BugplusInstance instantiate() {
+
+ return BugplusADDInstance.getInstance(this);
+ }
+
+ @Override
+ public BugplusInstanceDebug instantiateDebug() {
+
+ return BugplusADDInstanceDebug.getInstance(this);
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusADDInstance.java b/src/de/bugplus/development/BugplusADDInstance.java
new file mode 100644
index 0000000..5c71343
--- /dev/null
+++ b/src/de/bugplus/development/BugplusADDInstance.java
@@ -0,0 +1,40 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 25.01.22 20:53
+ * @Version 0.0.1
+ */
+public interface BugplusADDInstance extends BugplusInstance {
+
+
+ static BugplusADDInstance getInstance(BugplusImplementation implementation) {
+ return new BugplusADDInstanceImpl(implementation);
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusADDInstanceDebug.java b/src/de/bugplus/development/BugplusADDInstanceDebug.java
new file mode 100644
index 0000000..bcf4238
--- /dev/null
+++ b/src/de/bugplus/development/BugplusADDInstanceDebug.java
@@ -0,0 +1,38 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 22.02.22 17:41
+ * @Version 0.0.1
+ */
+public interface BugplusADDInstanceDebug extends BugplusADDInstance, BugplusInstanceDebug {
+
+ static BugplusADDInstanceDebug getInstance(BugplusImplementation implementation) {
+ return new BugplusADDInstanceDebugImpl(implementation);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusADDInstanceDebugImpl.java b/src/de/bugplus/development/BugplusADDInstanceDebugImpl.java
new file mode 100644
index 0000000..81c297b
--- /dev/null
+++ b/src/de/bugplus/development/BugplusADDInstanceDebugImpl.java
@@ -0,0 +1,76 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 22.02.22 17:51
+ * @Version 0.0.1
+ */
+final public class BugplusADDInstanceDebugImpl extends BugplusADDInstanceImpl implements BugplusADDInstanceDebug {
+
+ private BugplusInterfaceDebug bugplusIF;
+
+
+ BugplusADDInstanceDebugImpl(BugplusImplementation implementation) {
+
+ this.initializeImplementation(this, implementation);
+
+ this.createInterface(2,2);
+
+ this.initializeInterface(this.bugplusIF);
+
+ BugplusControlInPinDebug controlInPin = BugplusControlInPinDebug.getInstance(this);
+ this.bugplusIF.setControlInput(controlInPin);
+ }
+
+
+ public BugplusControlInPinDebug getControlIn() {
+ return this.bugplusIF.getControlInput();
+ }
+
+
+ public void createInterface(int numDataIn, int numControlOut) {
+
+ this.bugplusIF = BugplusInterfaceDebug.getInstance(numDataIn, numControlOut, this);
+ }
+
+ public BugplusInterfaceDebug getInterface() {
+
+ return this.bugplusIF;
+ }
+
+ @Override
+ public void execute() {
+ String id = this.getImplementation().getSpecification().getIdentifier();
+ int summand1 = this.getInterface().getDataInputs().get(0).getVariable().getValue();
+ int summand2 = this.getInterface().getDataInputs().get(1).getVariable().getValue();
+
+ System.out.println("Request: " + id + "(" + summand1 + ", " + summand2 + ")");
+
+ super.execute();
+ }
+}
diff --git a/src/de/bugplus/development/BugplusADDInstanceImpl.java b/src/de/bugplus/development/BugplusADDInstanceImpl.java
new file mode 100644
index 0000000..cd4cc84
--- /dev/null
+++ b/src/de/bugplus/development/BugplusADDInstanceImpl.java
@@ -0,0 +1,113 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+import de.bugplus.specification.BugplusADDSpecification;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+public class BugplusADDInstanceImpl extends AbstractBugplusInstance implements BugplusADDInstance {
+
+
+ protected BugplusADDInstanceImpl() {}
+
+ BugplusADDInstanceImpl(BugplusImplementation implementation) {
+
+ this.initializeImplementation(this, implementation);
+
+ this.createInterface(2,2);
+
+ this.initializeInterface(this.getInterface());
+
+ BugplusControlInPin controlInPin = BugplusControlInPin.getInstance(this);
+ this.getInterface().setControlInput(controlInPin);
+ }
+
+ protected void initializeImplementation(BugplusADDInstanceImpl instance, BugplusImplementation implementation) {
+
+ implementation.setSpecification(BugplusADDSpecification.getInstance(this.getImplementation()));
+ instance.setImplementation(implementation);
+ }
+
+ protected void initializeInterface(BugplusInterface bugplusInterface) {
+
+ bugplusInterface.getDataInputs().get(0).setVariable(BugplusVariable.getInstance(0));
+ bugplusInterface.getDataInputs().get(1).setVariable(BugplusVariable.getInstance(0));
+
+ BugplusDataOutPin dataOutPin = BugplusDataOutPin.getInstance();
+ dataOutPin.setVariable(BugplusVariable.getInstance(0));
+ dataOutPin.setConnected();
+ bugplusInterface.setDataOutputPin(dataOutPin);
+ }
+
+
+
+ @Override
+ public void execute() {
+
+ boolean b1 = this.getDataInputs().get(0).isConnected();
+ boolean b2 = this.getDataInputs().get(1).isConnected();
+
+ int result = 0;
+
+ if (!b1 & !b2) {
+ result = 0;
+ } else if (b1 & !b2) {
+ result = 1;
+ } else if (!b1 & b2) {
+ result = -1;
+ } else {
+ int summand1 = this.getInterface().getDataInputs().get(0).getVariable().getValue();
+ int summand2 = this.getInterface().getDataInputs().get(1).getVariable().getValue();
+ result = summand1 + summand2;
+ }
+
+ BugplusDataOutPin dataOutPin = this.getDataOut();
+
+ if (dataOutPin.getVariable() == null) {
+ dataOutPin.setVariable(BugplusVariable.getInstance());
+ }
+
+ dataOutPin.getVariable().setValue(result);
+
+ dataOutPin.updateInterfaceOutput();
+
+ if (result == 0) {
+ this.getInterface().getControlOutputs().get(0).execute(); }
+ else {
+ this.getInterface().getControlOutputs().get(1).execute(); }
+ }
+
+ @Override
+ public void unsetPins() {
+ // do not implement
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusBugSet.java b/src/de/bugplus/development/BugplusBugSet.java
new file mode 100644
index 0000000..b654145
--- /dev/null
+++ b/src/de/bugplus/development/BugplusBugSet.java
@@ -0,0 +1,41 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.02.22 17:50
+ * @Version 0.0.1
+ */
+public interface BugplusBugSet {
+
+ void put(String bugID, BugplusInstance instance);
+ BugplusInstance get(String bugID);
+
+ static BugplusBugSet getInstance() {
+ return new BugplusBugSetImpl();
+ }
+}
diff --git a/src/de/bugplus/development/BugplusBugSetDebug.java b/src/de/bugplus/development/BugplusBugSetDebug.java
new file mode 100644
index 0000000..a34a5a8
--- /dev/null
+++ b/src/de/bugplus/development/BugplusBugSetDebug.java
@@ -0,0 +1,41 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.02.22 18:03
+ * @Version 0.0.1
+ */
+public interface BugplusBugSetDebug extends BugplusBugSet {
+
+ void put(String bugID, BugplusInstanceDebug instance);
+ BugplusInstanceDebug get(String bugID);
+
+ static BugplusBugSetDebug getInstance() {
+ return new BugplusBugSetDebugImpl();
+ }
+}
diff --git a/src/de/bugplus/development/BugplusBugSetDebugImpl.java b/src/de/bugplus/development/BugplusBugSetDebugImpl.java
new file mode 100644
index 0000000..5d41467
--- /dev/null
+++ b/src/de/bugplus/development/BugplusBugSetDebugImpl.java
@@ -0,0 +1,49 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.02.22 18:03
+ * @Version 0.0.1
+ */
+final public class BugplusBugSetDebugImpl extends BugplusBugSetImpl implements BugplusBugSetDebug {
+
+ final private Map bugs = new HashMap<>();
+
+ @Override
+ public void put(String bugID, BugplusInstanceDebug instance) {
+ this.bugs.put(bugID, instance);
+ }
+
+ @Override
+ public BugplusInstanceDebug get(String bugID) {
+ return this.bugs.get(bugID);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusBugSetImpl.java b/src/de/bugplus/development/BugplusBugSetImpl.java
new file mode 100644
index 0000000..da1cea7
--- /dev/null
+++ b/src/de/bugplus/development/BugplusBugSetImpl.java
@@ -0,0 +1,51 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.HashMap;
+import java.util.Map;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.02.22 17:52
+ * @Version 0.0.1
+ */
+public class BugplusBugSetImpl implements BugplusBugSet {
+
+ final private Map bugs = new HashMap<>();
+
+ BugplusBugSetImpl() {}
+
+ @Override
+ public void put(String bugID, BugplusInstance instance) {
+ this.bugs.put(bugID, instance);
+ }
+
+ @Override
+ public BugplusInstance get(String bugID) {
+ return this.bugs.get(bugID);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusControlInPin.java b/src/de/bugplus/development/BugplusControlInPin.java
new file mode 100644
index 0000000..757f964
--- /dev/null
+++ b/src/de/bugplus/development/BugplusControlInPin.java
@@ -0,0 +1,46 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 27.01.22 21:31
+ * @Version 0.0.1
+ */
+interface BugplusControlInPin extends BugplusControlPin {
+
+
+ BugplusExecutable getProgram();
+
+
+ static BugplusControlInPin getInstance() {
+ return new BugplusControlInPinImpl();
+ }
+
+ static BugplusControlInPin getInstance(BugplusInstance instance) {
+ return new BugplusControlInPinImpl(instance);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusControlInPinDebug.java b/src/de/bugplus/development/BugplusControlInPinDebug.java
new file mode 100644
index 0000000..504d82c
--- /dev/null
+++ b/src/de/bugplus/development/BugplusControlInPinDebug.java
@@ -0,0 +1,44 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 21.02.22 12:01
+ * @Version 0.0.1
+ */
+public interface BugplusControlInPinDebug extends BugplusControlInPin {
+
+ void addBug(BugplusInstance bug);
+
+ static BugplusControlInPinDebug getInstance() {
+ return new BugplusControlInPinDebugImpl();
+ }
+
+ static BugplusControlInPinDebug getInstance(BugplusInstanceDebug instance) {
+ return new BugplusControlInPinDebugImpl(instance);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusControlInPinDebugImpl.java b/src/de/bugplus/development/BugplusControlInPinDebugImpl.java
new file mode 100644
index 0000000..27866dd
--- /dev/null
+++ b/src/de/bugplus/development/BugplusControlInPinDebugImpl.java
@@ -0,0 +1,76 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.List;
+import java.util.ArrayList;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 19.02.22 11:34
+ * @Version 0.0.1
+ */
+final public class BugplusControlInPinDebugImpl extends BugplusControlInPinImpl implements BugplusControlInPinDebug {
+
+ final private List bugs = new ArrayList<>();
+
+ BugplusControlInPinDebugImpl() {}
+
+ BugplusControlInPinDebugImpl(BugplusExecutable executable) {
+ super(executable);
+ }
+
+ @Override
+ public void execute() {
+
+ String debugBugReporting = "Request Bugs: \n";
+ String debugInterfaceReporting;
+
+ for (BugplusInstance bug : this.bugs) {
+
+ debugInterfaceReporting = "(";
+
+ for (BugplusDataInPin dataInPin : bug.getInterface().getDataInputs()) {
+ debugInterfaceReporting = debugInterfaceReporting + dataInPin.getVariable().getValue()+ ", ";}
+
+ if (bug.getInterface().getDataInputs().size()>0) debugInterfaceReporting = debugInterfaceReporting.substring(0, debugInterfaceReporting.length()-2);
+ debugInterfaceReporting = debugInterfaceReporting + ")";
+
+ debugBugReporting = debugBugReporting + bug.getImplementation().getSpecification().getIdentifier() + debugInterfaceReporting + " \n"; }
+
+ if (debugBugReporting.length()>16) {
+ debugBugReporting = debugBugReporting.substring(0, debugBugReporting.length()-4);
+ System.out.println("\n\n" + debugBugReporting + "\n"); }
+
+ this.executable.execute();
+ }
+
+
+ @Override
+ public void addBug(BugplusInstance bug) {
+ this.bugs.add(bug);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusControlInPinImpl.java b/src/de/bugplus/development/BugplusControlInPinImpl.java
new file mode 100644
index 0000000..6a7d777
--- /dev/null
+++ b/src/de/bugplus/development/BugplusControlInPinImpl.java
@@ -0,0 +1,61 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 27.01.22 21:39
+ * @Version 0.0.1
+ */
+class BugplusControlInPinImpl implements BugplusControlInPin {
+
+ protected BugplusExecutable executable;
+
+
+ BugplusControlInPinImpl() {}
+
+ BugplusControlInPinImpl(BugplusExecutable executable) {
+
+ this.executable = executable;
+ }
+
+
+ @Override
+ public void execute() {
+
+ this.executable.execute();
+ }
+
+
+ @Override
+ public BugplusExecutable getProgram() {
+ return this.executable;
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusControlOutPin.java b/src/de/bugplus/development/BugplusControlOutPin.java
new file mode 100644
index 0000000..661c7aa
--- /dev/null
+++ b/src/de/bugplus/development/BugplusControlOutPin.java
@@ -0,0 +1,43 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 27.01.22 21:32
+ * @Version 0.0.1
+ */
+interface BugplusControlOutPin extends BugplusControlPin {
+
+ void setFlowTarget(BugplusControlInPin controlInPin);
+ BugplusControlInPin getFlowTarget();
+ void unsetFlowTarget();
+
+ static BugplusControlOutPin getInstance() {
+ return new BugplusControlOutPinImpl();
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusControlOutPinImpl.java b/src/de/bugplus/development/BugplusControlOutPinImpl.java
new file mode 100644
index 0000000..9820526
--- /dev/null
+++ b/src/de/bugplus/development/BugplusControlOutPinImpl.java
@@ -0,0 +1,71 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 27.01.22 21:40
+ * @Version 0.0.1
+ */
+class BugplusControlOutPinImpl implements BugplusControlOutPin {
+
+ protected BugplusControlInPin controlTarget = null;
+
+ BugplusControlOutPinImpl() {}
+
+ BugplusControlOutPinImpl(BugplusControlInPin controlFlowTarget) {
+
+ this();
+ this.controlTarget = controlFlowTarget;
+ }
+
+ @Override
+ public void setFlowTarget(BugplusControlInPin controlInPin) {
+ this.controlTarget = controlInPin;
+ }
+
+ @Override
+ public BugplusControlInPin getFlowTarget() {
+
+ return this.controlTarget;
+ }
+
+ @Override
+ public void unsetFlowTarget() {
+ this.controlTarget = null;
+ }
+
+ @Override
+ public void execute() {
+
+ if (this.controlTarget != null) {
+ this.controlTarget.execute(); }
+ else {
+ // changed by tsesterh and romanhess98
+ //System.out.println("Bug+ program has been terminated!");
+ }
+ }
+}
diff --git a/src/de/bugplus/development/BugplusControlPin.java b/src/de/bugplus/development/BugplusControlPin.java
new file mode 100644
index 0000000..0ed0296
--- /dev/null
+++ b/src/de/bugplus/development/BugplusControlPin.java
@@ -0,0 +1,36 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 30.01.22 21:06
+ * @Version 0.0.1
+ */
+interface BugplusControlPin {
+
+ void execute();
+}
diff --git a/src/de/bugplus/development/BugplusDataInPin.java b/src/de/bugplus/development/BugplusDataInPin.java
new file mode 100644
index 0000000..d57bbd9
--- /dev/null
+++ b/src/de/bugplus/development/BugplusDataInPin.java
@@ -0,0 +1,46 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+public interface BugplusDataInPin extends BugplusDataPin {
+
+
+ void addDataInputToInterface(BugplusDataInPin internalDataInToConnect);
+
+ void updateInterfaceInputs();
+
+ void connect(BugplusDataOutPin dataOutPin);
+
+ static BugplusDataInPin getInstance() {
+
+ return new BugplusDataInPinImpl();
+ }
+}
diff --git a/src/de/bugplus/development/BugplusDataInPinImpl.java b/src/de/bugplus/development/BugplusDataInPinImpl.java
new file mode 100644
index 0000000..b792b3d
--- /dev/null
+++ b/src/de/bugplus/development/BugplusDataInPinImpl.java
@@ -0,0 +1,79 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+import java.util.HashSet;
+import java.util.Set;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 26.01.22 22:44
+ * @Version 0.0.1
+ */
+final class BugplusDataInPinImpl extends AbstractBugplusDataPin implements BugplusDataInPin {
+
+ final private Set interfaceInputs = new HashSet<>();
+
+
+ @Override
+ public void setVariable(BugplusVariable variable) {
+
+ variable.addReader(this);
+ super.setVariable(variable);
+ }
+
+ @Override
+ public void addDataInputToInterface(BugplusDataInPin internalDataInToConnect) {
+
+ if (internalDataInToConnect.getVariable() == null) {
+ internalDataInToConnect.setVariable(BugplusVariable.getInstance()); }
+
+ this.interfaceInputs.add(internalDataInToConnect);
+ internalDataInToConnect.setConnected();
+ }
+
+ @Override
+ public void updateInterfaceInputs() {
+
+ for (BugplusDataInPin internalDataInPin: this.interfaceInputs) {
+
+ internalDataInPin.getVariable().setValue(this.getVariable().getValue());
+ internalDataInPin.updateInterfaceInputs(); }
+ }
+
+ @Override
+ public void connect(BugplusDataOutPin dataOutPin) {
+
+ this.connect(this, dataOutPin);
+ }
+
+ @Override
+ public void unsubscribe() {
+ this.getVariable().getReaders().remove(this);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusDataOutPin.java b/src/de/bugplus/development/BugplusDataOutPin.java
new file mode 100644
index 0000000..d5fc80e
--- /dev/null
+++ b/src/de/bugplus/development/BugplusDataOutPin.java
@@ -0,0 +1,45 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 25.01.22 19:25
+ * @Version 0.0.1
+ */
+interface BugplusDataOutPin extends BugplusDataPin {
+
+ void addDataOutputToInterface(BugplusDataOutPin internalDataOutToConnect);
+
+ void updateInterfaceOutput();
+
+ void connect(BugplusDataInPin dataInPin);
+
+ static BugplusDataOutPin getInstance() {
+
+ return new BugplusDataOutPinImpl();
+ }
+}
diff --git a/src/de/bugplus/development/BugplusDataOutPinImpl.java b/src/de/bugplus/development/BugplusDataOutPinImpl.java
new file mode 100644
index 0000000..2f3a540
--- /dev/null
+++ b/src/de/bugplus/development/BugplusDataOutPinImpl.java
@@ -0,0 +1,80 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 26.01.22 22:44
+ * @Version 0.0.1
+ */
+final class BugplusDataOutPinImpl extends AbstractBugplusDataPin implements BugplusDataOutPin {
+
+ private BugplusDataOutPin interfaceOutput;
+
+ BugplusDataOutPinImpl() {
+ this.setVariable(BugplusVariable.getInstance());
+ }
+
+ @Override
+ public void addDataOutputToInterface(BugplusDataOutPin internalDataOutToConnect) {
+
+ if (internalDataOutToConnect.getVariable() == null) {
+ internalDataOutToConnect.setVariable(BugplusVariable.getInstance()); }
+
+ this.interfaceOutput = internalDataOutToConnect;
+ internalDataOutToConnect.setConnected();
+ }
+
+ @Override
+ public void updateInterfaceOutput() {
+
+ if (this.interfaceOutput != null) {
+ this.interfaceOutput.getVariable().setValue(this.getVariable().getValue());
+
+ if (this.interfaceOutput.isConnected()) {
+ this.interfaceOutput.updateInterfaceOutput();
+ }
+ }
+ }
+
+ @Override
+ public void connect(BugplusDataInPin dataInPin) {
+
+ this.connect(dataInPin, this);
+ }
+
+ @Override
+ public void unsubscribe() {
+ this.getVariable().getWriters().remove(this);
+ }
+
+ public void setVariable(BugplusVariable variable) {
+
+ variable.addWriter(this);
+ super.setVariable(variable);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusDataPin.java b/src/de/bugplus/development/BugplusDataPin.java
new file mode 100644
index 0000000..e05de06
--- /dev/null
+++ b/src/de/bugplus/development/BugplusDataPin.java
@@ -0,0 +1,47 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 26.01.22 22:06
+ * @Version 0.0.1
+ */
+interface BugplusDataPin {
+
+
+ void setVariable(BugplusVariable variable);
+
+ void setConnected();
+
+ boolean isConnected();
+
+ BugplusVariable getVariable();
+
+ void disconnect();
+
+}
diff --git a/src/de/bugplus/development/BugplusExecutable.java b/src/de/bugplus/development/BugplusExecutable.java
new file mode 100644
index 0000000..4fb6b5a
--- /dev/null
+++ b/src/de/bugplus/development/BugplusExecutable.java
@@ -0,0 +1,42 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 31.01.22 22:38
+ * @Version 0.0.1
+ */
+public interface BugplusExecutable {
+
+ BugplusInterface getInterface();
+
+ void setInputValue(int indexDataInputPin, int value);
+
+ int getOutputValue();
+
+ void execute();
+}
diff --git a/src/de/bugplus/development/BugplusImplementation.java b/src/de/bugplus/development/BugplusImplementation.java
new file mode 100644
index 0000000..3632c7c
--- /dev/null
+++ b/src/de/bugplus/development/BugplusImplementation.java
@@ -0,0 +1,42 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import de.bugplus.specification.BugplusSpecification;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 04.02.22 18:27
+ * @Version 0.0.1
+ */
+public interface BugplusImplementation extends BugplusInstantiable {
+
+ BugplusSpecification getSpecification();
+ void setSpecification(BugplusSpecification specification);
+
+
+
+}
diff --git a/src/de/bugplus/development/BugplusInstance.java b/src/de/bugplus/development/BugplusInstance.java
new file mode 100644
index 0000000..0a1c45f
--- /dev/null
+++ b/src/de/bugplus/development/BugplusInstance.java
@@ -0,0 +1,57 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import de.bugplus.specification.BugplusSpecification;
+
+import java.util.List;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 03.02.22 23:14
+ * @Version 0.0.1
+ */
+public interface BugplusInstance extends BugplusExecutable {
+
+ BugplusControlInPin getControlIn();
+ List getControlOuts();
+ List getDataInputs();
+ BugplusDataOutPin getDataOut();
+
+ BugplusImplementation getImplementation();
+ void setImplementation(BugplusImplementation implementation);
+ BugplusSpecification getSpecification();
+
+ //Tobi
+ int getInternalState();
+ void setInternalState(int internalState);
+ BugplusProgramInstanceImpl getInstanceImpl();
+
+ int getCallCounter();
+ void setCallCounter(int callCounter);
+
+ void unsetPins();
+}
diff --git a/src/de/bugplus/development/BugplusInstanceDebug.java b/src/de/bugplus/development/BugplusInstanceDebug.java
new file mode 100644
index 0000000..703d502
--- /dev/null
+++ b/src/de/bugplus/development/BugplusInstanceDebug.java
@@ -0,0 +1,36 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 22.02.22 00:03
+ * @Version 0.0.1
+ */
+public interface BugplusInstanceDebug extends BugplusInstance {
+
+ BugplusControlInPinDebug getControlIn();
+}
diff --git a/src/de/bugplus/development/BugplusInstantiable.java b/src/de/bugplus/development/BugplusInstantiable.java
new file mode 100644
index 0000000..37eee3b
--- /dev/null
+++ b/src/de/bugplus/development/BugplusInstantiable.java
@@ -0,0 +1,38 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 03.02.22 00:01
+ * @Version 0.0.1
+ */
+public interface BugplusInstantiable {
+
+ BugplusInstance instantiate();
+
+ BugplusInstanceDebug instantiateDebug();
+}
diff --git a/src/de/bugplus/development/BugplusInterface.java b/src/de/bugplus/development/BugplusInterface.java
new file mode 100644
index 0000000..4829220
--- /dev/null
+++ b/src/de/bugplus/development/BugplusInterface.java
@@ -0,0 +1,61 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.List;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 27.01.22 22:17
+ * @Version 0.0.1
+ */
+public interface BugplusInterface {
+
+ void setDataInputs(BugplusDataInPin internalDataInPin, int indexExternalDataInPin);
+ void setDataOutputPin(BugplusDataOutPin internalDataOutPin);
+
+ void setControlInput(BugplusControlInPin internalControlInPin);
+ void setControlOutputs(BugplusControlOutPin internalControlOutPin, int indexExternalControlOutPin);
+
+
+ List getDataInputs();
+ BugplusDataOutPin getDataOutput();
+
+ List getControlOutputs();
+ BugplusControlInPin getControlInput();
+
+ //Tobi
+ int getInternalState();
+ void setInternalState(int internalState);
+
+ int getCallCounter();
+ void setCallCounter(int callCounter);
+
+ static BugplusInterface getInstance(int numDataInputs, int numControlOutputs, BugplusInstance instance) {
+ return new BugplusInterfaceImpl(numDataInputs, numControlOutputs, instance);
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusInterfaceDebug.java b/src/de/bugplus/development/BugplusInterfaceDebug.java
new file mode 100644
index 0000000..b8be32c
--- /dev/null
+++ b/src/de/bugplus/development/BugplusInterfaceDebug.java
@@ -0,0 +1,42 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 21.02.22 22:52
+ * @Version 0.0.1
+ */
+public interface BugplusInterfaceDebug extends BugplusInterface {
+
+
+ BugplusControlInPinDebug getControlInput();
+ void setControlInput(BugplusControlInPinDebug controlInPin);
+
+ static BugplusInterfaceDebug getInstance(int numDataInputs, int numControlOutputs, BugplusInstance instance) {
+ return new BugplusInterfaceDebugImpl(numDataInputs, numControlOutputs, instance);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusInterfaceDebugImpl.java b/src/de/bugplus/development/BugplusInterfaceDebugImpl.java
new file mode 100644
index 0000000..d00b6c1
--- /dev/null
+++ b/src/de/bugplus/development/BugplusInterfaceDebugImpl.java
@@ -0,0 +1,57 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 21.02.22 22:52
+ * @Version 0.0.1
+ */
+final public class BugplusInterfaceDebugImpl extends BugplusInterfaceImpl implements BugplusInterfaceDebug {
+
+ private BugplusControlInPinDebug controlInputPin;
+
+ BugplusInterfaceDebugImpl(int numDataIns, int numControlOuts, BugplusInstance instance) {
+ super(numDataIns, numControlOuts, instance);
+ }
+
+ @Override
+ public void setControlInput(BugplusControlInPinDebug controlInPin) {
+
+ this.controlInputPin = controlInPin;
+ }
+
+ @Override
+ public void setControlInput(BugplusControlInPin controlInPin) {
+ this.controlInputPin = (BugplusControlInPinDebug) controlInPin;
+ }
+
+ @Override
+ public BugplusControlInPinDebug getControlInput() {
+ return this.controlInputPin;
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusInterfaceImpl.java b/src/de/bugplus/development/BugplusInterfaceImpl.java
new file mode 100644
index 0000000..a3bd177
--- /dev/null
+++ b/src/de/bugplus/development/BugplusInterfaceImpl.java
@@ -0,0 +1,143 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 27.01.22 22:18
+ * @Version 0.0.1
+ */
+class BugplusInterfaceImpl implements BugplusInterface {
+
+ final private List dataInputPins = new ArrayList<>();
+ private BugplusDataOutPin dataOutputPin;
+
+ private BugplusControlInPin controlInputPin;
+ final private List controlOutputPins = new ArrayList<>();
+ final private List controlReturnNodes = new ArrayList<>();
+ private int internalState;
+ private int callCounter;
+
+
+ private BugplusInterfaceImpl() {
+ }
+
+ BugplusInterfaceImpl(int numDataIns, int numControlOuts, BugplusInstance instance) {
+
+ this();
+
+ this.dataOutputPin = BugplusDataOutPin.getInstance();
+
+ for (int i = 0; i < numDataIns; i++) {
+ this.dataInputPins.add(i, BugplusDataInPin.getInstance());
+ }
+
+ for (int i = 0; i < numControlOuts; i++) {
+
+ BugplusControlOutPin controlOutPin = BugplusControlOutPin.getInstance();
+ this.controlOutputPins.add(i, controlOutPin);
+ this.controlReturnNodes.add(i, BugplusJOINControlInstance.getInterfaceControlOutNode(controlOutPin));
+ }
+
+ this.internalState = 0;
+ this.callCounter = 0;
+ }
+
+
+ @Override
+ public void setDataInputs(BugplusDataInPin internalDataInPin, int indexExternalDataInPin) {
+
+ if (indexExternalDataInPin < this.dataInputPins.size()) {
+ this.dataInputPins.set(indexExternalDataInPin, internalDataInPin);
+ } else {
+ System.out.println("Error: The index to connect the data-in-pin is out of bounds of permitted data inputs.");
+ }
+ }
+
+
+ @Override
+ public void setDataOutputPin(BugplusDataOutPin dataOutPin) {
+ this.dataOutputPin = dataOutPin;
+ }
+
+ @Override
+ public void setControlInput(BugplusControlInPin controlInPin) {
+ this.controlInputPin = controlInPin;
+ }
+
+
+ @Override
+ public void setControlOutputs(BugplusControlOutPin internalControlOutPin, int indexExternalControlOutPin) {
+
+ BugplusJOINControlInstance returnNode = this.controlReturnNodes.get(indexExternalControlOutPin);
+ internalControlOutPin.setFlowTarget(returnNode.getControlIn());
+ }
+
+ @Override
+ public List getDataInputs() {
+ return this.dataInputPins;
+ }
+
+ @Override
+ public BugplusDataOutPin getDataOutput() {
+ return this.dataOutputPin;
+ }
+
+ @Override
+ public List getControlOutputs() {
+ return this.controlOutputPins;
+ }
+
+ @Override
+ public BugplusControlInPin getControlInput() {
+ return this.controlInputPin;
+ }
+
+ @Override
+ public int getInternalState() {
+ return this.internalState;
+ }
+
+ @Override
+ public void setInternalState(int internalState) {
+ this.internalState = internalState;
+ }
+
+ @Override
+ public int getCallCounter() {
+ return this.callCounter;
+ }
+
+ @Override
+ public void setCallCounter(int callCounter) {
+ this.callCounter = callCounter;
+ }
+
+}
+
diff --git a/src/de/bugplus/development/BugplusJOINControlInstance.java b/src/de/bugplus/development/BugplusJOINControlInstance.java
new file mode 100644
index 0000000..6e25cfb
--- /dev/null
+++ b/src/de/bugplus/development/BugplusJOINControlInstance.java
@@ -0,0 +1,40 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 28.01.22 23:39
+ * @Version 0.0.1
+ */
+interface BugplusJOINControlInstance extends BugplusInstance {
+
+ BugplusControlInPin getControlIn();
+
+ static BugplusJOINControlInstance getInterfaceControlOutNode(BugplusControlOutPin controlOutputPin) {
+ return new BugplusJOINControlInstanceImpl(controlOutputPin);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusJOINControlInstanceImpl.java b/src/de/bugplus/development/BugplusJOINControlInstanceImpl.java
new file mode 100644
index 0000000..3e78588
--- /dev/null
+++ b/src/de/bugplus/development/BugplusJOINControlInstanceImpl.java
@@ -0,0 +1,86 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 28.01.22 18:23
+ * @Version 0.0.1
+ */
+final class BugplusJOINControlInstanceImpl extends AbstractBugplusInstance implements BugplusJOINControlInstance {
+
+ private BugplusControlInPin controlInPin;
+ private BugplusControlOutPin controlOutPin;
+
+ BugplusJOINControlInstanceImpl(BugplusControlOutPin controlOutputPin) {
+
+ this.controlInPin = new BugplusControlInPinImpl(this);
+ this.controlOutPin = controlOutputPin;
+ }
+
+
+ @Override
+ public void execute() {
+
+ this.controlOutPin.execute();
+ }
+
+ @Override
+ public BugplusControlInPin getControlIn() {
+ return this.controlInPin;
+ }
+
+ @Override
+ public List getControlOuts() {
+
+ List controlOuts = new ArrayList<>();
+ controlOuts.add(this.controlOutPin);
+
+ return controlOuts;
+ }
+
+ @Override
+ public List getDataInputs() {
+ return new ArrayList();
+ }
+
+ @Override
+ public void unsetPins() {
+
+ }
+
+ @Override
+ public BugplusInterface getInterface() {
+ return BugplusInterface.getInstance(0,1,this);
+ }
+
+
+
+}
diff --git a/src/de/bugplus/development/BugplusNEGImplementation.java b/src/de/bugplus/development/BugplusNEGImplementation.java
new file mode 100644
index 0000000..424506f
--- /dev/null
+++ b/src/de/bugplus/development/BugplusNEGImplementation.java
@@ -0,0 +1,38 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 04.02.22 17:48
+ * @Version 0.0.1
+ */
+public interface BugplusNEGImplementation extends BugplusImplementation {
+
+ static BugplusNEGImplementation getInstance(){
+ return new BugplusNEGImplementationImpl();
+ }
+}
diff --git a/src/de/bugplus/development/BugplusNEGImplementationImpl.java b/src/de/bugplus/development/BugplusNEGImplementationImpl.java
new file mode 100644
index 0000000..c4f2f98
--- /dev/null
+++ b/src/de/bugplus/development/BugplusNEGImplementationImpl.java
@@ -0,0 +1,55 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+import de.bugplus.specification.BugplusNEGSpecification;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 04.02.22 17:50
+ * @Version 0.0.1
+ */
+final class BugplusNEGImplementationImpl extends AbstractBugplusProgram implements BugplusNEGImplementation {
+
+ BugplusNEGImplementationImpl() {
+
+ this.specification = BugplusNEGSpecification.getInstance(this);
+ }
+
+ @Override
+ public BugplusInstance instantiate() {
+
+ return BugplusNEGInstance.getInstance(this);
+ }
+
+ @Override
+ public BugplusInstanceDebug instantiateDebug() {
+
+ return BugplusNEGInstanceDebug.getInstance(this);
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusNEGInstance.java b/src/de/bugplus/development/BugplusNEGInstance.java
new file mode 100644
index 0000000..5db6bb4
--- /dev/null
+++ b/src/de/bugplus/development/BugplusNEGInstance.java
@@ -0,0 +1,40 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 25.01.22 20:53
+ * @Version 0.0.1
+ */
+public interface BugplusNEGInstance extends BugplusInstance {
+
+
+ static BugplusNEGInstance getInstance(BugplusImplementation implementation) {
+ return new BugplusNEGInstanceImpl(implementation);
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusNEGInstanceDebug.java b/src/de/bugplus/development/BugplusNEGInstanceDebug.java
new file mode 100644
index 0000000..474fdb1
--- /dev/null
+++ b/src/de/bugplus/development/BugplusNEGInstanceDebug.java
@@ -0,0 +1,38 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 22.02.22 17:41
+ * @Version 0.0.1
+ */
+public interface BugplusNEGInstanceDebug extends BugplusNEGInstance, BugplusInstanceDebug {
+
+ static BugplusNEGInstanceDebug getInstance(BugplusImplementation implementation) {
+ return new BugplusNEGInstanceDebugImpl(implementation);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusNEGInstanceDebugImpl.java b/src/de/bugplus/development/BugplusNEGInstanceDebugImpl.java
new file mode 100644
index 0000000..62f4290
--- /dev/null
+++ b/src/de/bugplus/development/BugplusNEGInstanceDebugImpl.java
@@ -0,0 +1,76 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 22.02.22 17:51
+ * @Version 0.0.1
+ */
+final public class BugplusNEGInstanceDebugImpl extends BugplusNEGInstanceImpl implements BugplusNEGInstanceDebug {
+
+ private BugplusInterfaceDebug bugplusIF;
+
+
+ BugplusNEGInstanceDebugImpl(BugplusImplementation implementation) {
+
+ this.initializeImplementation(this, implementation);
+
+ this.createInterface(1,2);
+
+ this.initializeInterface(this.bugplusIF);
+
+ BugplusControlInPinDebug controlInPin = BugplusControlInPinDebug.getInstance(this);
+ this.bugplusIF.setControlInput(controlInPin);
+ }
+
+
+ public BugplusControlInPinDebug getControlIn() {
+ return this.bugplusIF.getControlInput();
+ }
+
+
+ public void createInterface(int numDataIn, int numControlOut) {
+
+ this.bugplusIF = BugplusInterfaceDebug.getInstance(numDataIn, numControlOut, this);
+ }
+
+ public BugplusInterfaceDebug getInterface() {
+
+ return this.bugplusIF;
+ }
+
+ @Override
+ public void execute() {
+ String id = this.getImplementation().getSpecification().getIdentifier();
+ int bit = this.getInterface().getDataInputs().get(0).getVariable().getValue();
+ //int summand2 = this.getInterface().getDataInputs().get(1).getVariable().getValue();
+
+ System.out.println("Request: " + id + "(" + bit + ")");
+
+ super.execute();
+ }
+}
diff --git a/src/de/bugplus/development/BugplusNEGInstanceImpl.java b/src/de/bugplus/development/BugplusNEGInstanceImpl.java
new file mode 100644
index 0000000..127353d
--- /dev/null
+++ b/src/de/bugplus/development/BugplusNEGInstanceImpl.java
@@ -0,0 +1,135 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+import de.bugplus.specification.BugplusNEGSpecification;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+public class BugplusNEGInstanceImpl extends AbstractBugplusInstance implements BugplusNEGInstance {
+
+ //protected int callCounter;
+
+ protected BugplusNEGInstanceImpl() {
+ //this.callCounter = 0;
+ }
+
+ BugplusNEGInstanceImpl(BugplusImplementation implementation) {
+
+ this.initializeImplementation(this, implementation);
+
+ this.createInterface(1, 2);
+
+ this.initializeInterface(this.getInterface());
+
+ BugplusControlInPin controlInPin = BugplusControlInPin.getInstance(this);
+ this.getInterface().setControlInput(controlInPin);
+
+ }
+
+ protected void initializeImplementation(BugplusNEGInstanceImpl instance, BugplusImplementation implementation) {
+
+ implementation.setSpecification(BugplusNEGSpecification.getInstance(this.getImplementation()));
+ instance.setImplementation(implementation);
+ }
+
+ protected void initializeInterface(BugplusInterface bugplusInterface) {
+
+ bugplusInterface.getDataInputs().get(0).setVariable(BugplusVariable.getInstance(this.getInterface().getInternalState()));
+ //System.out.println(this.getInterface().getInternalState());
+ //bugplusInterface.getDataInputs().get(1).setVariable(BugplusVariable.getInstance(0));
+
+ BugplusDataOutPin dataOutPin = BugplusDataOutPin.getInstance();
+ dataOutPin.setVariable(BugplusVariable.getInstance(0));
+ dataOutPin.setConnected();
+ bugplusInterface.setDataOutputPin(dataOutPin);
+
+ //bugplusInterface.getDataInputs().get(0).getVariable().setValue(this.getInterface().getInternalState());
+ }
+
+
+ @Override
+ public void execute() {
+ //this.callCounter++;
+ //System.out.println("in exec internal State: " + this.getInterface().getInternalState());
+ //System.out.println("Data in Value: " + this.getInterface().getDataInputs().get(0).getVariable().getValue());
+ boolean b1 = this.getDataInputs().get(0).isConnected();
+ //boolean b2 = this.getDataInputs().get(1).isConnected();
+
+ int result = 0;
+ /**
+ if (!b1) {
+ result = 1;
+ } else if (b1 & !b2) {
+ result = 1;
+ } else if (!b1 & b2) {
+ result = -1;
+ } else {
+ int summand1 = this.getInterface().getDataInputs().get(0).getVariable().getValue();
+ int summand2 = this.getInterface().getDataInputs().get(1).getVariable().getValue();
+ result = summand1 + summand2;
+ }
+ */
+
+
+ if (this.getDataInputs().get(0).getVariable().getValue() != 0 && this.getDataInputs().get(0).getVariable().getValue() != 1) {
+ throw new IllegalStateException("Wrong Data Input Value! Must be 0 or 1!");
+ }
+ result = this.getDataInputs().get(0).getVariable().getValue() == 1 ? 0 : 1;
+ this.getInterface().setInternalState(result);
+ this.getInterface().setCallCounter(this.getInterface().getCallCounter() + 1);
+
+ if(this.getInterface().getCallCounter() >= 20){
+ throw new IllegalStateException("Too many Bugcalls!");
+ }
+
+ BugplusDataOutPin dataOutPin = this.getDataOut();
+
+ if (dataOutPin.getVariable() == null) {
+ dataOutPin.setVariable(BugplusVariable.getInstance());
+ }
+
+ dataOutPin.getVariable().setValue(result);
+
+ dataOutPin.updateInterfaceOutput();
+
+ if (result == 0) {
+ this.getInterface().getControlOutputs().get(0).execute();
+ } else {
+ this.getInterface().getControlOutputs().get(1).execute();
+ }
+ }
+
+ @Override
+ public void unsetPins() {
+ // do not implement
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusProgramImplementation.java b/src/de/bugplus/development/BugplusProgramImplementation.java
new file mode 100644
index 0000000..2a1c1b0
--- /dev/null
+++ b/src/de/bugplus/development/BugplusProgramImplementation.java
@@ -0,0 +1,63 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+import de.bugplus.specification.BugplusProgramSpecification;
+
+import java.util.List;
+import java.util.Set;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+public interface BugplusProgramImplementation extends BugplusImplementation {
+
+ void addBug(String specID, String bugID);
+ Set getBugs();
+ void removeNode(String id);
+
+ void addDataFlow(String idSourceBug, String idTargetBug, int indexDataIn);
+ void disconnectDataInPin(String id, int index);
+ void disconnectDataOutPin(String id);
+
+ void addControlFlow(String idSourceBug, int indexControlOut, String idTargetBug);
+ void disconnectControlFlowOut(String idSourceBug, int indexControlOut);
+
+ void connectDataInInterface(String idInternalBug, int indexInternalDataIn, int indexExternalDataInIF);
+ void connectDataOutInterface(String idInternalBug);
+ void connectControlInInterface(String idInternalBug);
+ void connectControlOutInterface(String idInternalBug, int indexInternalControlOut, int indexExternalControlOutIF);
+
+
+ static BugplusProgramImplementation getInstance(BugplusProgramSpecification specification) {
+ return new BugplusProgramImplementationImpl(specification);
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusProgramImplementationImpl.java b/src/de/bugplus/development/BugplusProgramImplementationImpl.java
new file mode 100644
index 0000000..c716229
--- /dev/null
+++ b/src/de/bugplus/development/BugplusProgramImplementationImpl.java
@@ -0,0 +1,201 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import de.bugplus.specification.BugplusProgramSpecification;
+
+import java.util.ArrayList;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 03.02.22 22:03
+ * @Version 0.0.1
+ */
+final class BugplusProgramImplementationImpl extends AbstractBugplusProgram implements BugplusProgramImplementation {
+
+ final private List newBugStatements = new ArrayList<>();
+ final private List newFlowsStatements = new ArrayList<>();
+
+ final private List newIFConnectDataInStatements = new ArrayList<>();
+ final private List newIFConnectDataOutStatements = new ArrayList<>();
+
+ final private List newIFConnectControlInStatements = new ArrayList<>();
+ final private List newIFConnectControlOutStatements = new ArrayList<>();
+
+ final private Set instances = new HashSet<>();
+
+ private boolean debugMode = false;
+
+
+ private BugplusProgramImplementationImpl() {
+ }
+
+ public BugplusProgramImplementationImpl(BugplusProgramSpecification specification) {
+
+ this.specification = specification;
+ this.debugMode = false;
+ }
+
+
+ @Override
+ public void addBug(String specID, String bugID) {
+
+ this.newBugStatements.add(BugplusStatementNewBug.getInstance(specID, bugID));
+ }
+
+ //Tobi
+ @Override
+ public Set getBugs() {
+ return this.instances;
+ }
+
+ @Override
+ public void removeNode(String id) {
+
+ // implement
+ }
+
+ @Override
+ public void addDataFlow(String idSourceBug, String idTargetBug, int indexDataIn) {
+
+ this.newFlowsStatements.add(BugplusStatementNewFlowData.getInstance(idSourceBug, idTargetBug, indexDataIn));
+ }
+
+ @Override
+ public void disconnectDataInPin(String idDataIn, int index) {
+ // implement
+ }
+
+ @Override
+ public void disconnectDataOutPin(String idDataOut) {
+ // implement
+ }
+
+ @Override
+ public void addControlFlow(String idSourceBug, int indexControlOut, String idTargetBug) {
+
+ this.newFlowsStatements.add(BugplusStatementNewFlowControl.getInstance(idSourceBug, indexControlOut, idTargetBug));
+ }
+
+ @Override
+ public void disconnectControlFlowOut(String idSourceBug, int indexControlOut) {
+ // implement
+ }
+
+ @Override
+ public void connectDataInInterface(String idInternalBug, int indexInternalDataIn, int indexExternalDataInIF) {
+
+ this.newIFConnectDataInStatements.add(BugplusStatementNewIFConnectDataIn.getInstance(idInternalBug, indexInternalDataIn, indexExternalDataInIF));
+ }
+
+ @Override
+ public void connectDataOutInterface(String idInternalBug) {
+
+ this.newIFConnectDataOutStatements.add(BugplusStatementNewIFConnectDataOut.getInstance(idInternalBug));
+ }
+
+ @Override
+ public void connectControlInInterface(String idInternalBug) {
+
+ this.newIFConnectControlInStatements.add(BugplusStatementNewIFConnectControlIn.getInstance(idInternalBug));
+ }
+
+ @Override
+ public void connectControlOutInterface(String idInternalBug, int indexInternalControlOut, int indexExternalControlOutIF) {
+
+ this.newIFConnectControlOutStatements.add(BugplusStatementNewIFConnectControlOut.getInstance(idInternalBug, indexInternalControlOut, indexExternalControlOutIF));
+ }
+
+
+ @Override
+ public BugplusProgramInstance instantiate() {
+
+ BugplusProgramInstance newInstance = BugplusProgramInstance.getInstance(this);
+
+ for (BugplusStatementNewBug newBugStatement : this.newBugStatements) {
+ newBugStatement.apply(newInstance);
+ }
+
+ this.instanciateInternals(newInstance);
+
+ for (BugplusStatementNewIFConnectControlIn newIFConnectControlInStatement : this.newIFConnectControlInStatements) {
+ newIFConnectControlInStatement.apply(newInstance);
+ }
+
+ return newInstance;
+ }
+
+ @Override
+ public BugplusProgramInstanceDebug instantiateDebug() {
+
+ this.debugMode = true;
+
+ BugplusProgramInstanceDebug newInstance = BugplusProgramInstanceDebug.getInstance(this);
+
+ for (BugplusStatementNewBug newBugStatement : this.newBugStatements) {
+ BugplusStatementNewBugDebug newBugStatementDebug = BugplusStatementNewBugDebug.getInstance(newBugStatement.getSpecificationID(), newBugStatement.getBugRoleID());
+ newBugStatementDebug.apply(newInstance);
+ }
+
+ this.instanciateInternals(newInstance);
+
+ for (BugplusStatementNewIFConnectControlIn newIFConnectControlInStatement : this.newIFConnectControlInStatements) {
+ BugplusStatementNewIFConnectControlInDebug newIFConnectControlInStatementDebug = BugplusStatementNewIFConnectControlInDebug.getInstance(newIFConnectControlInStatement.getInternalBugID());
+ newIFConnectControlInStatementDebug.apply(newInstance);
+ }
+
+ return newInstance;
+ }
+
+
+ private BugplusProgramInstance instanciateInternals(BugplusProgramInstance instance) {
+
+ this.instances.add(instance);
+
+
+ for (BugplusStatementNewFlow newFlowStatement : this.newFlowsStatements) {
+ newFlowStatement.apply(instance);
+ }
+
+ for (BugplusStatementNewIFConnectDataIn newIFConnectDataInStatement : this.newIFConnectDataInStatements) {
+ newIFConnectDataInStatement.apply(instance);
+ }
+
+ for (BugplusStatementNewIFConnectDataOut newIFConnectDataOutStatement : this.newIFConnectDataOutStatements) {
+ newIFConnectDataOutStatement.apply(instance);
+ }
+
+ for (BugplusStatementNewIFConnectControlOut newIFConnectControlOutStatement : this.newIFConnectControlOutStatements) {
+ newIFConnectControlOutStatement.apply(instance);
+ }
+
+ return instance;
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusProgramInstance.java b/src/de/bugplus/development/BugplusProgramInstance.java
new file mode 100644
index 0000000..79f71f9
--- /dev/null
+++ b/src/de/bugplus/development/BugplusProgramInstance.java
@@ -0,0 +1,50 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.List;
+import java.util.Map;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 17:30
+ * @Version 0.0.1
+ */
+public interface BugplusProgramInstance extends BugplusInstance {
+
+
+ void setOutputVariable();
+
+ void addBug(String bugRoleID, BugplusInstance bug);
+
+ BugplusBugSet getBugs();
+
+ List getControlOutPinsOf(String bugID);
+
+ static BugplusProgramInstance getInstance(BugplusProgramImplementation implementation) {
+ return new BugplusProgramInstanceImpl(implementation);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusProgramInstanceDebug.java b/src/de/bugplus/development/BugplusProgramInstanceDebug.java
new file mode 100644
index 0000000..9172282
--- /dev/null
+++ b/src/de/bugplus/development/BugplusProgramInstanceDebug.java
@@ -0,0 +1,44 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 21.02.22 23:43
+ * @Version 0.0.1
+ */
+public interface BugplusProgramInstanceDebug extends BugplusProgramInstance, BugplusInstanceDebug {
+
+ void addBug(String bugID, BugplusInstanceDebug bug);
+
+ BugplusBugSetDebug getBugs();
+
+ static BugplusProgramInstanceDebug getInstance(BugplusProgramImplementation implementation) {
+ return new BugplusProgramInstanceDebugImpl(implementation);
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusProgramInstanceDebugImpl.java b/src/de/bugplus/development/BugplusProgramInstanceDebugImpl.java
new file mode 100644
index 0000000..bc92fcf
--- /dev/null
+++ b/src/de/bugplus/development/BugplusProgramInstanceDebugImpl.java
@@ -0,0 +1,71 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 21.02.22 23:44
+ * @Version 0.0.1
+ */
+final public class BugplusProgramInstanceDebugImpl extends BugplusProgramInstanceImpl implements BugplusProgramInstanceDebug {
+
+ final private BugplusBugSetDebug bugs = BugplusBugSetDebug.getInstance();
+ private BugplusInterfaceDebug bugplusIF;
+
+
+ BugplusProgramInstanceDebugImpl(BugplusProgramImplementation implementation) {
+
+ this.setImplementation(implementation);
+ this.createInterface(this.getSpecification().getNumDataIn(), this.getSpecification().getNumControlOut());
+ }
+
+ protected void createInterface(int numDataIn, int numControlOut) {
+ this.bugplusIF = BugplusInterfaceDebug.getInstance(numDataIn, numControlOut, this);
+ }
+
+ @Override
+ public BugplusControlInPinDebug getControlIn() {
+ return this.getInterface().getControlInput();
+ }
+
+ @Override
+ public void addBug(String bugID, BugplusInstanceDebug bug) {
+
+ this.getBugs().put(bugID, bug);
+ }
+
+ @Override
+ public BugplusInterfaceDebug getInterface() {
+ return this.bugplusIF;
+ }
+
+ @Override
+ public BugplusBugSetDebug getBugs() {
+ return this.bugs;
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusProgramInstanceImpl.java b/src/de/bugplus/development/BugplusProgramInstanceImpl.java
new file mode 100644
index 0000000..038448f
--- /dev/null
+++ b/src/de/bugplus/development/BugplusProgramInstanceImpl.java
@@ -0,0 +1,127 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.List;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+public class BugplusProgramInstanceImpl extends AbstractBugplusInstance implements BugplusProgramInstance {
+
+ final private BugplusBugSet bugs = BugplusBugSet.getInstance();
+
+
+ protected BugplusProgramInstanceImpl() {}
+
+ BugplusProgramInstanceImpl(BugplusProgramImplementation implementation) {
+
+ this.setImplementation(implementation);
+
+ this.createInterface(this.getSpecification().getNumDataIn(), this.getSpecification().getNumControlOut());
+ }
+
+
+ @Override
+ public void setOutputVariable() {
+
+ }
+
+
+ @Override
+ public void addBug(String bugID, BugplusInstance bug) {
+
+ this.getBugs().put(bugID, bug);
+ }
+
+ @Override
+ public BugplusBugSet getBugs() {
+ return this.bugs;
+ }
+
+
+ public List getControlOutPinsOf(String bugID) {
+ return this.getBugs().get(bugID).getControlOuts();
+ }
+
+ @Override
+ public void unsetPins() {
+
+ for(BugplusDataPin pin : this.getDataInputs()) {
+ pin.disconnect();
+ }
+
+ this.getDataOut().disconnect();
+ }
+
+
+ @Override
+ public void execute() {
+
+ System.out.println("Error: Cannot execute this bug instance because it has not native implementation!");
+ }
+
+
+/*
+
+ @Override
+ public void removeNode(String id) {
+
+ //Maybe unnecessary because automatically processed by the garbage collection
+ //BugplusInstance nodeToRemove = this.turingNodes.get(id);
+ //nodeToRemove.unsetPins();
+
+ this.bugs.remove(id);
+ }
+
+ @Override
+ public void disconnectDataInPin(String id, int index) {
+
+ BugplusDataInPin pin = this.bugs.get(id).getDataIns().get(index);
+ pin.disconnect();
+ }
+
+ @Override
+ public void disconnectDataOutPin(String id) {
+
+ BugplusDataOutPin pin = this.bugs.get(id).getDataOut();
+ pin.disconnect();
+ }
+
+ @Override
+ public void disconnectControlFlowOut(String idSourceBug, int indexControlOut) {
+
+ BugplusControlOutPin controlOutPin = this.getControlOutPinsOf(idSourceBug).get(indexControlOut);
+ controlOutPin.unsetFlowTarget();
+ }
+
+*/
+
+
+}
diff --git a/src/de/bugplus/development/BugplusRuntimeEnvironment.java b/src/de/bugplus/development/BugplusRuntimeEnvironment.java
new file mode 100644
index 0000000..5acb450
--- /dev/null
+++ b/src/de/bugplus/development/BugplusRuntimeEnvironment.java
@@ -0,0 +1,34 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 10:30
+ * @Version 0.0.1
+ */
+public interface BugplusRuntimeEnvironment {
+}
diff --git a/src/de/bugplus/development/BugplusRuntimeEnvironmentImpl.java b/src/de/bugplus/development/BugplusRuntimeEnvironmentImpl.java
new file mode 100644
index 0000000..e44c0eb
--- /dev/null
+++ b/src/de/bugplus/development/BugplusRuntimeEnvironmentImpl.java
@@ -0,0 +1,38 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.Set;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 10:31
+ * @Version 0.0.1
+ */
+final public class BugplusRuntimeEnvironmentImpl implements BugplusRuntimeEnvironment {
+
+ private Set bugs;
+}
diff --git a/src/de/bugplus/development/BugplusStatement.java b/src/de/bugplus/development/BugplusStatement.java
new file mode 100644
index 0000000..97eb93f
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatement.java
@@ -0,0 +1,37 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 03.02.22 17:33
+ * @Version 0.0.1
+ */
+interface BugplusStatement {
+
+ void apply(BugplusProgramInstance instance);
+}
+
diff --git a/src/de/bugplus/development/BugplusStatementNewBug.java b/src/de/bugplus/development/BugplusStatementNewBug.java
new file mode 100644
index 0000000..5603b8c
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewBug.java
@@ -0,0 +1,45 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 03.02.22 22:23
+ * @Version 0.0.1
+ */
+interface BugplusStatementNewBug extends BugplusStatement {
+
+ void apply(BugplusProgramInstance instance);
+
+ String getSpecificationID();
+ String getBugRoleID();
+
+ static BugplusStatementNewBug getInstance(String specificationID, String bugID) {
+
+ return new BugplusStatementNewBugImpl(specificationID, bugID);
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewBugDebug.java b/src/de/bugplus/development/BugplusStatementNewBugDebug.java
new file mode 100644
index 0000000..6313e90
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewBugDebug.java
@@ -0,0 +1,40 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 22.02.22 20:44
+ * @Version 0.0.1
+ */
+public interface BugplusStatementNewBugDebug extends BugplusStatementNewBug {
+
+ void apply(BugplusProgramInstanceDebug instance);
+
+ static BugplusStatementNewBugDebug getInstance(String specificationID, String bugID) {
+ return new BugplusStatementNewBugDebugImpl(specificationID, bugID);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewBugDebugImpl.java b/src/de/bugplus/development/BugplusStatementNewBugDebugImpl.java
new file mode 100644
index 0000000..06c3328
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewBugDebugImpl.java
@@ -0,0 +1,47 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import de.bugplus.specification.BugplusSpecification;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 22.02.22 22:44
+ * @Version 0.0.1
+ */
+final public class BugplusStatementNewBugDebugImpl extends BugplusStatementNewBugImpl implements BugplusStatementNewBugDebug {
+
+ BugplusStatementNewBugDebugImpl(String specificationID, String bugRoleID) {
+ super(specificationID, bugRoleID);
+ }
+
+ public void apply(BugplusProgramInstanceDebug instance) {
+
+ BugplusSpecification spec = instance.getSpecification().getLibrary().selectSpecification(this.specID);
+ BugplusInstanceDebug newBug = spec.getImplementation(0).instantiateDebug();
+ instance.addBug(this.bugRoleID, newBug);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewBugImpl.java b/src/de/bugplus/development/BugplusStatementNewBugImpl.java
new file mode 100644
index 0000000..4045f3b
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewBugImpl.java
@@ -0,0 +1,67 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import de.bugplus.specification.BugplusSpecification;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 10:43
+ * @Version 0.0.1
+ */
+class BugplusStatementNewBugImpl implements BugplusStatementNewBug {
+
+ protected String specID;
+ protected String bugRoleID;
+
+ private BugplusStatementNewBugImpl() {}
+
+ BugplusStatementNewBugImpl(String specificationID, String bugRoleID) {
+
+ this.specID = specificationID;
+ this.bugRoleID = bugRoleID;
+
+ }
+
+ @Override
+ public void apply(BugplusProgramInstance instance) {
+
+ BugplusSpecification spec = instance.getSpecification().getLibrary().selectSpecification(this.specID);
+ BugplusInstance newBug = spec.getImplementation(0).instantiate();
+ instance.addBug(this.bugRoleID, newBug);
+ }
+
+ @Override
+ public String getSpecificationID() {
+ return this.specID;
+ }
+
+ @Override
+ public String getBugRoleID() {
+ return this.bugRoleID;
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewFlow.java b/src/de/bugplus/development/BugplusStatementNewFlow.java
new file mode 100644
index 0000000..a4295c4
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewFlow.java
@@ -0,0 +1,34 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 16:25
+ * @Version 0.0.1
+ */
+interface BugplusStatementNewFlow extends BugplusStatement {
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewFlowControl.java b/src/de/bugplus/development/BugplusStatementNewFlowControl.java
new file mode 100644
index 0000000..5d04daa
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewFlowControl.java
@@ -0,0 +1,39 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 11:42
+ * @Version 0.0.1
+ */
+interface BugplusStatementNewFlowControl extends BugplusStatementNewFlow {
+
+ static BugplusStatementNewFlowControl getInstance(String idSourceBug, int indexControlOut, String idTargetBug) {
+
+ return new BugplusStatementNewFlowControlImpl(idSourceBug, indexControlOut, idTargetBug);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewFlowControlImpl.java b/src/de/bugplus/development/BugplusStatementNewFlowControlImpl.java
new file mode 100644
index 0000000..e7cc136
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewFlowControlImpl.java
@@ -0,0 +1,57 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 11:42
+ * @Version 0.0.1
+ */
+final class BugplusStatementNewFlowControlImpl implements BugplusStatementNewFlowControl {
+
+ private String sourceBugID;
+ private int indexControlOut;
+ private String targetBugID;
+
+
+ private BugplusStatementNewFlowControlImpl() {}
+
+ BugplusStatementNewFlowControlImpl(String idSourceBug, int indexControlOut, String idTargetBug) {
+
+ this.sourceBugID = idSourceBug;
+ this.indexControlOut = indexControlOut;
+ this.targetBugID = idTargetBug;
+ }
+
+ @Override
+ public void apply(BugplusProgramInstance instance) {
+
+ BugplusControlOutPin controlOutPin = instance.getControlOutPinsOf(this.sourceBugID).get(this.indexControlOut);
+ BugplusControlInPin controlInPin = instance.getBugs().get(this.targetBugID).getControlIn();
+
+ controlOutPin.setFlowTarget(controlInPin);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewFlowData.java b/src/de/bugplus/development/BugplusStatementNewFlowData.java
new file mode 100644
index 0000000..f7ca24d
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewFlowData.java
@@ -0,0 +1,38 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 03.02.22 22:44
+ * @Version 0.0.1
+ */
+interface BugplusStatementNewFlowData extends BugplusStatementNewFlow {
+
+ static BugplusStatementNewFlowData getInstance(String idSourceBug, String idTargetBug, int indexDataIn) {
+ return new BugplusStatementNewFlowDataImpl(idSourceBug, idTargetBug, indexDataIn);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewFlowDataImpl.java b/src/de/bugplus/development/BugplusStatementNewFlowDataImpl.java
new file mode 100644
index 0000000..7d6319c
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewFlowDataImpl.java
@@ -0,0 +1,56 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 11:14
+ * @Version 0.0.1
+ */
+final class BugplusStatementNewFlowDataImpl implements BugplusStatementNewFlowData {
+
+ private String sourceBugID;
+ private String targetBugID;
+ private int indexDataIn;
+
+ private BugplusStatementNewFlowDataImpl() {}
+
+ BugplusStatementNewFlowDataImpl(String idSourceBug, String idTargetBug, int indexDataIn) {
+
+ this.sourceBugID = idSourceBug;
+ this.targetBugID = idTargetBug;
+ this.indexDataIn = indexDataIn;
+ }
+
+ @Override
+ public void apply(BugplusProgramInstance instance) {
+
+ BugplusDataOutPin dataOutPin = instance.getBugs().get(this.sourceBugID).getDataOut();
+ BugplusDataInPin dataInPin = instance.getBugs().get(this.targetBugID).getDataInputs().get(indexDataIn);
+
+ dataOutPin.connect(dataInPin);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnect.java b/src/de/bugplus/development/BugplusStatementNewIFConnect.java
new file mode 100644
index 0000000..bd4d48d
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnect.java
@@ -0,0 +1,34 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 16:26
+ * @Version 0.0.1
+ */
+public interface BugplusStatementNewIFConnect extends BugplusStatement {
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectControlIn.java b/src/de/bugplus/development/BugplusStatementNewIFConnectControlIn.java
new file mode 100644
index 0000000..cf52112
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectControlIn.java
@@ -0,0 +1,40 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 12:36
+ * @Version 0.0.1
+ */
+interface BugplusStatementNewIFConnectControlIn extends BugplusStatementNewIFConnect {
+
+ String getInternalBugID();
+
+ static BugplusStatementNewIFConnectControlIn getInstance(String idInternalBug) {
+ return new BugplusStatementNewIFConnectControlInImpl(idInternalBug);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectControlInDebug.java b/src/de/bugplus/development/BugplusStatementNewIFConnectControlInDebug.java
new file mode 100644
index 0000000..14bd5af
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectControlInDebug.java
@@ -0,0 +1,40 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 21.02.22 23:58
+ * @Version 0.0.1
+ */
+public interface BugplusStatementNewIFConnectControlInDebug extends BugplusStatementNewIFConnectControlIn{
+
+ void apply(BugplusProgramInstanceDebug instance);
+
+ static BugplusStatementNewIFConnectControlInDebug getInstance(String idInternalBug) {
+ return new BugplusStatementNewIFConnectControlInDebugImpl(idInternalBug);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectControlInDebugImpl.java b/src/de/bugplus/development/BugplusStatementNewIFConnectControlInDebugImpl.java
new file mode 100644
index 0000000..5694893
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectControlInDebugImpl.java
@@ -0,0 +1,50 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.lang.reflect.Method;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 21.02.22 23:38
+ * @Version 0.0.1
+ */
+final public class BugplusStatementNewIFConnectControlInDebugImpl extends BugplusStatementNewIFConnectControlInImpl implements BugplusStatementNewIFConnectControlInDebug {
+
+ BugplusStatementNewIFConnectControlInDebugImpl(String idInternalBug) {
+ super(idInternalBug);
+ }
+
+ @Override
+ public void apply(BugplusProgramInstanceDebug instance) {
+
+ BugplusControlInPinDebug controlInPin = instance.getBugs().get(this.internalBugID).getControlIn();
+ BugplusInterface interf = instance.getInterface();
+ instance.getInterface().setControlInput(controlInPin);
+ controlInPin.addBug(instance);
+ }
+
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectControlInImpl.java b/src/de/bugplus/development/BugplusStatementNewIFConnectControlInImpl.java
new file mode 100644
index 0000000..823938f
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectControlInImpl.java
@@ -0,0 +1,57 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 12:36
+ * @Version 0.0.1
+ */
+class BugplusStatementNewIFConnectControlInImpl implements BugplusStatementNewIFConnectControlIn {
+
+ protected String internalBugID;
+
+
+ private BugplusStatementNewIFConnectControlInImpl() {}
+
+ BugplusStatementNewIFConnectControlInImpl(String idInternalBug) {
+
+ this.internalBugID = idInternalBug;
+ }
+
+ @Override
+ public void apply(BugplusProgramInstance instance) {
+
+ BugplusControlInPin controlInPin = instance.getBugs().get(this.internalBugID).getControlIn();
+ instance.getInterface().setControlInput(controlInPin);
+ }
+
+ @Override
+ public String getInternalBugID() {
+
+ return this.internalBugID;
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectControlOut.java b/src/de/bugplus/development/BugplusStatementNewIFConnectControlOut.java
new file mode 100644
index 0000000..4f5c95d
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectControlOut.java
@@ -0,0 +1,40 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 12:45
+ * @Version 0.0.1
+ */
+interface BugplusStatementNewIFConnectControlOut extends BugplusStatementNewIFConnect {
+
+
+
+ static BugplusStatementNewIFConnectControlOut getInstance(String idInternalBug, int indexInternalControlOut, int indexExternalControlOutIF) {
+ return new BugplusStatementNewIFConnectControlOutImpl(idInternalBug, indexInternalControlOut, indexExternalControlOutIF);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectControlOutImpl.java b/src/de/bugplus/development/BugplusStatementNewIFConnectControlOutImpl.java
new file mode 100644
index 0000000..49d5aeb
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectControlOutImpl.java
@@ -0,0 +1,54 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 12:47
+ * @Version 0.0.1
+ */
+final class BugplusStatementNewIFConnectControlOutImpl implements BugplusStatementNewIFConnectControlOut {
+
+ private String internalBugID;
+ private int indexInternalControlOut;
+ private int indexExternalControlOutIF;
+
+
+ private BugplusStatementNewIFConnectControlOutImpl() {}
+
+ BugplusStatementNewIFConnectControlOutImpl(String idInternalBug, int indexInternalControlOut, int indexExternalControlOutIF) {
+
+ this.internalBugID = idInternalBug;
+ this.indexInternalControlOut = indexInternalControlOut;
+ this.indexExternalControlOutIF = indexExternalControlOutIF;
+ }
+
+ @Override
+ public void apply(BugplusProgramInstance instance) {
+
+ instance.getInterface().setControlOutputs(instance.getBugs().get(this.internalBugID).getControlOuts().get(this.indexInternalControlOut), this.indexExternalControlOutIF);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectDataIn.java b/src/de/bugplus/development/BugplusStatementNewIFConnectDataIn.java
new file mode 100644
index 0000000..6a7cfce
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectDataIn.java
@@ -0,0 +1,38 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 11:29
+ * @Version 0.0.1
+ */
+interface BugplusStatementNewIFConnectDataIn extends BugplusStatementNewIFConnect {
+
+ static BugplusStatementNewIFConnectDataIn getInstance(String idInternalBug, int indexInternalDataIn, int indexExternalDataInIF) {
+ return new BugplusStatementNewIFConnectDataInImpl(idInternalBug, indexInternalDataIn, indexExternalDataInIF);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectDataInImpl.java b/src/de/bugplus/development/BugplusStatementNewIFConnectDataInImpl.java
new file mode 100644
index 0000000..b039057
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectDataInImpl.java
@@ -0,0 +1,57 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.List;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 11:30
+ * @Version 0.0.1
+ */
+final class BugplusStatementNewIFConnectDataInImpl implements BugplusStatementNewIFConnectDataIn {
+
+ private String internalBugID;
+ private int indexInternalDataIn;
+ private int indexExternalDataInIF;
+
+
+ private BugplusStatementNewIFConnectDataInImpl() {}
+
+ BugplusStatementNewIFConnectDataInImpl(String idInternalBug, int indexInternalDataIn, int indexExternalDataInIF) {
+
+ this.internalBugID = idInternalBug;
+ this.indexInternalDataIn = indexInternalDataIn;
+ this.indexExternalDataInIF = indexExternalDataInIF;
+ }
+
+ @Override
+ public void apply(BugplusProgramInstance instance) {
+
+ BugplusDataInPin internalDataInPin = instance.getBugs().get(this.internalBugID).getDataInputs().get(this.indexInternalDataIn);
+ instance.getDataInputs().get(this.indexExternalDataInIF).addDataInputToInterface(internalDataInPin);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectDataOut.java b/src/de/bugplus/development/BugplusStatementNewIFConnectDataOut.java
new file mode 100644
index 0000000..947301c
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectDataOut.java
@@ -0,0 +1,38 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 12:29
+ * @Version 0.0.1
+ */
+interface BugplusStatementNewIFConnectDataOut extends BugplusStatementNewIFConnect {
+
+ static BugplusStatementNewIFConnectDataOut getInstance(String idInternalBug) {
+ return new BugplusStatementNewIFConnectDataOutImpl(idInternalBug);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusStatementNewIFConnectDataOutImpl.java b/src/de/bugplus/development/BugplusStatementNewIFConnectDataOutImpl.java
new file mode 100644
index 0000000..f3d91da
--- /dev/null
+++ b/src/de/bugplus/development/BugplusStatementNewIFConnectDataOutImpl.java
@@ -0,0 +1,50 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 05.02.22 12:29
+ * @Version 0.0.1
+ */
+final class BugplusStatementNewIFConnectDataOutImpl implements BugplusStatementNewIFConnectDataOut {
+
+ private String internalBugID;
+
+ private BugplusStatementNewIFConnectDataOutImpl() {}
+
+ BugplusStatementNewIFConnectDataOutImpl(String idInternalBug) {
+
+ this.internalBugID = idInternalBug;
+ }
+
+ @Override
+ public void apply(BugplusProgramInstance instance) {
+
+ BugplusDataOutPin internalDataOutPin = instance.getBugs().get(this.internalBugID).getDataOut();
+ internalDataOutPin.addDataOutputToInterface(instance.getDataOut());
+ }
+}
diff --git a/src/de/bugplus/development/BugplusThread.java b/src/de/bugplus/development/BugplusThread.java
new file mode 100644
index 0000000..379abc7
--- /dev/null
+++ b/src/de/bugplus/development/BugplusThread.java
@@ -0,0 +1,42 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 31.01.22 21:15
+ * @Version 0.0.1
+ */
+public interface BugplusThread extends BugplusControlOutPin {
+
+ void connectInstance(BugplusInstance instance);
+
+ void start();
+
+ static BugplusThread getInstance() {
+ return new BugplusThreadImpl();
+ }
+}
diff --git a/src/de/bugplus/development/BugplusThreadImpl.java b/src/de/bugplus/development/BugplusThreadImpl.java
new file mode 100644
index 0000000..1445844
--- /dev/null
+++ b/src/de/bugplus/development/BugplusThreadImpl.java
@@ -0,0 +1,50 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 31.01.22 21:45
+ * @Version 0.0.1
+ */
+final public class BugplusThreadImpl extends BugplusControlOutPinImpl implements BugplusThread {
+
+
+ @Override
+ public void connectInstance(BugplusInstance instance) {
+
+ this.controlTarget = instance.getControlIn();
+ }
+
+ @Override
+ public void start() {
+
+ if (this.controlTarget == null) {
+ System.out.println("Warning: Thread terminated, but was not connected."); }
+ else {
+ this.controlTarget.execute(); }
+ }
+}
diff --git a/src/de/bugplus/development/BugplusVariable.java b/src/de/bugplus/development/BugplusVariable.java
new file mode 100644
index 0000000..8fff2c1
--- /dev/null
+++ b/src/de/bugplus/development/BugplusVariable.java
@@ -0,0 +1,60 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.Set;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+public interface BugplusVariable {
+
+ Set getWriters();
+ Set getReaders();
+
+ void addWriter(BugplusDataOutPin writer);
+ void addReader(BugplusDataInPin reader);
+
+ void addAllWriters(Set writers);
+ void addAllReaders(Set readers);
+
+ int getValue();
+ void setValue(int v);
+
+ static BugplusVariable getInstance() {
+ return new BugplusVariableImpl();
+ }
+
+ static BugplusVariable getInstance(int value) {
+ return new BugplusVariableImpl(value);
+ }
+
+ static BugplusVariable getInstance(BugplusDataInPin reader, BugplusDataOutPin writer) {
+ return new BugplusVariableImpl(reader,writer);
+ }
+}
diff --git a/src/de/bugplus/development/BugplusVariableImpl.java b/src/de/bugplus/development/BugplusVariableImpl.java
new file mode 100644
index 0000000..ffdbf0c
--- /dev/null
+++ b/src/de/bugplus/development/BugplusVariableImpl.java
@@ -0,0 +1,110 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.development;
+
+import java.util.HashSet;
+import java.util.Set;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+final class BugplusVariableImpl implements BugplusVariable {
+
+ private int value = 0;
+
+ final private Set readers = new HashSet<>();
+ final private Set writers = new HashSet<>();
+
+
+ BugplusVariableImpl() {
+
+ this.value = 0;
+ }
+
+ BugplusVariableImpl(int value) {
+
+ this();
+ this.value = value;
+ }
+
+ BugplusVariableImpl(BugplusDataInPin reader, BugplusDataOutPin writer) {
+
+ this();
+ this.readers.add(reader);
+ this.writers.add(writer);
+ this.value = -1;
+ }
+
+
+ @Override
+ public Set getWriters() {
+ return this.writers;
+ }
+
+ @Override
+ public Set getReaders() {
+ return this.readers;
+ }
+
+ @Override
+ public void addWriter(BugplusDataOutPin writer) {
+ this.writers.add(writer);
+ }
+
+ @Override
+ public void addReader(BugplusDataInPin reader) {
+ this.readers.add(reader);
+ }
+
+ @Override
+ public void addAllWriters(Set ws) {
+ this.writers.addAll(ws);
+ }
+
+ @Override
+ public void addAllReaders(Set rs) {
+ this.readers.addAll(rs);
+ }
+
+ @Override
+ public int getValue() {
+
+ return this.value;
+ }
+
+ @Override
+ public void setValue(int v) {
+
+ this.value = v;
+
+ for (BugplusDataInPin reader : this.readers) {
+
+ reader.updateInterfaceInputs();
+ }
+ }
+}
diff --git a/src/de/bugplus/examples/development/Blueprint.txt b/src/de/bugplus/examples/development/Blueprint.txt
new file mode 100644
index 0000000..05821f0
--- /dev/null
+++ b/src/de/bugplus/examples/development/Blueprint.txt
@@ -0,0 +1,18 @@
+package de.bugplus.examples.development;
+
+import de.bugplus.development.*;
+import de.bugplus.specification.BugplusLibrary;
+import de.bugplus.specification.BugplusProgramSpecification;
+
+import java.util.LinkedList;
+import java.util.List;
+
+public class Challenge {
+ public static void main(String[] args){
+ BugplusLibrary myFunctionLibrary = BugplusLibrary.getInstance();
+ BugplusNEGImplementation negImpl = BugplusNEGImplementation.getInstance();
+ myFunctionLibrary.addSpecification(negImpl.getSpecification());
+
+ //CODE HERE
+ }
+}
\ No newline at end of file
diff --git a/src/de/bugplus/examples/development/BugplusBasicArithmetic.java b/src/de/bugplus/examples/development/BugplusBasicArithmetic.java
new file mode 100644
index 0000000..2d8cf33
--- /dev/null
+++ b/src/de/bugplus/examples/development/BugplusBasicArithmetic.java
@@ -0,0 +1,668 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.examples.development;
+
+import de.bugplus.development.*;
+import de.bugplus.specification.BugplusLibrary;
+import de.bugplus.specification.BugplusProgramSpecification;
+
+import java.util.LinkedList;
+import java.util.List;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 27.01.22 21:59
+ * @Version 0.0.1
+ */
+public class BugplusBasicArithmetic {
+
+ public static void createCoherentComponents(List bugs, BugplusProgramImplementation impl) {
+ for (String s1 : bugs) {
+ for (String s2 : bugs) {
+ impl.addDataFlow(s1, s2, 0);
+ }
+ }
+ }
+
+ public static void main(String[] args) {
+
+
+ //Initialization of a new function library
+
+ BugplusLibrary myFunctionLibrary = BugplusLibrary.getInstance();
+
+ BugplusADDImplementation addImpl = BugplusADDImplementation.getInstance();
+
+ myFunctionLibrary.addSpecification(addImpl.getSpecification());
+
+ BugplusNEGImplementation negImpl = BugplusNEGImplementation.getInstance();
+ myFunctionLibrary.addSpecification(negImpl.getSpecification());
+
+
+ // Design of a basic incrementer
+
+ BugplusProgramSpecification incrementSpec = BugplusProgramSpecification.getInstance("++", 1, 2, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(incrementSpec);
+
+ BugplusProgramImplementation incrementProgram = incrementSpec.addImplementation();
+
+ incrementProgram.addBug("+", "0_001");
+ incrementProgram.addBug("+", "1_001");
+ incrementProgram.addDataFlow("0_001", "1_001", 0);
+
+ incrementProgram.addBug("+", "+_001");
+
+ incrementProgram.addDataFlow("1_001", "+_001", 1);
+ incrementProgram.addControlFlow("1_001", 1, "+_001");
+
+ incrementProgram.connectControlInInterface("1_001");
+ incrementProgram.connectControlOutInterface("+_001", 0, 0);
+ incrementProgram.connectControlOutInterface("+_001", 1, 1);
+ incrementProgram.connectDataInInterface("+_001", 0, 0);
+ incrementProgram.connectDataOutInterface("+_001");
+
+
+ //Design of a basic decrementer
+
+ BugplusProgramSpecification decrementSpec = BugplusProgramSpecification.getInstance("--", 1, 2, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(decrementSpec);
+
+ BugplusProgramImplementation decrementProgram = decrementSpec.addImplementation();
+
+ decrementProgram.addBug("+", "0_001");
+
+ decrementProgram.addBug("+", "-1_001");
+ decrementProgram.addDataFlow("0_001", "-1_001", 1);
+
+ decrementProgram.addBug("+", "+_001");
+ decrementProgram.addDataFlow("-1_001", "+_001", 1);
+ decrementProgram.addControlFlow("-1_001", 1, "+_001");
+
+ decrementProgram.connectControlInInterface("-1_001");
+ decrementProgram.connectControlOutInterface("+_001", 0, 0);
+ decrementProgram.connectControlOutInterface("+_001", 1, 1);
+ decrementProgram.connectDataInInterface("+_001", 0, 0);
+ decrementProgram.connectDataOutInterface("+_001");
+
+
+ //Design of an assignment
+
+ BugplusProgramSpecification assignmentSpec = BugplusProgramSpecification.getInstance(":=", 1, 1, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(assignmentSpec);
+
+ BugplusProgramImplementation assignmentProgram = assignmentSpec.addImplementation();
+
+ assignmentProgram.addBug("+", "0_001");
+
+ assignmentProgram.addBug("+", "+_001");
+ assignmentProgram.addDataFlow("0_001", "+_001", 1);
+
+ assignmentProgram.connectControlInInterface("+_001");
+ assignmentProgram.connectControlOutInterface("+_001", 0, 0);
+ assignmentProgram.connectControlOutInterface("+_001", 1, 0);
+ assignmentProgram.connectDataInInterface("+_001", 0, 0);
+ assignmentProgram.connectDataOutInterface("+_001");
+
+
+ //Design of an increment iterator
+
+ BugplusProgramSpecification iteratorSpec = BugplusProgramSpecification.getInstance("+++", 1, 1, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(iteratorSpec);
+
+ BugplusProgramImplementation iteratorProgram = iteratorSpec.addImplementation();
+
+ iteratorProgram.addBug("+", "0_001");
+
+ iteratorProgram.addBug("+", "1_001");
+ iteratorProgram.addDataFlow("0_001", "1_001", 0);
+
+ iteratorProgram.addBug("+", "+_001");
+ iteratorProgram.addDataFlow("1_001", "+_001", 0);
+ iteratorProgram.addDataFlow("+_001", "+_001", 1);
+ iteratorProgram.addControlFlow("1_001", 1, "+_001");
+
+ iteratorProgram.connectControlInInterface("1_001");
+ iteratorProgram.connectControlOutInterface("+_001", 0, 0);
+ iteratorProgram.connectControlOutInterface("+_001", 1, 0);
+
+ iteratorProgram.connectDataInInterface("+_001", 1, 0);
+ iteratorProgram.connectDataOutInterface("+_001");
+
+
+ //Design of a decrement iterator
+
+ BugplusProgramSpecification negIteratorSpec = BugplusProgramSpecification.getInstance("---", 1, 1, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(negIteratorSpec);
+
+ BugplusProgramImplementation negIteratorProgram = negIteratorSpec.addImplementation();
+
+ negIteratorProgram.addBug("+", "0_001");
+
+ negIteratorProgram.addBug("+", "1_001");
+ negIteratorProgram.addDataFlow("0_001", "1_001", 1);
+
+ negIteratorProgram.addBug("+", "+_001");
+ negIteratorProgram.addDataFlow("1_001", "+_001", 0);
+ negIteratorProgram.addDataFlow("+_001", "+_001", 1);
+ negIteratorProgram.addControlFlow("1_001", 1, "+_001");
+
+ negIteratorProgram.connectControlInInterface("1_001");
+ negIteratorProgram.connectControlOutInterface("+_001", 0, 0);
+ negIteratorProgram.connectControlOutInterface("+_001", 1, 0);
+ negIteratorProgram.connectDataInInterface("+_001", 1, 0);
+ negIteratorProgram.connectDataOutInterface("+_001");
+
+
+ //Design an isZero-Operation
+
+ BugplusProgramSpecification isZeroSpec = BugplusProgramSpecification.getInstance("==0", 1, 2, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(isZeroSpec);
+
+ BugplusProgramImplementation isZeroProgram = isZeroSpec.addImplementation();
+
+ isZeroProgram.addBug("+", "+_001");
+
+ isZeroProgram.connectControlInInterface("+_001");
+ isZeroProgram.connectDataInInterface("+_001", 0, 0);
+ isZeroProgram.connectDataInInterface("+_001", 1, 0);
+ isZeroProgram.connectControlOutInterface("+_001", 0, 1);
+ isZeroProgram.connectControlOutInterface("+_001", 1, 0);
+
+
+ //Design a pseudo-parallel-Operation
+
+ BugplusProgramSpecification pseudoParallelSpec = BugplusProgramSpecification.getInstance("||", 0, 2, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(pseudoParallelSpec);
+
+ BugplusProgramImplementation pseudoParallelProgram = pseudoParallelSpec.addImplementation();
+
+ pseudoParallelProgram.addBug("+", "+_001");
+ pseudoParallelProgram.addBug("++", "++_001");
+ pseudoParallelProgram.addBug("--", "--_001");
+ pseudoParallelProgram.addBug("+", "0_001");
+
+
+ pseudoParallelProgram.addControlFlow("+_001", 0, "++_001");
+ pseudoParallelProgram.addControlFlow("+_001", 1, "--_001");
+
+ pseudoParallelProgram.addDataFlow("0_001", "+_001", 0);
+ pseudoParallelProgram.addDataFlow("++_001", "+_001", 1);
+ pseudoParallelProgram.addDataFlow("--_001", "++_001", 0);
+ pseudoParallelProgram.addDataFlow("--_001", "+_001", 1);
+ pseudoParallelProgram.addDataFlow("++_001", "--_001", 0);
+
+
+ pseudoParallelProgram.connectControlInInterface("+_001");
+ pseudoParallelProgram.connectControlOutInterface("++_001", 0, 0);
+ pseudoParallelProgram.connectControlOutInterface("++_001", 1, 0);
+ pseudoParallelProgram.connectControlOutInterface("--_001", 0, 1);
+ pseudoParallelProgram.connectControlOutInterface("--_001", 1, 1);
+
+
+ //Design an isPositive-Operation
+
+ BugplusProgramSpecification isPositiveSpec = BugplusProgramSpecification.getInstance("?+", 1, 2, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(isPositiveSpec);
+
+ BugplusProgramImplementation isPositiveProgram = isPositiveSpec.addImplementation();
+
+ isPositiveProgram.addBug("+", "0_001");
+ isPositiveProgram.addBug("+", "1_001");
+ isPositiveProgram.addDataFlow("0_001", "1_001", 0);
+ isPositiveProgram.addControlFlow("1_001", 1, "==0_001");
+
+ isPositiveProgram.addBug("==0", "==0_001");
+ isPositiveProgram.addBug(":=", ":=_001");
+ isPositiveProgram.addDataFlow("1_001", ":=_001", 0);
+ isPositiveProgram.addControlFlow("==0_001", 1, ":=_001");
+
+ isPositiveProgram.addControlFlow("==0_001", 0, ":=_002");
+ isPositiveProgram.addBug(":=", ":=_002");
+ isPositiveProgram.addControlFlow(":=_002", 0, ":=_003");
+ isPositiveProgram.addBug(":=", ":=_003");
+ isPositiveProgram.addControlFlow(":=_003", 0, "||_001");
+ isPositiveProgram.addBug("||", "||_001");
+ isPositiveProgram.addControlFlow("||_001", 0, "++_001");
+ isPositiveProgram.addControlFlow("||_001", 1, "--_001");
+ isPositiveProgram.addBug("++", "++_001");
+ isPositiveProgram.addControlFlow("++_001", 0, ":=_004");
+ isPositiveProgram.addControlFlow("++_001", 1, "||_001");
+ isPositiveProgram.addBug("--", "--_001");
+ isPositiveProgram.addControlFlow("--_001", 0, ":=_005");
+ isPositiveProgram.addControlFlow("--_001", 1, "||_001");
+ isPositiveProgram.addBug(":=", ":=_004");
+ isPositiveProgram.addBug(":=", ":=_005");
+
+ isPositiveProgram.addDataFlow(":=_002", "++_001", 0);
+ isPositiveProgram.addDataFlow("++_001", "++_001", 0);
+
+ isPositiveProgram.addDataFlow(":=_003", "--_001", 0);
+ isPositiveProgram.addDataFlow("--_001", "--_001", 0);
+
+ isPositiveProgram.addDataFlow("0_001", ":=_004", 0);
+ isPositiveProgram.addDataFlow("1_001", ":=_005", 0);
+
+
+ isPositiveProgram.connectControlInInterface("1_001");
+ isPositiveProgram.connectDataInInterface("==0_001", 0, 0);
+ isPositiveProgram.connectDataInInterface(":=_002", 0, 0);
+ isPositiveProgram.connectDataInInterface(":=_003", 0, 0);
+ isPositiveProgram.connectDataOutInterface(":=_001");
+ isPositiveProgram.connectDataOutInterface(":=_004");
+ isPositiveProgram.connectDataOutInterface(":=_005");
+ isPositiveProgram.connectControlOutInterface(":=_001", 0, 0);
+ isPositiveProgram.connectControlOutInterface(":=_004", 0, 0);
+ isPositiveProgram.connectControlOutInterface(":=_005", 0, 1);
+
+
+ //Design an Change-Sign-Operation
+
+ BugplusProgramSpecification changeSignSpec = BugplusProgramSpecification.getInstance("-x", 1, 1, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(changeSignSpec);
+
+ BugplusProgramImplementation changeSignProgram = changeSignSpec.addImplementation();
+
+
+ changeSignProgram.addBug("+", "0_001");
+ changeSignProgram.addBug("==0", "==0_001");
+ changeSignProgram.addControlFlow("==0_001", 1, ":=_001");
+ changeSignProgram.addBug(":=", ":=_001");
+ changeSignProgram.addControlFlow("==0_001", 0, ":=_004");
+ changeSignProgram.addBug(":=", ":=_004");
+ changeSignProgram.addControlFlow(":=_004", 0, "?+_001");
+ changeSignProgram.addBug("?+", "?+_001");
+ changeSignProgram.addControlFlow("?+_001", 0, ":=_002");
+ changeSignProgram.addBug(":=", ":=_002");
+ changeSignProgram.addControlFlow("?+_001", 1, ":=_003");
+ changeSignProgram.addBug(":=", ":=_003");
+ changeSignProgram.addControlFlow(":=_002", 0, "+++_001");
+ changeSignProgram.addBug("+++", "+++_001");
+ changeSignProgram.addControlFlow(":=_003", 0, "---_001");
+ changeSignProgram.addBug("---", "---_001");
+ changeSignProgram.addControlFlow("+++_001", 0, "++_001");
+ changeSignProgram.addBug("++", "++_001");
+ changeSignProgram.addControlFlow("---_001", 0, "--_001");
+ changeSignProgram.addBug("--", "--_001");
+ changeSignProgram.addControlFlow("++_001", 1, "+++_001");
+ changeSignProgram.addControlFlow("--_001", 1, "---_001");
+
+
+ changeSignProgram.addDataFlow("0_001", ":=_004", 0);
+ changeSignProgram.addDataFlow(":=_004", "+++_001", 0);
+ changeSignProgram.addDataFlow(":=_004", "---_001", 0);
+
+ changeSignProgram.addDataFlow(":=_002", "++_001", 0);
+ changeSignProgram.addDataFlow("++_001", "++_001", 0);
+
+ changeSignProgram.addDataFlow(":=_003", "--_001", 0);
+ changeSignProgram.addDataFlow("--_001", "--_001", 0);
+
+
+ changeSignProgram.connectControlInInterface("==0_001");
+ changeSignProgram.connectControlOutInterface(":=_001", 0, 0);
+ changeSignProgram.connectControlOutInterface("++_001", 0, 0);
+ changeSignProgram.connectControlOutInterface("--_001", 0, 0);
+
+ changeSignProgram.connectDataInInterface("==0_001", 0, 0);
+ changeSignProgram.connectDataInInterface("?+_001", 0, 0);
+ changeSignProgram.connectDataInInterface(":=_001", 0, 0);
+ changeSignProgram.connectDataInInterface(":=_002", 0, 0);
+ changeSignProgram.connectDataInInterface(":=_003", 0, 0);
+
+ changeSignProgram.connectDataOutInterface(":=_001");
+ changeSignProgram.connectDataOutInterface("+++_001");
+ changeSignProgram.connectDataOutInterface("---_001");
+
+
+ //Design a Minus-Operation
+
+ BugplusProgramSpecification minusSpec = BugplusProgramSpecification.getInstance("-", 2, 2, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(minusSpec);
+
+ BugplusProgramImplementation minusProgram = minusSpec.addImplementation();
+
+ minusProgram.addBug("-x", "-x_001");
+ minusProgram.addBug("+", "+_001");
+
+ minusProgram.addControlFlow("-x_001", 0, "+_001");
+ minusProgram.addDataFlow("-x_001", "+_001", 1);
+
+ minusProgram.connectControlInInterface("-x_001");
+ minusProgram.connectControlOutInterface("+_001", 0, 0);
+ minusProgram.connectControlOutInterface("+_001", 1, 1);
+
+ minusProgram.connectDataInInterface("+_001", 0, 0);
+ minusProgram.connectDataInInterface("-x_001", 0, 1);
+ minusProgram.connectDataOutInterface("+_001");
+
+
+ //Design a Compare-Operation
+
+ BugplusProgramSpecification compareSpec = BugplusProgramSpecification.getInstance("==", 2, 2, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(compareSpec);
+
+ BugplusProgramImplementation compareProgram = compareSpec.addImplementation();
+
+ compareProgram.addBug("+", "0_001");
+ compareProgram.addBug("+", "1_001");
+ compareProgram.addDataFlow("0_001", "1_001", 0);
+ compareProgram.addControlFlow("1_001", 1, "-_001");
+
+ compareProgram.addBug("-", "-_001");
+ compareProgram.addControlFlow("-_001", 0, ":=_001");
+ compareProgram.addBug(":=", ":=_001");
+ compareProgram.addControlFlow("-_001", 1, ":=_002");
+ compareProgram.addBug(":=", ":=_002");
+
+ compareProgram.addDataFlow("1_001", ":=_001", 0);
+ compareProgram.addDataFlow("0_001", ":=_002", 0);
+
+
+ compareProgram.connectControlInInterface("1_001");
+ compareProgram.connectControlOutInterface(":=_002", 0, 0);
+ compareProgram.connectControlOutInterface(":=_001", 0, 1);
+
+ compareProgram.connectDataInInterface("-_001", 0, 0);
+ compareProgram.connectDataInInterface("-_001", 1, 1);
+ compareProgram.connectDataOutInterface(":=_001");
+ compareProgram.connectDataOutInterface(":=_002");
+
+
+ //Design a Multiply-Operation
+
+ BugplusProgramSpecification multiplySpec = BugplusProgramSpecification.getInstance("*", 2, 1, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(multiplySpec);
+
+ BugplusProgramImplementation multiplyProgram = multiplySpec.addImplementation();
+
+
+ multiplyProgram.addBug("+", "0_001");
+ multiplyProgram.addBug("+", "0_002");
+ multiplyProgram.addBug("+", "0_003");
+ multiplyProgram.addControlFlow("0_001", 0, "0_002");
+ multiplyProgram.addControlFlow("0_002", 0, "0_003");
+ multiplyProgram.addControlFlow("0_003", 0, "==_001");
+
+ multiplyProgram.addBug("==", "==_001");
+ multiplyProgram.addControlFlow("==_001", 1, ":=_001");
+ multiplyProgram.addBug(":=", ":=_001");
+ multiplyProgram.addControlFlow("==_001", 0, "==_002");
+ multiplyProgram.addBug("==", "==_002");
+ multiplyProgram.addControlFlow("==_002", 1, ":=_001");
+ multiplyProgram.addControlFlow("==_002", 0, "+_001");
+ multiplyProgram.addBug("+", "+_001");
+ multiplyProgram.addControlFlow("+_001", 1, "+++_001");
+ multiplyProgram.addBug("+++", "+++_001");
+ multiplyProgram.addControlFlow("+++_001", 0, "==_001");
+
+ multiplyProgram.addDataFlow("0_001", "==_001", 1);
+ multiplyProgram.addDataFlow("0_002", ":=_001", 0);
+ multiplyProgram.addDataFlow("0_003", "==_002", 1);
+ multiplyProgram.addDataFlow("0_002", "+_001", 1);
+ multiplyProgram.addDataFlow("0_001", "+++_001", 0);
+
+ multiplyProgram.addDataFlow("+_001", ":=_001", 0);
+ multiplyProgram.addDataFlow("+_001", "+_001", 1);
+ multiplyProgram.addDataFlow("+++_001", "==_001", 1);
+
+
+ multiplyProgram.connectControlInInterface("0_001");
+ multiplyProgram.connectControlOutInterface(":=_001", 0, 0);
+
+ multiplyProgram.connectDataInInterface("==_001", 0, 0);
+ multiplyProgram.connectDataInInterface("==_002", 0, 1);
+ multiplyProgram.connectDataInInterface("+_001", 0, 1);
+ multiplyProgram.connectDataOutInterface(":=_001");
+
+
+ //Application of the isZero-operation which is available in the library
+
+ BugplusProgramSpecification isZeroTestSpec = BugplusProgramSpecification.getInstance("==0_Test", 3, 1, myFunctionLibrary);
+ BugplusProgramImplementation isZeroTestImpl = isZeroTestSpec.addImplementation();
+
+ isZeroTestImpl.addBug(":=", ":=_001");
+ isZeroTestImpl.addBug(":=", ":=_002");
+ isZeroTestImpl.addBug("==0", "==0_001");
+
+ isZeroTestImpl.addControlFlow("==0_001", 0, ":=_001");
+ isZeroTestImpl.addControlFlow("==0_001", 1, ":=_002");
+
+ isZeroTestImpl.connectControlInInterface("==0_001");
+ isZeroTestImpl.connectDataInInterface("==0_001", 0, 0);
+ isZeroTestImpl.connectDataInInterface(":=_001", 0, 1);
+ isZeroTestImpl.connectDataInInterface(":=_002", 0, 2);
+ isZeroTestImpl.connectDataOutInterface(":=_001");
+ isZeroTestImpl.connectDataOutInterface(":=_002");
+ isZeroTestImpl.connectControlOutInterface(":=_001", 0, 0);
+ isZeroTestImpl.connectControlOutInterface(":=_002", 0, 0);
+
+ //Max Node:
+ BugplusProgramSpecification maxSpec = BugplusProgramSpecification.getInstance("max", 2, 2, myFunctionLibrary);
+ BugplusProgramImplementation maxImpl = maxSpec.addImplementation();
+
+ maxImpl.addBug("-", "-_001");
+ maxImpl.addBug("?+", "?+_001");
+ maxImpl.addBug(":=", ":=_001");
+ maxImpl.addBug(":=", ":=_002");
+
+ maxImpl.addDataFlow("-_001", "?+_001", 0);
+
+ maxImpl.connectDataInInterface(":=_001", 0, 1);
+ maxImpl.connectDataInInterface(":=_002", 0, 0);
+
+ maxImpl.connectDataInInterface("-_001", 0, 0);
+ maxImpl.connectDataInInterface("-_001", 1, 1);
+
+ maxImpl.connectDataOutInterface(":=_001");
+ maxImpl.connectDataOutInterface(":=_002");
+
+ maxImpl.connectControlOutInterface(":=_001", 0, 0);
+ maxImpl.connectControlOutInterface(":=_002", 0, 1);
+
+ maxImpl.connectControlInInterface("-_001");
+
+ maxImpl.addControlFlow("-_001", 0, "?+_001");
+ maxImpl.addControlFlow("-_001", 1, "?+_001");
+ maxImpl.addControlFlow("?+_001", 0, ":=_001");
+ maxImpl.addControlFlow("?+_001", 1, ":=_002");
+
+
+ //Min Node:
+ BugplusProgramSpecification minSpec = BugplusProgramSpecification.getInstance("min", 2, 2, myFunctionLibrary);
+ BugplusProgramImplementation minImpl = maxSpec.addImplementation();
+
+ minImpl.addBug("-", "-_001");
+ minImpl.addBug("?+", "?+_001");
+ minImpl.addBug(":=", ":=_001");
+ minImpl.addBug(":=", ":=_002");
+
+ minImpl.addDataFlow("-_001", "?+_001", 0);
+
+ minImpl.connectDataInInterface(":=_001", 0, 0);
+ minImpl.connectDataInInterface(":=_002", 0, 1);
+
+ minImpl.connectDataInInterface("-_001", 0, 0);
+ minImpl.connectDataInInterface("-_001", 1, 1);
+
+ minImpl.connectDataOutInterface(":=_001");
+ minImpl.connectDataOutInterface(":=_002");
+
+ minImpl.connectControlOutInterface(":=_001", 0, 0);
+ minImpl.connectControlOutInterface(":=_002", 0, 1);
+
+ minImpl.connectControlInInterface("-_001");
+
+ minImpl.addControlFlow("-_001", 0, "?+_001");
+ minImpl.addControlFlow("-_001", 1, "?+_001");
+ minImpl.addControlFlow("?+_001", 0, ":=_001");
+ minImpl.addControlFlow("?+_001", 1, ":=_002");
+
+
+ //Test Negation Node:
+ BugplusProgramSpecification negTestSpec = BugplusProgramSpecification.getInstance("!0_Test", 0, 2, myFunctionLibrary);
+ BugplusProgramImplementation negTestImpl = negTestSpec.addImplementation();
+
+
+ negTestImpl.addBug("!", "!_001"); //-> internalState(bug) = 200 + dataIn(bug) = 200
+ negTestImpl.addBug("!", "!_002");
+ negTestImpl.addBug("!", "!_003");
+
+ // System.out.println(negImpl.instantiate());
+
+ LinkedList bugids = new LinkedList();
+ bugids.add("!_001");
+ bugids.add("!_002");
+ bugids.add("!_003");
+ negTestImpl.addBug("!", "!_004");
+ negTestImpl.addControlFlow("!_001", 0, "!_002");
+ negTestImpl.addControlFlow("!_001", 1, "!_003");
+ //negTestImpl.addDataFlow("!_001", "!_001", 0);
+ //negTestImpl.addDataFlow("!_002", "!_002", 0);
+ //negTestImpl.addDataFlow("!_003", "!_003", 0);
+
+ //Zahnraeder
+ createCoherentComponents(bugids, negTestImpl);
+
+ negTestImpl.connectControlInInterface("!_001");
+ //negTestImpl.connectDataInInterface("!_001", 0, 0);
+ //negTestImpl.connectDataInInterface("!_002", 0, 1);
+ //negTestImpl.connectDataInInterface("!_003", 0, 2);
+ //negTestImpl.connectDataOutInterface("!_001");
+ negTestImpl.connectDataOutInterface("!_002");
+ negTestImpl.connectDataOutInterface("!_003");
+ negTestImpl.connectControlOutInterface("!_002", 0, 0);
+ negTestImpl.connectControlOutInterface("!_002", 1, 1);
+ negTestImpl.connectControlOutInterface("!_003", 0, 0);
+ negTestImpl.connectControlOutInterface("!_003", 1, 1);
+
+
+ BugplusInstance testInstance = negTestImpl.instantiate();
+ BugplusProgramInstanceImpl test = (BugplusProgramInstanceImpl) testInstance;
+ test.getBugs().get("!_001").setInternalState(0);
+ test.getBugs().get("!_002").setInternalState(1);
+ test.getBugs().get("!_003").setInternalState(1);
+ test.getBugs().get("!_004").setInternalState(0);
+
+ System.out.println("Starting State " + "!_001 : " + test.getBugs().get("!_001").getInternalState());
+ System.out.println("Starting State " + "!_002 : " + test.getBugs().get("!_002").getInternalState());
+ System.out.println("Starting State " + "!_003 : " + test.getBugs().get("!_003").getInternalState());
+ System.out.println("Starting State " + "!_004 : " + test.getBugs().get("!_004").getInternalState()+"\n");
+
+
+ System.out.println("Data Ins:");
+ System.out.println("Data In " + "!_001 : " + test.getBugs().get("!_001").getDataInputs().get(0).getVariable().getValue());
+ System.out.println("Data In " + "!_002 : " + test.getBugs().get("!_002").getDataInputs().get(0).getVariable().getValue());
+ System.out.println("Data In " + "!_003 : " + test.getBugs().get("!_003").getDataInputs().get(0).getVariable().getValue());
+ System.out.println("Data In " + "!_004 : " + test.getBugs().get("!_004").getDataInputs().get(0).getVariable().getValue() +"\n");
+
+// Application
+ // for (String s : bugids) {
+ // System.out.println(s);
+ // }
+
+
+ //System.out.println(negTestImpl.instantiate());
+ //BugplusInstance testInstance = multiplyProgram.instantiateDebug();
+// testInstance = negTestImpl.instantiate();
+
+// testInstance = maxImpl.instantiate();
+
+// testInstance = isPositiveProgram.instantiate();
+
+ //testInstance.setInputValue(0, 1);
+ //testInstance.setInputValue(1, 0);
+ //testInstance.setInputValue(2, 0);
+ //testInstance.setInputValue(1,3);
+ //testInstance.setInputValue(2,53);
+
+
+ BugplusThread newThread = BugplusThread.getInstance();
+ newThread.connectInstance(testInstance);
+
+
+ newThread.start();
+ System.out.println("Hier das Ergebnis: " + testInstance.getOutputValue());
+// System.out.println(testInstance.getControlOuts().get(0));
+ //System.out.println("Internal State: " + testInstance.getInternalState());
+ test = (BugplusProgramInstanceImpl) testInstance;
+ for (
+ String s : bugids) {
+ test.getBugs().get(s).setInternalState(test.getBugs().get(s).getDataInputs().get(0).getVariable().getValue());
+
+ System.out.println("Internal State " + s + ": " +test.getBugs().get(s).getInternalState());
+ }
+
+ /**
+ for (int i = 0; i < negTestImpl.getBugs().size(); i++) {
+ System.out.println(negTestImpl.getBugs().size());
+ BugplusInstance bi = (BugplusInstance) negTestImpl.getBugs().toArray()[i];
+ System.out.println(bi.getInternalState());
+ //System.out.println(incrementProgram.getBugs().toArray()[i]);
+ }
+ */
+// testInstance.setInputValue(0,-6);
+
+ newThread.start();
+ System.out.println("Hier das Ergebnis: " + testInstance.getOutputValue());
+ for (
+ String s : bugids) {
+ test.getBugs().get(s).setInternalState(test.getBugs().get(s).getDataInputs().get(0).getVariable().getValue());
+
+ System.out.println("Internal State " + s + ": " +test.getBugs().get(s).getInternalState());
+ }
+// // testInstance.setInputValue(0,-1);
+//
+// newThread.start();
+// System.out.println("Hier das Ergebnis: " + testInstance.getOutputValue());
+// for (
+// String s; :bugids)
+//
+// {
+// System.out.println(test.getBugs().get(s).getInternalState());
+// }
+// // testInstance.setInputValue(0,23);
+//
+// newThread.start();
+// System.out.println("Hier das Ergebnis: " + testInstance.getOutputValue());
+// for (
+// String s; :bugids)
+//
+// {
+// System.out.println(test.getBugs().get(s).getInternalState());
+// }
+
+
+ //1. NullerInput bei DataIn
+ //2. Alle gleichen Zustand (auch ohne ControlFlow)
+ /**
+ * Wir haben herausgefunden:
+ * 1. Bugs, die mit ihren DataPins verbunden sind, haben alle das gleiche DataIn-Signal anliegen
+ * 1.1 obwohl alle gleiches DataIn-Signal haben, aktualisiert jeder Bug immer nur, wenn bei ihm der Control Flow anliegt (Zustaende synchronisieren sich nicht)
+ * 2. Bugs, die nicht verbunden sind, haben ihr eigenes DataIn-Signal
+ *
+ */
+ }
+}
diff --git a/src/de/bugplus/examples/development/Bugplus_Translator_newSpec.java b/src/de/bugplus/examples/development/Bugplus_Translator_newSpec.java
new file mode 100644
index 0000000..9aaee99
--- /dev/null
+++ b/src/de/bugplus/examples/development/Bugplus_Translator_newSpec.java
@@ -0,0 +1,143 @@
+package de.bugplus.examples.development;
+
+import de.bugplus.development.*;
+import de.bugplus.specification.BugplusLibrary;
+import de.bugplus.specification.BugplusProgramSpecification;
+
+public class Bugplus_Translator_newSpec {
+ private static int[] execTimes;
+
+
+ public static int[] execute(int numBugs, int[][] cfMatrix, int[][] dfMatrix, int[][] spec_input) {
+ BugplusLibrary myFunctionLibrary = BugplusLibrary.getInstance();
+ BugplusADDImplementation addImpl = BugplusADDImplementation.getInstance();
+ myFunctionLibrary.addSpecification(addImpl.getSpecification());
+
+ BugplusProgramSpecification Program = BugplusProgramSpecification.getInstance("bug_program", 2, 2, myFunctionLibrary);
+ myFunctionLibrary.addSpecification(Program);
+ BugplusProgramImplementation program_impl = Program.addImplementation();
+ for (int i = 0; i < numBugs; i++) {
+ String bugId = "+_" + i;
+ program_impl.addBug("+", bugId);
+ //System.out.println("Add Bug " + bugId);
+ //qm_impl.addDataFlow(bugId, bugId, 0);
+ }
+
+
+ for (int i = 0; i < cfMatrix.length - 2; i++) {
+ for (int j = 0; j < cfMatrix[0].length - 1; j++) {
+ if (cfMatrix[i][j] == 1) {
+ program_impl.addControlFlow("+_" + (j / 2), j % 2, "+_" + i);
+ //System.out.println("addControlFlow( +_" + (j / 2) + " , " + j % 2 + " , " + "+_" + i + ")");
+ }
+ }
+ }
+
+
+ //C_Out Interfaces:
+ for (int i = cfMatrix.length - 2; i < cfMatrix.length; i++) {
+ for (int j = 0; j < cfMatrix[0].length - 1; j++) { //last column means we connect in-interface directly to out-interface
+ if (cfMatrix[i][j] == 1) {
+ program_impl.connectControlOutInterface("+_" + (j / 2), j % 2, i == cfMatrix.length - 2 ? 0 : 1);
+ //System.out.println("connectControlOutInterface(+_ " + (j / 2) + " , " + (j % 2) + " , " + (i == cfMatrix.length - 2 ? 0 : 1) + ")");
+ }
+ }
+ }
+
+ //C_In Interface:
+ for (int i = 0; i < cfMatrix.length; i++) {
+ if (cfMatrix[i][cfMatrix[0].length - 1] == 1) {
+ if (i != cfMatrix.length - 1 && i != cfMatrix.length - 2) { // last two rows means we connect in-interface directly to out-interface
+ program_impl.connectControlInInterface("+_" + (i));
+ //System.out.println("connectControlInInterface(+_ " + (i) + ")");
+ } //else
+ //System.out.println("Can't connect in-interface to out-interface");
+ }
+ }
+
+
+ //DataFlow Matrix:
+ for (int i = 0; i < dfMatrix.length - 1; i++) {
+ for (int j = 0; j < dfMatrix[0].length - 2; j++) {
+ if (dfMatrix[i][j] == 1) {
+ program_impl.addDataFlow("+_" + j, "+_" + (i / 2), i % 2);
+ //System.out.println("addDataFlow(+_ " + j + " , +_" + (i / 2) + " , " + i % 2 + ")");
+ }
+ }
+ }
+
+
+ //D_IN Interfaces:
+ for (int i = 0; i < dfMatrix.length - 1; i++) {
+ for (int j = dfMatrix[0].length - 2; j < dfMatrix[0].length; j++) {
+ if (dfMatrix[i][j] == 1) {
+ program_impl.connectDataInInterface("+_" + (i / 2), i % 2, j == dfMatrix[0].length - 2 ? 0 : 1);
+ //System.out.println("connectDataInInterface(+_" + (i / 2) + " , " + i % 2 + " , " + (j == dfMatrix[0].length - 2 ? 0 : 1) + ")");
+ }
+ }
+ }
+
+ //D_OUT Interface:
+ for (int j = 0; j < dfMatrix[0].length; j++) {
+ if (dfMatrix[dfMatrix.length - 1][j] == 1) {
+ if (j < dfMatrix[0].length - 2) { //last row means we connect in-interface directly to out-interface
+ program_impl.connectDataOutInterface("+_" + (j));
+ //System.out.println("connectDataOutInterface(+_" + j + ")");
+ }// else
+ //System.out.println("Can't connect DataIn-interface to DataOut-interface");
+ }
+ }
+
+
+ BugplusInstance cftInstance = program_impl.instantiate();
+ BugplusProgramInstanceImpl cft_instance_impl = cftInstance.getInstanceImpl();
+ BugplusThread newThread = BugplusThread.getInstance();
+ newThread.connectInstance(cftInstance);
+
+ int diff = 0;
+ int[] outputs = new int[spec_input.length];
+
+ for (int i = 0; i < spec_input.length; i++) {
+ cftInstance.setInputValue(0, spec_input[i][0]);
+ cftInstance.setInputValue(1, spec_input[i][1]);
+
+ newThread.start();
+ outputs[i] = cftInstance.getOutputValue();
+
+
+// System.out.println(cftInstance.getOutputValue());
+ }
+
+
+ return outputs;
+
+ }
+
+ public static void main(String[] args) {
+ int[] bitSpec = {1, 1, 1};
+ int[][] cfMatrix = {
+ {0, 0, 1},
+ {1, 0, 0},
+ {0, 1, 0}
+ };
+ // Out1 Out2 CIN
+ //BitIN
+ //COut1
+ //COut2
+ int[][] dfMatrix = {
+ {0, 1, 0},
+ {0, 0, 1},
+ {1, 0, 0}
+ };
+
+ // BitOut DIN1 DIN2
+ //BitIN1
+ //BitIn2
+ //ROut
+ int[][] specInput = {{1, 1}, {2, 3}, {4, 5}};
+ int[] outs = execute(1, cfMatrix, dfMatrix, specInput);
+ for (int i : outs) {
+ System.out.println(i);
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/de/bugplus/examples/development/CFTranslateBlueprint.txt b/src/de/bugplus/examples/development/CFTranslateBlueprint.txt
new file mode 100644
index 0000000..8a9081d
--- /dev/null
+++ b/src/de/bugplus/examples/development/CFTranslateBlueprint.txt
@@ -0,0 +1,104 @@
+package de.bugplus.examples.development;
+
+import de.bugplus.development.*;
+import de.bugplus.specification.BugplusLibrary;
+import de.bugplus.specification.BugplusProgramSpecification;
+
+import java.util.Arrays;
+import java.util.LinkedList;
+import java.util.List;
+
+public class CF_Translated {
+ public static int[] execute(int num_bugs, int[][] cfMatrix) {
+ BugplusLibrary myFunctionLibrary = BugplusLibrary.getInstance();
+ BugplusNEGImplementation negImpl = BugplusNEGImplementation.getInstance();
+ myFunctionLibrary.addSpecification(negImpl.getSpecification());
+
+ //CODE HERE
+ BugplusProgramSpecification CF_Translate_Specification = BugplusProgramSpecification.getInstance("CF_Translate", 0, 2, myFunctionLibrary);
+ BugplusProgramImplementation cft_impl = CF_Translate_Specification.addImplementation();
+ for (int i = 0; i < num_bugs; i++) {
+ String bugId = "!_" + i;
+ cft_impl.addBug("!", bugId);
+ cft_impl.addDataFlow(bugId, bugId, 0);
+ }
+ /*
+ for i in range(self.N):
+ for j in range(2 * self.N):
+ if self.cfMatrix[i, j] == 1:
+ self.write_to_file(
+ f'cft_impl.addControlFlow("!_{int(j / 2)}", {j % 2}, "!_{i}");'
+ )
+ */
+
+
+ for (int i = 0; i < cfMatrix.length; i++) {
+ for (int j = 0; j < cfMatrix[0].length; j++) {
+ if (cfMatrix[i][j] == 1) {
+ cft_impl.addControlFlow("!_" + (j / 2), j % 2, "!_" + i);
+ }
+ }
+ }
+ cft_impl.connectControlInInterface("!_0");
+ BugplusInstance cftInstance = cft_impl.instantiate();
+ BugplusProgramInstanceImpl cft_instance_impl = cftInstance.getInstanceImpl();
+ BugplusThread newThread = BugplusThread.getInstance();
+ newThread.connectInstance(cftInstance);
+ newThread.start();
+ int[] internalStates = new int[num_bugs];
+ for (int i = 0; i < num_bugs; i++) {
+ internalStates[i] = cft_instance_impl.getBugs().get("!_" + i).getInternalState();
+ }
+ return internalStates;
+
+ }
+
+ public static int obtain_reward(int[] bit_specification, int[][] cfMatrix) {
+ //System.out.println(bit_specification);
+ //System.out.println(Arrays.toString(bit_specification));
+ for (int[] i : cfMatrix) {
+ //System.out.println(Arrays.toString(i));
+ }
+ //System.out.println(cfMatrix);
+ int reward = 0;
+ try {
+ int[] internalStates = execute(cfMatrix.length, cfMatrix);
+ for (int i : internalStates) {
+ //System.out.println("Internal State: " + i);
+ }
+ //reward = 0;
+ boolean same_arrays = true;
+ for (int i = 0; i < bit_specification.length; i++) {
+ if (bit_specification[i] == -1) {
+ continue;
+ }
+ if (bit_specification[i] != internalStates[i]) {
+ //reward -= 20;
+ same_arrays = false;
+ }else{
+ reward += 1;
+ }
+ }
+ //give high reward if correct
+ if (same_arrays) {
+ reward += 1000;
+ // System.out.println("Solved");
+ }
+ } catch (IllegalStateException ise) {
+ //System.out.println("Illegal State Exception: " + ise.toString());
+ reward = -10;
+ } catch (StackOverflowError soe){
+ //System.out.println("Stack Overflow Error: " + soe.toString());
+ reward = -10;
+ }
+ //System.out.println(reward);
+ return reward;
+ }
+
+ public static void main(String[] args) {
+ int[] bitSpec = {1, 1, 1};
+ int[][] cfMatrix = {{1, 1, 0, 0, 0, 0, 0}, {0, 0, 0, 0, 0, 0, 0}, {0, 0, 0, 0, 0, 0, 0}};
+ int reward = obtain_reward(bitSpec, cfMatrix);
+ //System.out.println(reward);
+ }
+}
\ No newline at end of file
diff --git a/src/de/bugplus/examples/development/CF_Translated.java b/src/de/bugplus/examples/development/CF_Translated.java
new file mode 100644
index 0000000..779f1a5
--- /dev/null
+++ b/src/de/bugplus/examples/development/CF_Translated.java
@@ -0,0 +1,196 @@
+package de.bugplus.examples.development;
+
+import de.bugplus.development.*;
+import de.bugplus.specification.BugplusLibrary;
+import de.bugplus.specification.BugplusProgramSpecification;
+
+public class CF_Translated {
+ private static int[] execTimes;
+
+ public static int[] execute(int num_bugs, int[][] cfMatrix, int[] positions) {
+ BugplusLibrary myFunctionLibrary = BugplusLibrary.getInstance();
+ BugplusNEGImplementation negImpl = BugplusNEGImplementation.getInstance();
+ myFunctionLibrary.addSpecification(negImpl.getSpecification());
+
+ //CODE HERE
+ BugplusProgramSpecification CF_Translate_Specification = BugplusProgramSpecification.getInstance("CF_Translate", 0, 2, myFunctionLibrary);
+ BugplusProgramImplementation cft_impl = CF_Translate_Specification.addImplementation();
+ for (int i = 0; i < num_bugs; i++) {
+ String bugId = "!_" + i;
+ cft_impl.addBug("!", bugId);
+ cft_impl.addDataFlow(bugId, bugId, 0);
+ }
+
+
+ for (int i = 0; i < cfMatrix.length; i++) {
+ for (int j = 0; j < cfMatrix[0].length; j++) {
+ if (cfMatrix[i][j] == 1) {
+ cft_impl.addControlFlow("!_" + (j / 2), j % 2, "!_" + i);
+ }
+ }
+ }
+ cft_impl.connectControlInInterface("!_0");
+ BugplusInstance cftInstance = cft_impl.instantiate();
+ BugplusProgramInstanceImpl cft_instance_impl = cftInstance.getInstanceImpl();
+ BugplusThread newThread = BugplusThread.getInstance();
+ newThread.connectInstance(cftInstance);
+
+ //set internal states
+ for (int i = 0; i < num_bugs; i++) {
+ cft_instance_impl.getBugs().get("!_" + i).setInternalState(positions[i]);
+ }
+
+ newThread.start();
+ int[] internalStates = new int[num_bugs];
+ execTimes = new int[num_bugs];
+
+ for (int i = 0; i < num_bugs; i++) {
+ internalStates[i] = cft_instance_impl.getBugs().get("!_" + i).getInternalState();
+ execTimes[i] = cft_instance_impl.getBugs().get("!_" + i).getCallCounter();
+ }
+ return internalStates;
+ }
+
+ public static int[] execute(int num_bugs, int[][] cfMatrix) {
+ BugplusLibrary myFunctionLibrary = BugplusLibrary.getInstance();
+ BugplusNEGImplementation negImpl = BugplusNEGImplementation.getInstance();
+ myFunctionLibrary.addSpecification(negImpl.getSpecification());
+
+ //CODE HERE
+ BugplusProgramSpecification CF_Translate_Specification = BugplusProgramSpecification.getInstance("CF_Translate", 0, 2, myFunctionLibrary);
+ BugplusProgramImplementation cft_impl = CF_Translate_Specification.addImplementation();
+ for (int i = 0; i < num_bugs; i++) {
+ String bugId = "!_" + i;
+ cft_impl.addBug("!", bugId);
+ cft_impl.addDataFlow(bugId, bugId, 0);
+ }
+ /*
+ for i in range(self.N):
+ for j in range(2 * self.N):
+ if self.cfMatrix[i, j] == 1:
+ self.write_to_file(
+ f'cft_impl.addControlFlow("!_{int(j / 2)}", {j % 2}, "!_{i}");'
+ )
+ */
+
+
+ for (int i = 0; i < cfMatrix.length; i++) {
+ for (int j = 0; j < cfMatrix[0].length; j++) {
+ if (cfMatrix[i][j] == 1) {
+ cft_impl.addControlFlow("!_" + (j / 2), j % 2, "!_" + i);
+ }
+ }
+ }
+ cft_impl.connectControlInInterface("!_0");
+ BugplusInstance cftInstance = cft_impl.instantiate();
+ BugplusProgramInstanceImpl cft_instance_impl = cftInstance.getInstanceImpl();
+ BugplusThread newThread = BugplusThread.getInstance();
+ newThread.connectInstance(cftInstance);
+ newThread.start();
+ int[] internalStates = new int[num_bugs];
+ execTimes = new int[num_bugs];
+
+ for (int i = 0; i < num_bugs; i++) {
+ internalStates[i] = cft_instance_impl.getBugs().get("!_" + i).getInternalState();
+ execTimes[i] = cft_instance_impl.getBugs().get("!_" + i).getCallCounter();
+ }
+ return internalStates;
+
+ }
+
+ public static boolean isZeroConnectionValid(int[][] cfMatrix, int pos) {
+// int wrongConnections = 0;
+ for (int i = 0; i < cfMatrix.length * 2; i++) {
+ if (cfMatrix[pos][i] != 0) {
+ return false;
+// wrongConnections++;
+ }
+ }
+ for (int i = 0; i < cfMatrix.length; i++) {
+ if (cfMatrix[i][2 * pos] != 0) {
+ return false;
+// wrongConnections++;
+ }
+ if (cfMatrix[i][2 * pos + 1] != 0) {
+ return false;
+// wrongConnections++;
+ }
+ }
+ return true;
+// return wrongConnections;
+ }
+
+ public static float obtain_reward(int[] bit_specification, int[][] cfMatrix, float Exec_Win_Reward, float Exec_Failure_Reward, float Exec_Partial_Correct_Reward) {
+ //System.out.println("Partial " + Exec_Partial_Correct_Reward);
+ //System.out.println("WIN: " + Exec_Win_Reward);
+// System.out.println("BITSPEC_CF");
+// System.out.println(bit_specification);
+ //System.out.println(Arrays.toString(bit_specification));
+ //for (int[] i : cfMatrix) {
+ //System.out.println(Arrays.toString(i));
+ //}
+ //System.out.println(cfMatrix);
+ float reward = 0;
+ try {
+ int[] internalStates = execute(cfMatrix.length, cfMatrix);
+// System.out.println("BITSPEC: " + bit_specification[0] + " " + bit_specification[1] + " " + bit_specification[2]);
+// System.out.println("Internal State: " + internalStates[0] + " " + internalStates[1] + " " + internalStates[2]);
+ //reward = 0;
+ boolean same_arrays = true;
+ //self.bugs = 5 [0 1 2 0]
+
+ for (int i = 0; i < bit_specification.length; i++) {
+ if (bit_specification[i] == -1) {
+ if (execTimes[i] > 0) {
+ reward += Exec_Partial_Correct_Reward;
+ } else {
+ same_arrays = false;
+ }
+ //System.out.println("-1-1-1-1-1--1-1-1-");
+ } else if (bit_specification[i] == 0) {
+ //System.out.println("0000000000000");
+ if (execTimes[i] == 0) {
+ reward += Exec_Partial_Correct_Reward;
+ } else {
+ same_arrays = false;
+ }
+
+ } else if (bit_specification[i] != internalStates[i] + 1) {
+
+ //reward -= 20;
+ same_arrays = false;
+ } else {
+ if (execTimes[i] > 0) {
+ reward += Exec_Partial_Correct_Reward;
+ } else {
+ same_arrays = false;
+ }
+ // bit_specification[i] == internalStates[i]
+ //reward += 1;
+ }
+ }
+ //give high reward if correct
+ if (same_arrays) {
+ reward += Exec_Win_Reward;
+ // System.out.println("Solved");
+ }
+// System.out.println("REWARD: " + reward);
+// System.out.println("------------------------------------");
+ } catch (IllegalStateException ise) {
+ //System.out.println("Illegal State Exception: " + ise.toString());
+ reward = Exec_Failure_Reward;
+ } catch (StackOverflowError soe) {
+ //System.out.println("Stack Overflow Error: " + soe.toString());
+ reward = Exec_Failure_Reward;
+ }
+ //System.out.println(reward);
+ return reward;
+ }
+
+ public static void main(String[] args) {
+ int[] bitSpec = {1, 1, 1};
+ int[][] cfMatrix = {{1, 1, 0, 0, 0, 0, 0}, {0, 0, 0, 0, 0, 0, 0}, {0, 0, 0, 0, 0, 0, 0}};
+ float reward = obtain_reward(bitSpec, cfMatrix, 1000, -10, 1);
+ //System.out.println(reward);
+ }
+}
\ No newline at end of file
diff --git a/src/de/bugplus/examples/development/Challenge.java b/src/de/bugplus/examples/development/Challenge.java
new file mode 100644
index 0000000..bd05e92
--- /dev/null
+++ b/src/de/bugplus/examples/development/Challenge.java
@@ -0,0 +1,34 @@
+package de.bugplus.examples.development;
+
+import de.bugplus.development.*;
+import de.bugplus.specification.BugplusLibrary;
+import de.bugplus.specification.BugplusProgramSpecification;
+
+import java.util.LinkedList;
+import java.util.List;
+
+public class Challenge {
+ public static void main(String[] args){
+ BugplusLibrary myFunctionLibrary = BugplusLibrary.getInstance();
+ BugplusNEGImplementation negImpl = BugplusNEGImplementation.getInstance();
+ myFunctionLibrary.addSpecification(negImpl.getSpecification());
+
+ //CODE HERE
+ BugplusProgramSpecification T2_Code_specification = BugplusProgramSpecification.getInstance("T2_Code_Instance", 0, 2, myFunctionLibrary);
+ BugplusProgramImplementation T2_Code_Implementation = T2_Code_specification.addImplementation();
+ T2_Code_Implementation.addBug("!", "!_0");
+ T2_Code_Implementation.addDataFlow("!_0", "!_0", 0);
+ T2_Code_Implementation.connectControlInInterface("!_0");
+ T2_Code_Implementation.addControlFlow("!_0", 0, "!_0");
+ T2_Code_Implementation.addControlFlow("!_0", 1, "!_0");
+ BugplusInstance challengeInstance = T2_Code_Implementation.instantiate();
+ BugplusProgramInstanceImpl T2_Code_Instance_Impl = challengeInstance.getInstanceImpl();
+ T2_Code_Instance_Impl.getBugs().get("!_0").setInternalState(0);
+ BugplusThread newThread = BugplusThread.getInstance();
+ newThread.connectInstance(challengeInstance);
+ newThread.start();
+ LinkedList challengeBugs = new LinkedList();
+ System.out.println("Internal State " + "!_0" + ": " + T2_Code_Instance_Impl.getBugs().get("!_0").getInternalState());
+ System.out.println("Call Counter " + "!_0" + ": " + T2_Code_Instance_Impl.getBugs().get("!_0").getCallCounter() + "\n");
+ }
+}
\ No newline at end of file
diff --git a/src/de/bugplus/examples/development/NegBugsBasicArithmetic.java b/src/de/bugplus/examples/development/NegBugsBasicArithmetic.java
new file mode 100644
index 0000000..8086428
--- /dev/null
+++ b/src/de/bugplus/examples/development/NegBugsBasicArithmetic.java
@@ -0,0 +1,308 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.examples.development;
+
+import de.bugplus.development.*;
+import de.bugplus.specification.BugplusLibrary;
+import de.bugplus.specification.BugplusProgramSpecification;
+
+import java.util.LinkedList;
+import java.util.List;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 27.01.22 21:59
+ * @Version 0.0.1
+ */
+public class NegBugsBasicArithmetic {
+
+ public static void createCoherentComponents(List bugs, BugplusProgramImplementation impl) {
+ for (String s1 : bugs) {
+ for (String s2 : bugs) {
+ impl.addDataFlow(s1, s2, 0);
+ }
+ }
+ }
+
+ public static void main(String[] args) {
+
+
+ //Initialization of a new function library
+
+ BugplusLibrary myFunctionLibrary = BugplusLibrary.getInstance();
+
+
+ BugplusNEGImplementation negImpl = BugplusNEGImplementation.getInstance();
+ myFunctionLibrary.addSpecification(negImpl.getSpecification());
+
+ //Test Negation Node:
+ BugplusProgramSpecification negTestSpec = BugplusProgramSpecification.getInstance("!0_Test", 0, 2, myFunctionLibrary);
+ BugplusProgramImplementation negTestImpl = negTestSpec.addImplementation();
+
+
+ negTestImpl.addBug("!", "!_001"); //-> internalState(bug) = 200 + dataIn(bug) = 200
+ negTestImpl.addBug("!", "!_002");
+ negTestImpl.addBug("!", "!_003");
+
+ // System.out.println(negImpl.instantiate());
+
+ LinkedList bugids = new LinkedList();
+ bugids.add("!_001");
+ bugids.add("!_002");
+ bugids.add("!_003");
+ negTestImpl.addBug("!", "!_004");
+ negTestImpl.addControlFlow("!_001", 0, "!_002");
+ negTestImpl.addControlFlow("!_001", 1, "!_003");
+ //negTestImpl.addDataFlow("!_001", "!_001", 0);
+ //negTestImpl.addDataFlow("!_002", "!_002", 0);
+ //negTestImpl.addDataFlow("!_003", "!_003", 0);
+
+ //Zahnraeder
+ createCoherentComponents(bugids, negTestImpl);
+
+ negTestImpl.connectControlInInterface("!_001");
+ //negTestImpl.connectDataInInterface("!_001", 0, 0);
+ //negTestImpl.connectDataInInterface("!_002", 0, 1);
+ //negTestImpl.connectDataInInterface("!_003", 0, 2);
+ //negTestImpl.connectDataOutInterface("!_001");
+ negTestImpl.connectDataOutInterface("!_002");
+ negTestImpl.connectDataOutInterface("!_003");
+ negTestImpl.connectControlOutInterface("!_002", 0, 0);
+ negTestImpl.connectControlOutInterface("!_002", 1, 1);
+ negTestImpl.connectControlOutInterface("!_003", 0, 0);
+ negTestImpl.connectControlOutInterface("!_003", 1, 1);
+
+
+ /*BugplusInstance testInstance = negTestImpl.instantiate();
+ BugplusProgramInstanceImpl test = (BugplusProgramInstanceImpl) testInstance;
+ test.getBugs().get("!_001").setInternalState(0);
+ test.getBugs().get("!_002").setInternalState(1);
+ test.getBugs().get("!_003").setInternalState(1);
+ test.getBugs().get("!_004").setInternalState(0);*/
+
+ /*System.out.println("Starting State " + "!_001 : " + test.getBugs().get("!_001").getInternalState());
+ System.out.println("Starting State " + "!_002 : " + test.getBugs().get("!_002").getInternalState());
+ System.out.println("Starting State " + "!_003 : " + test.getBugs().get("!_003").getInternalState());
+ System.out.println("Starting State " + "!_004 : " + test.getBugs().get("!_004").getInternalState()+"\n");
+
+
+ System.out.println("Data Ins:");
+ System.out.println("Data In " + "!_001 : " + test.getBugs().get("!_001").getDataInputs().get(0).getVariable().getValue());
+ System.out.println("Data In " + "!_002 : " + test.getBugs().get("!_002").getDataInputs().get(0).getVariable().getValue());
+ System.out.println("Data In " + "!_003 : " + test.getBugs().get("!_003").getDataInputs().get(0).getVariable().getValue());
+ System.out.println("Data In " + "!_004 : " + test.getBugs().get("!_004").getDataInputs().get(0).getVariable().getValue() +"\n");
+*/
+
+
+ //Challenge 24
+ BugplusProgramSpecification challenge24Spec = BugplusProgramSpecification.getInstance("ch24_Test", 0, 2, myFunctionLibrary);
+ BugplusProgramImplementation challenge24Impl = challenge24Spec.addImplementation();
+ //We need 4 Bits
+ LinkedList ch24bugs = new LinkedList();
+ for (int i = 1; i <= 4; i++) {
+ String bugID = "!_00" + i;
+ ch24bugs.add(bugID);
+ challenge24Impl.addBug("!", bugID);
+
+ //connect data out with data in for each bug
+ challenge24Impl.addDataFlow(bugID, bugID, 0);
+ }
+
+
+ challenge24Impl.connectControlInInterface(ch24bugs.get(0));
+ challenge24Impl.addControlFlow(ch24bugs.get(0), 0, ch24bugs.get(0));
+ challenge24Impl.addControlFlow(ch24bugs.get(0), 1, ch24bugs.get(1));
+
+ challenge24Impl.addControlFlow(ch24bugs.get(1), 0, ch24bugs.get(0));
+ challenge24Impl.addControlFlow(ch24bugs.get(1), 1, ch24bugs.get(2));
+
+ challenge24Impl.addControlFlow(ch24bugs.get(2), 0, ch24bugs.get(0));
+ challenge24Impl.addControlFlow(ch24bugs.get(2), 1, ch24bugs.get(3));
+
+ challenge24Impl.addControlFlow(ch24bugs.get(3), 0, ch24bugs.get(0));
+ //challenge24Impl.addControlFlow(ch24bugs.get(3), 1, ch24bugs.get(1));
+
+ challenge24Impl.connectControlOutInterface(ch24bugs.get(3), 1, 0);
+ challenge24Impl.connectControlOutInterface(ch24bugs.get(3), 1, 1);
+
+
+ challenge24Impl.connectDataOutInterface(ch24bugs.get(3));
+
+
+ //Example
+ BugplusProgramSpecification exampleSpec = BugplusProgramSpecification.getInstance("example", 0, 2, myFunctionLibrary);
+ BugplusProgramImplementation exampleImpl = exampleSpec.addImplementation();
+
+ exampleImpl.addBug("!", "!_01");
+ exampleImpl.addBug("!", "!_02");
+ exampleImpl.addBug("!", "!_03");
+
+
+ exampleImpl.addDataFlow("!_01", "!_01", 0);
+ exampleImpl.addDataFlow("!_02", "!_02", 0);
+ exampleImpl.addDataFlow("!_03", "!_03", 0);
+
+ exampleImpl.addControlFlow("!_01", 1, "!_01");
+ exampleImpl.addControlFlow("!_01", 0, "!_02");
+
+ exampleImpl.addControlFlow("!_02", 1, "!_01");
+ exampleImpl.addControlFlow("!_02", 0, "!_03");
+
+ exampleImpl.addControlFlow("!_03", 1, "!_01");
+ //exampleImpl.addControlFlow("!_03", 0, "!_02");
+ exampleImpl.connectControlInInterface("!_01");
+
+
+
+ //Challenge 41
+ BugplusProgramSpecification challenge41Spec = BugplusProgramSpecification.getInstance("ch41_Test", 0, 2, myFunctionLibrary);
+ BugplusProgramImplementation challenge41Impl = challenge24Spec.addImplementation();
+
+
+
+
+ //We need 8 Bits
+ LinkedList ch41bugs = new LinkedList();
+
+ //4 Register Bits + 4 Helper Bits
+ for (int i = 0; i < 8; i++) {
+ String bugID = "!_00" + i;
+ ch41bugs.add(bugID);
+ challenge41Impl.addBug("!", bugID);
+ }
+ for (int i = 0; i < 4; i++) {
+ createCoherentComponents(ch41bugs.subList((i * 2), (i * 2 + 2)), challenge41Impl);
+ }
+
+
+ challenge41Impl.connectControlInInterface(ch41bugs.get(1));
+ challenge41Impl.addControlFlow(ch41bugs.get(1), 0, ch41bugs.get(3));
+ challenge41Impl.addControlFlow(ch41bugs.get(1), 1, ch41bugs.get(0));
+
+ challenge41Impl.addControlFlow(ch41bugs.get(0), 0, ch41bugs.get(3));
+ //challenge41Impl.addControlFlow(ch41bugs.get(0), 1, ch41bugs.get(2));
+
+ challenge41Impl.addControlFlow(ch41bugs.get(3), 0, ch41bugs.get(4));
+ challenge41Impl.addControlFlow(ch41bugs.get(3), 1, ch41bugs.get(2));
+
+ challenge41Impl.addControlFlow(ch41bugs.get(2), 0, ch41bugs.get(4));
+ //challenge41Impl.addControlFlow(ch41bugs.get(3), 1, ch41bugs.get(2));
+
+ challenge41Impl.addControlFlow(ch41bugs.get(4), 0, ch41bugs.get(6));
+ challenge41Impl.addControlFlow(ch41bugs.get(4), 1, ch41bugs.get(5));
+
+ challenge41Impl.addControlFlow(ch41bugs.get(5), 0, ch41bugs.get(6));
+
+ challenge41Impl.addControlFlow(ch41bugs.get(6), 1, ch41bugs.get(7));
+ challenge41Impl.connectControlOutInterface(ch41bugs.get(6), 0, 0);
+ challenge41Impl.connectControlOutInterface(ch41bugs.get(6), 0, 1);
+
+
+ challenge41Impl.connectControlOutInterface(ch41bugs.get(7), 0, 0);
+ challenge41Impl.connectControlOutInterface(ch41bugs.get(7), 0, 1);
+
+ challenge41Impl.connectDataOutInterface(ch41bugs.get(6));
+ challenge41Impl.connectDataOutInterface(ch41bugs.get(7));
+
+
+// Application
+
+ //Challenge 24
+ BugplusInstance ch24Instance = challenge24Impl.instantiate();
+ //BugplusProgramInstanceImpl ch24Test = (BugplusProgramInstanceImpl) ch24Instance;
+ BugplusProgramInstanceImpl ch24Test = ch24Instance.getInstanceImpl();
+ ch24Test.getBugs().get("!_001").setInternalState(1);
+ ch24Test.getBugs().get("!_002").setInternalState(0);
+ ch24Test.getBugs().get("!_003").setInternalState(0);
+ ch24Test.getBugs().get("!_004").setInternalState(1);
+
+ BugplusThread newThread = BugplusThread.getInstance();
+ newThread.connectInstance(ch24Instance);
+
+
+ newThread.start();
+ //Override to correct internal state
+ for (
+ String s : ch24bugs) {
+ //ch24Test.getBugs().get(s).setInternalState(ch24Test.getBugs().get(s).getDataInputs().get(0).getVariable().getValue());
+
+ System.out.println("Internal State " + s + ": \t" + ch24Test.getBugs().get(s).getInternalState());
+ System.out.println("Call Counter " + s + ": \t" + ch24Test.getBugs().get(s).getCallCounter() + "\n");
+ }
+
+ //Challenge 41
+ BugplusInstance ch41Instance = challenge41Impl.instantiate();
+ BugplusProgramInstanceImpl ch41Test = (BugplusProgramInstanceImpl) ch41Instance;
+ for (int i = 0; i < 2; i++) {
+ for (int j = 0; j < 2; j++) {
+ for (int k = 0; k < 2; k++) {
+ for (int l = 0; l < 2; l++) {
+ ch41Test.getBugs().get("!_000").setInternalState(i);
+ ch41Test.getBugs().get("!_002").setInternalState(j);
+ ch41Test.getBugs().get("!_004").setInternalState(k);
+ ch41Test.getBugs().get("!_006").setInternalState(l);
+
+ newThread = BugplusThread.getInstance();
+ newThread.connectInstance(ch41Instance);
+
+
+ newThread.start();
+ //Override to correct internal state
+ int count = 0;
+ for (
+ String s : ch41bugs) {
+ if (count % 2 == 0) {
+ ch41Test.getBugs().get(s).setInternalState(ch41Test.getBugs().get(s).getDataInputs().get(0).getVariable().getValue());
+
+ System.out.println("Internal State " + s + ": " + ch41Test.getBugs().get(s).getInternalState());
+ }
+ count++;
+ }
+ }
+ }
+ }
+ }
+
+ System.out.println("Example Challenge");
+ //Example Challenge
+ BugplusInstance exampleInstance = exampleImpl.instantiate();
+ newThread= BugplusThread.getInstance();
+ newThread.connectInstance(exampleInstance);
+ newThread.start();
+ BugplusProgramInstanceImpl exampleTest = exampleInstance.getInstanceImpl();
+
+
+ System.out.println("Internal State " + "!_01" + ": \t" + exampleTest.getBugs().get("!_01").getInternalState());
+ System.out.println("Call Counter " + "!_01" + ": \t" + exampleTest.getBugs().get("!_01").getCallCounter() + "\n");
+
+ System.out.println("Internal State " + "!_02" + ": \t" + exampleTest.getBugs().get("!_02").getInternalState());
+ System.out.println("Call Counter " + "!_02" + ": \t" + exampleTest.getBugs().get("!_02").getCallCounter() + "\n");
+
+ System.out.println("Internal State " + "!_03" + ": \t" + exampleTest.getBugs().get("!_03").getInternalState());
+ System.out.println("Call Counter " + "!_03" + ": \t" + exampleTest.getBugs().get("!_03").getCallCounter() + "\n");
+
+ }
+}
diff --git a/src/de/bugplus/specification/AbstractBugplusSpecification.java b/src/de/bugplus/specification/AbstractBugplusSpecification.java
new file mode 100644
index 0000000..2ed4c14
--- /dev/null
+++ b/src/de/bugplus/specification/AbstractBugplusSpecification.java
@@ -0,0 +1,90 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+import java.util.List;
+import java.util.ArrayList;
+
+import de.bugplus.development.BugplusImplementation;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 25.01.22 19:51
+ * @Version 0.0.1
+ */
+abstract class AbstractBugplusSpecification implements BugplusSpecification {
+
+ protected String identifier;
+
+ protected int numDataIn = 2;
+ protected int numControlOut = 2;
+
+ //Tobi
+ //protected int internalState = 0;
+
+ final protected List implementations = new ArrayList<>();
+
+ protected BugplusLibrary lib;
+
+
+ //Tobi
+ //@Override
+ //public int getInternalState() {
+ // return this.internalState;
+ //}
+
+ @Override
+ public int getNumDataIn() {
+
+ return this.numDataIn;
+ }
+
+ @Override
+ public int getNumControlOut() {
+
+ return this.numControlOut;
+ }
+
+
+ @Override
+ public String getIdentifier() {
+
+ return this.identifier;
+ }
+
+ @Override
+ public BugplusLibrary getLibrary() {
+
+ return this.lib;
+ }
+
+ @Override
+ public BugplusImplementation getImplementation(int indexSelectedImplementation) {
+ return this.implementations.get(indexSelectedImplementation);
+ }
+
+}
diff --git a/src/de/bugplus/specification/BugplusADDSpecification.java b/src/de/bugplus/specification/BugplusADDSpecification.java
new file mode 100644
index 0000000..183a04c
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusADDSpecification.java
@@ -0,0 +1,46 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+import de.bugplus.development.BugplusImplementation;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 25.01.22 21:17
+ * @Version 0.0.1
+ */
+public interface BugplusADDSpecification extends BugplusSpecification {
+
+ void addProgram(BugplusImplementation implementation);
+
+ static BugplusADDSpecification getInstance() {
+ return BugplusADDSpecificationImpl.getInstance();
+ }
+
+ static BugplusADDSpecification getInstance(BugplusImplementation implementation) {
+ return BugplusADDSpecificationImpl.getInstance(implementation);
+ }
+}
diff --git a/src/de/bugplus/specification/BugplusADDSpecificationImpl.java b/src/de/bugplus/specification/BugplusADDSpecificationImpl.java
new file mode 100644
index 0000000..514426c
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusADDSpecificationImpl.java
@@ -0,0 +1,71 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+
+import de.bugplus.development.BugplusImplementation;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+final class BugplusADDSpecificationImpl extends AbstractBugplusSpecification implements BugplusADDSpecification {
+
+ static BugplusADDSpecification OBJ;
+
+ private BugplusADDSpecificationImpl() {
+
+ this.identifier = "+";
+ this.numDataIn = 2;
+ this.numControlOut = 2;
+ }
+
+ public void addProgram(BugplusImplementation implementation) {
+
+ this.implementations.add(0, implementation);
+ }
+
+ static BugplusADDSpecification getInstance() {
+
+ if (OBJ == null) {
+ OBJ = new BugplusADDSpecificationImpl(); }
+
+ return OBJ;
+ }
+
+ static BugplusADDSpecification getInstance(BugplusImplementation implementation) {
+
+ if (OBJ == null) {
+ OBJ = new BugplusADDSpecificationImpl();
+ OBJ.addProgram(implementation); }
+
+ return OBJ;
+ }
+
+
+}
diff --git a/src/de/bugplus/specification/BugplusJOINControlSpecification.java b/src/de/bugplus/specification/BugplusJOINControlSpecification.java
new file mode 100644
index 0000000..d085858
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusJOINControlSpecification.java
@@ -0,0 +1,39 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 31.01.22 17:20
+ * @Version 0.0.1
+ */
+public interface BugplusJOINControlSpecification extends BugplusSpecification {
+
+ static BugplusJOINControlSpecification getInstance() {
+ return BugplusJOINControlSpecificationImpl.getInstance();
+ }
+}
diff --git a/src/de/bugplus/specification/BugplusJOINControlSpecificationImpl.java b/src/de/bugplus/specification/BugplusJOINControlSpecificationImpl.java
new file mode 100644
index 0000000..3aad65c
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusJOINControlSpecificationImpl.java
@@ -0,0 +1,60 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 31.01.22 17:23
+ * @Version 0.0.1
+ */
+final public class BugplusJOINControlSpecificationImpl extends AbstractBugplusSpecification implements BugplusJOINControlSpecification {
+
+ static BugplusJOINControlSpecification OBJ;
+
+ @Override
+ public int getNumDataIn() {
+ return 0;
+ }
+
+ @Override
+ public int getNumControlOut() {
+ return 1;
+ }
+
+ @Override
+ public String getIdentifier() {
+ return "";
+ }
+
+ static BugplusJOINControlSpecification getInstance() {
+
+ if (OBJ == null) {
+ OBJ = new BugplusJOINControlSpecificationImpl(); }
+
+ return OBJ;
+ }
+
+}
diff --git a/src/de/bugplus/specification/BugplusLibrary.java b/src/de/bugplus/specification/BugplusLibrary.java
new file mode 100644
index 0000000..063c009
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusLibrary.java
@@ -0,0 +1,47 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+public interface BugplusLibrary {
+
+ boolean containsSpecification(String id);
+
+ BugplusSpecification selectSpecification(String id);
+
+ void addSpecification(BugplusSpecification spec);
+
+ static BugplusLibrary getInstance() {
+
+ return new BugplusLibraryImpl();
+ }
+
+}
diff --git a/src/de/bugplus/specification/BugplusLibraryImpl.java b/src/de/bugplus/specification/BugplusLibraryImpl.java
new file mode 100644
index 0000000..3ae003e
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusLibraryImpl.java
@@ -0,0 +1,80 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+
+import java.util.Map;
+import java.util.HashMap;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+final class BugplusLibraryImpl implements BugplusLibrary {
+
+ private Map functionalKnowledge = new HashMap();
+
+
+ BugplusLibraryImpl() {
+
+ }
+
+ BugplusLibraryImpl(BugplusSpecification spec) {
+
+ this();
+ if (this.functionalKnowledge.containsKey(spec.getIdentifier())) {
+ System.out.println("Error: Specification identifier cannot add to knowledge base it already exists in knowledge base."); }
+ else {
+ this.functionalKnowledge.put(spec.getIdentifier(), spec);}
+ }
+
+
+ @Override
+ public boolean containsSpecification(String id) {
+
+ return this.functionalKnowledge.containsKey(id);
+ }
+
+ @Override
+ public BugplusSpecification selectSpecification(String id) {
+
+ if (this.containsSpecification(id)) {
+ return this.functionalKnowledge.get(id);}
+ else {
+ System.out.println("Error: Specification identifier is unknown in the knowledge base.");
+ return null; }
+ }
+
+ @Override
+ public void addSpecification(BugplusSpecification spec) {
+
+ if (this.functionalKnowledge.containsKey(spec.getIdentifier())) {
+ System.out.println("Error: Specification identifier cannot be defined newly because it already exists in knowledge base."); }
+
+ this.functionalKnowledge.put(spec.getIdentifier(), spec);
+ }
+}
diff --git a/src/de/bugplus/specification/BugplusNEGSpecification.java b/src/de/bugplus/specification/BugplusNEGSpecification.java
new file mode 100644
index 0000000..c356f34
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusNEGSpecification.java
@@ -0,0 +1,46 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+import de.bugplus.development.BugplusImplementation;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 25.01.22 21:17
+ * @Version 0.0.1
+ */
+public interface BugplusNEGSpecification extends BugplusSpecification {
+
+ void addProgram(BugplusImplementation implementation);
+
+ static BugplusNEGSpecification getInstance() {
+ return BugplusNEGSpecificationImpl.getInstance();
+ }
+
+ static BugplusNEGSpecification getInstance(BugplusImplementation implementation) {
+ return BugplusNEGSpecificationImpl.getInstance(implementation);
+ }
+}
diff --git a/src/de/bugplus/specification/BugplusNEGSpecificationImpl.java b/src/de/bugplus/specification/BugplusNEGSpecificationImpl.java
new file mode 100644
index 0000000..64f2c74
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusNEGSpecificationImpl.java
@@ -0,0 +1,71 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+
+import de.bugplus.development.BugplusImplementation;
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+final class BugplusNEGSpecificationImpl extends AbstractBugplusSpecification implements BugplusNEGSpecification {
+
+ static BugplusNEGSpecification OBJ;
+
+ private BugplusNEGSpecificationImpl() {
+
+ this.identifier = "!";
+ this.numDataIn = 1;
+ this.numControlOut = 2;
+ }
+
+ public void addProgram(BugplusImplementation implementation) {
+
+ this.implementations.add(0, implementation);
+ }
+
+ static BugplusNEGSpecification getInstance() {
+
+ if (OBJ == null) {
+ OBJ = new BugplusNEGSpecificationImpl(); }
+
+ return OBJ;
+ }
+
+ static BugplusNEGSpecification getInstance(BugplusImplementation implementation) {
+
+ if (OBJ == null) {
+ OBJ = new BugplusNEGSpecificationImpl();
+ OBJ.addProgram(implementation); }
+
+ return OBJ;
+ }
+
+
+}
diff --git a/src/de/bugplus/specification/BugplusProgramSpecification.java b/src/de/bugplus/specification/BugplusProgramSpecification.java
new file mode 100644
index 0000000..ab7ec6e
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusProgramSpecification.java
@@ -0,0 +1,45 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+import de.bugplus.development.BugplusProgramImplementation;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 25.01.22 20:03
+ * @Version 0.0.1
+ */
+public interface BugplusProgramSpecification extends BugplusSpecification {
+
+ BugplusProgramImplementation addImplementation();
+
+ BugplusLibrary getLibrary();
+
+ static BugplusProgramSpecification getInstance(String id, int numDataIn, int numControlOut, BugplusLibrary lib) {
+
+ return new BugplusProgramSpecificationImpl(id, numDataIn, numControlOut, lib);
+ };
+}
diff --git a/src/de/bugplus/specification/BugplusProgramSpecificationImpl.java b/src/de/bugplus/specification/BugplusProgramSpecificationImpl.java
new file mode 100644
index 0000000..2d3a674
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusProgramSpecificationImpl.java
@@ -0,0 +1,90 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+import de.bugplus.development.BugplusProgramImplementation;
+import de.bugplus.development.BugplusImplementation;
+
+
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+final public class BugplusProgramSpecificationImpl extends AbstractBugplusSpecification implements BugplusProgramSpecification {
+
+
+ private BugplusProgramSpecificationImpl() {}
+
+ public BugplusProgramSpecificationImpl(String id, int numDataIn, int numControlOut, BugplusLibrary library) {
+
+ this();
+
+ this.identifier = id;
+
+ this.numDataIn = numDataIn;
+
+ this.numControlOut = numControlOut;
+
+ this.lib = library;
+
+ if (this.lib.containsSpecification(id)) {
+ System.out.println("Error: Specification identifier cannot be defined newly because it already exists in knowledge base."); }
+
+
+
+ }
+
+
+ @Override
+ public BugplusImplementation getImplementation(int indexSelectedImplementation) {
+
+ if (this.implementations.size()> indexSelectedImplementation) {
+ return this.implementations.get(indexSelectedImplementation); }
+ else {
+ System.out.println("Error: The selected implementation index of specification \"" + this.getIdentifier() + "\" does not exists.");
+ return null;
+ }
+ }
+
+ @Override
+ public BugplusLibrary getLibrary() {
+
+ return this.lib;
+ }
+
+ @Override
+ public BugplusProgramImplementation addImplementation() {
+
+
+ BugplusProgramImplementation newImplementation = BugplusProgramImplementation.getInstance(this);
+
+ this.implementations.add(newImplementation);
+
+ return newImplementation;
+ }
+}
diff --git a/src/de/bugplus/specification/BugplusSpecification.java b/src/de/bugplus/specification/BugplusSpecification.java
new file mode 100644
index 0000000..36b9ca7
--- /dev/null
+++ b/src/de/bugplus/specification/BugplusSpecification.java
@@ -0,0 +1,50 @@
+/*
+ * MIT License
+ *
+ * Bug+ Interpreter
+ * Copyright (c) 2022 Christian Bartelt
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy
+ * of this software and associated documentation files (the "Software"), to deal
+ * in the Software without restriction, including without limitation the rights
+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+ * copies of the Software, and to permit persons to whom the Software is
+ * furnished to do so, subject to the following conditions:
+ *
+ * The above copyright notice and this permission notice shall be included in all
+ * copies or substantial portions of the Software.
+ *
+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+ * SOFTWARE.
+ */
+
+package de.bugplus.specification;
+
+import de.bugplus.development.BugplusImplementation;
+
+/**
+ * @Author Christian Bartelt
+ * @Date 23.01.22 21:37
+ * @Version 0.0.1
+ */
+public interface BugplusSpecification {
+
+
+ int getNumDataIn();
+
+ int getNumControlOut();
+
+ //int getInternalState();
+
+ String getIdentifier();
+
+ BugplusImplementation getImplementation(int indexSelectedProgram);
+
+ BugplusLibrary getLibrary();
+
+}
diff --git a/ttsim/LICENSE b/ttsim/LICENSE
new file mode 100644
index 0000000..cf1ab25
--- /dev/null
+++ b/ttsim/LICENSE
@@ -0,0 +1,24 @@
+This is free and unencumbered software released into the public domain.
+
+Anyone is free to copy, modify, publish, use, compile, sell, or
+distribute this software, either in source code form or as a compiled
+binary, for any purpose, commercial or non-commercial, and by any
+means.
+
+In jurisdictions that recognize copyright laws, the author or authors
+of this software dedicate any and all copyright interest in the
+software to the public domain. We make this dedication for the benefit
+of the public at large and to the detriment of our heirs and
+successors. We intend this dedication to be an overt act of
+relinquishment in perpetuity of all present and future rights to this
+software under copyright law.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
+IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR
+OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
+ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
+OTHER DEALINGS IN THE SOFTWARE.
+
+For more information, please refer to
diff --git a/ttsim/README.md b/ttsim/README.md
new file mode 100644
index 0000000..f003057
--- /dev/null
+++ b/ttsim/README.md
@@ -0,0 +1,87 @@
+Turing Tumble Simulator
+=======================
+
+This is a software simulation of the [Turing Tumble](https://www.turingtumble.com/),
+an amazing programmable marble-powered computer. It runs entirely in your browser, so
+you can [try it out here](https://jessecrossen.github.io/ttsim/). If you've used
+an actual Turing Tumble, it should be straightforward to get started, but here's
+[some documentation about how to use it](https://jessecrossen.github.io/ttsim/usage).
+If you got here but haven't used an actual Turing Tumble yet, you may need one in
+your life!
+
+What's Inside?
+==============
+
+It uses [pixi.js](http://www.pixijs.com/) for graphics and interaction, and
+[matter.js](http://brm.io/matter-js/) to simulate the physics of balls dropping
+through the board. It's written in [TypeScript](https://www.typescriptlang.org/) and
+uses [GNU make](https://www.gnu.org/software/make/) as a build system. All the graphics
+and the vertices for the physics engine are generated from [InkScape](https://inkscape.org/)
+SVG files.
+
+What's Next?
+============
+
+Here are some things I'd like to implement in the near future:
+
+- [ ] Wrap toolbar buttons when the screen height is small
+- [ ] Support for touch events
+- [ ] Select one or more parts and cut/copy/paste/move them
+- [ ] Keyboard shortcuts
+- [ ] Undo/redo
+- [ ] Allow toggling of whether parts are locked (for setting up challenges)
+
+Reporting Bugs and Requesting Features
+======================================
+
+Please file an issue if you find a bug that doesn't have one yet. Or if you have
+the will and the skill and feel like doing something nice, fix it yourself and submit a
+pull request. Feature requests are also welcome, and especially so if you can suggest
+a way to add the feature with minimal complication of the interface. Note that this is
+a hobby project, so it could take some time for me to respond.
+
+Browser Support
+===============
+
+I've developed and tested it on the latest version of Chrome, and the code should be standards-compliant enough that recent versions of Firefox will probably work as well. I'm not that interested in working around any quirks of platform-specific browsers like Safari or Edge, but will merge in basic fixes if anyone cares enough to make a pull request. Also note that the graphics may be slow/jerky if WebGL doesn't work for whatever reason.
+
+Building
+========
+
+If you'd like to build the project yourself, you'll need at least the following:
+
+* [GNU make](https://www.gnu.org/software/make/) to run the build
+* [node.js](https://nodejs.org/en/download/) to run TypeScript and npm
+* [npm](https://www.npmjs.com/) to install dependencies
+* [Python](https://www.python.org/) for various custom build scripts (tested on 2.7, may work on 3)
+
+To edit and re-build the graphics and physics assets, you'll need:
+
+* [InkScape](https://inkscape.org/) to edit and rasterize SVG files
+* [ImageMagick](https://www.imagemagick.org/script/index.php) for some image conversion operations
+
+The build process is very likely to work well on Linux, will probably kind of work on OS X, and
+is very unlikely to work on Windows. Go to the root directory of the project in your console,
+and run `make` to build the whole thing. Running `make server` will start a web server that serves
+the application on `localhost:8080`. Running `make watch` will watch TypeScript files for changes
+and automatically rebuild. There are also some handy targets if you're working on just one part
+of the project: `make graphics` updates the image assets and `make physics` updates the physics
+assets. Note that the physics target actually generates code, so you'll need to rebuild or have
+`make watch` running to see any effects. If things get really messed up, you can always run
+`make clean` to delete all the targets and start over.
+
+
+Building on Windows (10/11)
+===========================
+
+1. [Install chocolatey](https://chocolatey.org/install)
+2. Install node.js using `choco install nodejs`
+3. Install [GNU Make](https://www.gnu.org/software/make/) using `choco install make`
+4. Navigate to `ttsim` in the command line and run `make`
+5. Wait for the process to finish and start the HTTP server with `make server`
+
+License
+=======
+
+It's licensed under the terms of [the unlicense](LICENSE), so you can pretty much
+do whatever you like with it.
diff --git a/ttsim/docs/app.js b/ttsim/docs/app.js
new file mode 100644
index 0000000..e09ea3e
--- /dev/null
+++ b/ttsim/docs/app.js
@@ -0,0 +1,6279 @@
+var __awaiter = (this && this.__awaiter) || function (thisArg, _arguments, P, generator) {
+ return new (P || (P = Promise))(function (resolve, reject) {
+ function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }
+ function rejected(value) { try { step(generator["throw"](value)); } catch (e) { reject(e); } }
+ function step(result) { result.done ? resolve(result.value) : new P(function (resolve) { resolve(result.value); }).then(fulfilled, rejected); }
+ step((generator = generator.apply(thisArg, _arguments || [])).next());
+ });
+};
+System.register("parts/location", ["parts/part"], function (exports_1, context_1) {
+ "use strict";
+ var __moduleName = context_1 && context_1.id;
+ var part_1, PartLocation, GearLocation;
+ return {
+ setters: [
+ function (part_1_1) {
+ part_1 = part_1_1;
+ }
+ ],
+ execute: function () {
+ PartLocation = class PartLocation extends part_1.Part {
+ get canRotate() { return (false); }
+ get canMirror() { return (true); }
+ get canFlip() { return (false); }
+ get type() { return (1 /* PARTLOC */); }
+ // make the pins bouncy so it's more fun when the ball goes off track
+ get bodyRestitution() { return (0.5); }
+ };
+ exports_1("PartLocation", PartLocation);
+ GearLocation = class GearLocation extends part_1.Part {
+ get canRotate() { return (false); }
+ get canMirror() { return (true); }
+ get canFlip() { return (false); }
+ get type() { return (2 /* GEARLOC */); }
+ // make the pins bouncy so it's more fun when the ball goes off track
+ get bodyRestitution() { return (0.5); }
+ };
+ exports_1("GearLocation", GearLocation);
+ }
+ };
+});
+System.register("parts/ramp", ["parts/part"], function (exports_2, context_2) {
+ "use strict";
+ var __moduleName = context_2 && context_2.id;
+ var part_2, Ramp;
+ return {
+ setters: [
+ function (part_2_1) {
+ part_2 = part_2_1;
+ }
+ ],
+ execute: function () {
+ Ramp = class Ramp extends part_2.Part {
+ get canRotate() { return (true); }
+ get canMirror() { return (false); }
+ get canFlip() { return (true); }
+ get type() { return (3 /* RAMP */); }
+ get bodyRestitution() { return (0.0); }
+ // simulate the counterweight when doing physics
+ get isCounterWeighted() { return (true); }
+ // return ramps to zero (simulating counterweight when not doing physics)
+ get restingRotation() { return (0.0); }
+ };
+ exports_2("Ramp", Ramp);
+ }
+ };
+});
+System.register("parts/crossover", ["parts/part"], function (exports_3, context_3) {
+ "use strict";
+ var __moduleName = context_3 && context_3.id;
+ var part_3, Crossover;
+ return {
+ setters: [
+ function (part_3_1) {
+ part_3 = part_3_1;
+ }
+ ],
+ execute: function () {
+ Crossover = class Crossover extends part_3.Part {
+ get canRotate() { return (false); }
+ get canMirror() { return (true); }
+ get canFlip() { return (false); }
+ get type() { return (4 /* CROSSOVER */); }
+ get bodyRestitution() { return (0.5); }
+ };
+ exports_3("Crossover", Crossover);
+ }
+ };
+});
+System.register("parts/interceptor", ["parts/part"], function (exports_4, context_4) {
+ "use strict";
+ var __moduleName = context_4 && context_4.id;
+ var part_4, Interceptor;
+ return {
+ setters: [
+ function (part_4_1) {
+ part_4 = part_4_1;
+ }
+ ],
+ execute: function () {
+ Interceptor = class Interceptor extends part_4.Part {
+ get canRotate() { return (false); }
+ get canMirror() { return (true); }
+ get canFlip() { return (false); }
+ get type() { return (5 /* INTERCEPTOR */); }
+ };
+ exports_4("Interceptor", Interceptor);
+ }
+ };
+});
+System.register("parts/bit", ["parts/part"], function (exports_5, context_5) {
+ "use strict";
+ var __moduleName = context_5 && context_5.id;
+ var part_5, Bit;
+ return {
+ setters: [
+ function (part_5_1) {
+ part_5 = part_5_1;
+ }
+ ],
+ execute: function () {
+ Bit = class Bit extends part_5.Part {
+ get canRotate() { return (true); }
+ get canMirror() { return (true); }
+ get canFlip() { return (false); }
+ get type() { return (6 /* BIT */); }
+ // return the bit to whichever side it's closest to, preventing stuck bits
+ get restingRotation() { return (this.bitValue ? 1.0 : 0.0); }
+ };
+ exports_5("Bit", Bit);
+ }
+ };
+});
+System.register("parts/gearbit", ["parts/part"], function (exports_6, context_6) {
+ "use strict";
+ var __moduleName = context_6 && context_6.id;
+ var part_6, GearBase, Gearbit, Gear;
+ return {
+ setters: [
+ function (part_6_1) {
+ part_6 = part_6_1;
+ }
+ ],
+ execute: function () {
+ GearBase = class GearBase extends part_6.Part {
+ constructor() {
+ super(...arguments);
+ // a set of connected gears that should have the same rotation
+ this.connected = null;
+ // a label used in the connection-finding algorithm
+ this._connectionLabel = -1;
+ this._rotationVote = NaN;
+ }
+ // transfer rotation to connected elements
+ get rotation() { return (super.rotation); }
+ set rotation(r) {
+ // if this is connected to a gear train, register a vote
+ // to be tallied later
+ if ((this.connected) && (this.connected.size > 1) &&
+ (!GearBase._updating)) {
+ this._rotationVote = r;
+ GearBase._rotationElections.add(this.connected);
+ }
+ else {
+ super.rotation = r;
+ }
+ }
+ // tally votes and apply rotation
+ static update() {
+ // skip this if there are no votes
+ if (!(GearBase._rotationElections.size > 0))
+ return;
+ GearBase._updating = true;
+ for (const election of GearBase._rotationElections) {
+ let sum = 0;
+ let count = 0;
+ for (const voter of election) {
+ if (!isNaN(voter._rotationVote)) {
+ sum += voter._rotationVote;
+ count += 1;
+ voter._rotationVote = NaN;
+ }
+ }
+ if (!(count > 0))
+ continue;
+ const mean = sum / count;
+ for (const voter of election) {
+ voter.rotation = mean;
+ }
+ }
+ GearBase._rotationElections.clear();
+ GearBase._updating = false;
+ }
+ isBeingDriven() {
+ return (GearBase._rotationElections.has(this.connected) &&
+ (isNaN(this._rotationVote)));
+ }
+ };
+ GearBase._rotationElections = new Set();
+ GearBase._updating = false;
+ exports_6("GearBase", GearBase);
+ Gearbit = class Gearbit extends GearBase {
+ get canRotate() { return (true); }
+ get canMirror() { return (true); }
+ get canFlip() { return (false); }
+ get type() { return (7 /* GEARBIT */); }
+ // return the bit to whichever side it's closest to, preventing stuck bits
+ get restingRotation() { return (this.bitValue ? 1.0 : 0.0); }
+ };
+ exports_6("Gearbit", Gearbit);
+ Gear = class Gear extends GearBase {
+ constructor() {
+ super(...arguments);
+ this._isOnPartLocation = false;
+ }
+ get canRotate() { return (true); }
+ get canMirror() { return (false); } // (the cross is not mirrored)
+ get canFlip() { return (false); }
+ get type() { return (8 /* GEAR */); }
+ get isOnPartLocation() { return (this._isOnPartLocation); }
+ set isOnPartLocation(v) {
+ if (v === this.isOnPartLocation)
+ return;
+ this._isOnPartLocation = v;
+ this._updateSprites();
+ }
+ // gears don't interact with balls in a rotationally asymmetric way,
+ // so we can ignore their rotation
+ get bodyCanRotate() { return (false); }
+ angleForRotation(r, layer) {
+ // gears on a regular-part location need to be rotated by 1/16 turn
+ // to mesh with neighbors
+ if (this.isOnPartLocation) {
+ if (layer == 4 /* SCHEMATIC */) {
+ return (super.angleForRotation(r, layer));
+ }
+ else {
+ return (super.angleForRotation(r, layer) + (Math.PI * 0.125));
+ }
+ }
+ else {
+ return (-super.angleForRotation(r, layer));
+ }
+ }
+ };
+ exports_6("Gear", Gear);
+ }
+ };
+});
+System.register("parts/fence", ["parts/part", "board/board"], function (exports_7, context_7) {
+ "use strict";
+ var __moduleName = context_7 && context_7.id;
+ var part_7, board_1, Side, Slope;
+ return {
+ setters: [
+ function (part_7_1) {
+ part_7 = part_7_1;
+ },
+ function (board_1_1) {
+ board_1 = board_1_1;
+ }
+ ],
+ execute: function () {
+ Side = class Side extends part_7.Part {
+ get canRotate() { return (false); }
+ get canMirror() { return (false); }
+ get canFlip() { return (true); }
+ get type() { return (12 /* SIDE */); }
+ };
+ exports_7("Side", Side);
+ Slope = class Slope extends part_7.Part {
+ constructor() {
+ super(...arguments);
+ this._modulus = 1;
+ this._sequence = 1;
+ }
+ get canRotate() { return (false); }
+ get canMirror() { return (false); }
+ get canFlip() { return (true); }
+ get type() { return (13 /* SLOPE */); }
+ static get maxModulus() { return (6); }
+ // for slopes, the number of part units in the slope
+ get modulus() { return (this._modulus); }
+ set modulus(v) {
+ v = Math.min(Math.max(0, Math.round(v)), Slope.maxModulus);
+ if (v === this.modulus)
+ return;
+ this._modulus = v;
+ this._updateTexture();
+ this.changeCounter++;
+ }
+ // for slopes, the position of this part in the run of parts,
+ // where 0 is at the highest point and (modulus - 1) is at the lowest
+ get sequence() { return (this._sequence); }
+ set sequence(v) {
+ if (v === this.sequence)
+ return;
+ this._sequence = v;
+ this._updateTexture();
+ this.changeCounter++;
+ }
+ // a number that uniquely identifies the fence body type
+ get signature() {
+ return (this.modulus > 0 ?
+ (this.sequence / this.modulus) : -1);
+ }
+ textureSuffix(layer) {
+ let suffix = super.textureSuffix(layer);
+ if (layer != 7 /* TOOL */)
+ suffix += this.modulus;
+ return (suffix);
+ }
+ _updateTexture() {
+ for (let layer = 0 /* BACK */; layer < 9 /* COUNT */; layer++) {
+ const sprite = this.getSpriteForLayer(layer);
+ if (!sprite)
+ continue;
+ if (this.modulus > 0) {
+ this._yOffset = ((this.sequence % this.modulus) / this.modulus) * board_1.SPACING_FACTOR;
+ }
+ else {
+ this._yOffset = 0;
+ }
+ const textureName = this.getTextureNameForLayer(layer);
+ if (textureName in this.textures) {
+ sprite.texture = this.textures[textureName];
+ }
+ }
+ this._updateSprites();
+ }
+ };
+ exports_7("Slope", Slope);
+ }
+ };
+});
+System.register("parts/blank", ["parts/part"], function (exports_8, context_8) {
+ "use strict";
+ var __moduleName = context_8 && context_8.id;
+ var part_8, Blank;
+ return {
+ setters: [
+ function (part_8_1) {
+ part_8 = part_8_1;
+ }
+ ],
+ execute: function () {
+ Blank = class Blank extends part_8.Part {
+ get canRotate() { return (false); }
+ get canMirror() { return (false); }
+ get canFlip() { return (false); }
+ get type() { return (0 /* BLANK */); }
+ };
+ exports_8("Blank", Blank);
+ }
+ };
+});
+System.register("ui/config", [], function (exports_9, context_9) {
+ "use strict";
+ var __moduleName = context_9 && context_9.id;
+ // formats a color as an HTML color code
+ function htmlColor(c) {
+ return ('#' + ('000000' + c.toString(16)).substr(-6));
+ }
+ exports_9("htmlColor", htmlColor);
+ // converts an HSL color value to RGB
+ // adapted from http://en.wikipedia.org/wiki/HSL_color_space
+ // via https://stackoverflow.com/a/9493060/745831
+ function colorFromHSL(h, s, l) {
+ let r, g, b;
+ if (s == 0) {
+ r = g = b = l; // achromatic
+ }
+ else {
+ const q = l < 0.5 ? l * (1 + s) : l + s - l * s;
+ const p = 2 * l - q;
+ r = hue2rgb(p, q, h + 1 / 3);
+ g = hue2rgb(p, q, h);
+ b = hue2rgb(p, q, h - 1 / 3);
+ }
+ return ((Math.round(r * 255) << 16) |
+ (Math.round(g * 255) << 8) |
+ (Math.round(b * 255)));
+ }
+ exports_9("colorFromHSL", colorFromHSL);
+ function hue2rgb(p, q, t) {
+ if (t < 0)
+ t += 1;
+ if (t > 1)
+ t -= 1;
+ if (t < 1 / 6)
+ return (p + (q - p) * 6 * t);
+ if (t < 1 / 2)
+ return (q);
+ if (t < 2 / 3)
+ return (p + (q - p) * (2 / 3 - t) * 6);
+ return (p);
+ }
+ var Zooms, Speeds, ButtonSizes;
+ return {
+ setters: [],
+ execute: function () {
+ exports_9("Zooms", Zooms = [2, 4, 6, 8, 12, 16, 24, 32, 48, 64]);
+ exports_9("Speeds", Speeds = [0.0, 0.25, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 4.0, 5.0, 6.0, 8.0]);
+ exports_9("ButtonSizes", ButtonSizes = [16, 24, 32, 48, 64]);
+ }
+ };
+});
+System.register("parts/ball", ["parts/part", "ui/config"], function (exports_10, context_10) {
+ "use strict";
+ var __moduleName = context_10 && context_10.id;
+ var part_9, config_1, Ball;
+ return {
+ setters: [
+ function (part_9_1) {
+ part_9 = part_9_1;
+ },
+ function (config_1_1) {
+ config_1 = config_1_1;
+ }
+ ],
+ execute: function () {
+ Ball = class Ball extends part_9.Part {
+ constructor() {
+ super(...arguments);
+ this.lastDistinctColumn = NaN;
+ // whether the ball has been released from a drop
+ this.released = false;
+ this.vx = 0;
+ this.vy = 0;
+ this.minX = NaN;
+ this.maxX = NaN;
+ this.maxY = NaN;
+ this._hue = 220;
+ this._color = this._colorForHue(this._hue);
+ }
+ get canRotate() { return (false); }
+ get canMirror() { return (false); }
+ get canFlip() { return (false); }
+ get type() { return (9 /* BALL */); }
+ // when the ball goes below its drop, reset the released flag
+ get row() { return (super.row); }
+ set row(r) {
+ super.row = r;
+ if ((this.released) && (this.drop) && (r > this.drop.row + 0.5)) {
+ this.released = false;
+ }
+ }
+ // track the last column the ball was in to determine travel direction
+ get column() { return (super.column); }
+ set column(c) {
+ const oldColumn = Math.round(this.column);
+ const newColumn = Math.round(c);
+ super.column = c;
+ if (isNaN(this.lastDistinctColumn))
+ this.lastDistinctColumn = newColumn;
+ if (newColumn !== oldColumn) {
+ this.lastDistinctColumn = oldColumn;
+ }
+ }
+ // the hue of the ball in degrees
+ get hue() { return (this._hue); }
+ set hue(v) {
+ if (isNaN(v))
+ return;
+ while (v < 0)
+ v += 360;
+ if (v >= 360)
+ v %= 360;
+ if (v === this._hue)
+ return;
+ this._hue = v;
+ this._color = this._colorForHue(this._hue);
+ this._updateSprites();
+ }
+ // the color of the ball
+ get color() { return (this._color); }
+ _colorForHue(hue) {
+ return (config_1.colorFromHSL(hue / 360, 1, 0.53));
+ }
+ // update the given sprite to track the part's state
+ _updateSprite(layer) {
+ super._updateSprite(layer);
+ // we use the front layer for a specular highlight, so don't tint it
+ if (layer !== 2 /* FRONT */) {
+ const sprite = this.getSpriteForLayer(layer);
+ if (!sprite)
+ return;
+ sprite.tint = this.color;
+ }
+ }
+ get bodyCanMove() { return (true); }
+ get bodyRestitution() { return (0.05); }
+ };
+ exports_10("Ball", Ball);
+ }
+ };
+});
+System.register("parts/turnstile", ["parts/part", "parts/ball"], function (exports_11, context_11) {
+ "use strict";
+ var __moduleName = context_11 && context_11.id;
+ var part_10, ball_1, Turnstile;
+ return {
+ setters: [
+ function (part_10_1) {
+ part_10 = part_10_1;
+ },
+ function (ball_1_1) {
+ ball_1 = ball_1_1;
+ }
+ ],
+ execute: function () {
+ Turnstile = class Turnstile extends part_10.Part {
+ constructor() {
+ super(...arguments);
+ this._centerBall = new ball_1.Ball(this.textures);
+ }
+ get canRotate() { return (true); }
+ get canMirror() { return (false); }
+ get canFlip() { return (true); }
+ get type() { return (11 /* TURNSTILE */); }
+ // the drop the turnstile is connected to
+ get drop() { return (this._drop); }
+ set drop(newDrop) {
+ if (newDrop === this.drop)
+ return;
+ if (this._drop)
+ this._drop.turnstiles.delete(this);
+ this._drop = newDrop;
+ if (this._drop) {
+ this._drop.turnstiles.add(this);
+ this.hue = this._drop.hue;
+ }
+ }
+ // put a ball in the center to show the color of the associated drop
+ _initSprite(layer) {
+ if (layer == 3 /* SCHEMATIC_BACK */) {
+ return (this._centerBall.getSpriteForLayer(4 /* SCHEMATIC */));
+ }
+ const sprite = super._initSprite(layer);
+ if ((layer == 2 /* FRONT */) && (!this._ballContainer)) {
+ this._ballContainer = new PIXI.Container();
+ this._ballContainer.addChild(this._centerBall.getSpriteForLayer(1 /* MID */));
+ this._ballContainer.addChild(this._centerBall.getSpriteForLayer(2 /* FRONT */));
+ sprite.addChild(this._ballContainer);
+ }
+ return (sprite);
+ }
+ // keep the ball the same size as the component
+ get size() { return (super.size); }
+ set size(s) {
+ if (s === this.size)
+ return;
+ super.size = s;
+ this._centerBall.size = s;
+ }
+ // pass hue through to the center ball
+ get hue() { return (this._centerBall.hue); }
+ set hue(v) {
+ this._centerBall.hue = v;
+ this._updateSprites();
+ }
+ // don't rotate or flip the ball or the highlight will look strange
+ _shouldRotateLayer(layer) {
+ return ((layer !== 0 /* BACK */) && (layer !== 2 /* FRONT */));
+ }
+ _shouldFlipLayer(layer) {
+ return (layer !== 2 /* FRONT */);
+ }
+ // release a ball when the turnstile makes a turn
+ get rotation() { return (super.rotation); }
+ set rotation(r) {
+ const oldRotation = this.rotation;
+ super.rotation = r;
+ if ((this.rotation == 0.0) && (oldRotation > 0.5) && (this.drop)) {
+ this.drop.releaseBall();
+ }
+ }
+ // configure for continuous rotation
+ get biasRotation() { return (false); }
+ get restingRotation() {
+ return (Math.round(this.rotation));
+ }
+ };
+ exports_11("Turnstile", Turnstile);
+ }
+ };
+});
+System.register("parts/drop", ["parts/part"], function (exports_12, context_12) {
+ "use strict";
+ var __moduleName = context_12 && context_12.id;
+ var part_11, Drop;
+ return {
+ setters: [
+ function (part_11_1) {
+ part_11 = part_11_1;
+ }
+ ],
+ execute: function () {
+ Drop = class Drop extends part_11.Part {
+ constructor() {
+ super(...arguments);
+ // a set of balls associated with the drop
+ this.balls = new Set();
+ // a set of turnstiles associated with the drop
+ this.turnstiles = new Set();
+ this._hue = 0.0;
+ }
+ get canRotate() { return (false); }
+ get canMirror() { return (false); }
+ get canFlip() { return (true); }
+ get type() { return (10 /* DROP */); }
+ // a flag to set signalling a desire to release a ball, which will be cleared
+ // after a ball is released
+ releaseBall() {
+ // find the ball closest to the bottom right
+ let closest;
+ let maxSum = -Infinity;
+ for (const ball of this.balls) {
+ // skip balls we've already released
+ if (ball.released)
+ continue;
+ // never release a ball that is outside the drop
+ if ((Math.round(ball.row) != this.row) ||
+ (Math.round(ball.column) != this.column))
+ continue;
+ let dc = ball.column - this.column;
+ if (this.isFlipped)
+ dc *= -1;
+ const d = dc + ball.row;
+ if (d > maxSum) {
+ closest = ball;
+ maxSum = d;
+ }
+ }
+ // release the ball closest to the exit if we found one
+ if (closest) {
+ closest.released = true;
+ if (this.onRelease)
+ this.onRelease();
+ }
+ }
+ // the hue of balls in this ball drop
+ get hue() { return (this._hue); }
+ set hue(v) {
+ if (isNaN(v))
+ return;
+ while (v < 0)
+ v += 360;
+ if (v >= 360)
+ v %= 360;
+ if (v === this._hue)
+ return;
+ this._hue = v;
+ for (const ball of this.balls) {
+ ball.hue = this.hue;
+ }
+ for (const turnstile of this.turnstiles) {
+ turnstile.hue = this.hue;
+ }
+ }
+ };
+ exports_12("Drop", Drop);
+ }
+ };
+});
+System.register("parts/factory", ["parts/location", "parts/ramp", "parts/crossover", "parts/interceptor", "parts/bit", "parts/gearbit", "parts/fence", "parts/blank", "parts/drop", "parts/ball", "parts/turnstile"], function (exports_13, context_13) {
+ "use strict";
+ var __moduleName = context_13 && context_13.id;
+ var location_1, ramp_1, crossover_1, interceptor_1, bit_1, gearbit_1, fence_1, blank_1, drop_1, ball_2, turnstile_1, PartFactory;
+ return {
+ setters: [
+ function (location_1_1) {
+ location_1 = location_1_1;
+ },
+ function (ramp_1_1) {
+ ramp_1 = ramp_1_1;
+ },
+ function (crossover_1_1) {
+ crossover_1 = crossover_1_1;
+ },
+ function (interceptor_1_1) {
+ interceptor_1 = interceptor_1_1;
+ },
+ function (bit_1_1) {
+ bit_1 = bit_1_1;
+ },
+ function (gearbit_1_1) {
+ gearbit_1 = gearbit_1_1;
+ },
+ function (fence_1_1) {
+ fence_1 = fence_1_1;
+ },
+ function (blank_1_1) {
+ blank_1 = blank_1_1;
+ },
+ function (drop_1_1) {
+ drop_1 = drop_1_1;
+ },
+ function (ball_2_1) {
+ ball_2 = ball_2_1;
+ },
+ function (turnstile_1_1) {
+ turnstile_1 = turnstile_1_1;
+ }
+ ],
+ execute: function () {
+ PartFactory = class PartFactory {
+ constructor(textures) {
+ this.textures = textures;
+ }
+ static constructorForType(type) {
+ switch (type) {
+ case 0 /* BLANK */: return (blank_1.Blank);
+ case 1 /* PARTLOC */: return (location_1.PartLocation);
+ case 2 /* GEARLOC */: return (location_1.GearLocation);
+ case 3 /* RAMP */: return (ramp_1.Ramp);
+ case 4 /* CROSSOVER */: return (crossover_1.Crossover);
+ case 5 /* INTERCEPTOR */: return (interceptor_1.Interceptor);
+ case 6 /* BIT */: return (bit_1.Bit);
+ case 8 /* GEAR */: return (gearbit_1.Gear);
+ case 7 /* GEARBIT */: return (gearbit_1.Gearbit);
+ case 9 /* BALL */: return (ball_2.Ball);
+ case 12 /* SIDE */: return (fence_1.Side);
+ case 13 /* SLOPE */: return (fence_1.Slope);
+ case 10 /* DROP */: return (drop_1.Drop);
+ case 11 /* TURNSTILE */: return (turnstile_1.Turnstile);
+ default: return (null);
+ }
+ }
+ // make a new part of the given type
+ make(type) {
+ const constructor = PartFactory.constructorForType(type);
+ if (!constructor)
+ return (null);
+ return (new constructor(this.textures));
+ }
+ // make a copy of the given part with the same basic state
+ copy(part) {
+ if (!part)
+ return (null);
+ const newPart = this.make(part.type);
+ if (newPart) {
+ newPart.rotation = part.bitValue ? 1.0 : 0.0;
+ newPart.isFlipped = part.isFlipped;
+ newPart.isLocked = part.isLocked;
+ newPart.hue = part.hue;
+ }
+ if ((newPart instanceof ball_2.Ball) && (part instanceof ball_2.Ball)) {
+ newPart.drop = part.drop;
+ if (newPart.drop)
+ newPart.drop.balls.add(newPart);
+ }
+ return (newPart);
+ }
+ };
+ exports_13("PartFactory", PartFactory);
+ }
+ };
+});
+System.register("renderer", ["pixi.js"], function (exports_14, context_14) {
+ "use strict";
+ var __moduleName = context_14 && context_14.id;
+ var PIXI, Renderer;
+ return {
+ setters: [
+ function (PIXI_1) {
+ PIXI = PIXI_1;
+ }
+ ],
+ execute: function () {
+ Renderer = class Renderer {
+ static needsUpdate() {
+ Renderer._needsUpdate = true;
+ }
+ static get interaction() {
+ return (Renderer.instance.plugins.interaction);
+ }
+ static render() {
+ // render at 30fps, it's good enough
+ if (Renderer._counter++ % 2 == 0)
+ return;
+ if (Renderer._needsUpdate) {
+ Renderer.instance.render(Renderer.stage);
+ Renderer._needsUpdate = false;
+ }
+ }
+ };
+ Renderer._needsUpdate = false;
+ Renderer.instance = PIXI.autoDetectRenderer({
+ antialias: false,
+ backgroundColor: 16777215 /* BACKGROUND */
+ });
+ Renderer.stage = new PIXI.Container();
+ Renderer._counter = 0;
+ exports_14("Renderer", Renderer);
+ }
+ };
+});
+System.register("ui/animator", ["renderer"], function (exports_15, context_15) {
+ "use strict";
+ var __moduleName = context_15 && context_15.id;
+ var renderer_1, Animator;
+ return {
+ setters: [
+ function (renderer_1_1) {
+ renderer_1 = renderer_1_1;
+ }
+ ],
+ execute: function () {
+ // centrally manage animations of properties
+ Animator = class Animator {
+ constructor() {
+ this._subjects = new Map();
+ }
+ // a singleton instance of the class
+ static get current() {
+ if (!Animator._current)
+ Animator._current = new Animator();
+ return (Animator._current);
+ }
+ // animate the given property of the given subject from its current value
+ // to the given end point, at a speed which would take the given time to
+ // traverse the range from start to end
+ animate(subject, property, start, end, time, callback) {
+ // handle the edge-cases of zero or negative time
+ if (!(time > 0.0)) {
+ this.stopAnimating(subject, property);
+ subject[property] = end;
+ return (null);
+ }
+ // get all animations for this subject
+ if (!this._subjects.has(subject))
+ this._subjects.set(subject, new Map());
+ const properties = this._subjects.get(subject);
+ // calculate a delta to traverse the property's entire range in the given time
+ const delta = (end - start) / (time * 60);
+ // update an existing animation
+ let animation = null;
+ if (properties.has(property)) {
+ animation = properties.get(property);
+ animation.start = start;
+ animation.end = end;
+ animation.time = time;
+ animation.delta = delta;
+ animation.callback = callback;
+ }
+ else {
+ animation = {
+ subject: subject,
+ property: property,
+ start: start,
+ end: end,
+ time: time,
+ delta: delta,
+ callback: callback
+ };
+ properties.set(property, animation);
+ }
+ return (animation);
+ }
+ // get the end value for the given property, or the current value if it's
+ // not currently being animated
+ getEndValue(subject, property) {
+ const current = subject[property];
+ if (!this._subjects.has(subject))
+ return (current);
+ const properties = this._subjects.get(subject);
+ if (!properties.has(property))
+ return (current);
+ return (properties.get(property).end);
+ }
+ // get whether the given property is being animated
+ isAnimating(subject, property) {
+ const current = subject[property];
+ if (!this._subjects.has(subject))
+ return (false);
+ const properties = this._subjects.get(subject);
+ return (properties.has(property));
+ }
+ // stop animating the given property, leaving the current value as-is
+ stopAnimating(subject, property) {
+ if (!this._subjects.has(subject))
+ return;
+ const properties = this._subjects.get(subject);
+ properties.delete(property);
+ // remove entries for subjects with no animations
+ if (properties.size == 0) {
+ this._subjects.delete(subject);
+ }
+ }
+ // advance all animations by one tick
+ update(correction) {
+ let someAnimations = false;
+ for (const [subject, properties] of this._subjects.entries()) {
+ for (const [property, animation] of properties) {
+ someAnimations = true;
+ let finished = false;
+ let current = subject[property];
+ current += (animation.delta * Math.abs(correction));
+ if (animation.delta > 0) {
+ if (current >= animation.end) {
+ current = animation.end;
+ finished = true;
+ }
+ }
+ else if (animation.delta < 0) {
+ if (current <= animation.end) {
+ current = animation.end;
+ finished = true;
+ }
+ }
+ else {
+ current = animation.end;
+ }
+ subject[property] = current;
+ if (finished) {
+ this.stopAnimating(subject, property);
+ if (animation.callback)
+ animation.callback();
+ }
+ }
+ }
+ if (someAnimations)
+ renderer_1.Renderer.needsUpdate();
+ }
+ };
+ exports_15("Animator", Animator);
+ }
+ };
+});
+System.register("parts/part", ["pixi.js", "renderer", "ui/animator"], function (exports_16, context_16) {
+ "use strict";
+ var __moduleName = context_16 && context_16.id;
+ var PIXI, renderer_2, animator_1, Part;
+ return {
+ setters: [
+ function (PIXI_2) {
+ PIXI = PIXI_2;
+ },
+ function (renderer_2_1) {
+ renderer_2 = renderer_2_1;
+ },
+ function (animator_1_1) {
+ animator_1 = animator_1_1;
+ }
+ ],
+ execute: function () {
+ ;
+ // base class for all parts
+ Part = class Part {
+ constructor(textures) {
+ this.textures = textures;
+ // whether the part can be replaced
+ this.isLocked = false;
+ // a counter to track changes to non-display properties
+ this.changeCounter = 0;
+ this._column = 0.0;
+ this._row = 0.0;
+ this._size = 64;
+ this._rotation = 0.0;
+ this._isFlipped = false;
+ this._x = 0;
+ this._y = 0;
+ this._alpha = 1;
+ this._visible = true;
+ this._sprites = new Map();
+ // adjustable offsets for textures (as a fraction of the size)
+ this._xOffset = 0.0;
+ this._yOffset = 0.0;
+ }
+ // the current position of the ball in grid units
+ get column() { return (this._column); }
+ set column(v) {
+ if (v === this._column)
+ return;
+ this._column = v;
+ this.changeCounter++;
+ }
+ get row() { return (this._row); }
+ set row(v) {
+ if (v === this._row)
+ return;
+ this._row = v;
+ this.changeCounter++;
+ }
+ // a placeholder for the hue property of parts that have it
+ get hue() { return (0); }
+ set hue(v) { }
+ // the unit-size of the part
+ get size() { return (this._size); }
+ set size(s) {
+ if (s === this._size)
+ return;
+ this._size = s;
+ this._updateSprites();
+ }
+ // the left/right rotation of the part (from 0.0 to 1.0)
+ get rotation() { return (this._rotation); }
+ set rotation(r) {
+ if (!this.canRotate)
+ return;
+ r = Math.min(Math.max(0.0, r), 1.0);
+ if (r === this._rotation)
+ return;
+ this._rotation = r;
+ this._updateSprites();
+ this.changeCounter++;
+ }
+ // whether the part is pointing right (or will be when animations finish)
+ get bitValue() {
+ return (animator_1.Animator.current.getEndValue(this, 'rotation') >= 0.5);
+ }
+ // whether the part is flipped to its left/right variant
+ get isFlipped() { return (this._isFlipped); }
+ set isFlipped(v) {
+ if ((!this.canFlip) || (v === this._isFlipped))
+ return;
+ this._isFlipped = v;
+ this._updateSprites();
+ this.changeCounter++;
+ }
+ // flip the part if it can be flipped
+ flip(time = 0.0) {
+ if (this.canFlip)
+ this.isFlipped = !this.isFlipped;
+ else if (this.canRotate) {
+ const bitValue = this.bitValue;
+ animator_1.Animator.current.animate(this, 'rotation', bitValue ? 1.0 : 0.0, bitValue ? 0.0 : 1.0, time);
+ // cancel rotation animations for connected gear trains
+ // (note that we don't refer to Gearbase to avoid a circular reference)
+ if ((this.type == 8 /* GEAR */) || (this.type == 7 /* GEARBIT */)) {
+ const connected = this.connected;
+ if (connected) {
+ for (const gear of connected) {
+ if (gear !== this)
+ animator_1.Animator.current.stopAnimating(gear, 'rotation');
+ }
+ }
+ }
+ }
+ }
+ // the part's horizontal position in the parent
+ get x() { return (this._x); }
+ set x(v) {
+ if (v === this._x)
+ return;
+ this._x = v;
+ this._updateSprites();
+ }
+ // the part's vertical position in the parent
+ get y() { return (this._y); }
+ set y(v) {
+ if (v === this._y)
+ return;
+ this._y = v;
+ this._updateSprites();
+ }
+ // the part's opacity
+ get alpha() { return (this._alpha); }
+ set alpha(v) {
+ if (v === this._alpha)
+ return;
+ this._alpha = v;
+ this._updateSprites();
+ }
+ // whether to show the part
+ get visible() { return (this._visible); }
+ set visible(v) {
+ if (v === this._visible)
+ return;
+ this._visible = v;
+ this._updateSprites();
+ }
+ // return whether the part has the same state as the given part
+ hasSameStateAs(part) {
+ return ((part) &&
+ (this.type === part.type) &&
+ (this.isFlipped === part.isFlipped) &&
+ (this.bitValue === part.bitValue));
+ }
+ // SPRITES ******************************************************************
+ // the prefix to append before texture names for this part
+ get texturePrefix() { return (this.constructor.name); }
+ // the suffix to append to select a specific layer
+ textureSuffix(layer) {
+ if (layer === 0 /* BACK */)
+ return ('-b');
+ if (layer === 1 /* MID */)
+ return ('-m');
+ if (layer === 2 /* FRONT */)
+ return ('-f');
+ if (layer === 3 /* SCHEMATIC_BACK */)
+ return ('-sb');
+ if (layer === 4 /* SCHEMATIC */)
+ return ('-s');
+ if (layer === 6 /* SCHEMATIC_4 */)
+ return ('-s4');
+ if (layer === 5 /* SCHEMATIC_2 */)
+ return ('-s2');
+ if (layer === 7 /* TOOL */)
+ return ('-t');
+ return ('');
+ }
+ // get texture names for the various layers
+ getTextureNameForLayer(layer) {
+ return (this.texturePrefix + this.textureSuffix(layer));
+ }
+ // return a sprite for the given layer, or null if there is none
+ getSpriteForLayer(layer) {
+ if (!this._sprites.has(layer)) {
+ this._sprites.set(layer, this._initSprite(layer));
+ this._updateSprite(layer);
+ }
+ return (this._sprites.get(layer));
+ }
+ // destroy all cached sprites for the part
+ destroySprites() {
+ for (const layer of this._sprites.keys()) {
+ const sprite = this._sprites.get(layer);
+ if (sprite)
+ sprite.destroy();
+ }
+ this._sprites.clear();
+ }
+ // set initial properties for a newly-created sprite
+ _initSprite(layer) {
+ const textureName = this.getTextureNameForLayer(layer);
+ const sprite = new PIXI.Sprite(this.textures[textureName]);
+ if ((!textureName) || (!(textureName in this.textures)))
+ return (null);
+ if (sprite) {
+ // always position sprites from the center
+ sprite.anchor.set(0.5, 0.5);
+ }
+ return (sprite);
+ }
+ // update all sprites to track the part's state
+ _updateSprites() {
+ for (let i = 0 /* BACK */; i < 9 /* COUNT */; i++) {
+ if (this._sprites.has(i))
+ this._updateSprite(i);
+ }
+ }
+ // update the given sprite to track the part's state
+ _updateSprite(layer) {
+ const sprite = this._sprites.get(layer);
+ if ((!sprite) || (!sprite.transform))
+ return;
+ // apply size
+ const size = (this.size > 2) ? (this.size * 1.5) : this.size;
+ sprite.width = size;
+ sprite.height = size;
+ // apply flipping
+ let xScale = (this._flipX && this._shouldFlipLayer(layer)) ?
+ -Math.abs(sprite.scale.x) : Math.abs(sprite.scale.x);
+ // apply rotation on all layers but the background
+ if (this._shouldRotateLayer(layer)) {
+ // if we can, flip the sprite when it rotates past the center so there's
+ // less distortion from the rotation transform
+ if ((this.canMirror) && (this.rotation > 0.5)) {
+ xScale = -xScale;
+ sprite.rotation = this.angleForRotation(this.rotation - 1.0, layer);
+ }
+ else {
+ sprite.rotation = this.angleForRotation(this.rotation, layer);
+ }
+ }
+ // apply any scale changes
+ sprite.scale.x = xScale;
+ // position the part
+ sprite.position.set(this.x + (this._xOffset * this.size), this.y + (this._yOffset * this.size));
+ // apply opacity and visibility
+ sprite.visible = this._isLayerVisible(layer);
+ sprite.alpha = this._layerAlpha(layer);
+ // schedule rendering
+ renderer_2.Renderer.needsUpdate();
+ }
+ // control the rotation of layers
+ _shouldRotateLayer(layer) {
+ return (layer !== 0 /* BACK */);
+ }
+ // control the flipping of layers
+ _shouldFlipLayer(layer) {
+ return (true);
+ }
+ // control the visibility of layers
+ _isLayerVisible(layer) {
+ return (this.visible);
+ }
+ // control the opacity of layers
+ _layerAlpha(layer) {
+ return (this._isLayerVisible(layer) ? this.alpha : 0.0);
+ }
+ // get the angle for the given rotation value
+ angleForRotation(r, layer = 1 /* MID */) {
+ return ((this.isFlipped ? -r : r) * (Math.PI / 2));
+ }
+ // get the rotation for the given angle
+ rotationForAngle(a) {
+ return ((this.isFlipped ? -a : a) / (Math.PI / 2));
+ }
+ // get whether to flip the x axis
+ get _flipX() {
+ return (this.isFlipped);
+ }
+ // PHYSICS ******************************************************************
+ // whether the body can be moved by the physics simulator
+ get bodyCanMove() { return (false); }
+ // whether the body can be rotated by the physics simulator
+ get bodyCanRotate() { return (this.canRotate); }
+ // the rotation to return the body to when not active
+ get restingRotation() { return (this.rotation); }
+ // whether the body has a counterweight (like a ramp)
+ get isCounterWeighted() { return (false); }
+ // whether to bias the rotation to either side
+ get biasRotation() { return (!this.isCounterWeighted); }
+ ;
+ // the amount the body will bounce in a collision (0.0 - 1.0)
+ get bodyRestitution() { return (0.1); }
+ };
+ exports_16("Part", Part);
+ }
+ };
+});
+/*
+ * Disjoint-set data structure - Library (TypeScript)
+ *
+ * Copyright (c) 2018 Project Nayuki. (MIT License)
+ * https://www.nayuki.io/page/disjoint-set-data-structure
+ *
+ * Permission is hereby granted, free of charge, to any person obtaining a copy of
+ * this software and associated documentation files (the "Software"), to deal in
+ * the Software without restriction, including without limitation the rights to
+ * use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
+ * the Software, and to permit persons to whom the Software is furnished to do so,
+ * subject to the following conditions:
+ * - The above copyright notice and this permission notice shall be included in
+ * all copies or substantial portions of the Software.
+ * - The Software is provided "as is", without warranty of any kind, express or
+ * implied, including but not limited to the warranties of merchantability,
+ * fitness for a particular purpose and noninfringement. In no event shall the
+ * authors or copyright holders be liable for any claim, damages or other
+ * liability, whether in an action of contract, tort or otherwise, arising from,
+ * out of or in connection with the Software or the use or other dealings in the
+ * Software.
+ */
+System.register("util/disjoint", [], function (exports_17, context_17) {
+ "use strict";
+ var __moduleName = context_17 && context_17.id;
+ var DisjointSet;
+ return {
+ setters: [],
+ execute: function () {
+ /*
+ * Represents a set of disjoint sets. Also known as the union-find data structure.
+ * Main operations are querying if two elements are in the same set, and merging two sets together.
+ * Useful for testing graph connectivity, and is used in Kruskal's algorithm.
+ */
+ DisjointSet = class DisjointSet {
+ // Constructs a new set containing the given number of singleton sets.
+ // For example, new DisjointSet(3) --> {{0}, {1}, {2}}.
+ constructor(numElems) {
+ // Per-node property arrays. This representation is more space-efficient than creating one node object per element.
+ this.parents = []; // The index of the parent element. An element is a representative iff its parent is itself.
+ this.ranks = []; // Always in the range [0, floor(log2(numElems))].
+ this.sizes = []; // Positive number if the element is a representative, otherwise zero.
+ if (numElems < 0)
+ throw "Number of elements must be non-negative";
+ this.numSets = numElems;
+ for (let i = 0; i < numElems; i++) {
+ this.parents.push(i);
+ this.ranks.push(0);
+ this.sizes.push(1);
+ }
+ }
+ // Returns the number of elements among the set of disjoint sets; this was the number passed
+ // into the constructor and is constant for the lifetime of the object. All the other methods
+ // require the argument elemIndex to satisfy 0 <= elemIndex < getNumberOfElements().
+ getNumberOfElements() {
+ return this.parents.length;
+ }
+ // Returns the number of disjoint sets overall. This number decreases monotonically as time progresses;
+ // each call to mergeSets() either decrements the number by one or leaves it unchanged. 0 <= result <= getNumberOfElements().
+ getNumberOfSets() {
+ return this.numSets;
+ }
+ // Returns the size of the set that the given element is a member of. 1 <= result <= getNumberOfElements().
+ getSizeOfSet(elemIndex) {
+ return this.sizes[this.getRepr(elemIndex)];
+ }
+ // Tests whether the given two elements are members of the same set. Note that the arguments are orderless.
+ areInSameSet(elemIndex0, elemIndex1) {
+ return this.getRepr(elemIndex0) == this.getRepr(elemIndex1);
+ }
+ // Merges together the sets that the given two elements belong to. This method is also known as "union" in the literature.
+ // If the two elements belong to different sets, then the two sets are merged and the method returns true.
+ // Otherwise they belong in the same set, nothing is changed and the method returns false. Note that the arguments are orderless.
+ mergeSets(elemIndex0, elemIndex1) {
+ // Get representatives
+ let repr0 = this.getRepr(elemIndex0);
+ let repr1 = this.getRepr(elemIndex1);
+ if (repr0 == repr1)
+ return false;
+ // Compare ranks
+ let cmp = this.ranks[repr0] - this.ranks[repr1];
+ if (cmp == 0)
+ this.ranks[repr0]++;
+ else if (cmp < 0) {
+ let temp = repr0;
+ repr0 = repr1;
+ repr1 = temp;
+ }
+ // Graft repr1's subtree onto node repr0
+ this.parents[repr1] = repr0;
+ this.sizes[repr0] += this.sizes[repr1];
+ this.sizes[repr1] = 0;
+ this.numSets--;
+ return true;
+ }
+ // Returns the representative element for the set containing the given element. This method is also
+ // known as "find" in the literature. Also performs path compression, which alters the internal state to
+ // improve the speed of future queries, but has no externally visible effect on the values returned.
+ getRepr(elemIndex) {
+ if (elemIndex < 0 || elemIndex >= this.parents.length)
+ throw "Element index out of bounds";
+ // Follow parent pointers until we reach a representative
+ let parent = this.parents[elemIndex];
+ if (parent == elemIndex)
+ return elemIndex;
+ while (true) {
+ let grandparent = this.parents[parent];
+ if (grandparent == parent)
+ return parent;
+ this.parents[elemIndex] = grandparent; // Partial path compression
+ elemIndex = parent;
+ parent = grandparent;
+ }
+ }
+ };
+ exports_17("DisjointSet", DisjointSet);
+ }
+ };
+});
+System.register("board/constants", [], function (exports_18, context_18) {
+ "use strict";
+ var __moduleName = context_18 && context_18.id;
+ var PART_SIZE, SPACING, BALL_RADIUS, PART_DENSITY, BALL_DENSITY, BALL_MASS, BALL_FRICTION, PART_FRICTION, DROP_FRICTION, BALL_FRICTION_STATIC, PART_FRICTION_STATIC, DROP_FRICTION_STATIC, IDEAL_VX, NUDGE_ACCEL, MAX_V, DAMPER_RADIUS, BIAS_STIFFNESS, BIT_BIAS_STIFFNESS, BIAS_DAMPING, COUNTERWEIGHT_STIFFNESS, COUNTERWEIGHT_DAMPING, PART_CATEGORY, UNRELEASED_BALL_CATEGORY, BALL_CATEGORY, GATE_CATEGORY, DEFAULT_MASK, PART_MASK, UNRELEASED_BALL_MASK, BALL_MASK, GATE_MASK;
+ return {
+ setters: [],
+ execute: function () {
+ // the canonical part size the simulator runs at
+ exports_18("PART_SIZE", PART_SIZE = 64);
+ exports_18("SPACING", SPACING = 68);
+ // the size of a ball in simulator units
+ exports_18("BALL_RADIUS", BALL_RADIUS = 10);
+ exports_18("PART_DENSITY", PART_DENSITY = 0.100);
+ exports_18("BALL_DENSITY", BALL_DENSITY = 0.008);
+ exports_18("BALL_MASS", BALL_MASS = BALL_DENSITY * (BALL_RADIUS * BALL_RADIUS * Math.PI));
+ exports_18("BALL_FRICTION", BALL_FRICTION = 0.03);
+ exports_18("PART_FRICTION", PART_FRICTION = 0.03);
+ exports_18("DROP_FRICTION", DROP_FRICTION = 0);
+ exports_18("BALL_FRICTION_STATIC", BALL_FRICTION_STATIC = 0.03);
+ exports_18("PART_FRICTION_STATIC", PART_FRICTION_STATIC = 0.03);
+ exports_18("DROP_FRICTION_STATIC", DROP_FRICTION_STATIC = 0);
+ // the ideal horizontal velocity at which a ball should be moving
+ exports_18("IDEAL_VX", IDEAL_VX = 1.5);
+ // the maximum acceleration to use when nudging the ball
+ exports_18("NUDGE_ACCEL", NUDGE_ACCEL = 0.001);
+ // the maximum speed at which a part can move
+ exports_18("MAX_V", MAX_V = 12);
+ // damping/counterweight constraint parameters
+ exports_18("DAMPER_RADIUS", DAMPER_RADIUS = PART_SIZE / 2);
+ exports_18("BIAS_STIFFNESS", BIAS_STIFFNESS = BALL_DENSITY / 16);
+ exports_18("BIT_BIAS_STIFFNESS", BIT_BIAS_STIFFNESS = BALL_DENSITY / 4);
+ exports_18("BIAS_DAMPING", BIAS_DAMPING = 0.3);
+ exports_18("COUNTERWEIGHT_STIFFNESS", COUNTERWEIGHT_STIFFNESS = BALL_DENSITY / 8);
+ exports_18("COUNTERWEIGHT_DAMPING", COUNTERWEIGHT_DAMPING = 0.1);
+ // collision filtering categories
+ exports_18("PART_CATEGORY", PART_CATEGORY = 0x0001);
+ exports_18("UNRELEASED_BALL_CATEGORY", UNRELEASED_BALL_CATEGORY = 0x0002);
+ exports_18("BALL_CATEGORY", BALL_CATEGORY = 0x0004);
+ exports_18("GATE_CATEGORY", GATE_CATEGORY = 0x0008);
+ exports_18("DEFAULT_MASK", DEFAULT_MASK = 0xFFFFFF);
+ exports_18("PART_MASK", PART_MASK = UNRELEASED_BALL_CATEGORY | BALL_CATEGORY);
+ exports_18("UNRELEASED_BALL_MASK", UNRELEASED_BALL_MASK = DEFAULT_MASK ^ BALL_CATEGORY);
+ exports_18("BALL_MASK", BALL_MASK = DEFAULT_MASK);
+ exports_18("GATE_MASK", GATE_MASK = DEFAULT_MASK ^ BALL_CATEGORY);
+ }
+ };
+});
+System.register("board/router", [], function (exports_19, context_19) {
+ "use strict";
+ var __moduleName = context_19 && context_19.id;
+ return {
+ setters: [],
+ execute: function () {
+ }
+ };
+});
+// WARNING: this file is autogenerated from src/svg/parts.svg
+// (any changes you make will be overwritten)
+System.register("parts/partvertices", [], function (exports_20, context_20) {
+ "use strict";
+ var __moduleName = context_20 && context_20.id;
+ function getVertexSets(name) {
+ switch (name) {
+ case 'Bit':
+ return ([[{ x: -1.055230, y: -32.311157 }, { x: 0.083096, y: -27.714949 }, { x: -27.716345, y: 0.194329 }, { x: -32.193815, y: -1.017236 }, { x: -34.041082, y: -34.054879 }], [{ x: -9.275339, y: -18.699340 }, { x: -18.644512, y: -8.976619 }, { x: -0.000001, y: 14.000036 }, { x: 12.203027, y: 15.153396 }, { x: 15.296620, y: 11.971412 }, { x: 13.999992, y: 0.000024 }], [{ x: 26.999991, y: -2.999976 }, { x: 27.625370, y: -30.038640 }, { x: 27.844205, y: -31.163654 }, { x: 28.781679, y: -32.163642 }, { x: 30.000425, y: -32.538571 }, { x: 31.156696, y: -32.288366 }, { x: 32.156683, y: -31.507138 }, { x: 32.625458, y: -30.163364 }, { x: 31.999992, y: -2.999976 }], [{ x: -4.000007, y: 27.000023 }, { x: -30.292815, y: 27.954316 }, { x: -31.416144, y: 28.181465 }, { x: -32.409014, y: 29.126461 }, { x: -32.774721, y: 30.348004 }, { x: -32.515786, y: 31.502385 }, { x: -31.727017, y: 32.496401 }, { x: -30.379740, y: 32.955008 }, { x: -4.000007, y: 32.000035 }], [{ x: 26.999991, y: -2.999976 }, { x: 13.999992, y: 0.000024 }, { x: 15.385008, y: 12.059815 }, { x: 28.731649, y: 2.602266 }, { x: 31.999992, y: -2.999976 }], [{ x: -4.000007, y: 27.000023 }, { x: 0.000033, y: 14.000036 }, { x: 11.959138, y: 15.360666 }, { x: 2.501589, y: 28.707311 }, { x: -4.000007, y: 32.000035 }]]);
+ case 'Crossover':
+ return ([[{ x: -0.125001, y: -48.250010 }, { x: -2.750000, y: -46.000019 }, { x: -2.750000, y: -15.874993 }, { x: 2.999999, y: -15.874993 }, { x: 2.999999, y: -46.374986 }], [{ x: -3.000008, y: -15.999982 }, { x: -12.000004, y: -9.999982 }, { x: -2.249999, y: 4.250008 }, { x: 2.374997, y: 4.250008 }, { x: 11.999991, y: -9.999982 }, { x: 2.999991, y: -15.999982 }], [{ x: -32.250002, y: 31.999979 }, { x: -0.051777, y: 29.502580 }, { x: 31.124997, y: 31.499985 }, { x: 32.874998, y: 34.374996 }, { x: 30.374999, y: 36.999991 }, { x: -30.250001, y: 36.999991 }, { x: -32.749999, y: 35.125005 }], [{ x: -36.000004, y: -27.999982 }, { x: -43.000006, y: -5.000008 }, { x: -48.000003, y: -2.999995 }, { x: -45.000003, y: -20.999995 }, { x: -36.000004, y: -35.999994 }], [{ x: -43.000006, y: -5.000008 }, { x: -33.000004, y: 6.999992 }, { x: -39.000004, y: 6.999992 }, { x: -48.000003, y: -2.999995 }], [{ x: -35.999992, y: -35.999994 }, { x: -32.000005, y: -35.999994 }, { x: -31.999994, y: -31.999969 }, { x: -36.000000, y: -27.999982 }], [{ x: 35.999937, y: -27.999982 }, { x: 42.999940, y: -5.000008 }, { x: 47.999937, y: -2.999995 }, { x: 44.999937, y: -20.999995 }, { x: 35.999937, y: -35.999994 }], [{ x: 42.999940, y: -5.000008 }, { x: 32.999938, y: 6.999992 }, { x: 38.999937, y: 6.999992 }, { x: 47.999937, y: -2.999995 }], [{ x: 35.999926, y: -35.999994 }, { x: 31.999992, y: -35.999994 }, { x: 31.999988, y: -31.999969 }, { x: 35.999934, y: -27.999982 }]]);
+ case 'Drop':
+ return ([[{ x: -37.000010, y: -36.999968 }, { x: -31.000048, y: -36.999968 }, { x: -31.000048, y: 21.000014 }, { x: -37.000010, y: 21.000014 }], [{ x: -24.987727, y: 28.000303 }, { x: 35.938482, y: 31.000038 }, { x: 35.643301, y: 36.992782 }, { x: -25.282870, y: 33.993046 }], [{ x: -31.000048, y: 21.000014 }, { x: -25.000048, y: 28.000001 }, { x: -25.000048, y: 34.000001 }, { x: -28.000048, y: 34.000001 }, { x: -34.000048, y: 29.000026 }, { x: -37.000048, y: 24.000013 }, { x: -37.000048, y: 21.000014 }]]);
+ case 'GearLocation':
+ return ([[{ x: -0.015622, y: -4.546899 }, { x: 2.093748, y: -4.046868 }, { x: 4.046879, y: -2.046893 }, { x: 4.562501, y: 0.015633 }, { x: 4.031251, y: 2.062512 }, { x: 2.093748, y: 4.015620 }, { x: -0.015622, y: 4.468748 }, { x: -2.031251, y: 4.000011 }, { x: -4.015620, y: 2.015608 }, { x: -4.546871, y: -0.031271 }, { x: -4.031252, y: -2.031246 }, { x: -2.046872, y: -4.000001 }]]);
+ case 'Gearbit':
+ return ([[{ x: -19.999999, y: 16.000007 }, { x: -22.637134, y: 25.233204 }, { x: -19.101594, y: 28.768725 }, { x: -14.858953, y: 22.316391 }, { x: -14.682185, y: 16.040826 }], [{ x: -22.637134, y: 25.144801 }, { x: -30.857243, y: 28.326785 }, { x: -30.945646, y: 32.569418 }, { x: -23.962966, y: 32.216032 }, { x: -18.748057, y: 28.326936 }], [{ x: 15.999997, y: -20.000005 }, { x: 25.168110, y: -23.063501 }, { x: 28.703632, y: -19.527961 }, { x: 22.251298, y: -15.285321 }, { x: 15.975733, y: -15.108552 }], [{ x: 25.079707, y: -23.063501 }, { x: 28.261691, y: -31.283611 }, { x: 32.504324, y: -31.372014 }, { x: 32.150939, y: -24.389333 }, { x: 28.261843, y: -19.174424 }], [{ x: -27.999999, y: -32.000001 }, { x: 15.999997, y: -20.000002 }, { x: 6.999994, y: 7.000024 }, { x: -20.000002, y: 16.000001 }, { x: -32.000001, y: -28.000003 }, { x: -31.999994, y: -31.999986 }]]);
+ case 'Interceptor':
+ return ([[{ x: -45.691339, y: -8.678367 }, { x: 45.525428, y: -8.678367 }, { x: 46.507670, y: -3.375047 }, { x: -46.600350, y: -3.375047 }], [{ x: -40.374999, y: -8.249995 }, { x: -28.500000, y: -30.875002 }, { x: -33.125000, y: -33.624986 }, { x: -42.000000, y: -20.749988 }, { x: -45.625001, y: -9.124993 }], [{ x: 40.624998, y: -8.249995 }, { x: 28.749999, y: -30.875002 }, { x: 33.374999, y: -33.624986 }, { x: 42.249998, y: -20.749988 }, { x: 45.875000, y: -9.124993 }], [{ x: -6.999999, y: -3.499998 }, { x: -6.500010, y: 3.625016 }, { x: -0.000012, y: 6.999982 }, { x: 6.374988, y: 3.624978 }, { x: 6.499977, y: -3.499998 }]]);
+ case 'PartLocation':
+ return ([[{ x: -0.015622, y: -4.546893 }, { x: 2.093748, y: -4.046862 }, { x: 4.046879, y: -2.046887 }, { x: 4.562501, y: 0.015639 }, { x: 4.031251, y: 2.062517 }, { x: 2.093748, y: 4.015626 }, { x: -0.015622, y: 4.468754 }, { x: -2.031251, y: 4.000017 }, { x: -4.015620, y: 2.015613 }, { x: -4.546871, y: -0.031265 }, { x: -4.031252, y: -2.031240 }, { x: -2.046872, y: -3.999996 }]]);
+ case 'Ramp':
+ return ([[{ x: 13.000001, y: -13.999998 }, { x: -32.000005, y: -24.999972 }, { x: -34.000006, y: -29.999985 }, { x: -34.000006, y: -31.999997 }, { x: -32.000005, y: -32.999985 }, { x: 16.000001, y: -21.000023 }], [{ x: 16.000001, y: -21.000023 }, { x: 25.000001, y: -24.000023 }, { x: 30.000002, y: -21.000023 }, { x: 23.000000, y: -16.000011 }, { x: 14.000000, y: -16.000011 }], [{ x: 25.000001, y: -24.000023 }, { x: 27.759381, y: -30.974460 }, { x: 30.000002, y: -31.999997 }, { x: 33.000002, y: -30.000023 }, { x: 30.000002, y: -21.000023 }], [{ x: -8.000006, y: 3.000014 }, { x: -27.999999, y: 10.999989 }, { x: -33.000000, y: 18.000014 }, { x: -33.000000, y: 25.999988 }, { x: -27.000004, y: 33.000013 }, { x: -16.000007, y: 33.000013 }, { x: -11.000006, y: 25.000001 }, { x: -5.000006, y: 6.000014 }], [{ x: -4.000000, y: -7.000011 }, { x: -7.999998, y: -3.000024 }, { x: -7.999998, y: 1.999989 }, { x: -4.000000, y: 7.000001 }, { x: 8.999999, y: 13.999989 }, { x: 14.000000, y: 13.999989 }, { x: 14.000000, y: 9.000014 }, { x: 5.999999, y: -6.000023 }], [{ x: -4.000000, y: -17.999985 }, { x: 12.999997, y: -13.999998 }, { x: 5.999999, y: -6.000023 }, { x: -4.000000, y: -7.000011 }]]);
+ case 'Side':
+ return ([[{ x: -37.000038, y: -34.000014 }, { x: -31.000038, y: -34.000014 }, { x: -31.000038, y: 33.999997 }, { x: -37.000038, y: 33.999997 }]]);
+ case 'Slope-1':
+ return ([[{ x: -32.000022, y: -35.999992 }, { x: 35.999988, y: 30.999925 }, { x: 31.999963, y: 36.000013 }, { x: -36.000010, y: -31.999994 }]]);
+ case 'Slope-2':
+ return ([[{ x: -32.000022, y: -35.999987 }, { x: 35.999988, y: -2.999988 }, { x: 32.999988, y: 3.000012 }, { x: -35.000022, y: -30.999989 }]]);
+ case 'Slope-3':
+ return ([[{ x: -33.000010, y: -35.999985 }, { x: 35.999988, y: -13.999983 }, { x: 33.999976, y: -7.999983 }, { x: -35.000022, y: -30.999984 }]]);
+ case 'Slope-4':
+ return ([[{ x: -33.000013, y: -36.999978 }, { x: 34.999960, y: -19.999981 }, { x: 32.999985, y: -13.999981 }, { x: -35.000026, y: -30.999978 }]]);
+ case 'Slope-5':
+ return ([[{ x: -34.000001, y: -36.999976 }, { x: 34.999960, y: -23.999974 }, { x: 33.999972, y: -16.999975 }, { x: -36.000013, y: -30.999976 }]]);
+ case 'Slope-6':
+ return ([[{ x: -34.000030, y: -35.999971 }, { x: 33.999994, y: -26.999966 }, { x: 33.999974, y: -19.999971 }, { x: -34.000017, y: -30.999971 }]]);
+ case 'Turnstile':
+ return ([[{ x: -32.500401, y: -33.999981 }, { x: 15.254059, y: -9.330725 }, { x: 12.500281, y: -3.999993 }, { x: -35.254179, y: -28.669249 }], [{ x: 32.500294, y: 34.000001 }, { x: -15.254149, y: 9.330753 }, { x: -12.500385, y: 4.000020 }, { x: 35.254057, y: 28.669279 }], [{ x: 33.999934, y: -32.500316 }, { x: 9.330694, y: 15.254111 }, { x: 3.999973, y: 12.500363 }, { x: 28.669213, y: -35.254080 }], [{ x: -34.000038, y: 32.500360 }, { x: -9.330798, y: -15.254068 }, { x: -4.000077, y: -12.500304 }, { x: -28.669317, y: 35.254123 }]]);
+ default:
+ return (null);
+ }
+ }
+ exports_20("getVertexSets", getVertexSets);
+ function getPinLocations(name) {
+ switch (name) {
+ default:
+ return (null);
+ }
+ }
+ exports_20("getPinLocations", getPinLocations);
+ return {
+ setters: [],
+ execute: function () {
+ }
+ };
+});
+System.register("parts/partbody", ["matter-js", "parts/factory", "parts/partvertices", "board/constants", "parts/ball", "parts/fence", "parts/drop", "parts/turnstile"], function (exports_21, context_21) {
+ "use strict";
+ var __moduleName = context_21 && context_21.id;
+ var matter_js_1, factory_1, partvertices_1, constants_1, ball_3, fence_2, drop_2, turnstile_2, PartBody, PartBodyFactory;
+ return {
+ setters: [
+ function (matter_js_1_1) {
+ matter_js_1 = matter_js_1_1;
+ },
+ function (factory_1_1) {
+ factory_1 = factory_1_1;
+ },
+ function (partvertices_1_1) {
+ partvertices_1 = partvertices_1_1;
+ },
+ function (constants_1_1) {
+ constants_1 = constants_1_1;
+ },
+ function (ball_3_1) {
+ ball_3 = ball_3_1;
+ },
+ function (fence_2_1) {
+ fence_2 = fence_2_1;
+ },
+ function (drop_2_1) {
+ drop_2 = drop_2_1;
+ },
+ function (turnstile_2_1) {
+ turnstile_2 = turnstile_2_1;
+ }
+ ],
+ execute: function () {
+ // this composes a part with a matter.js body which simulates it
+ PartBody = class PartBody {
+ constructor(part) {
+ this._body = undefined;
+ // the fence parameters last time we constructed a fence
+ this._slopeSignature = NaN;
+ this._composite = matter_js_1.Composite.create();
+ this._compositePosition = { x: 0.0, y: 0.0 };
+ this._bodyOffset = { x: 0.0, y: 0.0 };
+ this._bodyFlipped = false;
+ this._partChangeCounter = NaN;
+ this.type = part.type;
+ this.part = part;
+ }
+ get part() { return (this._part); }
+ set part(part) {
+ if (part === this._part)
+ return;
+ if (part) {
+ if (part.type !== this.type)
+ throw ('Part type must match PartBody type');
+ this._partChangeCounter = NaN;
+ this._part = part;
+ this.initBodyFromPart();
+ }
+ }
+ // a body representing the physical form of the part
+ get body() {
+ // if there are no stored vertices, the body will be set to null,
+ // and we shouldn't keep trying to construct it
+ if (this._body === undefined)
+ this._makeBody();
+ return (this._body);
+ }
+ ;
+ _makeBody() {
+ this._body = null;
+ // construct the ball as a circle
+ if (this.type == 9 /* BALL */) {
+ this._body = matter_js_1.Bodies.circle(0, 0, constants_1.BALL_RADIUS, { density: constants_1.BALL_DENSITY, friction: constants_1.BALL_FRICTION,
+ frictionStatic: constants_1.BALL_FRICTION_STATIC,
+ collisionFilter: { category: constants_1.UNRELEASED_BALL_CATEGORY, mask: constants_1.UNRELEASED_BALL_MASK, group: 0 } });
+ }
+ else if (this._part instanceof fence_2.Slope) {
+ this._body = this._bodyForSlope(this._part);
+ this._slopeSignature = this._part.signature;
+ }
+ else {
+ const constructor = factory_1.PartFactory.constructorForType(this.type);
+ this._body = this._bodyFromVertexSets(partvertices_1.getVertexSets(constructor.name));
+ }
+ if (this._body) {
+ matter_js_1.Body.setPosition(this._body, { x: 0.0, y: 0.0 });
+ matter_js_1.Composite.add(this._composite, this._body);
+ }
+ this.initBodyFromPart();
+ }
+ _refreshBody() {
+ this._clearBody();
+ this._makeBody();
+ }
+ // a composite representing the body and related constraints, etc.
+ get composite() { return (this._composite); }
+ // initialize the body after creation
+ initBodyFromPart() {
+ if ((!this._body) || (!this._part))
+ return;
+ // parts that can't rotate can be static
+ if ((!this._part.bodyCanRotate) && (!this._part.bodyCanMove)) {
+ matter_js_1.Body.setStatic(this._body, true);
+ }
+ else {
+ matter_js_1.Body.setStatic(this._body, false);
+ }
+ // add bodies and constraints to control rotation
+ if (this._part.bodyCanRotate) {
+ this._makeRotationConstraints();
+ }
+ // set restitution
+ this._body.restitution = this._part.bodyRestitution;
+ // do special configuration for ball drops
+ if (this._part.type == 10 /* DROP */) {
+ this._makeDropGate();
+ }
+ // perform a first update of properties from the part
+ this.updateBodyFromPart();
+ }
+ _makeRotationConstraints() {
+ // make constraints that bias parts and keep them from bouncing at the
+ // ends of their range
+ if (this._part.isCounterWeighted) {
+ this._counterweightDamper = this._makeDamper(this._part.isFlipped, true, constants_1.COUNTERWEIGHT_STIFFNESS, constants_1.COUNTERWEIGHT_DAMPING);
+ }
+ else if (this._part.biasRotation) {
+ this._biasDamper = this._makeDamper(false, false, this._part.type == 6 /* BIT */ ? constants_1.BIT_BIAS_STIFFNESS : constants_1.BIAS_STIFFNESS, constants_1.BIAS_DAMPING);
+ }
+ }
+ _makeDamper(flipped, counterweighted, stiffness, damping) {
+ const constraint = matter_js_1.Constraint.create({
+ bodyA: this._body,
+ pointA: this._damperAttachmentVector(flipped),
+ pointB: this._damperAnchorVector(flipped, counterweighted),
+ stiffness: stiffness,
+ damping: damping
+ });
+ matter_js_1.Composite.add(this._composite, constraint);
+ return (constraint);
+ }
+ _damperAttachmentVector(flipped) {
+ return ({ x: flipped ? constants_1.DAMPER_RADIUS : -constants_1.DAMPER_RADIUS,
+ y: -constants_1.DAMPER_RADIUS });
+ }
+ _damperAnchorVector(flipped, counterweighted) {
+ return (counterweighted ?
+ { x: (flipped ? constants_1.DAMPER_RADIUS : -constants_1.DAMPER_RADIUS), y: 0 } :
+ { x: 0, y: constants_1.DAMPER_RADIUS });
+ }
+ _makeDropGate() {
+ this._body.friction = constants_1.DROP_FRICTION;
+ this._body.friction = constants_1.DROP_FRICTION_STATIC;
+ const sign = this._part.isFlipped ? -1 : 1;
+ this._dropGate = matter_js_1.Bodies.rectangle((constants_1.SPACING / 2) * sign, 0, constants_1.PART_SIZE / 16, constants_1.SPACING, { friction: constants_1.DROP_FRICTION, frictionStatic: constants_1.DROP_FRICTION_STATIC,
+ collisionFilter: { category: constants_1.GATE_CATEGORY, mask: constants_1.GATE_MASK, group: 0 },
+ isStatic: true });
+ matter_js_1.Composite.add(this._composite, this._dropGate);
+ }
+ // remove all constraints and bodies we've added to the composite
+ _clearBody() {
+ const clear = (item) => {
+ if (item)
+ matter_js_1.Composite.remove(this._composite, item);
+ return (undefined);
+ };
+ this._counterweightDamper = clear(this._counterweightDamper);
+ this._biasDamper = clear(this._biasDamper);
+ this._dropGate = clear(this._dropGate);
+ this._body = clear(this._body);
+ this._compositePosition.x = this._compositePosition.y = 0;
+ }
+ // transfer relevant properties to the body
+ updateBodyFromPart() {
+ // skip the update if we have no part
+ if ((!this._body) || (!this._part))
+ return;
+ // update collision masks for balls
+ if (this._part instanceof ball_3.Ball) {
+ this._body.collisionFilter.category = this._part.released ?
+ constants_1.BALL_CATEGORY : constants_1.UNRELEASED_BALL_CATEGORY;
+ this._body.collisionFilter.mask = this._part.released ?
+ constants_1.BALL_MASK : constants_1.UNRELEASED_BALL_MASK;
+ }
+ // skip the rest of the update if the part hasn't changed
+ if (this._part.changeCounter === this._partChangeCounter)
+ return;
+ // rebuild the body if the slope signature changes
+ if ((this._part instanceof fence_2.Slope) &&
+ (this._part.signature != this._slopeSignature)) {
+ this._refreshBody();
+ return;
+ }
+ // update mirroring
+ if (this._bodyFlipped !== this._part.isFlipped) {
+ this._refreshBody();
+ return;
+ }
+ // update position
+ const position = { x: (this._part.column * constants_1.SPACING) + this._bodyOffset.x,
+ y: (this._part.row * constants_1.SPACING) + this._bodyOffset.y };
+ const positionDelta = matter_js_1.Vector.sub(position, this._compositePosition);
+ matter_js_1.Composite.translate(this._composite, positionDelta, true);
+ this._compositePosition = position;
+ matter_js_1.Body.setVelocity(this._body, { x: 0, y: 0 });
+ // move damper anchor points
+ if (this._counterweightDamper) {
+ matter_js_1.Vector.add(this._body.position, this._damperAnchorVector(this._part.isFlipped, true), this._counterweightDamper.pointB);
+ }
+ if (this._biasDamper) {
+ matter_js_1.Vector.add(this._body.position, this._damperAnchorVector(this._part.isFlipped, false), this._biasDamper.pointB);
+ }
+ matter_js_1.Body.setAngle(this._body, this._part.angleForRotation(this._part.rotation));
+ // record that we've synced with the part
+ this._partChangeCounter = this._part.changeCounter;
+ }
+ // tranfer relevant properties from the body
+ updatePartFromBody() {
+ if ((!this._body) || (!this._part) || (this._body.isStatic))
+ return;
+ if (this._part.bodyCanMove) {
+ this._part.column = this._body.position.x / constants_1.SPACING;
+ this._part.row = this._body.position.y / constants_1.SPACING;
+ }
+ if (this._part.bodyCanRotate) {
+ const r = this._part.rotationForAngle(this._body.angle);
+ this._part.rotation = r;
+ }
+ // record that we've synced with the part
+ this._partChangeCounter = this._part.changeCounter;
+ }
+ // add the body to the given world, creating the body if needed
+ addToWorld(world) {
+ const body = this.body;
+ if (body) {
+ matter_js_1.World.add(world, this._composite);
+ // try to release any stored energy in the part
+ matter_js_1.Body.setVelocity(this._body, { x: 0, y: 0 });
+ matter_js_1.Body.setAngularVelocity(this._body, 0);
+ }
+ }
+ // remove the body from the given world
+ removeFromWorld(world) {
+ matter_js_1.World.remove(world, this._composite);
+ }
+ // construct a body for the current fence configuration
+ _bodyForSlope(slope) {
+ const name = 'Slope-' + slope.modulus;
+ const y = -((slope.sequence % slope.modulus) / slope.modulus) * constants_1.SPACING;
+ return (this._bodyFromVertexSets(partvertices_1.getVertexSets(name), 0, y));
+ }
+ // construct a body from a set of vertex lists
+ _bodyFromVertexSets(vertexSets, x = 0, y = 0) {
+ if (!vertexSets)
+ return (null);
+ const parts = [];
+ this._bodyFlipped = this._part.isFlipped;
+ for (const vertices of vertexSets) {
+ // flip the vertices if the part is flipped
+ if (this._part.isFlipped) {
+ matter_js_1.Vertices.scale(vertices, -1, 1, { x: 0, y: 0 });
+ }
+ // make sure they're in clockwise order, because flipping reverses
+ // their direction and we can't be sure how the source SVG is drawn
+ matter_js_1.Vertices.clockwiseSort(vertices);
+ const center = matter_js_1.Vertices.centre(vertices);
+ parts.push(matter_js_1.Body.create({ position: center, vertices: vertices }));
+ }
+ const body = matter_js_1.Body.create({ parts: parts,
+ friction: constants_1.PART_FRICTION, frictionStatic: constants_1.PART_FRICTION_STATIC,
+ density: constants_1.PART_DENSITY,
+ collisionFilter: { category: constants_1.PART_CATEGORY, mask: constants_1.PART_MASK, group: 0 } });
+ // this is a hack to prevent matter.js from placing the body's center
+ // of mass over the origin, which complicates our ability to precisely
+ // position parts of an arbitrary shape
+ body.position.x = x;
+ body.position.y = y;
+ body.positionPrev.x = x;
+ body.positionPrev.y = y;
+ return (body);
+ }
+ // PHYSICS ENGINE CHEATS ****************************************************
+ // apply corrections to the body and any balls contacting it
+ cheat(contacts, nearby) {
+ if ((!this._body) || (!this._part))
+ return;
+ this._controlRotation(contacts, nearby);
+ this._controlVelocity();
+ this._nudge(contacts, nearby);
+ if (nearby) {
+ for (const ballPartBody of nearby) {
+ this._influenceBall(ballPartBody);
+ }
+ }
+ }
+ _nudge(contacts, nearby) {
+ if (!contacts)
+ return;
+ // don't nudge multiple balls on slopes,
+ // it tends to cause pileups in the output
+ if ((this._part.type === 13 /* SLOPE */) && (contacts.size > 1))
+ return;
+ for (const contact of contacts) {
+ const nudged = this._nudgeBall(contact);
+ // if we've nudged a ball, don't do other stuff to it
+ if ((nudged) && (nearby))
+ nearby.delete(contact.ballPartBody);
+ }
+ }
+ // constrain the position and angle of the part to simulate
+ // an angle-constrained revolute joint
+ _controlRotation(contacts, nearby) {
+ const positionDelta = { x: 0, y: 0 };
+ let angleDelta = 0;
+ let moved = false;
+ if (!this._part.bodyCanMove) {
+ matter_js_1.Vector.sub(this._compositePosition, this._body.position, positionDelta);
+ matter_js_1.Body.translate(this._body, positionDelta);
+ matter_js_1.Body.setVelocity(this._body, { x: 0, y: 0 });
+ moved = true;
+ }
+ if (this._part.bodyCanRotate) {
+ const r = this._part.rotationForAngle(this._body.angle);
+ let target = this._part.angleForRotation(Math.min(Math.max(0.0, r), 1.0));
+ let lock = false;
+ if (this._part instanceof turnstile_2.Turnstile) {
+ // turnstiles can only rotate in one direction
+ if (((!this._part.isFlipped) && (this._body.angularVelocity < 0)) ||
+ ((this._part.isFlipped) && (this._body.angularVelocity > 0))) {
+ matter_js_1.Body.setAngularVelocity(this._body, 0);
+ }
+ // engage and disengage based on ball contact
+ const engaged = ((nearby instanceof Set) && (nearby.size > 0));
+ if (!engaged) {
+ target = this._part.angleForRotation(0);
+ lock = true;
+ }
+ else if (r >= 1.0)
+ lock = true;
+ }
+ else if ((r < 0) || (r > 1))
+ lock = true;
+ if (lock) {
+ angleDelta = target - this._body.angle;
+ matter_js_1.Body.rotate(this._body, angleDelta);
+ matter_js_1.Body.setAngularVelocity(this._body, 0);
+ }
+ moved = true;
+ }
+ // apply the same movements to balls if there are any, otherwise they
+ // will squash into the part
+ if ((moved) && (contacts)) {
+ const combined = matter_js_1.Vector.rotate(positionDelta, angleDelta);
+ for (const contact of contacts) {
+ matter_js_1.Body.translate(contact.ballPartBody.body, combined);
+ }
+ }
+ }
+ // apply a limit to how fast a part can move, mainly to prevent fall-through
+ // and conditions resulting from too much kinetic energy
+ _controlVelocity() {
+ if ((!this._body) || (!this._part) || (!this._part.bodyCanMove))
+ return;
+ if (matter_js_1.Vector.magnitude(this._body.velocity) > constants_1.MAX_V) {
+ const v = matter_js_1.Vector.mult(matter_js_1.Vector.normalise(this._body.velocity), constants_1.MAX_V);
+ matter_js_1.Body.setVelocity(this._body, v);
+ }
+ }
+ // apply a speed limit to the given ball
+ _nudgeBall(contact) {
+ if ((!this._body) || (!contact.ballPartBody.body))
+ return (false);
+ const ball = contact.ballPartBody.part;
+ const body = contact.ballPartBody.body;
+ let tangent = matter_js_1.Vector.clone(contact.tangent);
+ // only nudge the ball if it's touching a horizontal-ish surface
+ let maxSlope = 0.3;
+ // get the horizontal direction and relative magnitude we want the ball
+ // to be going in
+ let mag = 1;
+ let sign = 0;
+ // ramps direct in a single direction
+ if (this._part.type == 3 /* RAMP */) {
+ if ((this._part.rotation < 0.25) && (ball.row < this._part.row)) {
+ sign = this._part.isFlipped ? -1 : 1;
+ }
+ if (body.velocity.y < 0) {
+ matter_js_1.Body.setVelocity(body, { x: body.velocity.x, y: 0 });
+ }
+ }
+ else if (this._part.type == 7 /* GEARBIT */) {
+ if (this._part.rotation < 0.25)
+ sign = 1;
+ else if (this._part.rotation > 0.75)
+ sign = -1;
+ }
+ else if (this._part.type == 6 /* BIT */) {
+ const bottomHalf = ball.row > this._part.row;
+ if (this._part.rotation >= 0.9)
+ sign = bottomHalf ? 1 : -1;
+ else if (this._part.rotation <= 0.1)
+ sign = bottomHalf ? -1 : 1;
+ if (!bottomHalf)
+ mag = 0.5;
+ }
+ else if (this._part.type == 4 /* CROSSOVER */) {
+ if (ball.lastDistinctColumn < ball.lastColumn)
+ sign = 1;
+ else if (ball.lastDistinctColumn > ball.lastColumn)
+ sign = -1;
+ else if (ball.row < this._part.row) {
+ sign = ball.column < this._part.column ? 1 : -1;
+ // remember this for when we get to the bottom
+ ball.lastDistinctColumn -= sign;
+ }
+ else {
+ sign = ball.column < this._part.column ? -1 : 1;
+ }
+ if (ball.row < this._part.row)
+ mag *= 16;
+ }
+ else if (this._part instanceof fence_2.Slope) {
+ mag = 2;
+ sign = this._part.isFlipped ? -1 : 1;
+ // the tangent is always the same for slopes, and setting it explicitly
+ // prevents strange effect at corners
+ tangent = matter_js_1.Vector.normalise({ x: this._part.modulus * sign, y: 1 });
+ maxSlope = 1;
+ }
+ else if ((this._part instanceof drop_2.Drop) && (ball.released)) {
+ sign = this._part.isFlipped ? -1 : 1;
+ }
+ // exit if we're not nudging
+ if (sign == 0)
+ return (false);
+ // limit slope
+ const slope = Math.abs(tangent.y) / Math.abs(tangent.x);
+ if (slope > maxSlope)
+ return (false);
+ // flip the tangent if the direction doesn't match the target direction
+ if (((sign < 0) && (tangent.x > 0)) ||
+ ((sign > 0) && (tangent.x < 0)))
+ tangent = matter_js_1.Vector.mult(tangent, -1);
+ // see how much and in which direction we need to correct the horizontal velocity
+ const target = constants_1.IDEAL_VX * sign * mag;
+ const current = body.velocity.x;
+ let accel = 0;
+ if (sign > 0) {
+ if (current < target)
+ accel = constants_1.NUDGE_ACCEL; // too slow => right
+ else if (current > target)
+ accel = -constants_1.NUDGE_ACCEL; // too fast => right
+ }
+ else {
+ if (target < current)
+ accel = constants_1.NUDGE_ACCEL; // too slow <= left
+ else if (target > current)
+ accel = -constants_1.NUDGE_ACCEL; // too fast <= left
+ }
+ if (accel == 0)
+ return (false);
+ // scale the acceleration by the difference
+ // if it gets close to prevent flip-flopping
+ accel *= Math.min(Math.abs(current - target) * 4, 1.0);
+ // accelerate the ball in the desired direction
+ matter_js_1.Body.applyForce(body, body.position, matter_js_1.Vector.mult(tangent, accel * body.mass));
+ // return that we've nudged the ball
+ return (true);
+ }
+ // apply trajectory influences to balls in the vicinity
+ _influenceBall(ballPartBody) {
+ const ball = ballPartBody.part;
+ const body = ballPartBody.body;
+ // crossovers are complicated!
+ if (this._part.type == 4 /* CROSSOVER */) {
+ const currentSign = body.velocity.x > 0 ? 1 : -1;
+ // make trajectories in the upper half of the crossover more diagonal,
+ // which ensures they have enough horizontal energy to make it through
+ // the bottom half without the "conveyer belt" nudge being obvious
+ if ((ball.row < this._part.row) && (body.velocity.x > 0.001)) {
+ if (Math.abs(body.velocity.x) < Math.abs(body.velocity.y)) {
+ matter_js_1.Body.applyForce(body, body.position, { x: currentSign * constants_1.NUDGE_ACCEL * body.mass, y: 0 });
+ return (true);
+ }
+ }
+ else if (ball.row > this._part.row) {
+ let desiredSign = 0;
+ if (ball.lastDistinctColumn < ball.lastColumn)
+ desiredSign = 1;
+ else if (ball.lastDistinctColumn > ball.lastColumn)
+ desiredSign = -1;
+ if ((desiredSign != 0) && (desiredSign != currentSign)) {
+ matter_js_1.Body.applyForce(body, body.position, { x: desiredSign * constants_1.NUDGE_ACCEL * body.mass, y: 0 });
+ return (true);
+ }
+ }
+ }
+ return (false);
+ }
+ };
+ exports_21("PartBody", PartBody);
+ // FACTORY / CACHE ************************************************************
+ // maintain a cache of PartBody instances
+ PartBodyFactory = class PartBodyFactory {
+ constructor() {
+ // cached instances
+ this._instances = new WeakMap();
+ }
+ // make or reuse a part body from the cache
+ make(part) {
+ if (!this._instances.has(part)) {
+ this._instances.set(part, new PartBody(part));
+ }
+ return (this._instances.get(part));
+ }
+ // mark that a part body is not currently being used
+ release(instance) {
+ }
+ };
+ exports_21("PartBodyFactory", PartBodyFactory);
+ }
+ };
+});
+System.register("board/physics", ["pixi.js", "matter-js", "renderer", "parts/gearbit", "parts/partbody", "board/constants", "ui/animator"], function (exports_22, context_22) {
+ "use strict";
+ var __moduleName = context_22 && context_22.id;
+ var PIXI, matter_js_2, renderer_3, gearbit_2, partbody_1, constants_2, animator_2, PhysicalBallRouter;
+ return {
+ setters: [
+ function (PIXI_3) {
+ PIXI = PIXI_3;
+ },
+ function (matter_js_2_1) {
+ matter_js_2 = matter_js_2_1;
+ },
+ function (renderer_3_1) {
+ renderer_3 = renderer_3_1;
+ },
+ function (gearbit_2_1) {
+ gearbit_2 = gearbit_2_1;
+ },
+ function (partbody_1_1) {
+ partbody_1 = partbody_1_1;
+ },
+ function (constants_2_1) {
+ constants_2 = constants_2_1;
+ },
+ function (animator_2_1) {
+ animator_2 = animator_2_1;
+ }
+ ],
+ execute: function () {
+ PhysicalBallRouter = class PhysicalBallRouter {
+ constructor(board) {
+ this.board = board;
+ this.partBodyFactory = new partbody_1.PartBodyFactory();
+ this._boardChangeCounter = -1;
+ this._wallWidth = 16;
+ this._wallHeight = 16;
+ this._wallThickness = 16;
+ this._ballNeighbors = new Map();
+ this._parts = new Map();
+ this._bodies = new Map();
+ this.engine = matter_js_2.Engine.create();
+ this.balls = this.board.balls;
+ // make walls to catch stray balls
+ this._createWalls();
+ // capture initial board state
+ this.beforeUpdate();
+ }
+ onBoardSizeChanged() {
+ // update the walls around the board
+ this._updateWalls();
+ // re-render the wireframe
+ this.renderWireframe();
+ // capture changes to board state
+ this.beforeUpdate();
+ }
+ // UPDATING *****************************************************************
+ update(speed, correction) {
+ if (!(speed > 0))
+ return;
+ let iterations = speed * 2;
+ if (iterations < 1) {
+ this.engine.timing.timeScale = speed;
+ iterations = 1;
+ }
+ else
+ this.engine.timing.timeScale = 1;
+ for (let i = 0; i < iterations; i++) {
+ this.beforeUpdate();
+ matter_js_2.Engine.update(this.engine);
+ this.afterUpdate();
+ gearbit_2.GearBase.update();
+ }
+ }
+ beforeUpdate() {
+ const partsChanged = this.addNeighborParts(this._boardChangeCounter !== this.board.changeCounter);
+ this._boardChangeCounter = this.board.changeCounter;
+ for (const partBody of this._parts.values()) {
+ partBody.updateBodyFromPart();
+ }
+ // if parts have been added or removed, update the broadphase grid
+ if ((partsChanged) && (this.engine.broadphase)) {
+ matter_js_2.Grid.update(this.engine.broadphase, matter_js_2.Composite.allBodies(this.engine.world), this.engine, true);
+ }
+ }
+ afterUpdate() {
+ // determine the set of balls touching each part
+ const contacts = this._mapContacts();
+ const nearby = this._mapNearby();
+ // apply physics corrections
+ for (const partBody of this._parts.values()) {
+ partBody.cheat(contacts.get(partBody), nearby.get(partBody));
+ }
+ // transfer part positions
+ for (const [part, partBody] of this._parts.entries()) {
+ partBody.updatePartFromBody();
+ if (part.bodyCanMove) {
+ this.board.layoutPart(part, part.column, part.row);
+ }
+ }
+ // combine the velocities of connected gear trains
+ this.connectGears(contacts);
+ // re-render the wireframe if there is one
+ this.renderWireframe();
+ // re-render the whole display if we're managing parts
+ if (this._parts.size > 0)
+ renderer_3.Renderer.needsUpdate();
+ }
+ // average the angular velocities of all simulated gears with ball contacts,
+ // and transfer it to all simulated gears that are connected
+ connectGears(contacts) {
+ const activeTrains = new Set();
+ for (const part of this._parts.keys()) {
+ if (part instanceof gearbit_2.GearBase)
+ activeTrains.add(part.connected);
+ }
+ for (const train of activeTrains) {
+ let av = 0;
+ let contactCount = 0;
+ for (const gear of train) {
+ // select gears which are simulated and have balls in contact
+ const partBody = this._parts.get(gear);
+ if ((partBody) && (partBody.body) && (contacts.has(partBody))) {
+ av += partBody.body.angularVelocity;
+ contactCount++;
+ }
+ }
+ // transfer the average angular velocity to all connected gears
+ if (contactCount > 0) {
+ av /= contactCount;
+ for (const gear of train) {
+ const partBody = this._parts.get(gear);
+ if ((partBody) && (partBody.body)) {
+ matter_js_2.Body.setAngularVelocity(partBody.body, av);
+ }
+ }
+ }
+ }
+ }
+ _mapContacts() {
+ const contacts = new Map();
+ for (const pair of this.engine.pairs.collisionActive) {
+ const partA = this._findPartBody(pair.bodyA);
+ if (!partA)
+ continue;
+ const partB = this._findPartBody(pair.bodyB);
+ if (!partB)
+ continue;
+ if ((partA.type == 9 /* BALL */) && (partB.type != 9 /* BALL */)) {
+ if (!contacts.has(partB))
+ contacts.set(partB, new Set());
+ contacts.get(partB).add({ ballPartBody: partA, tangent: pair.collision.tangent });
+ }
+ else if ((partB.type == 9 /* BALL */) && (partA.type != 9 /* BALL */)) {
+ if (!contacts.has(partA))
+ contacts.set(partA, new Set());
+ contacts.get(partA).add({ ballPartBody: partB, tangent: pair.collision.tangent });
+ }
+ }
+ return (contacts);
+ }
+ _findPartBody(body) {
+ if (this._bodies.has(body))
+ return (this._bodies.get(body));
+ if ((body.parent) && (body.parent !== body)) {
+ return (this._findPartBody(body.parent));
+ }
+ return (null);
+ }
+ // map parts to the balls in their grid square
+ _mapNearby() {
+ const map = new Map;
+ for (const ball of this.balls) {
+ const ballPartBody = this._parts.get(ball);
+ if (!ballPartBody)
+ continue;
+ const part = this.board.getPart(Math.round(ball.column), Math.round(ball.row));
+ const partBody = this._parts.get(part);
+ if (!partBody)
+ continue;
+ if (!map.has(partBody))
+ map.set(partBody, new Set());
+ map.get(partBody).add(ballPartBody);
+ }
+ return (map);
+ }
+ // STATE MANAGEMENT *********************************************************
+ _createWalls() {
+ const options = { isStatic: true };
+ this._top = matter_js_2.Bodies.rectangle(0, 0, this._wallWidth, this._wallThickness, options);
+ this._bottom = matter_js_2.Bodies.rectangle(0, 0, this._wallWidth, this._wallThickness, options);
+ this._left = matter_js_2.Bodies.rectangle(0, 0, this._wallThickness, this._wallHeight, options);
+ this._right = matter_js_2.Bodies.rectangle(0, 0, this._wallThickness, this._wallHeight, options);
+ matter_js_2.World.add(this.engine.world, [this._top, this._right, this._bottom, this._left]);
+ }
+ _updateWalls() {
+ const w = ((this.board.columnCount + 3) * constants_2.SPACING);
+ const h = ((this.board.rowCount + 5) * constants_2.SPACING);
+ const hw = (w - this._wallThickness) / 2;
+ const hh = (h + this._wallThickness) / 2;
+ const cx = ((this.board.columnCount - 1) / 2) * constants_2.SPACING;
+ const cy = ((this.board.rowCount - 1) / 2) * constants_2.SPACING;
+ matter_js_2.Body.setPosition(this._top, { x: cx, y: cy - hh });
+ matter_js_2.Body.setPosition(this._bottom, { x: cx, y: cy + hh });
+ matter_js_2.Body.setPosition(this._left, { x: cx - hw, y: cy });
+ matter_js_2.Body.setPosition(this._right, { x: cx + hw, y: cy });
+ const sx = w / this._wallWidth;
+ const sy = h / this._wallHeight;
+ if (sx != 1.0) {
+ matter_js_2.Body.scale(this._top, sx, 1.0);
+ matter_js_2.Body.scale(this._bottom, sx, 1.0);
+ }
+ if (sy != 1.0) {
+ matter_js_2.Body.scale(this._left, 1.0, sy);
+ matter_js_2.Body.scale(this._right, 1.0, sy);
+ }
+ this._wallWidth = w;
+ this._wallHeight = h;
+ }
+ // update the working set of parts to include those that are near balls,
+ // and return whether parts have been added or removed
+ addNeighborParts(force = false) {
+ // track parts to add and remove
+ const addParts = new Set();
+ const removeParts = new Set(this._parts.keys());
+ // update for all balls on the board
+ for (const ball of this.balls) {
+ // get the ball's current location
+ const column = Math.round(ball.column);
+ const row = Math.round(ball.row);
+ // remove balls that drop off the board
+ if (Math.round(row) > this.board.rowCount) {
+ this.board.removeBall(ball);
+ continue;
+ }
+ // don't update for balls in the same locality (unless forced to)
+ if ((!force) && (this._ballNeighbors.has(ball)) &&
+ (ball.lastColumn === column) &&
+ ((ball.lastRow === row) || (ball.lastRow === row + 1))) {
+ removeParts.delete(ball);
+ for (const part of this._ballNeighbors.get(ball)) {
+ removeParts.delete(part);
+ }
+ continue;
+ }
+ // add the ball itself
+ addParts.add(ball);
+ removeParts.delete(ball);
+ // reset the list of neighbors
+ if (!this._ballNeighbors.has(ball)) {
+ this._ballNeighbors.set(ball, new Set());
+ }
+ const neighbors = this._ballNeighbors.get(ball);
+ neighbors.clear();
+ // update the neighborhood of parts around the ball
+ for (let c = -1; c <= 1; c++) {
+ for (let r = -1; r <= 1; r++) {
+ const part = this.board.getPart(column + c, row + r);
+ if (!part)
+ continue;
+ addParts.add(part);
+ removeParts.delete(part);
+ neighbors.add(part);
+ }
+ }
+ // store the last place we updated the ball
+ ball.lastColumn = column;
+ ball.lastRow = row;
+ }
+ // add new parts and remove old ones
+ for (const part of addParts)
+ this.addPart(part);
+ for (const part of removeParts)
+ this.removePart(part);
+ return ((addParts.size > 0) || (removeParts.size > 0));
+ }
+ addPart(part) {
+ if (this._parts.has(part))
+ return; // make it idempotent
+ const partBody = this.partBodyFactory.make(part);
+ this._parts.set(part, partBody);
+ partBody.updateBodyFromPart();
+ partBody.addToWorld(this.engine.world);
+ if (partBody.body)
+ this._bodies.set(partBody.body, partBody);
+ }
+ removePart(part) {
+ if (!this._parts.has(part))
+ return; // make it idempotent
+ const partBody = this._parts.get(part);
+ partBody.removeFromWorld(this.engine.world);
+ this._bodies.delete(partBody.body);
+ this.partBodyFactory.release(partBody);
+ this._parts.delete(part);
+ this._restoreRestingRotation(part);
+ }
+ // restore the rotation of the part if it has one
+ _restoreRestingRotation(part) {
+ if (part.rotation === part.restingRotation)
+ return;
+ // ensure we don't "restore" a gear that's still connected
+ // to a chain that's being simulated
+ if ((part instanceof gearbit_2.Gearbit) && (part.connected)) {
+ for (const gear of part.connected) {
+ if ((gear instanceof gearbit_2.Gearbit) && (this._parts.has(gear)))
+ return;
+ }
+ }
+ if (this.board.speed > 0) {
+ animator_2.Animator.current.animate(part, 'rotation', part.rotation, part.restingRotation, 0.1 / this.board.speed);
+ }
+ }
+ // WIREFRAME PREVIEW ********************************************************
+ get showWireframe() {
+ return (this._wireframe ? true : false);
+ }
+ set showWireframe(v) {
+ if ((v) && (!this._wireframe)) {
+ this._wireframe = new PIXI.Sprite();
+ this._wireframeGraphics = new PIXI.Graphics();
+ this._wireframe.addChild(this._wireframeGraphics);
+ this.board._layers.addChild(this._wireframe);
+ this.onBoardSizeChanged();
+ this.renderWireframe();
+ }
+ else if ((!v) && (this._wireframe)) {
+ this.board._layers.removeChild(this._wireframe);
+ this._wireframe = null;
+ this._wireframeGraphics = null;
+ renderer_3.Renderer.needsUpdate();
+ }
+ }
+ renderWireframe() {
+ if (!this._wireframe)
+ return;
+ // setup
+ const g = this._wireframeGraphics;
+ g.clear();
+ const scale = this.board.spacing / constants_2.SPACING;
+ // draw all constraints
+ var constraints = matter_js_2.Composite.allConstraints(this.engine.world);
+ for (const constraint of constraints) {
+ this._drawConstraint(g, constraint, scale);
+ }
+ // draw all bodies
+ var bodies = matter_js_2.Composite.allBodies(this.engine.world);
+ for (const body of bodies) {
+ this._drawBody(g, body, scale);
+ }
+ renderer_3.Renderer.needsUpdate();
+ }
+ _drawBody(g, body, scale) {
+ if (body.parts.length > 1) {
+ // if the body has more than one part, the first is the convex hull, which
+ // we draw in a different color to distinguish it
+ this._drawVertices(g, body.vertices, 65280 /* WIREFRAME_HULL */, scale);
+ for (let i = 1; i < body.parts.length; i++) {
+ this._drawBody(g, body.parts[i], scale);
+ }
+ }
+ else {
+ this._drawVertices(g, body.vertices, 16711680 /* WIREFRAME */, scale);
+ }
+ }
+ _drawVertices(g, vertices, color, scale) {
+ g.lineStyle(1, color);
+ g.beginFill(color, 0.2 /* WIREFRAME */);
+ // draw the vertices of the body
+ let first = true;
+ for (const vertex of vertices) {
+ if (first) {
+ g.moveTo(vertex.x * scale, vertex.y * scale);
+ first = false;
+ }
+ else {
+ g.lineTo(vertex.x * scale, vertex.y * scale);
+ }
+ }
+ g.closePath();
+ g.endFill();
+ }
+ _drawConstraint(g, c, scale) {
+ if ((!c.pointA) || (!c.pointB))
+ return;
+ g.lineStyle(2, 255 /* WIREFRAME_CONSTRAINT */, 0.5);
+ if (c.bodyA) {
+ g.moveTo((c.bodyA.position.x + c.pointA.x) * scale, (c.bodyA.position.y + c.pointA.y) * scale);
+ }
+ else {
+ g.moveTo(c.pointA.x * scale, c.pointA.y * scale);
+ }
+ if (c.bodyB) {
+ g.lineTo((c.bodyB.position.x + c.pointB.x) * scale, (c.bodyB.position.y + c.pointB.y) * scale);
+ }
+ else {
+ g.lineTo(c.pointB.x * scale, c.pointB.y * scale);
+ }
+ }
+ };
+ exports_22("PhysicalBallRouter", PhysicalBallRouter);
+ }
+ };
+});
+System.register("board/schematic", ["matter-js", "board/constants", "parts/fence", "parts/gearbit"], function (exports_23, context_23) {
+ "use strict";
+ var __moduleName = context_23 && context_23.id;
+ var matter_js_3, constants_3, fence_3, gearbit_3, RAD, DIAM, DIAM_2, FENCE, STEP, EXIT, SchematicBallRouter;
+ return {
+ setters: [
+ function (matter_js_3_1) {
+ matter_js_3 = matter_js_3_1;
+ },
+ function (constants_3_1) {
+ constants_3 = constants_3_1;
+ },
+ function (fence_3_1) {
+ fence_3 = fence_3_1;
+ },
+ function (gearbit_3_1) {
+ gearbit_3 = gearbit_3_1;
+ }
+ ],
+ execute: function () {
+ // compute the ball radius and diameter in grid units
+ RAD = constants_3.BALL_RADIUS / constants_3.SPACING;
+ DIAM = 2 * RAD;
+ // square the diameter for fast distance tests
+ DIAM_2 = DIAM * DIAM;
+ // the thickness of fences in grid units
+ FENCE = 0.125;
+ // the speed at which a ball should move through schematic parts
+ STEP = 1 / constants_3.PART_SIZE;
+ // the offset the schematic router should move toward when routing a ball,
+ // which must be over 0.5 to allow the next part to capture the ball
+ EXIT = 0.51 + RAD;
+ SchematicBallRouter = class SchematicBallRouter {
+ constructor(board) {
+ this.board = board;
+ this._initialBitValue = new WeakMap();
+ this.balls = this.board.balls;
+ }
+ onBoardSizeChanged() { }
+ update(speed, correction) {
+ const iterations = Math.ceil(speed * 8);
+ for (let i = 0; i < iterations; i++) {
+ for (const ball of this.balls) {
+ ball.vx = ball.vy = 0;
+ ball.minX = ball.maxX = ball.maxY = NaN;
+ if (this.routeBall(ball)) {
+ this.board.layoutPart(ball, ball.column, ball.row);
+ }
+ else {
+ this.board.removeBall(ball);
+ }
+ }
+ this.stackBalls();
+ this.moveBalls();
+ this.confineBalls();
+ gearbit_3.GearBase.update();
+ }
+ }
+ moveBalls() {
+ for (const ball of this.balls) {
+ const m = Math.sqrt((ball.vx * ball.vx) + (ball.vy * ball.vy));
+ if (m == 0.0)
+ continue;
+ const d = Math.min(m, STEP);
+ ball.column += (ball.vx * d) / m;
+ ball.row += (ball.vy * d) / m;
+ }
+ }
+ confineBalls() {
+ for (const ball of this.balls) {
+ if ((!isNaN(ball.maxX)) && (ball.column > ball.maxX)) {
+ ball.column = ball.maxX;
+ }
+ if ((!isNaN(ball.minX)) && (ball.column < ball.minX)) {
+ ball.column = ball.minX;
+ }
+ if ((!isNaN(ball.maxY)) && (ball.row > ball.maxY)) {
+ ball.row = ball.maxY;
+ }
+ }
+ }
+ routeBall(ball) {
+ let part;
+ let method;
+ // confine the ball on the sides
+ this.checkSides(ball);
+ // get the part containing the ball's center
+ part = this.board.getPart(Math.round(ball.column), Math.round(ball.row));
+ if ((part) && (method = this.routeMethodForPart(part)) &&
+ (method.call(this, part, ball)))
+ return (true);
+ // get the leading corner of the ball's location if
+ // we know it's moving horizontally
+ if (ball.lastColumn !== ball.column) {
+ const sign = ball.lastColumn < ball.column ? 1 : -1;
+ const c = ball.column + (RAD * sign);
+ const r = ball.row + RAD;
+ // get the part on the grid square containing the leading corner
+ part = this.board.getPart(Math.round(c), Math.round(r));
+ if ((part) && (method = this.routeMethodForPart(part)) &&
+ (method.call(this, part, ball)))
+ return (true);
+ }
+ // if we get here, the ball was not moved, so let it fall
+ this.routeFreefall(ball);
+ if (ball.row > this.board.rowCount + 0.5)
+ return (false);
+ return (true);
+ }
+ checkSides(ball) {
+ const c = Math.round(ball.column);
+ const r = Math.round(ball.row);
+ const left = this.board.getPart(c - 1, r);
+ const center = this.board.getPart(c, r);
+ const right = this.board.getPart(c + 1, r);
+ if (((left) && (left.type == 12 /* SIDE */) && (left.isFlipped)) ||
+ ((center) && (center.type == 12 /* SIDE */) && (!center.isFlipped))) {
+ ball.minX = c - 0.5 + RAD + (FENCE / 2);
+ }
+ if (((right) && (right.type == 12 /* SIDE */) && (!right.isFlipped)) ||
+ ((center) && (center.type == 12 /* SIDE */) && (center.isFlipped))) {
+ ball.maxX = c + 0.5 - RAD - (FENCE / 2);
+ }
+ }
+ routeMethodForPart(part) {
+ if (!part)
+ return (null);
+ switch (part.type) {
+ case 3 /* RAMP */: return (this.routeRamp);
+ case 4 /* CROSSOVER */: return (this.routeCrossover);
+ case 5 /* INTERCEPTOR */: return (this.routeInterceptor);
+ case 6 /* BIT */: // fall-through
+ case 7 /* GEARBIT */: return (this.routeBit);
+ case 12 /* SIDE */: return (this.routeSide);
+ case 13 /* SLOPE */: return (this.routeSlope);
+ case 10 /* DROP */: return (this.routeDrop);
+ case 11 /* TURNSTILE */: return (this.routeTurnstile);
+ default: return (null);
+ }
+ }
+ routeRamp(part, ball) {
+ // if the ball is in the top half of the part, proceed toward the center
+ if (ball.row < part.row)
+ this.approachTarget(ball, part.column, part.row);
+ else {
+ this.approachTarget(ball, part.column + (part.isFlipped ? -EXIT : EXIT), part.row + EXIT);
+ }
+ return (true);
+ }
+ routeCrossover(part, ball) {
+ // if the ball is in the top half of the part, proceed toward the center
+ if (ball.row < part.row)
+ this.approachTarget(ball, part.column, part.row);
+ else if (ball.lastDistinctColumn < ball.column) {
+ this.approachTarget(ball, part.column + EXIT, part.row + EXIT);
+ }
+ else {
+ this.approachTarget(ball, part.column - EXIT, part.row + EXIT);
+ }
+ return (true);
+ }
+ routeInterceptor(part, ball) {
+ ball.minX = part.column - 0.5 + RAD;
+ ball.maxX = part.column + 0.5 - RAD;
+ ball.maxY = part.row + 0.5 - RAD;
+ return (this.routeFreefall(ball));
+ }
+ routeBit(part, ball) {
+ // if the ball is in the top half of the part, proceed toward the center,
+ // rotating the bit as we go
+ if (ball.row < part.row) {
+ this._initialBitValue.set(part, part.bitValue);
+ this.approachTarget(ball, part.column, part.row);
+ }
+ else if (!this._initialBitValue.get(part)) {
+ this.approachTarget(ball, part.column + EXIT, part.row + EXIT);
+ }
+ else {
+ this.approachTarget(ball, part.column - EXIT, part.row + EXIT);
+ }
+ // rotate the part as the ball travels through it
+ let r = (part.row + 0.5) - ball.row;
+ if (!this._initialBitValue.get(part))
+ r = 1.0 - r;
+ part.rotation = r;
+ return (true);
+ }
+ routeSide(part, ball) {
+ // if the ball is contacting the side, push it inward
+ if (part.isFlipped) {
+ ball.maxX = part.column + 0.5 - RAD;
+ }
+ else {
+ ball.minX = part.column - 0.5 + RAD;
+ }
+ return (this.routeFreefall(ball));
+ }
+ routeSlope(part, ball) {
+ if (!(part instanceof fence_3.Slope))
+ return (false);
+ // get the ball's row and column as a percentage of the part area
+ const r = ball.row - (part.row - 0.5);
+ let c = ball.column - (part.column - 0.5);
+ if (part.isFlipped)
+ c = 1 - c;
+ // get the level the ball center should be at at that column
+ const m = part.modulus;
+ const s = part.sequence;
+ const level = ((c + s - FENCE) / m) - RAD;
+ // if the ball is above the slope, allow it to drop
+ if (r + STEP <= level)
+ return (this.routeFreefall(ball));
+ // if the ball is well below the slope, allow it to drop
+ if (r > level + DIAM)
+ return (this.routeFreefall(ball));
+ // the ball is near the fence, so put it on top of the fence
+ ball.maxY = (part.row - 0.5) + level;
+ // get the target column to aim for
+ const sign = part.isFlipped ? -1 : 1;
+ let target = sign * EXIT;
+ // roll toward the exit
+ this.approachTarget(ball, part.column + target, part.row - 0.5 + ((0.5 + (target * sign) + s - FENCE) / m) - RAD);
+ return (true);
+ }
+ routeDrop(part, ball) {
+ if (ball.released) {
+ const sign = part.isFlipped ? -1 : 1;
+ this.approachTarget(ball, part.column + (sign * EXIT), part.row + 0.5 - RAD);
+ }
+ else {
+ const offset = RAD + (FENCE / 2);
+ ball.minX = part.column - 0.5 + offset;
+ ball.maxX = part.column + 0.5 - offset;
+ ball.maxY = part.row + 0.5 - offset;
+ this.routeFreefall(ball);
+ }
+ return (true);
+ }
+ routeTurnstile(part, ball) {
+ // convert to direction and position neutral coordinates for simplicity
+ const sign = part.isFlipped ? -1 : 1;
+ let r = ball.row - part.row;
+ let tc = NaN;
+ let tr = NaN;
+ // lots of magic numbers here because the shape is complicated
+ const pocketR = -0.35;
+ const pocketC = 0.13;
+ if (r < pocketR) {
+ // if another ball is already rotating the turnstile,
+ // stop this one until that one goes through
+ if (part.rotation > 0.1)
+ return (true);
+ tc = pocketC;
+ tr = pocketR;
+ }
+ else if ((part.rotation < 1.0) && (r < pocketC)) {
+ part.rotation += 0.01;
+ const v = matter_js_3.Vector.rotate({ x: pocketC, y: pocketR }, part.angleForRotation(part.rotation) * sign);
+ tc = v.x;
+ tr = v.y;
+ }
+ else {
+ part.rotation = 0.0;
+ tr = 0.28;
+ tc = EXIT;
+ }
+ // if there is a target, convert back into real coordinates and route
+ if ((!isNaN(tc)) && (!isNaN(tr))) {
+ this.approachTarget(ball, part.column + (tc * sign), part.row + tr);
+ }
+ return (true);
+ }
+ routeFreefall(ball) {
+ ball.vy += STEP;
+ return (true);
+ }
+ // move the ball toward the given location
+ approachTarget(ball, c, r) {
+ let v = matter_js_3.Vector.normalise({ x: c - ball.column, y: r - ball.row });
+ ball.vx += v.x * STEP;
+ ball.vy += v.y * STEP;
+ }
+ // BALL STACKING ************************************************************
+ stackBalls() {
+ // group balls into columns containing balls that are on either side
+ const columns = [];
+ const add = (ball, c) => {
+ if ((c < 0) || (c >= this.board.rowCount))
+ return;
+ if (columns[c] === undefined)
+ columns[c] = [];
+ columns[c].push(ball);
+ };
+ for (const ball of this.balls) {
+ const center = Math.round(ball.column);
+ add(ball, center);
+ add(ball, center - 1);
+ add(ball, center + 1);
+ }
+ // sort the balls in each column from bottom to top
+ for (const c in columns) {
+ const column = columns[c];
+ if (!column)
+ continue;
+ column.sort((a, b) => a.row > b.row ? -1 : a.row < b.row ? 1 : 0);
+ this.stackColumn(parseInt(c), column);
+ }
+ }
+ stackColumn(column, balls) {
+ let ball;
+ let r, c, i, j, dc, dr;
+ const collisions = new Set();
+ for (i = 0; i < balls.length; i++) {
+ ball = balls[i];
+ // don't move balls from other columns, they'll be taken care of there
+ if (Math.round(ball.column) !== column)
+ continue;
+ // iterate over balls below this one to find collisions
+ collisions.clear();
+ r = ball.row;
+ c = ball.column;
+ for (j = i - 1; j >= 0; j--) {
+ dc = balls[j].column - c;
+ dr = balls[j].row - r;
+ // if we find a ball more than a diameter below this one,
+ // the rest must be lower
+ if (dr > DIAM)
+ break;
+ if ((dr * dr) + (dc * dc) < DIAM_2) {
+ collisions.add(balls[j]);
+ }
+ }
+ // if there are no collisions, there's nothing to do
+ if (collisions.size == 0)
+ continue;
+ // if the ball is in contact, remove any horizontal motion
+ // applied by the router so far
+ ball.vx = 0;
+ // move away from each other ball
+ for (const b of collisions) {
+ let dx = ball.column - b.column;
+ let dy = ball.row - b.row;
+ const m = Math.sqrt((dx * dx) + (dy * dy));
+ // if two ball are directly on top of eachother, push one of them up
+ if (!(m > 0)) {
+ ball.vy -= (DIAM - STEP);
+ }
+ else {
+ const d = (DIAM - STEP) - m;
+ // add some jitter so balls don't stack up vertically
+ if (dx === 0.0)
+ dx = (Math.random() - 0.5) * STEP * 0.01;
+ if (d > 0) {
+ ball.vx += (dx * d) / m;
+ ball.vy += (dy * d) / m;
+ }
+ }
+ }
+ }
+ }
+ };
+ exports_23("SchematicBallRouter", SchematicBallRouter);
+ }
+ };
+});
+System.register("custom/matrixTransformer", [], function (exports_24, context_24) {
+ "use strict";
+ var __moduleName = context_24 && context_24.id;
+ function arrayEquals(a, b) {
+ return a.every((val, index) => val === b[index]);
+ }
+ var Part, colors, loadImage, transformToMatrix, translateColor, transformArrToMatrix;
+ return {
+ setters: [],
+ execute: function () {
+ (function (Part) {
+ Part[Part["NotValid"] = -100] = "NotValid";
+ Part[Part["Valid"] = 0] = "Valid";
+ Part[Part["GreenLeft"] = 1] = "GreenLeft";
+ Part[Part["GreenRight"] = 2] = "GreenRight";
+ Part[Part["Orange"] = 3] = "Orange";
+ Part[Part["Red"] = 4] = "Red";
+ Part[Part["BlueLeft"] = 5] = "BlueLeft";
+ Part[Part["BlueWheelLeft"] = 7] = "BlueWheelLeft";
+ Part[Part["Black"] = 6] = "Black";
+ Part[Part["BlueWheelRight"] = 8] = "BlueWheelRight";
+ Part[Part["BlueRight"] = 9] = "BlueRight";
+ Part[Part["LightGrey"] = -100] = "LightGrey";
+ Part[Part["DarkGrey"] = -100] = "DarkGrey";
+ })(Part || (Part = {}));
+ colors = {
+ notValid: [32, 32, 32, 254],
+ red: [189, 0, 0, 255],
+ red2: [255, 0, 0, 255],
+ greenRight: [0, 255, 0, 255],
+ greenLeft: [0, 189, 0, 255],
+ orange: [255, 128, 0, 255],
+ blueLeft: [0, 255, 255, 255],
+ blueWheelLeft: [128, 0, 255, 255],
+ black: [0, 0, 0, 255],
+ white: [255, 255, 255, 255],
+ blueWheelRight: [96, 0, 189, 255],
+ blueRight: [0, 189, 189, 255],
+ lightGrey: [128, 128, 128, 254],
+ darkGrey: [96, 96, 96, 254],
+ };
+ loadImage = (path) => {
+ return new Promise((resolve, reject) => {
+ const img = new Image();
+ img.crossOrigin = "Anonymous"; // to avoid CORS if used with Canvas
+ img.src = path;
+ img.onload = () => {
+ resolve(img);
+ };
+ img.onerror = (e) => {
+ reject(e);
+ };
+ });
+ };
+ //Function that transforms the image to matrix (Board -> Matrix Converter)
+ exports_24("transformToMatrix", transformToMatrix = (url) => __awaiter(this, void 0, void 0, function* () {
+ // url is a base64 encoded image
+ let img = yield loadImage(url);
+ let cvs = document.createElement("canvas");
+ cvs.width = 13;
+ cvs.height = 18;
+ const matrix = [];
+ let ctx = cvs.getContext("2d");
+ ctx.drawImage(img, 0, 0);
+ const imageData = ctx.getImageData(0, 0, cvs.width, cvs.height);
+ const pixels = imageData.data;
+ /* pixels is an array containing imgWidth * imgHeight * 4 elemets
+ "* 4" because every pixel has 4 numbers coresponding for its rgba value
+ */
+ const pixelArr = []; // group every 4 pixels (for simplicity)
+ for (let i = 0; i < pixels.length; i += 4) {
+ const pixelGroup = [pixels[i], pixels[i + 1], pixels[i + 2], pixels[i + 3]];
+ pixelArr.push(pixelGroup);
+ }
+ let pixelMatrix = transformArrToMatrix(pixelArr); // transform the array in a matrix
+ // translate the colors into parts
+ for (let i = 2; i < 13; i++) {
+ const row = [];
+ for (let j = 1; j < 12; j++) {
+ row.push(translateColor(pixelMatrix[i][j]));
+ }
+ matrix.push(row);
+ }
+ return matrix;
+ }));
+ translateColor = (color) => {
+ console.log("Ich bin am Anfang.");
+ console.log("Hier ein Pixel");
+ console.log(color);
+ if (arrayEquals(color, colors.notValid)) {
+ return Part.NotValid;
+ }
+ if (arrayEquals(color, colors.red)) {
+ return Part.Red;
+ }
+ if (arrayEquals(color, colors.red2)) {
+ return Part.Red;
+ }
+ if (arrayEquals(color, colors.greenRight)) {
+ return Part.GreenRight;
+ }
+ if (arrayEquals(color, colors.greenLeft)) {
+ return Part.GreenLeft;
+ }
+ if (arrayEquals(color, colors.orange)) {
+ return Part.Orange;
+ }
+ if (arrayEquals(color, colors.blueLeft)) {
+ return Part.BlueLeft;
+ }
+ if (arrayEquals(color, colors.blueWheelLeft)) {
+ return Part.BlueWheelLeft;
+ }
+ if (arrayEquals(color, colors.black)) {
+ return Part.Black;
+ }
+ if (arrayEquals(color, colors.white)) {
+ return Part.Valid;
+ }
+ if (arrayEquals(color, colors.blueWheelRight)) {
+ return Part.BlueWheelRight;
+ }
+ if (arrayEquals(color, colors.blueRight)) {
+ return Part.BlueRight;
+ }
+ if (arrayEquals(color, colors.darkGrey)) {
+ return Part.DarkGrey;
+ }
+ if (arrayEquals(color, colors.lightGrey)) {
+ return Part.LightGrey;
+ }
+ console.log(color);
+ console.log("Ich bin am Ende.");
+ return -100;
+ };
+ transformArrToMatrix = (arr) => {
+ let matrix = [];
+ for (let i = 0; i < 18; i++) {
+ let row = [];
+ for (let j = 0; j < 13; j++) {
+ row.push(arr[i * 13 + j]);
+ }
+ matrix.push(row);
+ }
+ return matrix;
+ };
+ }
+ };
+});
+System.register("board/serializer", ["custom/matrixTransformer", "parts/drop"], function (exports_25, context_25) {
+ "use strict";
+ var __moduleName = context_25 && context_25.id;
+ var matrixTransformer_1, drop_3, URLBoardSerializer;
+ return {
+ setters: [
+ function (matrixTransformer_1_1) {
+ matrixTransformer_1 = matrixTransformer_1_1;
+ },
+ function (drop_3_1) {
+ drop_3 = drop_3_1;
+ }
+ ],
+ execute: function () {
+ URLBoardSerializer = class URLBoardSerializer {
+ constructor(board) {
+ this.board = board;
+ this._uiState = null;
+ this._boardState = null;
+ this._historyState = { source: "URLBoardSerializer" };
+ this._trySaveInterval = NaN;
+ this._restoring = false;
+ }
+ get dataUrl() {
+ return this._boardState;
+ }
+ onBoardStateChanged() {
+ this._uiState = null;
+ this._boardState = null;
+ this.onChange();
+ }
+ onUIStateChanged() {
+ this._uiState = null;
+ this.onChange();
+ }
+ onChange() {
+ if (!isNaN(this._trySaveInterval))
+ clearInterval(this._trySaveInterval);
+ this._trySaveInterval = setInterval(this.save.bind(this), 0.5 /* UPDATE_URL */ * 1000);
+ }
+ save() {
+ // don't save if we're in the process of a restore operation,
+ // the interval will call back again later and restore may be finished
+ if (this._restoring)
+ return;
+ // stop trying to save
+ if (!isNaN(this._trySaveInterval)) {
+ clearInterval(this._trySaveInterval);
+ this._trySaveInterval = NaN;
+ }
+ // regenerate any invalid state
+ if (this._uiState === null)
+ this._uiState = this._writeUIState();
+ if (this._boardState === null)
+ this._boardState = this._writeBoardState();
+ // if we can't update the URL, exit now
+ if (!window.history ||
+ !window.history.replaceState ||
+ !window.history.pushState)
+ return;
+ // compose a hash to use to save state
+ const hash = "#" + this._uiState + "&b=" + this._boardState;
+ // if no hash is set, we need to push state first
+ if (window.location.hash.length == 0) {
+ window.history.pushState(this._historyState, "", hash);
+ }
+ else {
+ window.history.replaceState(this._historyState, "", hash);
+ }
+ }
+ restore(callback) {
+ // if there is no hash, there's nothing to restore
+ console.log("restoring");
+ const hash = window.location.hash.substr(1);
+ if (hash.length == 0) {
+ callback(false);
+ return;
+ }
+ try {
+ this._restoring = true;
+ const [ui, board] = hash.split("&b=", 2);
+ console.log(ui, board);
+ this._readUIState(ui);
+ this._readBoardState(board, callback);
+ }
+ catch (e) {
+ console.warn(e);
+ callback(false);
+ }
+ finally {
+ this._restoring = false;
+ }
+ }
+ download() {
+ return __awaiter(this, void 0, void 0, function* () {
+ console.log("1");
+ const url = this.dataUrl;
+ const matrix = yield matrixTransformer_1.transformToMatrix(url);
+ const res = yield fetch("http://127.0.0.1:8000/TranslationLayer/t2/" + JSON.stringify(matrix), {
+ method: "GET",
+ });
+ console.log(res);
+ console.log(yield matrixTransformer_1.transformToMatrix(url));
+ // if (!(url.length > 0)) return false;
+ // const a = document.createElement("a");
+ // console.log(a);
+ // a.setAttribute("href", url);
+ // a.setAttribute("download", "ttsim.png");
+ // document.body.appendChild(a);
+ // a.click();
+ // document.body.removeChild(a);
+ return true;
+ });
+ }
+ upload(callback) {
+ const input = document.createElement("input");
+ input.setAttribute("type", "file");
+ input.setAttribute("accept", "image/png");
+ input.onchange = () => {
+ if (!(input.files.length > 0))
+ return;
+ const file = input.files[0];
+ var reader = new FileReader();
+ reader.onload = (e) => {
+ this._restoring = true;
+ try {
+ this._readBoardState(e.target.result, callback);
+ }
+ finally {
+ this._restoring = false;
+ }
+ };
+ reader.readAsDataURL(file);
+ };
+ input.click();
+ return false;
+ }
+ _writeUIState() {
+ let s = "";
+ s += "s=" + this.board.columnCount + "," + this.board.rowCount;
+ s += "&z=" + this.board.partSize;
+ s += "&cc=" + Math.round(this.board.centerColumn * 2) / 2;
+ s += "&cr=" + Math.round(this.board.centerRow * 2) / 2;
+ s += "&t=" + this.board.tool;
+ if (this.board.partPrototype) {
+ s += "&pt=" + this.board.partPrototype.type;
+ }
+ s += "&sp=" + this.board.speed;
+ s += "&sc=" + (this.board.schematic ? "1" : "0");
+ return s;
+ }
+ _readUIState(s) {
+ // split the hash into variables and parse them
+ for (const kv of s.split("&")) {
+ const [key, value] = kv.split("=", 2);
+ if (key == "t")
+ this.board.tool = parseInt(value);
+ else if (key == "pt") {
+ this.board.partPrototype = this.board.partFactory.make(parseInt(value));
+ }
+ else if (key == "z")
+ this.board.partSize = parseInt(value);
+ else if (key == "s") {
+ const [c, r] = value.split(",");
+ this.board.setSize(parseInt(c), parseInt(r), false);
+ }
+ else if (key == "cc")
+ this.board.centerColumn = parseFloat(value);
+ else if (key == "cr")
+ this.board.centerRow = parseFloat(value);
+ else if (key == "sp")
+ this.board.speed = parseFloat(value);
+ else if (key == "sc")
+ this.board.schematic = parseInt(value) === 1;
+ }
+ }
+ _writeMetadata() {
+ let items = [];
+ // add metadata about drops
+ for (const drop of this._getSortedDrops()) {
+ items.push("d " + drop.hue + " " + drop.balls.size);
+ }
+ return items.join(" ");
+ }
+ _readMetadata(s) {
+ const drops = this._getSortedDrops();
+ // tokenize the string
+ const tokens = s.split(" ");
+ let token, type, params;
+ while (tokens.length > 0) {
+ token = tokens.shift();
+ if (parseFloat(token).toString() != token) {
+ type = token;
+ params = [];
+ }
+ else {
+ params.push(parseFloat(token));
+ }
+ // read drop metadata
+ if (type == "d" && params.length == 2) {
+ const drop = drops.shift();
+ if (drop) {
+ drop.hue = Math.round(params[0]);
+ this.board.setDropBallCount(drop, Math.floor(params[1]));
+ }
+ }
+ }
+ }
+ _getSortedDrops() {
+ const drops = [];
+ let part;
+ for (let c = 0; c < this.board.columnCount; c++) {
+ for (let r = 0; r < this.board.rowCount; r++) {
+ part = this.board.getPart(c, r);
+ if (part instanceof drop_3.Drop)
+ drops.push(part);
+ }
+ }
+ return drops;
+ }
+ _writeBoardState() {
+ // compose metadata to include with the image
+ let metadata = this._writeMetadata();
+ const metadataBytesPerRow = (this.board.columnCount - 1) * 3;
+ const metadataRows = Math.ceil(metadata.length / metadataBytesPerRow);
+ // make a canvas where grid location on the board is a pixel
+ const canvas = document.createElement("canvas");
+ canvas.width = this.board.columnCount;
+ canvas.height = this.board.rowCount + metadataRows;
+ const ctx = canvas.getContext("2d");
+ const imageData = ctx.createImageData(canvas.width, canvas.height);
+ const rw = canvas.width * 4;
+ // draw pixels representing the parts
+ for (let c = 0; c < this.board.columnCount; c++) {
+ for (let r = 0; r < this.board.rowCount; r++) {
+ const part = this.board.getPart(c, r);
+ this.partToColor(part, imageData.data, r * rw + c * 4);
+ }
+ }
+ // write metadata
+ for (let r = this.board.rowCount; r < canvas.height; r++) {
+ if (!(metadata.length > 0))
+ break;
+ metadata = this.writeMetadataRow(imageData.data, r * rw, canvas.width, metadata);
+ }
+ ctx.putImageData(imageData, 0, 0);
+ return canvas.toDataURL();
+ }
+ _readBoardState(url, callback) {
+ const expectedPrefix = "data:image/png;base64,";
+ const prefix = url.substr(0, expectedPrefix.length);
+ if (prefix !== expectedPrefix) {
+ console.warn("Unexpected data url prefix: " + prefix);
+ callback(false);
+ return;
+ }
+ const img = document.createElement("img");
+ img.onload = () => {
+ const canvas = document.createElement("canvas");
+ const w = img.width;
+ const h = img.height;
+ canvas.width = w;
+ canvas.height = h;
+ const ctx = canvas.getContext("2d");
+ ctx.drawImage(img, 0, 0, w, h);
+ const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
+ let s, metadata = "";
+ // read parts and metadata from the image's pixels
+ this.board.bulkUpdate = true;
+ this.board.setSize(w, 0, false);
+ let r = 0;
+ for (let y = 0; y < h; y++) {
+ // read metadata row
+ s = this.readMetadataRow(imageData.data, y * w * 4, w);
+ if (s !== null) {
+ metadata += s;
+ continue;
+ }
+ // read part row
+ this.board.sizeBottom(1, false);
+ for (let c = 0; c < this.board.columnCount; c++) {
+ const part = this.colorToPart(imageData.data, y * w * 4 + c * 4);
+ if (part)
+ this.board.setPart(part, c, r);
+ else
+ this.board.clearPart(c, r);
+ }
+ r++;
+ }
+ this._readMetadata(metadata);
+ this.board.bulkUpdate = false;
+ callback(true);
+ };
+ img.onerror = () => {
+ callback(false);
+ };
+ img.src = url;
+ }
+ partToColor(part, data, i) {
+ let r = 0xff, g = 0xff, b = 0xff, a = 0xff;
+ let flip = part &&
+ ((part.canFlip && part.isFlipped) || (part.canRotate && part.bitValue));
+ // select a color for the part
+ if (part)
+ switch (part.type) {
+ // leave both types of locations white so we don't get a checker pattern
+ // in the image, which makes editing harder
+ case 1 /* PARTLOC */: // fall-through
+ case 2 /* GEARLOC */:
+ break;
+ // handle parts
+ case 3 /* RAMP */:
+ r = 0x00;
+ g = 0xff;
+ b = 0x00;
+ break; // green
+ case 4 /* CROSSOVER */:
+ r = 0xff;
+ g = 0x80;
+ b = 0x00;
+ break; // orange
+ case 5 /* INTERCEPTOR */:
+ r = 0x00;
+ g = 0x00;
+ b = 0x00;
+ break; // black
+ case 6 /* BIT */:
+ r = 0x00;
+ g = 0xff;
+ b = 0xff;
+ break; // cyan
+ case 7 /* GEARBIT */:
+ r = 0x80;
+ g = 0x00;
+ b = 0xff;
+ break; // purple
+ case 8 /* GEAR */:
+ r = 0xff;
+ g = 0x00;
+ b = 0x00;
+ break; // red
+ case 10 /* DROP */:
+ r = 0xff;
+ g = 0xff;
+ b = 0x00;
+ break; // yellow
+ case 11 /* TURNSTILE */:
+ r = 0xff;
+ g = 0x00;
+ b = 0xff;
+ break; // magenta
+ case 12 /* SIDE */:
+ if (!flip) {
+ r = 0xc0;
+ g = 0xc0;
+ b = 0xc0;
+ } // light gray
+ else {
+ r = 0xa0;
+ g = 0xa0;
+ b = 0xa0;
+ }
+ flip = false;
+ break;
+ case 13 /* SLOPE */:
+ if (!flip) {
+ r = 0x80;
+ g = 0x80;
+ b = 0x80;
+ } // middle gray
+ else {
+ r = 0x60;
+ g = 0x60;
+ b = 0x60;
+ }
+ flip = false;
+ break;
+ // leave blank spots and unknown parts a very dark gray
+ case 0 /* BLANK */: // fall-through
+ default:
+ r = g = b = 0x20;
+ break;
+ }
+ // if a part is flipped or rotated, make the color less bright
+ if (flip) {
+ r = (r >> 2) * 3;
+ g = (g >> 2) * 3;
+ b = (b >> 2) * 3;
+ }
+ // if a part is locked, reduce opacity very slightly
+ if (part && part.isLocked)
+ a = 0xfe;
+ // write the color
+ data[i++] = r;
+ data[i++] = g;
+ data[i++] = b;
+ data[i++] = a;
+ }
+ colorToPart(data, i) {
+ // read the color
+ let r = data[i++];
+ let g = data[i++];
+ let b = data[i++];
+ const a = data[i++];
+ const max = Math.max(r, g, b);
+ // define fudge factors for color recognition so the image can be edited,
+ // and slightly different colors will still be recognized
+ const isLow = (n) => n <= 0.25;
+ const isMid = (n) => n > 0.25 && n < 0.75;
+ const isHigh = (n) => n >= 0.75;
+ // get the part type
+ let type = -1;
+ let flipped = false;
+ if (max == 0)
+ type = 5 /* INTERCEPTOR */;
+ else {
+ r /= max;
+ g /= max;
+ b /= max;
+ // gray
+ if (isHigh(r) && isHigh(g) && isHigh(b)) {
+ if (max >= 0xd0) {
+ } // whiteish, clear the location
+ else if (max >= 0x90) {
+ // light gray
+ type = 12 /* SIDE */;
+ flipped = max < 0xb0; // distinguish between 0xC0 and 0xA0
+ }
+ else if (max >= 0x40) {
+ // dark gray
+ type = 13 /* SLOPE */;
+ flipped = max < 0x70; // distinguish between 0x60 and 0x80
+ }
+ else {
+ // very dark gray, consider blank
+ type = 0 /* BLANK */;
+ }
+ }
+ else {
+ // colors
+ if (isLow(r) && isHigh(g) && isLow(b))
+ type = 3 /* RAMP */;
+ else if (isHigh(r) && isMid(g) && isLow(b))
+ type = 4 /* CROSSOVER */;
+ else if (isLow(r) && isHigh(g) && isHigh(b))
+ type = 6 /* BIT */;
+ else if (isMid(r) && isLow(g) && isHigh(b))
+ type = 7 /* GEARBIT */;
+ else if (isHigh(r) && isLow(g) && isLow(b))
+ type = 8 /* GEAR */;
+ else if (isHigh(r) && isHigh(g) && isLow(b))
+ type = 10 /* DROP */;
+ else if (isHigh(r) && isLow(g) && isHigh(b))
+ type = 11 /* TURNSTILE */; // magenta
+ flipped = max < 0xde;
+ }
+ }
+ if (type >= 0) {
+ const part = this.board.partFactory.make(type);
+ if (a < 0xff)
+ part.isLocked = true;
+ if (flipped) {
+ if (part.canFlip)
+ part.isFlipped = true;
+ else if (part.canRotate)
+ part.rotation = 1;
+ }
+ return part;
+ }
+ return null;
+ }
+ writeMetadataRow(data, i, w, s) {
+ const end = i + w * 4;
+ // write a blue pixel to indicate a metadata row
+ data[i++] = 0x00;
+ data[i++] = 0x00;
+ data[i++] = 0xff;
+ let c = 0;
+ for (; i < end; i++) {
+ if (i % 4 == 3) {
+ // skip alpha
+ data[i] = 0xff;
+ }
+ else if (c >= s.length) {
+ // null termination
+ data[i] = 0;
+ }
+ else {
+ data[i] = s.charCodeAt(c++);
+ }
+ }
+ // return the unwritten string
+ return s.substr(c);
+ }
+ readMetadataRow(data, i, w) {
+ const end = i + w * 4;
+ // a blue pixel at the start represents a metadata row, skip if there isn't one
+ if (data[i++] != 0x00 || data[i++] != 0x00 || data[i++] != 0xff)
+ return null;
+ // build a string from the data in the row
+ let s = "";
+ let c;
+ for (; i < end; i++) {
+ if (i % 4 == 3)
+ continue; // skip alpha
+ c = data[i];
+ if (c == 0)
+ return s; // null termination
+ s += String.fromCharCode(c);
+ }
+ return s;
+ }
+ };
+ exports_25("URLBoardSerializer", URLBoardSerializer);
+ }
+ };
+});
+System.register("board/controls", ["pixi.js", "renderer", "ui/config"], function (exports_26, context_26) {
+ "use strict";
+ var __moduleName = context_26 && context_26.id;
+ var PIXI, renderer_4, config_2, ColorWheel, SpriteWithSize, DropButton, TurnButton, BallCounter;
+ return {
+ setters: [
+ function (PIXI_4) {
+ PIXI = PIXI_4;
+ },
+ function (renderer_4_1) {
+ renderer_4 = renderer_4_1;
+ },
+ function (config_2_1) {
+ config_2 = config_2_1;
+ }
+ ],
+ execute: function () {
+ ColorWheel = class ColorWheel extends PIXI.Sprite {
+ constructor(textures) {
+ super();
+ this.textures = textures;
+ this._hue = 0.0;
+ this._wheel = new PIXI.Sprite(textures['ColorWheel-m']);
+ this._wheel.anchor.set(0.5, 0.5);
+ this.addChild(this._wheel);
+ this._pointer = new PIXI.Sprite(textures['ColorWheel-f']);
+ this._pointer.anchor.set(0.5, 0.5);
+ this.addChild(this._pointer);
+ this.anchor.set(0.5, 0.5);
+ }
+ // the size of the control
+ get size() { return (this._wheel.width); }
+ set size(v) {
+ if (v === this.size)
+ return;
+ this._wheel.width = this._wheel.height = v;
+ this._pointer.width = this._pointer.height = v;
+ renderer_4.Renderer.needsUpdate();
+ }
+ // the hue in degrees
+ get hue() { return (this._hue); }
+ set hue(v) {
+ if (isNaN(v))
+ return;
+ while (v < 0)
+ v += 360;
+ if (v >= 360)
+ v %= 360;
+ if (v === this.hue)
+ return;
+ this._hue = v;
+ this._wheel.rotation = (this._hue / 180) * Math.PI;
+ renderer_4.Renderer.needsUpdate();
+ }
+ };
+ exports_26("ColorWheel", ColorWheel);
+ SpriteWithSize = class SpriteWithSize extends PIXI.Sprite {
+ // the size of the control
+ get size() { return (this.width); }
+ set size(v) {
+ if (v === this.size)
+ return;
+ this.width = this.height = v;
+ renderer_4.Renderer.needsUpdate();
+ }
+ // whether to flip the control horizontally
+ get isFlipped() { return (this.scale.x < 0); }
+ set isFlipped(v) {
+ if (v === this.isFlipped)
+ return;
+ this.scale.x = Math.abs(this.scale.x) * (v ? -1 : 1);
+ renderer_4.Renderer.needsUpdate();
+ }
+ };
+ DropButton = class DropButton extends SpriteWithSize {
+ constructor(textures) {
+ super(textures['DropButton-f']);
+ this.textures = textures;
+ this.anchor.set(0.5, 0.5);
+ }
+ };
+ exports_26("DropButton", DropButton);
+ TurnButton = class TurnButton extends SpriteWithSize {
+ constructor(textures) {
+ super(textures['TurnButton-f']);
+ this.textures = textures;
+ this.anchor.set(0.5, 0.5);
+ }
+ };
+ exports_26("TurnButton", TurnButton);
+ BallCounter = class BallCounter extends PIXI.Sprite {
+ constructor() {
+ super();
+ this._text = new PIXI.Text('0', { fontFamily: 'sans-serif', fontWeight: 'bold', align: 'center',
+ fontSize: 24, fill: config_2.htmlColor(16777215 /* BALL_COUNT */),
+ stroke: '#000000', strokeThickness: 4 });
+ this._text.anchor.set(0.5, 0.5);
+ this.addChild(this._text);
+ }
+ get count() {
+ if (!this.drop)
+ return (0);
+ let count = 0;
+ for (const ball of this.drop.balls) {
+ if ((ball.released) || (ball.row > this.drop.row + 0.5))
+ continue;
+ count++;
+ }
+ return (count);
+ }
+ update() {
+ const oldText = this._text.text;
+ this._text.text = this.count.toString();
+ if (this._text.text !== oldText)
+ renderer_4.Renderer.needsUpdate();
+ }
+ };
+ exports_26("BallCounter", BallCounter);
+ }
+ };
+});
+System.register("ui/keyboard", [], function (exports_27, context_27) {
+ "use strict";
+ var __moduleName = context_27 && context_27.id;
+ function makeKeyHandler(key) {
+ const handler = {
+ key: key,
+ isDown: false,
+ isUp: true,
+ downHandler: (event) => {
+ if (event.key === handler.key) {
+ if ((handler.isUp) && (handler.press))
+ handler.press();
+ handler.isDown = true;
+ handler.isUp = false;
+ event.preventDefault();
+ }
+ },
+ upHandler: (event) => {
+ if (event.key === handler.key) {
+ if ((handler.isDown) && (handler.release))
+ handler.release();
+ handler.isDown = false;
+ handler.isUp = true;
+ event.preventDefault();
+ }
+ }
+ };
+ //Attach event listeners
+ window.addEventListener('keydown', handler.downHandler.bind(handler), false);
+ window.addEventListener('keyup', handler.upHandler.bind(handler), false);
+ return (handler);
+ }
+ exports_27("makeKeyHandler", makeKeyHandler);
+ return {
+ setters: [],
+ execute: function () {
+ }
+ };
+});
+System.register("board/board", ["pixi-filters", "parts/fence", "parts/gearbit", "ui/config", "util/disjoint", "renderer", "parts/ball", "board/constants", "board/physics", "board/schematic", "parts/drop", "board/controls", "ui/animator", "parts/turnstile", "ui/keyboard"], function (exports_28, context_28) {
+ "use strict";
+ var __moduleName = context_28 && context_28.id;
+ var filter, fence_4, gearbit_4, config_3, disjoint_1, renderer_5, ball_4, constants_4, physics_1, schematic_1, drop_4, controls_1, animator_3, turnstile_3, keyboard_1, SPACING_FACTOR, Board;
+ return {
+ setters: [
+ function (filter_1) {
+ filter = filter_1;
+ },
+ function (fence_4_1) {
+ fence_4 = fence_4_1;
+ },
+ function (gearbit_4_1) {
+ gearbit_4 = gearbit_4_1;
+ },
+ function (config_3_1) {
+ config_3 = config_3_1;
+ },
+ function (disjoint_1_1) {
+ disjoint_1 = disjoint_1_1;
+ },
+ function (renderer_5_1) {
+ renderer_5 = renderer_5_1;
+ },
+ function (ball_4_1) {
+ ball_4 = ball_4_1;
+ },
+ function (constants_4_1) {
+ constants_4 = constants_4_1;
+ },
+ function (physics_1_1) {
+ physics_1 = physics_1_1;
+ },
+ function (schematic_1_1) {
+ schematic_1 = schematic_1_1;
+ },
+ function (drop_4_1) {
+ drop_4 = drop_4_1;
+ },
+ function (controls_1_1) {
+ controls_1 = controls_1_1;
+ },
+ function (animator_3_1) {
+ animator_3 = animator_3_1;
+ },
+ function (turnstile_3_1) {
+ turnstile_3 = turnstile_3_1;
+ },
+ function (keyboard_1_1) {
+ keyboard_1 = keyboard_1_1;
+ }
+ ],
+ execute: function () {
+ exports_28("SPACING_FACTOR", SPACING_FACTOR = 1.0625);
+ Board = class Board {
+ constructor(partFactory) {
+ this.partFactory = partFactory;
+ this.view = new PIXI.Sprite();
+ this._layers = new PIXI.Container();
+ // a serializer for the board state
+ this.serializer = null;
+ // the set of balls currently on the board
+ this.balls = new Set();
+ this._changeCounter = 0;
+ this._spriteChangeCounter = 0;
+ this._schematic = false;
+ this._speed = 1.0;
+ // routers to manage the positions of the balls
+ this.physicalRouter = new physics_1.PhysicalBallRouter(this);
+ this.schematicRouter = new schematic_1.SchematicBallRouter(this);
+ this._counter = 0;
+ this._areBallsAtRest = true;
+ this._visibleParts = new Set();
+ this._containers = new Map();
+ this._controls = [];
+ this._partSize = 64;
+ this._width = 0;
+ this._height = 0;
+ this._centerColumn = 0.0;
+ this._centerRow = 0.0;
+ this._columnCount = 0;
+ this._rowCount = 0;
+ // storage for the part grid
+ this._grid = [];
+ this._bulkUpdate = false;
+ this._tool = 3 /* HAND */;
+ this._partPrototype = null;
+ // keep a set of all drops on the board
+ this.drops = new Set();
+ this._ballPositions = new WeakMap();
+ this._bitState = new WeakMap();
+ this._controlKeyDown = false;
+ this._isMouseDown = false;
+ this._dragging = false;
+ this._dragFlippedParts = new Set();
+ this._action = 0 /* PAN */;
+ this._actionResizeDelta = 0;
+ this._bindMouseEvents();
+ this.view.addChild(this._layers);
+ this._initContainers();
+ this._updateDropShadows();
+ this._makeControls();
+ this._bindKeyEvents();
+ }
+ // a counter that increments whenever the board changes
+ get changeCounter() { return (this._changeCounter); }
+ onChange() {
+ this._changeCounter++;
+ this._spriteChangeCounter++;
+ if (this.serializer)
+ this.serializer.onBoardStateChanged();
+ }
+ // register changes to UI state
+ onUIChange() {
+ if (this.serializer)
+ this.serializer.onUIStateChanged();
+ }
+ // whether to show parts in schematic form
+ get schematicView() {
+ return ((this._schematic) || (this.spacing <= this.partSize));
+ }
+ // whether to route parts using the schematic router
+ get schematic() { return (this._schematic); }
+ set schematic(v) {
+ if (v === this._schematic)
+ return;
+ this._schematic = v;
+ this._updateLayerVisibility();
+ // return all balls because their positions will be different in the two
+ // routers and it can cause a lot of jumping and sticking
+ this.returnBalls();
+ this.onUIChange();
+ }
+ // the speed to run the simulator at
+ get speed() { return (this._speed); }
+ set speed(v) {
+ if ((isNaN(v)) || (v == null))
+ return;
+ v = Math.min(Math.max(config_3.Speeds[0], v), config_3.Speeds[config_3.Speeds.length - 1]);
+ if (v === this.speed)
+ return;
+ this._speed = v;
+ this.onUIChange();
+ }
+ // update the board state
+ update(correction) {
+ if (this.schematic)
+ this.schematicRouter.update(this.speed, correction);
+ else
+ this.physicalRouter.update(this.speed, correction);
+ if (++this._counter % 30 == 0) {
+ this._areBallsAtRest = this._checkBallMovement();
+ if (this.areBallsAtRest)
+ this._checkBitRotations();
+ this._counter = 0;
+ }
+ // update sprite visibility if the board changes
+ if (this._spriteChangeCounter !== this._lastSpriteChangeCounter) {
+ this._updateSpriteVisibility();
+ this._lastSpriteChangeCounter = this._spriteChangeCounter;
+ }
+ }
+ // whether all balls on the board have been basically motionless for a bit
+ get areBallsAtRest() { return (this._areBallsAtRest); }
+ // LAYERS *******************************************************************
+ _updateSpriteVisibility() {
+ // get the row/column limits on sprite visibility
+ const cx = this.xForColumn(this.centerColumn);
+ const cy = this.yForRow(this.centerRow);
+ const cMin = Math.floor(this.columnForX(cx - (this.width / 2)));
+ const cMax = Math.ceil(this.columnForX(cx + (this.width / 2)));
+ const rMin = Math.floor(this.rowForY(cy - (this.height / 2)));
+ const rMax = Math.ceil(this.rowForY(cy + (this.height / 2)));
+ // clamp to the limits of the actual grid
+ const cMinGrid = Math.min(Math.max(0, cMin), this.columnCount);
+ const cMaxGrid = Math.min(Math.max(0, cMax), this.columnCount);
+ const rMinGrid = Math.min(Math.max(0, rMin), this.rowCount);
+ const rMaxGrid = Math.min(Math.max(0, rMax), this.rowCount);
+ // make a list of parts we should be showing at this time
+ const visible = new Set();
+ // add parts from the grid
+ let c, r, row, part;
+ for (r = rMinGrid; r < rMaxGrid; r++) {
+ row = this._grid[r];
+ for (c = cMinGrid; c < cMaxGrid; c++) {
+ part = row[c];
+ if (part)
+ visible.add(part);
+ }
+ }
+ // add balls
+ for (const ball of this.balls) {
+ if ((ball.column < cMin) || (ball.column > cMax) ||
+ (ball.row < rMin) || (ball.row > rMax))
+ continue;
+ visible.add(ball);
+ }
+ // add the prototype part if there is one
+ if (this.partPrototype)
+ visible.add(this.partPrototype);
+ // remove sprites for parts that are no longer visible
+ const invisible = new Set();
+ for (const part of this._visibleParts) {
+ if (!visible.has(part))
+ invisible.add(part);
+ }
+ // remove sprites for parts that have become invisible
+ for (const part of invisible) {
+ this._removeSpritesForPart(part);
+ this._visibleParts.delete(part);
+ }
+ // add sprites for parts that have just become visible
+ for (const part of visible) {
+ if (!this._visibleParts.has(part)) {
+ this._addSpritesForPart(part);
+ this._visibleParts.add(part);
+ }
+ }
+ }
+ // add a part to the board's layers
+ _addSpritesForPart(part) {
+ for (let layer of this._containers.keys()) {
+ const sprite = part.getSpriteForLayer(layer);
+ if (!sprite)
+ continue;
+ // in non-schematic mode, add balls behind other parts to prevent ball
+ // highlights from displaying on top of gears, etc.
+ if ((part instanceof ball_4.Ball) && (layer < 4 /* SCHEMATIC */)) {
+ this._containers.get(layer).addChildAt(sprite, 0);
+ }
+ else {
+ // in schematic mode, place other parts behind balls
+ if ((layer >= 4 /* SCHEMATIC */) && (!(part instanceof ball_4.Ball))) {
+ this._containers.get(layer).addChildAt(sprite, 0);
+ }
+ else {
+ this._containers.get(layer).addChild(sprite);
+ }
+ }
+ }
+ renderer_5.Renderer.needsUpdate();
+ }
+ // remove a part from the board's layers
+ _removeSpritesForPart(part) {
+ if (!part)
+ return;
+ for (let layer of this._containers.keys()) {
+ const sprite = part.getSpriteForLayer(layer);
+ if (!sprite)
+ continue;
+ const container = this._containers.get(layer);
+ if (sprite.parent === container)
+ container.removeChild(sprite);
+ }
+ renderer_5.Renderer.needsUpdate();
+ }
+ _initContainers() {
+ this._setContainer(0 /* BACK */, false);
+ this._setContainer(1 /* MID */, false);
+ this._setContainer(2 /* FRONT */, false);
+ this._setContainer(3 /* SCHEMATIC_BACK */, true);
+ this._setContainer(4 /* SCHEMATIC */, true);
+ this._setContainer(6 /* SCHEMATIC_4 */, true);
+ this._setContainer(5 /* SCHEMATIC_2 */, true);
+ this._setContainer(8 /* CONTROL */, false);
+ this._updateLayerVisibility();
+ }
+ _setContainer(layer, highPerformance = false) {
+ const newContainer = this._makeContainer(highPerformance);
+ if (this._containers.has(layer)) {
+ const oldContainer = this._containers.get(layer);
+ this._layers.removeChild(oldContainer);
+ for (const child of oldContainer.children) {
+ newContainer.addChild(child);
+ }
+ }
+ this._containers.set(layer, newContainer);
+ this._layers.addChild(newContainer);
+ }
+ _makeContainer(highPerformance = false) {
+ if (highPerformance)
+ return (new PIXI.particles.ParticleContainer(16384, {
+ vertices: true,
+ position: true,
+ rotation: true,
+ tint: true,
+ alpha: true
+ }, 16384, true));
+ else
+ return (new PIXI.Container());
+ }
+ _updateDropShadows() {
+ this._containers.get(0 /* BACK */).filters = [
+ this._makeShadow(this.partSize / 32.0)
+ ];
+ this._containers.get(1 /* MID */).filters = [
+ this._makeShadow(this.partSize / 16.0)
+ ];
+ this._containers.get(2 /* FRONT */).filters = [
+ this._makeShadow(this.partSize / 8.0)
+ ];
+ this._containers.get(8 /* CONTROL */).filters = [
+ this._makeShadow(8.0)
+ ];
+ }
+ _makeShadow(size) {
+ return (new filter.DropShadowFilter({
+ alpha: 0.35,
+ blur: size * 0.25,
+ color: 0x000000,
+ distance: size,
+ kernels: null,
+ pixelSize: 1,
+ quality: 3,
+ resolution: PIXI.settings.RESOLUTION,
+ rotation: 45,
+ shadowOnly: false
+ }));
+ }
+ _updateFilterAreas() {
+ const tl = this.view.toGlobal(new PIXI.Point(0, 0));
+ const br = this.view.toGlobal(new PIXI.Point(this.width, this.height));
+ const area = new PIXI.Rectangle(tl.x, tl.y, br.x - tl.x, br.y - tl.y);
+ this._containers.get(0 /* BACK */).filterArea = area;
+ this._containers.get(1 /* MID */).filterArea = area;
+ this._containers.get(2 /* FRONT */).filterArea = area;
+ }
+ _updateLayerVisibility() {
+ const showContainer = (layer, show) => {
+ if (this._containers.has(layer))
+ this._containers.get(layer).visible = show;
+ };
+ showContainer(0 /* BACK */, !this.schematicView);
+ showContainer(1 /* MID */, !this.schematicView);
+ showContainer(2 /* FRONT */, !this.schematicView);
+ showContainer(3 /* SCHEMATIC_BACK */, this.schematicView && (this.partSize >= 12));
+ showContainer(4 /* SCHEMATIC */, this.schematicView);
+ showContainer(6 /* SCHEMATIC_4 */, this.schematicView && (this.partSize == 4));
+ showContainer(5 /* SCHEMATIC_2 */, this.schematicView && (this.partSize == 2));
+ let showControls = false;
+ for (const control of this._controls) {
+ if (control.visible) {
+ showControls = true;
+ break;
+ }
+ }
+ showContainer(8 /* CONTROL */, showControls);
+ renderer_5.Renderer.needsUpdate();
+ }
+ // controls
+ _makeControls() {
+ this._ballCounter = new controls_1.BallCounter();
+ this._controls.push(this._ballCounter);
+ this._dropButton = new controls_1.DropButton(this.partFactory.textures);
+ this._controls.push(this._dropButton);
+ this._turnButton = new controls_1.TurnButton(this.partFactory.textures);
+ this._controls.push(this._turnButton);
+ this._colorWheel = new controls_1.ColorWheel(this.partFactory.textures);
+ this._controls.push(this._colorWheel);
+ this._resizeOverlay = new PIXI.Sprite();
+ this._resizeOverlayGraphics = new PIXI.Graphics();
+ this._resizeOverlay.addChild(this._resizeOverlayGraphics);
+ this._controls.push(this._resizeOverlay);
+ const container = this._containers.get(8 /* CONTROL */);
+ for (const control of this._controls) {
+ control.visible = false;
+ container.addChild(control);
+ }
+ }
+ _showControl(control) {
+ if (!control.visible)
+ control.alpha = 0.0;
+ control.visible = true;
+ animator_3.Animator.current.animate(control, 'alpha', 0, 1, 0.1 /* SHOW_CONTROL */);
+ this._updateLayerVisibility();
+ }
+ _hideControl(control) {
+ animator_3.Animator.current.animate(control, 'alpha', 1, 0, 0.25 /* HIDE_CONTROL */, () => {
+ control.visible = false;
+ this._updateLayerVisibility();
+ });
+ }
+ _updateResizeOverlay(active, side, delta) {
+ const x0 = this.xForColumn(-1 - (side == 0 /* LEFT */ ? delta : 0));
+ const y0 = this.yForRow(-1 - (side == 1 /* TOP */ ? delta : 0));
+ const x1 = this.xForColumn(this.columnCount + (side == 2 /* RIGHT */ ? delta : 0));
+ const y1 = this.yForRow(this.rowCount + (side == 3 /* BOTTOM */ ? delta : 0));
+ const g = this._resizeOverlayGraphics;
+ g.clear();
+ g.lineStyle(2, active ? 16755200 /* HIGHLIGHT */ : 8421504 /* RESIZE_HINT */, 0.75);
+ if (active)
+ g.beginFill(16755200 /* HIGHLIGHT */, 0.25);
+ g.drawRect(x0, y0, x1 - x0, y1 - y0);
+ if (active)
+ g.endFill();
+ renderer_5.Renderer.needsUpdate();
+ }
+ // LAYOUT *******************************************************************
+ // change the size to draw parts at
+ get partSize() { return (this._partSize); }
+ set partSize(v) {
+ if ((isNaN(v)) || (v == null))
+ return;
+ v = Math.min(Math.max(config_3.Zooms[0], v), config_3.Zooms[config_3.Zooms.length - 1]);
+ if (v === this._partSize)
+ return;
+ this._partSize = v;
+ this.layoutParts();
+ this._updateDropShadows();
+ this._updateLayerVisibility();
+ this._updatePan();
+ this.physicalRouter.onBoardSizeChanged();
+ this.schematicRouter.onBoardSizeChanged();
+ this.onUIChange();
+ }
+ // the width of the display area
+ get width() { return (this._width); }
+ set width(v) {
+ if (v === this._width)
+ return;
+ this._width = v;
+ this.view.hitArea = new PIXI.Rectangle(0, 0, this._width, this._height);
+ this._updatePan();
+ this._updateFilterAreas();
+ }
+ // the height of the display area
+ get height() { return (this._height); }
+ set height(v) {
+ if (v === this._height)
+ return;
+ this._height = v;
+ this.view.hitArea = new PIXI.Rectangle(0, 0, this._width, this._height);
+ this._updatePan();
+ this._updateFilterAreas();
+ }
+ // the fractional column and row to keep in the center
+ get centerColumn() { return (this._centerColumn); }
+ set centerColumn(v) {
+ if ((isNaN(v)) || (v == null))
+ return;
+ v = Math.min(Math.max(0, v), this.columnCount - 1);
+ if (v === this.centerColumn)
+ return;
+ this._centerColumn = v;
+ this._updatePan();
+ this._spriteChangeCounter++;
+ this.onUIChange();
+ }
+ get centerRow() { return (this._centerRow); }
+ set centerRow(v) {
+ if ((isNaN(v)) || (v == null))
+ return;
+ v = Math.min(Math.max(0, v), this.rowCount - 1);
+ if (v === this.centerRow)
+ return;
+ this._centerRow = v;
+ this._updatePan();
+ this._spriteChangeCounter++;
+ this.onUIChange();
+ }
+ _updatePan() {
+ this._layers.x =
+ Math.round((this.width / 2) - this.xForColumn(this.centerColumn));
+ this._layers.y =
+ Math.round((this.height / 2) - this.yForRow(this.centerRow));
+ this._updateFilterAreas();
+ this._spriteChangeCounter++;
+ renderer_5.Renderer.needsUpdate();
+ }
+ // do layout for one part at the given location
+ layoutPart(part, column, row) {
+ if (!part)
+ return;
+ part.size = this.partSize;
+ part.column = column;
+ part.row = row;
+ part.x = this.xForColumn(column);
+ part.y = this.yForRow(row);
+ this._spriteChangeCounter++;
+ }
+ // do layout for all parts on the grid
+ layoutParts() {
+ let r = 0;
+ for (const row of this._grid) {
+ let c = 0;
+ for (const part of row) {
+ this.layoutPart(part, c, r);
+ c++;
+ }
+ r++;
+ }
+ for (const ball of this.balls) {
+ this.layoutPart(ball, ball.column, ball.row);
+ }
+ }
+ // get the spacing between part centers
+ get spacing() { return (Math.floor(this.partSize * SPACING_FACTOR)); }
+ // get the size of controls overlayed on the parts
+ get controlSize() {
+ return (Math.min(Math.max(16, Math.ceil(this.partSize * 0.75)), 32));
+ }
+ // get the column for the given X coordinate
+ columnForX(x) {
+ return (x / this.spacing);
+ }
+ // get the row for the given X coordinate
+ rowForY(y) {
+ return (y / this.spacing);
+ }
+ // get the X coordinate for the given column index
+ xForColumn(column) {
+ return (Math.round(column * this.spacing));
+ }
+ // get the Y coordinate for the given row index
+ yForRow(row) {
+ return (Math.round(row * this.spacing));
+ }
+ // GRID MANAGEMENT **********************************************************
+ // get the size of the part grid
+ get columnCount() { return (this._columnCount); }
+ get rowCount() { return (this._rowCount); }
+ // suspend expensive operations when updating parts in bulk
+ get bulkUpdate() { return (this._bulkUpdate); }
+ set bulkUpdate(v) {
+ if (v === this._bulkUpdate)
+ return;
+ this._bulkUpdate = v;
+ // when finishing a bulk update, execute deferred tasks
+ if (!v) {
+ this._connectSlopes();
+ this._connectTurnstiles();
+ this._connectGears();
+ // average gear rotations in connected sets
+ for (const row of this._grid) {
+ for (const part of row) {
+ if (part instanceof gearbit_4.GearBase) {
+ part.rotation = part.rotation >= 0.5 ? 1.0 : 0.0;
+ }
+ }
+ }
+ }
+ }
+ sizeRight(delta, addBackground = true) {
+ delta = Math.max(-this.columnCount, delta);
+ if (delta == 0)
+ return;
+ const oldBulkUpdate = this.bulkUpdate;
+ this.bulkUpdate = true;
+ const newColumnCount = this.columnCount + delta;
+ let c, r;
+ if (delta < 0) {
+ r = 0;
+ for (const row of this._grid) {
+ for (c = newColumnCount; c < this.columnCount; c++) {
+ this.setPart(null, c, r);
+ }
+ row.splice(newColumnCount, -delta);
+ r++;
+ }
+ }
+ else {
+ r = 0;
+ for (const row of this._grid) {
+ for (c = this.columnCount; c < newColumnCount; c++) {
+ if (addBackground) {
+ row.push(this.makeBackgroundPart(c, r));
+ }
+ else
+ row.push(null);
+ }
+ r++;
+ }
+ }
+ this._columnCount = newColumnCount;
+ this.bulkUpdate = oldBulkUpdate;
+ this.layoutParts();
+ this.physicalRouter.onBoardSizeChanged();
+ this.schematicRouter.onBoardSizeChanged();
+ this.onChange();
+ }
+ sizeBottom(delta, addBackground = true) {
+ delta = Math.max(-this.rowCount, delta);
+ if (delta == 0)
+ return;
+ const oldBulkUpdate = this.bulkUpdate;
+ this.bulkUpdate = true;
+ const newRowCount = this.rowCount + delta;
+ let c, r;
+ if (delta < 0) {
+ for (r = newRowCount; r < this.rowCount; r++) {
+ for (c = 0; c < this.columnCount; c++) {
+ this.setPart(null, c, r);
+ }
+ }
+ this._grid.splice(newRowCount, -delta);
+ }
+ else {
+ for (r = this.rowCount; r < newRowCount; r++) {
+ const row = [];
+ for (c = 0; c < this.columnCount; c++) {
+ if (addBackground) {
+ row.push(this.makeBackgroundPart(c, r));
+ }
+ else
+ row.push(null);
+ }
+ this._grid.push(row);
+ }
+ }
+ this._rowCount = newRowCount;
+ this.bulkUpdate = oldBulkUpdate;
+ this.layoutParts();
+ this.physicalRouter.onBoardSizeChanged();
+ this.schematicRouter.onBoardSizeChanged();
+ this.onChange();
+ }
+ sizeLeft(delta, addBackground = true) {
+ // we must increase/decrease by even numbers to keep part/gear locations
+ // on the same diagonals
+ if (delta % 2 !== 0)
+ delta += 1;
+ delta = Math.max(-this.columnCount, delta);
+ if (delta == 0)
+ return;
+ const oldBulkUpdate = this.bulkUpdate;
+ this.bulkUpdate = true;
+ const newColumnCount = this.columnCount + delta;
+ let c, r;
+ if (delta < 0) {
+ r = 0;
+ for (const row of this._grid) {
+ for (c = 0; c < Math.abs(delta); c++) {
+ this.setPart(null, c, r);
+ }
+ row.splice(0, Math.abs(delta));
+ r++;
+ }
+ }
+ else {
+ r = 0;
+ for (const row of this._grid) {
+ for (c = delta - 1; c >= 0; c--) {
+ if (addBackground) {
+ row.unshift(this.makeBackgroundPart(c, r));
+ }
+ else
+ row.unshift(null);
+ }
+ r++;
+ }
+ }
+ this._columnCount = newColumnCount;
+ this.centerColumn += delta;
+ this.bulkUpdate = oldBulkUpdate;
+ this.layoutParts();
+ this.physicalRouter.onBoardSizeChanged();
+ this.schematicRouter.onBoardSizeChanged();
+ this.onChange();
+ }
+ sizeTop(delta, addBackground = true) {
+ // we must increase/decrease by even numbers to keep part/gear locations
+ // on the same diagonals
+ if (delta % 2 !== 0)
+ delta += 1;
+ delta = Math.max(-this.rowCount, delta);
+ if (delta == 0)
+ return;
+ const oldBulkUpdate = this.bulkUpdate;
+ this.bulkUpdate = true;
+ const newRowCount = this.rowCount + delta;
+ let c, r, part;
+ if (delta < 0) {
+ for (r = 0; r < Math.abs(delta); r++) {
+ for (c = 0; c < this.columnCount; c++) {
+ this.setPart(null, c, r);
+ }
+ }
+ this._grid.splice(0, Math.abs(delta));
+ }
+ else {
+ for (r = delta - 1; r >= 0; r--) {
+ const row = [];
+ for (c = 0; c < this.columnCount; c++) {
+ if (addBackground) {
+ part = this.makeBackgroundPart(c, r);
+ this.layoutPart(part, c, r);
+ row.push(part);
+ }
+ else
+ row.push(null);
+ }
+ this._grid.unshift(row);
+ }
+ }
+ this._rowCount = newRowCount;
+ this.centerRow += delta;
+ this.bulkUpdate = oldBulkUpdate;
+ this.layoutParts();
+ this.physicalRouter.onBoardSizeChanged();
+ this.schematicRouter.onBoardSizeChanged();
+ this.onChange();
+ }
+ // update the part grid
+ setSize(columnCount, rowCount, addBackground = true) {
+ this.sizeRight(columnCount - this.columnCount, addBackground);
+ this.sizeBottom(rowCount - this.rowCount, addBackground);
+ }
+ // remove everything from the board
+ clear(addBackground = true) {
+ const oldBulkUpdate = this.bulkUpdate;
+ this.bulkUpdate = true;
+ // remove parts
+ let part;
+ for (let r = 0; r < this.rowCount; r++) {
+ for (let c = 0; c < this.columnCount; c++) {
+ part = addBackground ? this.makeBackgroundPart(c, r) : null;
+ this.setPart(part, c, r);
+ }
+ }
+ // remove balls
+ this.clearBalls();
+ this.bulkUpdate = oldBulkUpdate;
+ }
+ // remove balls from the board
+ clearBalls() {
+ for (const ball of this.balls)
+ this.removeBall(ball);
+ }
+ // whether a part can be placed at the given row and column
+ canPlacePart(type, column, row) {
+ if (type == 9 /* BALL */) {
+ return ((row >= 0.0) && (column >= 0.0) &&
+ (row < this.rowCount) && (column < this.columnCount));
+ }
+ if ((column < 0) || (column >= this._columnCount) ||
+ (row < 0) || (row >= this._rowCount))
+ return (false);
+ const oldPart = this.getPart(column, row);
+ if ((oldPart) && (oldPart.isLocked))
+ return (false);
+ else if ((type == 1 /* PARTLOC */) || (type == 2 /* GEARLOC */) ||
+ (type == 8 /* GEAR */) || (type == 13 /* SLOPE */) ||
+ (type == 12 /* SIDE */))
+ return (true);
+ else
+ return ((row + column) % 2 == 0);
+ }
+ // whether the part at the given location can be flipped
+ canFlipPart(column, row) {
+ const part = this.getPart(column, row);
+ return ((part) && (part.canFlip || part.canRotate) && (!part.isLocked));
+ }
+ // whether the part at the given location can be dragged
+ canDragPart(column, row) {
+ const part = this.getPart(column, row);
+ return ((part) && (part.type !== 2 /* GEARLOC */) &&
+ (part.type !== 1 /* PARTLOC */) &&
+ (part.type !== 0 /* BLANK */) &&
+ (!part.isLocked));
+ }
+ // whether the part at the given location is a background part
+ isBackgroundPart(column, row) {
+ const part = this.getPart(column, row);
+ return ((!part) ||
+ (part.type === 1 /* PARTLOC */) ||
+ (part.type === 2 /* GEARLOC */));
+ }
+ // make a background part for the given row and column position
+ makeBackgroundPart(column, row) {
+ return (this.partFactory.make((row + column) % 2 == 0 ?
+ 1 /* PARTLOC */ : 2 /* GEARLOC */));
+ }
+ // set the tool to use when the user clicks
+ get tool() { return (this._tool); }
+ set tool(v) {
+ if (!(v >= 0))
+ return;
+ v = Math.min(Math.max(0 /* MIN */, v), 3 /* MAX */);
+ if (v === this._tool)
+ return;
+ this._tool = v;
+ this.onUIChange();
+ }
+ // set the part used as a prototype for adding parts
+ get partPrototype() { return (this._partPrototype); }
+ set partPrototype(p) {
+ if (p === this._partPrototype)
+ return;
+ if (this._partPrototype) {
+ this._partPrototype.alpha = 1.0;
+ this._partPrototype.visible = true;
+ }
+ this._partPrototype = p;
+ if (this._partPrototype) {
+ // clear the part if the prototype is being pulled off the board
+ if (p instanceof ball_4.Ball)
+ this.removeBall(p);
+ else if (this.getPart(p.column, p.row) === p) {
+ this.clearPart(p.column, p.row);
+ }
+ this._partPrototype.alpha = 0.5 /* PREVIEW_ALPHA */;
+ this._partPrototype.visible = false;
+ }
+ this._spriteChangeCounter++;
+ this.onUIChange();
+ }
+ // get the part at the given coordinates
+ getPart(column, row) {
+ if ((isNaN(column)) || (isNaN(row)) ||
+ (column < 0) || (column >= this._columnCount) ||
+ (row < 0) || (row >= this._rowCount))
+ return (null);
+ return (this._grid[row][column]);
+ }
+ // set the part at the given coordinates
+ setPart(newPart, column, row) {
+ if ((column < 0) || (column >= this._columnCount) ||
+ (row < 0) || (row >= this._rowCount))
+ return;
+ const oldPart = this.getPart(column, row);
+ if (oldPart === newPart)
+ return;
+ this._grid[row][column] = newPart;
+ if (newPart)
+ this.layoutPart(newPart, column, row);
+ // tell gears what kind of location they're on
+ if (newPart instanceof gearbit_4.Gear) {
+ newPart.isOnPartLocation = ((column + row) % 2) == 0;
+ }
+ // update gear connections
+ if ((oldPart instanceof gearbit_4.GearBase) || (newPart instanceof gearbit_4.GearBase)) {
+ // disconnect the old part
+ if (oldPart instanceof gearbit_4.GearBase)
+ oldPart.connected = null;
+ // rebuild connections between gears and gearbits
+ if (!this.bulkUpdate)
+ this._connectGears();
+ // merge the new part's rotation with the connected set
+ if ((newPart instanceof gearbit_4.GearBase) && (newPart.connected)) {
+ let sum = 0.0;
+ for (const part of newPart.connected) {
+ sum += part.rotation;
+ }
+ newPart.rotation = ((sum / newPart.connected.size) >= 0.5) ? 1.0 : 0.0;
+ }
+ }
+ // update fences
+ if ((oldPart instanceof fence_4.Slope) || (newPart instanceof fence_4.Slope)) {
+ if (!this.bulkUpdate)
+ this._connectSlopes();
+ }
+ // maintain our set of drops
+ if ((oldPart instanceof drop_4.Drop) && (oldPart !== this.partPrototype)) {
+ this.drops.delete(oldPart);
+ for (const ball of oldPart.balls) {
+ this.removeBall(ball);
+ }
+ }
+ if (newPart instanceof drop_4.Drop) {
+ this.drops.add(newPart);
+ newPart.onRelease = () => {
+ if ((this._ballCounter.visible) &&
+ (this._ballCounter.drop === newPart))
+ this._ballCounter.update();
+ };
+ }
+ if ((oldPart instanceof drop_4.Drop) || (newPart instanceof drop_4.Drop) ||
+ (oldPart instanceof turnstile_3.Turnstile) || (newPart instanceof turnstile_3.Turnstile)) {
+ if (!this.bulkUpdate)
+ this._connectTurnstiles();
+ }
+ // remove and destroy sprites for the old part to avoid memory leaks
+ if ((oldPart) && (oldPart !== this.partPrototype)) {
+ this._removeSpritesForPart(oldPart);
+ oldPart.destroySprites();
+ }
+ this.onChange();
+ }
+ // flip the part at the given coordinates
+ flipPart(column, row) {
+ const part = this.getPart(column, row);
+ if ((part instanceof fence_4.Slope) || (part instanceof fence_4.Side)) {
+ this._flipFence(column, row);
+ }
+ else if (part)
+ part.flip(0.25 /* FLIP */);
+ this.onChange();
+ }
+ // clear parts from the given coordinates
+ clearPart(column, row) {
+ this.setPart(this.makeBackgroundPart(column, row), column, row);
+ }
+ // add a ball to the board
+ addBall(ball, c, r) {
+ if (!this.balls.has(ball)) {
+ this.balls.add(ball);
+ this.layoutPart(ball, c, r);
+ // assign the ball to a drop if it doesn't have one
+ if (!ball.drop) {
+ let drop = this.catchmentDrop(c, r);
+ if (drop) {
+ ball.released = false;
+ }
+ else {
+ ball.released = true;
+ drop = this.nearestDrop(c, r);
+ }
+ if (drop) {
+ this.drops.add(drop);
+ drop.balls.add(ball);
+ ball.drop = drop;
+ ball.hue = drop.hue;
+ }
+ }
+ // update the ball counter
+ if (this._ballCounter.visible)
+ this._ballCounter.update();
+ this.onChange();
+ }
+ this._spriteChangeCounter++;
+ }
+ // remove a ball from the board
+ removeBall(ball) {
+ if (this.balls.has(ball)) {
+ if (ball.drop)
+ ball.drop.balls.delete(ball);
+ this.balls.delete(ball);
+ // update the ball counter
+ if (this._ballCounter.visible)
+ this._ballCounter.update();
+ renderer_5.Renderer.needsUpdate();
+ this.onChange();
+ }
+ }
+ // add a ball to the given drop without returning all balls to it
+ addBallToDrop(drop) {
+ // get the highest ball associated with the drop
+ let topBall;
+ for (const ball of drop.balls) {
+ if ((!topBall) || (ball.row < topBall.row)) {
+ topBall = ball;
+ }
+ }
+ // get the fraction of a grid unit a ball's radius takes up
+ const radius = constants_4.BALL_RADIUS / constants_4.SPACING;
+ let c = drop.column;
+ let r = drop.row;
+ // if the highest ball is on or above the drop, add the new ball above it
+ if ((topBall) && (topBall.row <= drop.row + (0.5 - radius))) {
+ c = topBall.column;
+ r = topBall.row - (2 * radius);
+ }
+ this.addBall(this.partFactory.make(9 /* BALL */), c, Math.max(-0.5, r));
+ }
+ // fill the drop with the given number of balls, adjusting its total count
+ setDropBallCount(drop, count = drop.balls.size) {
+ // turn off bulk updating so we can make sure slopes are configured properly
+ const oldBulkUpdate = this.bulkUpdate;
+ this.bulkUpdate = false;
+ // remove all existing balls (we'll create new ones)
+ for (const ball of drop.balls) {
+ this.removeBall(ball);
+ }
+ // dividing each grid square into thirds, make a list of all open locations
+ const spots = [];
+ // find all grid locations that drain into the drop
+ let part, x, y, t;
+ for (let r = drop.row; r >= -1; r--) {
+ for (let c = 0; c < this.columnCount; c++) {
+ if (this.catchmentDrop(c, r) !== drop)
+ continue;
+ // add up to 9 locations for each grid unit
+ part = this.getPart(c, r);
+ t = part ? part.type : 0 /* BLANK */;
+ if ((t == 0 /* BLANK */) || (t == 10 /* DROP */) ||
+ (t == 12 /* SIDE */) || (t == 1 /* PARTLOC */) ||
+ (t == 2 /* GEARLOC */)) {
+ for (x = -1; x <= 1; x++) {
+ for (y = -1; y <= 1; y++) {
+ // leave room for the pins on part/gear locations
+ if ((x == 0) && (y == 0) && (!this.schematic) &&
+ ((t == 2 /* GEARLOC */) || (t == 1 /* PARTLOC */))) {
+ continue;
+ }
+ spots.push({ c: c + (x / 3), r: r + (y / 3) });
+ }
+ }
+ }
+ else if (part instanceof fence_4.Slope) {
+ const left = part.sequence / part.modulus;
+ const right = (part.sequence + 1) / part.modulus;
+ const sign = part.isFlipped ? -1 : 1;
+ for (x = -1; x <= 1; x++) {
+ const bottom = ((right + left) / 2) +
+ ((x / 3) * sign * (right - left)) - 0.5 - (1 / 6);
+ for (y = -1; y <= 1; y++) {
+ if ((y / 3) > bottom)
+ continue;
+ spots.push({ c: c + (x / 3), r: r + (y / 3) });
+ }
+ }
+ }
+ }
+ }
+ // sort all the spots from bottom to top and center to edge
+ spots.sort((a, b) => {
+ if (a.r > b.r)
+ return (-1);
+ if (a.r < b.r)
+ return (1);
+ if (Math.abs(a.c - drop.column) < Math.abs(b.c - drop.column))
+ return (-1);
+ if (Math.abs(a.c - drop.column) > Math.abs(b.c - drop.column))
+ return (1);
+ return (0);
+ });
+ // place balls in the spots
+ for (let i = 0; i < count; i++) {
+ const spot = spots[i % spots.length]; // re-use spots if we run out
+ this.addBall(this.partFactory.make(9 /* BALL */), spot.c, spot.r);
+ }
+ this.bulkUpdate = oldBulkUpdate;
+ }
+ // return all balls to their appropriate drops
+ returnBalls() {
+ for (const drop of this.drops) {
+ this.setDropBallCount(drop);
+ }
+ }
+ // get the ball under the given point in fractional column/row units
+ ballUnder(column, row) {
+ const radius = (constants_4.BALL_RADIUS / constants_4.SPACING) * 1.2;
+ let closest = null;
+ let minDistance = Infinity;
+ for (const ball of this.balls) {
+ const dx = Math.abs(column - ball.column);
+ const dy = Math.abs(row - ball.row);
+ if ((dx > radius) || (dy > radius))
+ continue;
+ const d = Math.sqrt((dx * dx) + (dy * dy));
+ if (d < minDistance) {
+ closest = ball;
+ minDistance = d;
+ }
+ }
+ return (closest);
+ }
+ // return the drop that would definitely collect a ball dropped at the given
+ // location, or null if it won't definitely reach one
+ catchmentDrop(c, r) {
+ c = Math.round(c);
+ r = Math.max(0, Math.round(r));
+ let lc = c; // the last column the ball was in
+ while ((r < this.rowCount) && (c >= 0) && (c < this.columnCount)) {
+ const p = this.getPart(c, r);
+ // don't go off the board
+ if (!p)
+ break;
+ // if we hit a drop we're done
+ if (p instanceof drop_4.Drop)
+ return (p);
+ else if (p.type == 13 /* SLOPE */) {
+ c += p.isFlipped ? -1 : 1;
+ }
+ else if (p.type == 3 /* RAMP */) {
+ c += p.isFlipped ? -1 : 1;
+ r++;
+ }
+ else if (p.type == 4 /* CROSSOVER */) {
+ if (lc < c) {
+ c++;
+ r++;
+ }
+ else if (lc > c) {
+ c--;
+ r++;
+ }
+ else
+ break; // a vertical drop onto a crossover is non-deterministic
+ }
+ else if (p.type == 5 /* INTERCEPTOR */)
+ break;
+ else if ((p.type == 6 /* BIT */) || (p.type == 7 /* GEARBIT */))
+ break;
+ else
+ r++;
+ lc = c;
+ }
+ return (null);
+ }
+ // return the drop that's closest to the given location
+ nearestDrop(c, r) {
+ let nearest = null;
+ let minDistance = Infinity;
+ for (const drop of this.drops) {
+ const d = Math.pow(c - drop.column, 2) + Math.pow(r - drop.row, 2);
+ if (d < minDistance) {
+ minDistance = d;
+ nearest = drop;
+ }
+ }
+ return (nearest);
+ }
+ // connect adjacent sets of gears
+ // see: https://en.wikipedia.org/wiki/Connected-component_labeling
+ _connectGears() {
+ let r;
+ let c;
+ let label = 0;
+ let min, max;
+ let westPart, westLabel;
+ let northPart, northLabel;
+ let allGears = new Set();
+ for (const row of this._grid) {
+ for (const part of row) {
+ if (part instanceof gearbit_4.GearBase)
+ allGears.add(part);
+ }
+ }
+ let equivalence = new disjoint_1.DisjointSet(allGears.size);
+ r = 0;
+ for (const row of this._grid) {
+ c = 0;
+ westPart = null;
+ for (const part of row) {
+ northPart = r > 0 ? this.getPart(c, r - 1) : null;
+ if (part instanceof gearbit_4.GearBase) {
+ northLabel = (northPart instanceof gearbit_4.GearBase) ?
+ northPart._connectionLabel : -1;
+ westLabel = (westPart instanceof gearbit_4.GearBase) ?
+ westPart._connectionLabel : -1;
+ if ((northLabel >= 0) && (westLabel >= 0)) {
+ if (northLabel === westLabel) {
+ part._connectionLabel = northLabel;
+ }
+ else {
+ min = Math.min(northLabel, westLabel);
+ max = Math.max(northLabel, westLabel);
+ part._connectionLabel = min;
+ equivalence.mergeSets(min, max);
+ }
+ }
+ else if (northLabel >= 0) {
+ part._connectionLabel = northLabel;
+ }
+ else if (westLabel >= 0) {
+ part._connectionLabel = westLabel;
+ }
+ else
+ part._connectionLabel = label++;
+ }
+ westPart = part;
+ c++;
+ }
+ r++;
+ }
+ // group labeled gears into sets
+ const sets = new Map();
+ for (const part of allGears) {
+ label = equivalence.getRepr(part._connectionLabel);
+ if (!sets.has(label))
+ sets.set(label, new Set());
+ const set = sets.get(label);
+ set.add(part);
+ part.connected = set;
+ }
+ }
+ // connect turnstiles to their nearest drops
+ _connectTurnstiles() {
+ for (const row of this._grid) {
+ for (const part of row) {
+ if (part instanceof turnstile_3.Turnstile) {
+ part.drop = this.nearestDrop(part.column, part.row);
+ }
+ }
+ }
+ }
+ // configure slope angles by grouping adjacent ones
+ _connectSlopes() {
+ let slopes = [];
+ for (const row of this._grid) {
+ for (const part of row) {
+ if (part instanceof fence_4.Slope) {
+ if ((slopes.length > 0) &&
+ (slopes[0].isFlipped !== part.isFlipped)) {
+ this._makeSlope(slopes);
+ }
+ slopes.push(part);
+ }
+ else if (slopes.length > 0) {
+ this._makeSlope(slopes);
+ }
+ }
+ if (slopes.length > 0) {
+ this._makeSlope(slopes);
+ }
+ }
+ }
+ // configure a horizontal run of fence parts
+ _makeSlope(slopes) {
+ if (!(slopes.length > 0))
+ return;
+ for (let i = 0; i < slopes.length; i++) {
+ slopes[i].modulus = slopes.length;
+ slopes[i].sequence = slopes[i].isFlipped ?
+ ((slopes.length - 1) - i) : i;
+ }
+ slopes.splice(0, slopes.length);
+ }
+ // flip a fence part
+ _flipFence(column, row) {
+ const part = this.getPart(column, row);
+ if ((!(part instanceof fence_4.Slope)) && (!(part instanceof fence_4.Side)))
+ return;
+ const wasFlipped = part.isFlipped;
+ const type = part.type;
+ part.flip();
+ // make a test function to shorten the code below
+ const shouldContinue = (part) => {
+ if ((part.isFlipped == wasFlipped) && (part.type == type)) {
+ part.flip();
+ return (true);
+ }
+ return (false);
+ };
+ if (part instanceof fence_4.Slope) {
+ // go right
+ for (let c = column + 1; c < this._columnCount; c++) {
+ if (!shouldContinue(this.getPart(c, row)))
+ break;
+ }
+ // go left
+ for (let c = column - 1; c >= 0; c--) {
+ if (!shouldContinue(this.getPart(c, row)))
+ break;
+ }
+ }
+ else if (part instanceof fence_4.Side) {
+ // go down
+ for (let r = row + 1; r < this._rowCount; r++) {
+ if (!shouldContinue(this.getPart(column, r)))
+ break;
+ }
+ // go up
+ for (let r = row - 1; r >= 0; r--) {
+ if (!shouldContinue(this.getPart(column, r)))
+ break;
+ }
+ }
+ // update sequence numbers for slopes
+ this._connectSlopes();
+ }
+ // return whether all balls appear to be at rest since the last check
+ _checkBallMovement() {
+ let atRest = true;
+ let p;
+ for (const ball of this.balls) {
+ if (!this._ballPositions.has(ball)) {
+ atRest = false;
+ this._ballPositions.set(ball, { c: ball.column, r: ball.row });
+ }
+ else {
+ p = this._ballPositions.get(ball);
+ if ((atRest) &&
+ (Math.max(Math.abs(p.c - ball.column), Math.abs(p.r - ball.row)) > 0.05)) {
+ atRest = false;
+ }
+ p.c = ball.column;
+ p.r = ball.row;
+ }
+ }
+ return (atRest);
+ }
+ // see if any bits or gearbits have changed their rotation states from
+ // interaction with balls, and notify if so
+ _checkBitRotations() {
+ let changed = false;
+ for (const row of this._grid) {
+ for (const part of row) {
+ if (!part)
+ continue;
+ if ((part.type !== 6 /* BIT */) &&
+ (part.type !== 7 /* GEARBIT */))
+ continue;
+ if (this._bitState.get(part) !== part.bitValue) {
+ changed = true;
+ this._bitState.set(part, part.bitValue);
+ }
+ }
+ }
+ if (changed)
+ this.onChange();
+ }
+ // INTERACTION **************************************************************
+ _bindMouseEvents() {
+ this.view.interactive = true;
+ this.view.addListener('mousedown', this._onMouseDown.bind(this));
+ this.view.addListener('mousemove', this._onMouseMove.bind(this));
+ this.view.addListener('mouseup', this._onMouseUp.bind(this));
+ this.view.addListener('click', this._onClick.bind(this));
+ this.view.addListener('touchstart', this._onMouseDown.bind(this));
+ this.view.addListener('touchmove', this._onMouseMove.bind(this));
+ this.view.addListener('touchend', this._onMouseUp.bind(this));
+ this.view.addListener('tap', this._onClick.bind(this));
+ }
+ _bindKeyEvents() {
+ const ctrl = keyboard_1.makeKeyHandler('Control');
+ ctrl.press = () => {
+ this._controlKeyDown = true;
+ if (!this._dragging)
+ this._updateAction();
+ };
+ ctrl.release = () => {
+ this._controlKeyDown = false;
+ if (!this._dragging)
+ this._updateAction();
+ };
+ }
+ _onMouseDown(e) {
+ this._updateAction(e);
+ this._isMouseDown = true;
+ this._mouseDownPoint = e.data.getLocalPosition(this.view);
+ }
+ _onMouseMove(e) {
+ // start dragging if the mouse moves more than the threshold
+ const p = e.data.getLocalPosition(this.view);
+ // cancel dragging if the button has been released elsewhere
+ if ((this._isMouseDown) && (e.data.buttons === 0)) {
+ this._onMouseUp(e);
+ }
+ if ((this._isMouseDown) && (!this._dragging) &&
+ ((Math.abs(p.x - this._mouseDownPoint.x) >= 5 /* DRAG_THRESHOLD */) ||
+ (Math.abs(p.y - this._mouseDownPoint.y) >= 5 /* DRAG_THRESHOLD */))) {
+ this._dragging = true;
+ this._lastMousePoint = this._mouseDownPoint;
+ this._onDragStart(this._mouseDownPoint.x, this._mouseDownPoint.y);
+ }
+ // handle dragging
+ if (this._dragging) {
+ this._onDrag(this._mouseDownPoint.x, this._mouseDownPoint.y, this._lastMousePoint.x, this._lastMousePoint.y, p.x, p.y);
+ }
+ else
+ this._updateAction(e);
+ // store this point for the next time
+ this._lastMousePoint = p;
+ }
+ _onMouseUp(e) {
+ this._isMouseDown = false;
+ if (this._dragging) {
+ this._dragging = false;
+ this._onDragFinish();
+ // don't trigger a click
+ e.stopPropagation();
+ }
+ this._updateAction(e);
+ }
+ _onDragStart(x, y) {
+ this._panStartColumn = this.centerColumn;
+ this._panStartRow = this.centerRow;
+ if ((this._action === 4 /* FLIP_PART */) &&
+ (this.canDragPart(this._actionColumn, this._actionRow))) {
+ this._action = 5 /* DRAG_PART */;
+ }
+ if ((this._action === 5 /* DRAG_PART */) && (this._actionPart)) {
+ this.partPrototype = this._actionPart;
+ this._action = 5 /* DRAG_PART */;
+ this._partDragStartColumn = this._actionColumn;
+ this._partDragStartRow = this._actionRow;
+ this.view.cursor = 'grabbing';
+ }
+ if ((this._action === 7 /* DROP_BALL */) &&
+ (this._actionPart instanceof drop_4.Drop)) {
+ this._colorWheel.x = this._actionPart.x;
+ this._colorWheel.y = this._actionPart.y;
+ this._colorWheel.hue = this._actionPart.hue;
+ this._actionHue = this._actionPart.hue;
+ this._showControl(this._colorWheel);
+ this._colorWheel.size = this.controlSize;
+ animator_3.Animator.current.animate(this._colorWheel, 'size', this.controlSize, 64, 0.1 /* SHOW_CONTROL */);
+ this._action = 6 /* COLOR_WHEEL */;
+ this.view.cursor = 'grabbing';
+ }
+ if (this.view.cursor === 'grab')
+ this.view.cursor = 'grabbing';
+ }
+ _onDrag(startX, startY, lastX, lastY, currentX, currentY) {
+ const deltaColumn = this.columnForX(currentX) - this.columnForX(startX);
+ const deltaRow = this.rowForY(currentY) - this.rowForY(startY);
+ const column = Math.round(this._actionColumn + deltaColumn);
+ const row = Math.round(this._actionRow + deltaRow);
+ if (this._action === 0 /* PAN */) {
+ this.centerColumn = this._panStartColumn - deltaColumn;
+ this.centerRow = this._panStartRow - deltaRow;
+ }
+ else if ((this._action === 1 /* PLACE_PART */) &&
+ (this.partPrototype)) {
+ if (this.canPlacePart(this.partPrototype.type, column, row)) {
+ const oldPart = this.getPart(column, row);
+ if ((!(oldPart.hasSameStateAs(this.partPrototype))) &&
+ (!((oldPart.type == 7 /* GEARBIT */) &&
+ (this.partPrototype.type == 8 /* GEAR */)))) {
+ this.setPart(this.partFactory.copy(this.partPrototype), column, row);
+ }
+ }
+ }
+ else if (this._action === 3 /* CLEAR_PART */) {
+ if (!this.isBackgroundPart(column, row)) {
+ // don't clear locked parts when dragging, as it's less likely
+ // to be intentional than with a click
+ const oldPart = this.getPart(column, row);
+ if (!oldPart.isLocked)
+ this.clearPart(column, row);
+ }
+ }
+ else if (this._action === 4 /* FLIP_PART */) {
+ const part = this.getPart(column, row);
+ if ((part) && (!part.isLocked) &&
+ (!this._dragFlippedParts.has(part))) {
+ this.flipPart(column, row);
+ this._dragFlippedParts.add(part);
+ }
+ }
+ else if (this._action === 5 /* DRAG_PART */) {
+ this._actionX += currentX - lastX;
+ this._actionY += currentY - lastY;
+ this._actionColumn = Math.round(this.columnForX(this._actionX));
+ this._actionRow = Math.round(this.rowForY(this._actionY));
+ this._updatePreview();
+ }
+ else if (this._action === 6 /* COLOR_WHEEL */) {
+ const dx = Math.abs(currentX - startX);
+ const dy = Math.abs(currentY - startY);
+ const r = Math.sqrt((dx * dx) + (dy * dy));
+ const f = Math.min(r / 20, 1.0);
+ const radians = Math.atan2(currentY - startY, currentX - startX);
+ this._colorWheel.hue = this._actionHue +
+ (f * (((radians * 180) / Math.PI) - 90));
+ if (this._actionPart instanceof drop_4.Drop) {
+ this._actionPart.hue = this._colorWheel.hue;
+ }
+ }
+ else if (this._action === 9 /* RESIZE_BOARD */) {
+ let delta = 0;
+ if (this._actionSide == 0 /* LEFT */) {
+ delta = Math.round(this.columnForX(startX - currentX));
+ if (delta % 2 != 0)
+ delta += 1;
+ delta = Math.max(delta, (-this.columnCount) + 2);
+ }
+ else if (this._actionSide == 1 /* TOP */) {
+ delta = Math.round(this.rowForY(startY - currentY));
+ if (delta % 2 != 0)
+ delta += 1;
+ delta = Math.max(delta, (-this.rowCount + 2));
+ }
+ else if (this._actionSide == 2 /* RIGHT */) {
+ delta = Math.round(this.columnForX(currentX - startX));
+ delta = Math.max(delta, (-this.columnCount) + 2);
+ }
+ else if (this._actionSide == 3 /* BOTTOM */) {
+ delta = Math.round(this.rowForY(currentY - startY));
+ delta = Math.max(delta, (-this.rowCount) + 2);
+ }
+ this._actionResizeDelta = delta;
+ this._updateResizeOverlay(true, this._actionSide, delta);
+ }
+ }
+ _onDragFinish() {
+ this._dragFlippedParts.clear();
+ if ((this._action === 5 /* DRAG_PART */) && (this.partPrototype)) {
+ // don't copy drops since we want to keep their associations
+ const part = this.partPrototype instanceof drop_4.Drop ? this.partPrototype :
+ this.partFactory.copy(this.partPrototype);
+ this.partPrototype = null;
+ if (part instanceof ball_4.Ball) {
+ this.addBall(part, this.columnForX(this._actionX), this.rowForY(this._actionY));
+ }
+ else if (this.canPlacePart(part.type, this._actionColumn, this._actionRow)) {
+ this.setPart(part, this._actionColumn, this._actionRow);
+ }
+ else {
+ this.setPart(part, this._partDragStartColumn, this._partDragStartRow);
+ }
+ }
+ if (this._action === 6 /* COLOR_WHEEL */) {
+ animator_3.Animator.current.animate(this._colorWheel, 'size', 64, this.controlSize, 0.25 /* HIDE_CONTROL */);
+ this._hideControl(this._colorWheel);
+ }
+ if (this._action === 9 /* RESIZE_BOARD */) {
+ if (this._actionSide == 0 /* LEFT */)
+ this.sizeLeft(this._actionResizeDelta, true);
+ if (this._actionSide == 1 /* TOP */)
+ this.sizeTop(this._actionResizeDelta, true);
+ if (this._actionSide == 2 /* RIGHT */)
+ this.sizeRight(this._actionResizeDelta, true);
+ if (this._actionSide == 3 /* BOTTOM */)
+ this.sizeBottom(this._actionResizeDelta, true);
+ this._updateResizeOverlay(false, this._actionSide, 0);
+ }
+ }
+ _updateAction(e) {
+ let cursor = 'auto';
+ let c, r, column, row;
+ if (e) {
+ const p = e.data.getLocalPosition(this._layers);
+ this._actionX = p.x;
+ this._actionY = p.y;
+ c = this.columnForX(p.x);
+ r = this.rowForY(p.y);
+ column = this._actionColumn = Math.round(c);
+ row = this._actionRow = Math.round(r);
+ }
+ else {
+ c = this.columnForX(this._actionX);
+ r = this.rowForY(this._actionY);
+ column = this._actionColumn;
+ row = this._actionRow;
+ }
+ const oldActionPart = this._actionPart;
+ this._actionPart = this.getPart(column, row);
+ let ball;
+ if (this._controlKeyDown) {
+ this._action = 0 /* PAN */;
+ cursor = 'all-scroll';
+ }
+ else if ((this.tool == 1 /* PART */) && (this.partPrototype) &&
+ ((this.canPlacePart(this.partPrototype.type, column, row)) ||
+ ((row == -1) && (column >= 0) && (column < this.columnCount)))) {
+ this._action = this.partPrototype.type == 9 /* BALL */ ?
+ 2 /* PLACE_BALL */ : 1 /* PLACE_PART */;
+ cursor = 'pointer';
+ }
+ else if (this.tool == 2 /* ERASER */) {
+ this._action = 3 /* CLEAR_PART */;
+ cursor = 'pointer';
+ }
+ else if ((this.tool == 3 /* HAND */) &&
+ (this._actionPart instanceof drop_4.Drop) &&
+ (Math.abs(this._actionX - this._actionPart.x) <= this.controlSize / 2) &&
+ (Math.abs(this._actionY - this._actionPart.y) <= this.controlSize / 2)) {
+ this._action = 7 /* DROP_BALL */;
+ cursor = 'pointer';
+ }
+ else if ((this.tool == 3 /* HAND */) &&
+ (this._actionPart instanceof turnstile_3.Turnstile) &&
+ (Math.abs(this._actionX - this._actionPart.x) <= this.controlSize / 2) &&
+ (Math.abs(this._actionY - this._actionPart.y) <= this.controlSize / 2)) {
+ this._action = 8 /* TURN_TURNSTILE */;
+ cursor = 'pointer';
+ }
+ else if ((this.tool == 3 /* HAND */) &&
+ (ball = this.ballUnder(c, r))) {
+ this._action = 5 /* DRAG_PART */;
+ this._actionPart = ball;
+ cursor = 'grab';
+ }
+ else if ((this.tool == 3 /* HAND */) &&
+ (this.canFlipPart(column, row))) {
+ this._action = 4 /* FLIP_PART */;
+ cursor = 'pointer';
+ }
+ else if ((this.tool == 3 /* HAND */) &&
+ (this.canDragPart(column, row))) {
+ this._action = 5 /* DRAG_PART */;
+ cursor = 'grab';
+ }
+ else if ((this.tool == 3 /* HAND */) &&
+ (this._actionRow >= 0) && (this._actionRow < this.rowCount) &&
+ ((Math.abs(this._actionX - this.xForColumn(-1)) < 16 /* RESIZE_THRESHOLD */) ||
+ (Math.abs(this._actionX - this.xForColumn(this.columnCount)) < 16 /* RESIZE_THRESHOLD */))) {
+ this._action = 9 /* RESIZE_BOARD */;
+ this._actionSide = this._actionColumn < (this.columnCount / 2) ?
+ 0 /* LEFT */ : 2 /* RIGHT */;
+ this._actionResizeDelta = 0;
+ cursor = 'ew-resize';
+ }
+ else if ((this.tool == 3 /* HAND */) &&
+ (this._actionColumn >= 0) && (this._actionColumn < this.columnCount) &&
+ ((Math.abs(this._actionY - this.yForRow(-1)) < 16 /* RESIZE_THRESHOLD */) ||
+ (Math.abs(this._actionY - this.yForRow(this.rowCount)) < 16 /* RESIZE_THRESHOLD */))) {
+ this._action = 9 /* RESIZE_BOARD */;
+ this._actionSide = this._actionRow < (this.rowCount / 2) ?
+ 1 /* TOP */ : 3 /* BOTTOM */;
+ this._actionResizeDelta = 0;
+ cursor = 'ns-resize';
+ }
+ else {
+ this._action = 0 /* PAN */;
+ this._actionPart = null;
+ cursor = 'auto';
+ }
+ this.view.cursor = cursor;
+ // respond to the part under the cursor changing
+ if (this._actionPart !== oldActionPart) {
+ // show/hide drop controls
+ if ((this._actionPart instanceof drop_4.Drop) &&
+ (this.tool == 3 /* HAND */)) {
+ this._dropButton.x = this._actionPart.x;
+ this._dropButton.y = this._actionPart.y;
+ this._dropButton.size = this.controlSize;
+ this._dropButton.isFlipped = this._actionPart.isFlipped;
+ this._showControl(this._dropButton);
+ }
+ else if (oldActionPart instanceof drop_4.Drop) {
+ this._hideControl(this._dropButton);
+ this._hideControl(this._colorWheel);
+ }
+ // show/hide turnstile controls
+ if ((this._actionPart instanceof turnstile_3.Turnstile) &&
+ (this.tool == 3 /* HAND */)) {
+ this._turnButton.x = this.xForColumn(this._actionPart.column);
+ this._turnButton.y = this.yForRow(this._actionPart.row);
+ this._turnButton.isFlipped = this._actionPart.isFlipped;
+ this._turnButton.size = this.controlSize;
+ this._showControl(this._turnButton);
+ }
+ else if (oldActionPart instanceof turnstile_3.Turnstile) {
+ this._hideControl(this._turnButton);
+ }
+ // show hide the ball counter
+ if ((this._action === 2 /* PLACE_BALL */) &&
+ (this._ballCounter.drop = // intentional assignment
+ this.catchmentDrop(this._actionColumn, this._actionRow))) {
+ this._ballCounter.x = this._ballCounter.drop.x;
+ this._ballCounter.y = this._ballCounter.drop.y;
+ this._showControl(this._ballCounter);
+ this._ballCounter.update();
+ }
+ else if (this._ballCounter.visible) {
+ this._hideControl(this._ballCounter);
+ }
+ }
+ this._updatePreview();
+ }
+ _updatePreview() {
+ if (this.partPrototype) {
+ if (this._action === 1 /* PLACE_PART */) {
+ this.partPrototype.visible = true;
+ this.layoutPart(this.partPrototype, this._actionColumn, this._actionRow);
+ }
+ else if (this._action == 5 /* DRAG_PART */) {
+ this.partPrototype.visible = true;
+ this.layoutPart(this.partPrototype, this.columnForX(this._actionX), this.rowForY(this._actionY));
+ }
+ else if (this._action === 2 /* PLACE_BALL */) {
+ this.partPrototype.visible = true;
+ this.partPrototype.x = Math.round(this._actionX);
+ this.partPrototype.y = Math.round(this._actionY);
+ }
+ else {
+ this.partPrototype.visible = false;
+ }
+ }
+ if (this._action == 9 /* RESIZE_BOARD */) {
+ this._showControl(this._resizeOverlay);
+ this._updateResizeOverlay(false, this._actionSide, 0);
+ }
+ else if (this._resizeOverlay.visible) {
+ this._hideControl(this._resizeOverlay);
+ }
+ }
+ _onClick(e) {
+ this._updateAction(e);
+ // place parts
+ if ((this._action === 1 /* PLACE_PART */) &&
+ (this.partPrototype)) {
+ const oldPart = this.getPart(this._actionColumn, this._actionRow);
+ if (this.partPrototype.hasSameStateAs(oldPart)) {
+ this.clearPart(this._actionColumn, this._actionRow);
+ }
+ else {
+ this.setPart(this.partFactory.copy(this.partPrototype), this._actionColumn, this._actionRow);
+ }
+ }
+ else if ((this._action === 2 /* PLACE_BALL */) &&
+ (this.partPrototype)) {
+ const ball = this.ballUnder(this.columnForX(this._actionX), this.rowForY(this._actionY));
+ if (ball) {
+ this.removeBall(ball);
+ }
+ else {
+ this.addBall(this.partFactory.copy(this.partPrototype), this.columnForX(this._actionX), this.rowForY(this._actionY));
+ }
+ }
+ else if (this._action === 3 /* CLEAR_PART */) {
+ // clearing a background part makes a blank
+ if (this.isBackgroundPart(this._actionColumn, this._actionRow)) {
+ this.setPart(this.partFactory.make(0 /* BLANK */), this._actionColumn, this._actionRow);
+ }
+ else {
+ this.clearPart(this._actionColumn, this._actionRow);
+ }
+ }
+ else if (this._action === 4 /* FLIP_PART */) {
+ this.flipPart(this._actionColumn, this._actionRow);
+ }
+ else if ((this._action === 7 /* DROP_BALL */) &&
+ (this._actionPart instanceof drop_4.Drop)) {
+ this._actionPart.releaseBall();
+ }
+ else if ((this._action === 8 /* TURN_TURNSTILE */) &&
+ (this._actionPart instanceof turnstile_3.Turnstile)) {
+ const ts = this._actionPart;
+ animator_3.Animator.current.animate(ts, 'rotation', 0, 1, 0.25 /* TURN */, () => { ts.rotation = 0.0; });
+ }
+ }
+ };
+ exports_28("Board", Board);
+ }
+ };
+});
+System.register("ui/button", ["pixi.js", "ui/config", "renderer"], function (exports_29, context_29) {
+ "use strict";
+ var __moduleName = context_29 && context_29.id;
+ var PIXI, config_4, renderer_6, Button, PartButton, SpriteButton, ButtonBar;
+ return {
+ setters: [
+ function (PIXI_5) {
+ PIXI = PIXI_5;
+ },
+ function (config_4_1) {
+ config_4 = config_4_1;
+ },
+ function (renderer_6_1) {
+ renderer_6 = renderer_6_1;
+ }
+ ],
+ execute: function () {
+ Button = class Button extends PIXI.Sprite {
+ constructor() {
+ super();
+ this._size = 96;
+ this._isToggled = false;
+ this._isEnabled = true;
+ this._mouseOver = false;
+ this._mouseDown = false;
+ this.cursor = 'pointer';
+ this.interactive = true;
+ this.anchor.set(0.5, 0.5);
+ this._background = new PIXI.Graphics();
+ this.addChild(this._background);
+ this._updateState();
+ this.onSizeChanged();
+ this._bindHover();
+ }
+ get size() { return (this._size); }
+ set size(v) {
+ if (v === this._size)
+ return;
+ this._size = v;
+ this.onSizeChanged();
+ renderer_6.Renderer.needsUpdate();
+ }
+ get isToggled() { return (this._isToggled); }
+ set isToggled(v) {
+ if (v === this._isToggled)
+ return;
+ this._isToggled = v;
+ this._drawDecorations();
+ this._updateState();
+ }
+ get isEnabled() { return (this._isEnabled); }
+ set isEnabled(v) {
+ if (v === this._isEnabled)
+ return;
+ this._isEnabled = v;
+ this.interactive = v;
+ this.cursor = v ? 'pointer' : 'auto';
+ this._updateState();
+ }
+ onSizeChanged() {
+ this._drawDecorations();
+ }
+ _bindHover() {
+ this.addListener('mouseover', (e) => {
+ this._mouseOver = true;
+ this._updateState();
+ });
+ this.addListener('mouseout', (e) => {
+ this._mouseOver = false;
+ this._updateState();
+ });
+ this.addListener('mousedown', (e) => {
+ this._mouseDown = true;
+ this._updateState();
+ });
+ this.addListener('mouseup', (e) => {
+ this._mouseDown = false;
+ this._updateState();
+ });
+ }
+ _updateState() {
+ let alpha = 0.1 /* BUTTON_NORMAL */;
+ if (this.isEnabled) {
+ if ((this._mouseOver) && (this._mouseDown)) {
+ alpha = 0.3 /* BUTTON_DOWN */;
+ }
+ else if (this._mouseOver) {
+ alpha = 0.15 /* BUTTON_OVER */;
+ }
+ else
+ alpha = 0.1 /* BUTTON_NORMAL */;
+ if (this.isToggled)
+ alpha = Math.min(alpha * 2, 1.0);
+ }
+ this._background.alpha = alpha;
+ this.alpha = this.isEnabled ? 1.0 : 0.25 /* BUTTON_DISABLED */;
+ renderer_6.Renderer.needsUpdate();
+ }
+ _drawDecorations() {
+ const radius = 8; // pixels
+ const s = this.size;
+ const hs = Math.round(s * 0.5);
+ if (this._background) {
+ this._background.clear();
+ if (this.isToggled) {
+ this._background.lineStyle(2, 16755200 /* HIGHLIGHT */);
+ }
+ this._background.beginFill(this.isToggled ? 16755200 /* HIGHLIGHT */ : 0 /* BUTTON_BACK */);
+ this._background.drawRoundedRect(-hs, -hs, s, s, radius);
+ this._background.endFill();
+ }
+ renderer_6.Renderer.needsUpdate();
+ }
+ };
+ exports_29("Button", Button);
+ PartButton = class PartButton extends Button {
+ constructor(part) {
+ super();
+ this.part = part;
+ this._schematic = false;
+ this._schematicView = part.getSpriteForLayer(4 /* SCHEMATIC */);
+ if (!this._schematicView) {
+ this._schematicView = part.getSpriteForLayer(3 /* SCHEMATIC_BACK */);
+ }
+ this._normalView = new PIXI.Container();
+ this.addChild(this._normalView);
+ const toolSprite = part.getSpriteForLayer(7 /* TOOL */);
+ if (toolSprite)
+ this._normalView.addChild(toolSprite);
+ else {
+ for (let i = 0 /* BACK */; i <= 2 /* FRONT */; i++) {
+ const sprite = part.getSpriteForLayer(i);
+ if (sprite)
+ this._normalView.addChild(sprite);
+ }
+ }
+ this.onSizeChanged();
+ }
+ get schematic() { return (this._schematic); }
+ set schematic(v) {
+ if (v === this._schematic)
+ return;
+ this._schematic = v;
+ if ((v) && (this.part.type <= 9 /* BALL */)) {
+ this.removeChild(this._normalView);
+ this.addChild(this._schematicView);
+ }
+ else {
+ this.addChild(this._normalView);
+ this.removeChild(this._schematicView);
+ }
+ renderer_6.Renderer.needsUpdate();
+ }
+ onSizeChanged() {
+ super.onSizeChanged();
+ if (this.part)
+ this.part.size = Math.floor(this.size * 0.75);
+ }
+ };
+ exports_29("PartButton", PartButton);
+ SpriteButton = class SpriteButton extends Button {
+ constructor(sprite) {
+ super();
+ this.sprite = sprite;
+ if (sprite) {
+ sprite.anchor.set(0.5, 0.5);
+ this.addChild(sprite);
+ }
+ this.onSizeChanged();
+ }
+ onSizeChanged() {
+ super.onSizeChanged();
+ if (this.sprite) {
+ this.sprite.width =
+ this.sprite.height =
+ Math.floor(this.size * 0.75);
+ }
+ }
+ };
+ exports_29("SpriteButton", SpriteButton);
+ ButtonBar = class ButtonBar extends PIXI.Container {
+ constructor() {
+ super();
+ this._background = new PIXI.Graphics();
+ this._buttons = [];
+ this._bottomCount = 0;
+ this._width = 96;
+ this._height = 96;
+ // whether to automatically adjust the width to match the height
+ this.autowidth = true;
+ this._margin = 4;
+ this.addChild(this._background);
+ this._layout();
+ }
+ // the number of buttons to push to the bottom of the bar
+ get bottomCount() { return (this._bottomCount); }
+ set bottomCount(v) {
+ if (v === this.bottomCount)
+ return;
+ this._bottomCount = v;
+ this._layout();
+ }
+ get width() { return (this._width); }
+ set width(v) {
+ if (v === this._width)
+ return;
+ this._width = v;
+ for (const button of this._buttons) {
+ button.size = this.width;
+ }
+ this._layout();
+ }
+ get height() { return (this._height); }
+ set height(v) {
+ if (v === this._height)
+ return;
+ this._height = v;
+ this._layout();
+ // if the height doesn't allow some buttons to show, make buttons smaller
+ if (this.autowidth) {
+ let safeSize = config_4.ButtonSizes[0];
+ let s;
+ for (s of config_4.ButtonSizes) {
+ if (this._contentHeightForWidth(s + (2 * this.margin)) <= this.height) {
+ safeSize = s;
+ }
+ }
+ this.width = safeSize + (2 * this.margin);
+ }
+ }
+ get margin() { return (this._margin); }
+ set margin(v) {
+ if (v === this._margin)
+ return;
+ this._margin = v;
+ this._layout();
+ }
+ addButton(button) {
+ this._buttons.push(button);
+ this.addChild(button);
+ button.addListener('click', this._onButtonClick.bind(this));
+ button.addListener('tap', this._onButtonClick.bind(this));
+ this._layout();
+ }
+ // handle buttons being clicked
+ _onButtonClick(e) {
+ if (!(e.target instanceof Button))
+ return;
+ this.onButtonClick(e.target);
+ }
+ // lay out buttons in a vertical strip
+ _layout() {
+ const m = this.margin;
+ const w = this.width - (2 * m);
+ const hw = Math.floor(w / 2);
+ const x = m + hw;
+ let y = m + hw;
+ // lay out top buttons
+ for (let i = 0; i < this._buttons.length - this.bottomCount; i++) {
+ const button = this._buttons[i];
+ button.size = w;
+ button.x = x;
+ button.y = y;
+ y += w + m;
+ }
+ // lay out bottom buttons
+ y = this.height - (m + hw);
+ for (let i = 0; i < this.bottomCount; i++) {
+ const button = this._buttons[(this._buttons.length - 1) - i];
+ button.size = w;
+ button.x = x;
+ button.y = y;
+ y -= w + m;
+ }
+ this._background.clear();
+ this._background.beginFill(16777215 /* BACKGROUND */, 1.0);
+ this._background.drawRect(0, 0, this.width, this.height);
+ this._background.endFill();
+ renderer_6.Renderer.needsUpdate();
+ }
+ // get the height taken up by all the buttons at the given width
+ _contentHeightForWidth(w) {
+ const m = this.margin;
+ return (m + ((w - m) * this._buttons.length));
+ }
+ };
+ exports_29("ButtonBar", ButtonBar);
+ }
+ };
+});
+System.register("ui/toolbar", ["pixi.js", "ui/button", "renderer"], function (exports_30, context_30) {
+ "use strict";
+ var __moduleName = context_30 && context_30.id;
+ var PIXI, button_1, renderer_7, Toolbar;
+ return {
+ setters: [
+ function (PIXI_6) {
+ PIXI = PIXI_6;
+ },
+ function (button_1_1) {
+ button_1 = button_1_1;
+ },
+ function (renderer_7_1) {
+ renderer_7 = renderer_7_1;
+ }
+ ],
+ execute: function () {
+ Toolbar = class Toolbar extends button_1.ButtonBar {
+ constructor(board) {
+ super();
+ this.board = board;
+ // add a button to change the position of parts
+ this._handButton = new button_1.SpriteButton(new PIXI.Sprite(board.partFactory.textures['hand']));
+ this.addButton(this._handButton);
+ // add a button to remove parts
+ this._eraserButton = new button_1.PartButton(this.board.partFactory.make(1 /* PARTLOC */));
+ this.addButton(this._eraserButton);
+ // add buttons for parts
+ for (let i = 3 /* TOOLBOX_MIN */; i <= 13 /* TOOLBOX_MAX */; i++) {
+ const part = board.partFactory.make(i);
+ if (!part)
+ continue;
+ const button = new button_1.PartButton(part);
+ this.addButton(button);
+ }
+ this.updateToggled();
+ }
+ onButtonClick(button) {
+ if (button === this._handButton) {
+ this.board.tool = 3 /* HAND */;
+ this.board.partPrototype = null;
+ }
+ else if (button === this._eraserButton) {
+ this.board.tool = 2 /* ERASER */;
+ this.board.partPrototype = null;
+ }
+ else if (button instanceof button_1.PartButton) {
+ const newPart = button.part;
+ if ((this.board.partPrototype) &&
+ (newPart.type === this.board.partPrototype.type)) {
+ // toggle direction if the selected part is clicked again
+ newPart.flip(0.25 /* FLIP */);
+ }
+ this.board.tool = 1 /* PART */;
+ this.board.partPrototype = this.board.partFactory.copy(newPart);
+ }
+ this.updateToggled();
+ }
+ updateToggled() {
+ // update button toggle states
+ for (const button of this._buttons) {
+ if (button === this._handButton) {
+ button.isToggled = (this.board.tool === 3 /* HAND */);
+ }
+ else if (button === this._eraserButton) {
+ button.isToggled = (this.board.tool === 2 /* ERASER */);
+ this._eraserButton.schematic = this.board.schematicView;
+ }
+ else if (button instanceof button_1.PartButton) {
+ button.isToggled = ((this.board.tool === 1 /* PART */) &&
+ (this.board.partPrototype) &&
+ (button.part.type === this.board.partPrototype.type));
+ button.schematic = this.board.schematicView;
+ }
+ }
+ renderer_7.Renderer.needsUpdate();
+ }
+ };
+ exports_30("Toolbar", Toolbar);
+ }
+ };
+});
+System.register("board/builder", ["parts/fence"], function (exports_31, context_31) {
+ "use strict";
+ var __moduleName = context_31 && context_31.id;
+ var fence_5, BoardBuilder;
+ return {
+ setters: [
+ function (fence_5_1) {
+ fence_5 = fence_5_1;
+ }
+ ],
+ execute: function () {
+ BoardBuilder = class BoardBuilder {
+ static initStandardBoard(board, redBlueDistance = 5, verticalDrop = 11) {
+ let r, c, run;
+ const width = (redBlueDistance * 2) + 3;
+ const center = Math.floor(width / 2);
+ const blueColumn = center - Math.floor(redBlueDistance / 2);
+ const redColumn = center + Math.floor(redBlueDistance / 2);
+ const dropLevel = (blueColumn % 2 == 0) ? 1 : 2;
+ const collectLevel = dropLevel + verticalDrop;
+ const steps = Math.ceil(center / fence_5.Slope.maxModulus);
+ const maxModulus = Math.ceil(center / steps);
+ const height = collectLevel + steps + 4;
+ board.bulkUpdate = true;
+ board.setSize(width, height, false);
+ board.clear(true);
+ // block out unreachable locations at the top
+ const blank = board.partFactory.make(0 /* BLANK */);
+ blank.isLocked = true;
+ for (r = 0; r < height; r++) {
+ for (c = 0; c < width; c++) {
+ const blueCantReach = ((r + c) < (blueColumn + dropLevel)) ||
+ ((c - r) > (blueColumn - dropLevel));
+ const redCantReach = ((r + c) < (redColumn + dropLevel)) ||
+ ((c - r) > (redColumn - dropLevel));
+ if ((blueCantReach && redCantReach) || (r <= dropLevel)) {
+ board.setPart(board.partFactory.copy(blank), c, r);
+ }
+ }
+ }
+ // add fences on the sides
+ const side = board.partFactory.make(12 /* SIDE */);
+ side.isLocked = true;
+ const flippedSide = board.partFactory.copy(side);
+ flippedSide.flip();
+ for (r = dropLevel - 1; r < collectLevel; r++) {
+ board.setPart(board.partFactory.copy(side), 0, r);
+ board.setPart(board.partFactory.copy(flippedSide), width - 1, r);
+ }
+ // add collection slopes at the bottom
+ const slope = board.partFactory.make(13 /* SLOPE */);
+ slope.isLocked = true;
+ const flippedSlope = board.partFactory.copy(slope);
+ flippedSlope.flip();
+ r = collectLevel;
+ run = 0;
+ for (c = 0; c < center - 1; c++, run++) {
+ if (run >= maxModulus) {
+ r++;
+ run = 0;
+ }
+ board.setPart(board.partFactory.copy(slope), c, r);
+ }
+ r = collectLevel;
+ run = 0;
+ for (c = width - 1; c > center + 1; c--, run++) {
+ if (run >= maxModulus) {
+ r++;
+ run = 0;
+ }
+ board.setPart(board.partFactory.copy(flippedSlope), c, r);
+ }
+ const turnstileLevel = r + 1;
+ // add hoppers for extra balls
+ board.setPart(board.partFactory.copy(slope), blueColumn - 2, dropLevel - 1);
+ board.setPart(board.partFactory.copy(flippedSlope), blueColumn, dropLevel - 1);
+ board.setPart(board.partFactory.copy(slope), redColumn, dropLevel - 1);
+ board.setPart(board.partFactory.copy(flippedSlope), redColumn + 2, dropLevel - 1);
+ // block out the unreachable locations at the bottom
+ for (r = collectLevel; r < height; r++) {
+ for (c = 0; c < width; c++) {
+ const p = board.getPart(c, r);
+ if ((p instanceof fence_5.Side) || (p instanceof fence_5.Slope))
+ break;
+ board.setPart(board.partFactory.copy(blank), c, r);
+ }
+ for (c = width - 1; c >= 0; c--) {
+ const p = board.getPart(c, r);
+ if ((p instanceof fence_5.Side) || (p instanceof fence_5.Slope))
+ break;
+ board.setPart(board.partFactory.copy(blank), c, r);
+ }
+ }
+ // make a fence to collect balls
+ const rightSide = center + fence_5.Slope.maxModulus;
+ for (c = center; c < rightSide; c++) {
+ board.setPart(board.partFactory.copy(slope), c, height - 1);
+ board.setPart(board.partFactory.copy(flippedSlope), c, height - 3);
+ }
+ for (r = height - 3; r <= height - 1; r++) {
+ board.setPart(board.partFactory.copy(side), rightSide, r);
+ }
+ board.setPart(board.partFactory.copy(slope), center - 1, height - 2);
+ board.setPart(board.partFactory.copy(slope), center - 2, height - 3);
+ // make ball drops
+ const blueDrop = board.partFactory.make(10 /* DROP */);
+ board.setPart(blueDrop, blueColumn - 1, dropLevel);
+ blueDrop.hue = 220;
+ blueDrop.isLocked = true;
+ const redDrop = board.partFactory.make(10 /* DROP */);
+ redDrop.isFlipped = true;
+ board.setPart(redDrop, redColumn + 1, dropLevel);
+ redDrop.hue = 0;
+ redDrop.isLocked = true;
+ // add balls
+ board.setDropBallCount(blueDrop, 8);
+ board.setDropBallCount(redDrop, 8);
+ // make turnstiles
+ const blueTurnstile = board.partFactory.make(11 /* TURNSTILE */);
+ blueTurnstile.isLocked = true;
+ board.setPart(blueTurnstile, center - 1, turnstileLevel);
+ const redTurnstile = board.partFactory.make(11 /* TURNSTILE */);
+ redTurnstile.isLocked = true;
+ redTurnstile.isFlipped = true;
+ board.setPart(redTurnstile, center + 1, turnstileLevel);
+ board.bulkUpdate = false;
+ }
+ };
+ exports_31("BoardBuilder", BoardBuilder);
+ }
+ };
+});
+System.register("ui/actionbar", ["pixi.js", "board/board", "ui/button", "ui/config", "renderer", "board/serializer", "ui/animator", "board/builder", "custom/matrixTransformer"], function (exports_32, context_32) {
+ "use strict";
+ var __moduleName = context_32 && context_32.id;
+ var PIXI, board_2, button_2, config_5, renderer_8, serializer_1, animator_4, builder_1, matrixTransformer_2, Actionbar, BoardDrawer;
+ return {
+ setters: [
+ function (PIXI_7) {
+ PIXI = PIXI_7;
+ },
+ function (board_2_1) {
+ board_2 = board_2_1;
+ },
+ function (button_2_1) {
+ button_2 = button_2_1;
+ },
+ function (config_5_1) {
+ config_5 = config_5_1;
+ },
+ function (renderer_8_1) {
+ renderer_8 = renderer_8_1;
+ },
+ function (serializer_1_1) {
+ serializer_1 = serializer_1_1;
+ },
+ function (animator_4_1) {
+ animator_4 = animator_4_1;
+ },
+ function (builder_1_1) {
+ builder_1 = builder_1_1;
+ },
+ function (matrixTransformer_2_1) {
+ matrixTransformer_2 = matrixTransformer_2_1;
+ }
+ ],
+ execute: function () {
+ Actionbar = class Actionbar extends button_2.ButtonBar {
+ constructor(board) {
+ super();
+ this.board = board;
+ // add the drawer behind the background
+ this._drawer = new BoardDrawer(this.board);
+ this._drawer.peer = this;
+ this.addChildAt(this._drawer, 0);
+ this._drawer.visible = false;
+ this._drawer.autowidth = false;
+ // add a button to show and hide extra board operations
+ this._matrixSendButton = new button_2.SpriteButton(new PIXI.Sprite()
+ // load img here, i don t know how :)
+ );
+ this.addButton(this._matrixSendButton);
+ this._drawerButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["board-drawer"]));
+ this.addButton(this._drawerButton);
+ // add a button to toggle schematic view
+ this._schematicButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["schematic"]));
+ this.addButton(this._schematicButton);
+ // add zoom controls
+ this._zoomInButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["zoomin"]));
+ this.addButton(this._zoomInButton);
+ this._zoomOutButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["zoomout"]));
+ this.addButton(this._zoomOutButton);
+ this._zoomToFitButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["zoomtofit"]));
+ this.addButton(this._zoomToFitButton);
+ // add speed controls
+ this._fasterButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["faster"]));
+ this.addButton(this._fasterButton);
+ this._slowerButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["slower"]));
+ this.addButton(this._slowerButton);
+ // add a ball return
+ this._returnButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["return"]));
+ this.addButton(this._returnButton);
+ // add more top buttons here...
+ // add a link to documentation
+ this._helpButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["help"]));
+ this.addButton(this._helpButton);
+ // add a link to the github repo
+ this._githubButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["octocat"]));
+ this.addButton(this._githubButton);
+ // add a link to the Turing Tumble website
+ this._heartButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["heart"]));
+ this.addButton(this._heartButton);
+ this.bottomCount = 3;
+ this.updateToggled();
+ // zoom on wheel events
+ document.addEventListener("wheel", (e) => {
+ console.log(e);
+ if (e.deltaY < 0 || e.deltaX < 0 || e.deltaZ < 0)
+ this.zoomIn();
+ else if (e.deltaY > 0 || e.deltaX > 0 || e.deltaZ > 0)
+ this.zoomOut();
+ e.preventDefault();
+ });
+ }
+ onButtonClick(button) {
+ return __awaiter(this, void 0, void 0, function* () {
+ if (button === this._schematicButton) {
+ this.board.schematic = !this.board.schematicView;
+ this.updateToggled();
+ if (this.peer)
+ this.peer.updateToggled();
+ }
+ else if (button === this._zoomInButton) {
+ this.zoomIn();
+ if (this.peer)
+ this.peer.updateToggled();
+ }
+ else if (button === this._zoomOutButton) {
+ this.zoomOut();
+ if (this.peer)
+ this.peer.updateToggled();
+ }
+ else if (button === this._zoomToFitButton) {
+ this.zoomToFit();
+ if (this.peer)
+ this.peer.updateToggled();
+ }
+ else if (button === this._fasterButton) {
+ this.goFaster();
+ }
+ else if (button === this._slowerButton) {
+ this.goSlower();
+ }
+ else if (button === this._returnButton) {
+ this.board.returnBalls();
+ }
+ else if (button === this._drawerButton)
+ this.toggleDrawer();
+ else if (button === this._helpButton) {
+ window.open("usage", "_blank");
+ }
+ else if (button === this._githubButton) {
+ let m = window.location.host.match(new RegExp("^([^.]+)[.]github[.]io"));
+ const user = m ? m[1] : "jessecrossen";
+ m = window.location.pathname.match(new RegExp("/*([^/?#]+)"));
+ const repo = m ? m[1] : "ttsim";
+ window.open("https://github.com/" + user + "/" + repo + "/", "_blank");
+ }
+ else if (button === this._heartButton) {
+ window.open("https://www.turingtumble.com/", "_blank");
+ }
+ else if (button === this._matrixSendButton) {
+ const hash = window.location.hash.substr(1);
+ const [ui, board] = hash.split("b=");
+ const matrix = yield matrixTransformer_2.transformToMatrix(board);
+ const body = {
+ array: matrix,
+ };
+ const strBody = JSON.stringify(body);
+ const resp = yield fetch("http://127.0.0.1:8000/TranslationLayer/t2/" + strBody);
+ console.log(resp);
+ }
+ });
+ }
+ updateToggled() {
+ // update button toggle states
+ for (const button of this._buttons) {
+ if (button === this._schematicButton) {
+ button.isToggled = this.board.schematic;
+ }
+ else if (button === this._zoomInButton) {
+ button.isEnabled = this.canZoomIn;
+ }
+ else if (button === this._zoomOutButton) {
+ button.isEnabled = this.canZoomOut;
+ }
+ else if (button === this._fasterButton) {
+ button.isEnabled = this.canGoFaster;
+ }
+ else if (button === this._slowerButton) {
+ button.isEnabled = this.canGoSlower;
+ }
+ else if (button === this._drawerButton) {
+ button.isToggled = this._drawer.visible;
+ }
+ }
+ renderer_8.Renderer.needsUpdate();
+ }
+ // SPEED CONTROL ************************************************************
+ get canGoFaster() {
+ return this.speedIndex < config_5.Speeds.length - 1;
+ }
+ get canGoSlower() {
+ return this.speedIndex > 0;
+ }
+ goFaster() {
+ this.speedIndex++;
+ }
+ goSlower() {
+ this.speedIndex--;
+ }
+ get speedIndex() {
+ return config_5.Speeds.indexOf(this.board.speed);
+ }
+ set speedIndex(i) {
+ if (i >= 0 && i < config_5.Speeds.length)
+ this.board.speed = config_5.Speeds[i];
+ this.updateToggled();
+ }
+ // ZOOMING ******************************************************************
+ get canZoomIn() {
+ return this.zoomIndex < config_5.Zooms.length - 1;
+ }
+ get canZoomOut() {
+ return this.zoomIndex > 0;
+ }
+ zoomIn() {
+ if (!this.canZoomIn)
+ return;
+ this.board.partSize = config_5.Zooms[this.zoomIndex + 1];
+ this.updateToggled();
+ }
+ zoomOut() {
+ if (!this.canZoomOut)
+ return;
+ this.board.partSize = config_5.Zooms[this.zoomIndex - 1];
+ this.updateToggled();
+ }
+ // zoom to fit the board
+ zoomToFit() {
+ this.board.centerColumn = (this.board.columnCount - 1) / 2;
+ this.board.centerRow = (this.board.rowCount - 1) / 2;
+ let s = config_5.Zooms[0];
+ for (let i = config_5.Zooms.length - 1; i >= 0; i--) {
+ s = config_5.Zooms[i];
+ const w = this.board.columnCount * Math.floor(s * board_2.SPACING_FACTOR);
+ const h = this.board.rowCount * Math.floor(s * board_2.SPACING_FACTOR);
+ if (w <= this.board.width && h <= this.board.height)
+ break;
+ }
+ this.board.partSize = s;
+ this.updateToggled();
+ }
+ get zoomIndex() {
+ return config_5.Zooms.indexOf(this.board.partSize);
+ }
+ // DRAWER *******************************************************************
+ _layout() {
+ super._layout();
+ if (this._drawer) {
+ this._drawer.width = this.width;
+ this._drawer.height = this.height;
+ this._drawer.x = this._drawer.visible ? -this.width : 0;
+ }
+ }
+ toggleDrawer() {
+ if (!this._drawer.visible) {
+ this._drawerButton.scale.x = -Math.abs(this._drawerButton.scale.x);
+ this._drawer.visible = true;
+ this._drawer.x = 0;
+ animator_4.Animator.current.animate(this._drawer, "x", 0, -this.width, 0.1 /* SHOW_CONTROL */);
+ this.updateToggled();
+ }
+ else {
+ this._drawerButton.scale.x = Math.abs(this._drawerButton.scale.x);
+ animator_4.Animator.current.animate(this._drawer, "x", -this.width, 0, 0.25 /* HIDE_CONTROL */, () => {
+ this._drawer.visible = false;
+ this.updateToggled();
+ });
+ }
+ }
+ };
+ exports_32("Actionbar", Actionbar);
+ BoardDrawer = class BoardDrawer extends button_2.ButtonBar {
+ constructor(board) {
+ super();
+ this.board = board;
+ // add standard boards in several sizes
+ this._smallButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["board-small"]));
+ this.addButton(this._smallButton);
+ this._mediumButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["board-medium"]));
+ this.addButton(this._mediumButton);
+ this._largeButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["board-large"]));
+ this.addButton(this._largeButton);
+ // add clear buttons
+ this._clearButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["board-clear"]));
+ this.addButton(this._clearButton);
+ this._clearBallsButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["clear-balls"]));
+ this.addButton(this._clearBallsButton);
+ // add upload download actions
+ this._downloadButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["download"]));
+ this.addButton(this._downloadButton);
+ this._uploadButton = new button_2.SpriteButton(new PIXI.Sprite(board.partFactory.textures["upload"]));
+ this.addButton(this._uploadButton);
+ }
+ onButtonClick(button) {
+ if (button === this._smallButton) {
+ builder_1.BoardBuilder.initStandardBoard(this.board, 5, 11);
+ this.zoomToFit();
+ }
+ else if (button === this._mediumButton) {
+ builder_1.BoardBuilder.initStandardBoard(this.board, 7, 15);
+ this.zoomToFit();
+ }
+ else if (button === this._largeButton) {
+ builder_1.BoardBuilder.initStandardBoard(this.board, 9, 19);
+ this.zoomToFit();
+ }
+ else if (button === this._clearButton) {
+ this.board.clear();
+ this.zoomToFit();
+ }
+ else if (button === this._clearBallsButton) {
+ this.board.clearBalls();
+ }
+ else if (button === this._downloadButton) {
+ if (this.board.serializer instanceof serializer_1.URLBoardSerializer) {
+ this.board.serializer.download();
+ }
+ }
+ else if (button === this._uploadButton) {
+ if (this.board.serializer instanceof serializer_1.URLBoardSerializer) {
+ this.board.serializer.upload((restored) => {
+ if (restored)
+ this.zoomToFit();
+ });
+ }
+ }
+ }
+ zoomToFit() {
+ if (this.peer instanceof Actionbar)
+ this.peer.zoomToFit();
+ }
+ updateToggled() { }
+ };
+ exports_32("BoardDrawer", BoardDrawer);
+ }
+ };
+});
+System.register("app", ["pixi.js", "board/board", "parts/factory", "ui/toolbar", "ui/actionbar", "renderer", "ui/animator", "ui/keyboard", "parts/gearbit"], function (exports_33, context_33) {
+ "use strict";
+ var __moduleName = context_33 && context_33.id;
+ var PIXI, board_3, factory_2, toolbar_1, actionbar_1, renderer_9, animator_5, keyboard_2, gearbit_5, SimulatorApp;
+ return {
+ setters: [
+ function (PIXI_8) {
+ PIXI = PIXI_8;
+ },
+ function (board_3_1) {
+ board_3 = board_3_1;
+ },
+ function (factory_2_1) {
+ factory_2 = factory_2_1;
+ },
+ function (toolbar_1_1) {
+ toolbar_1 = toolbar_1_1;
+ },
+ function (actionbar_1_1) {
+ actionbar_1 = actionbar_1_1;
+ },
+ function (renderer_9_1) {
+ renderer_9 = renderer_9_1;
+ },
+ function (animator_5_1) {
+ animator_5 = animator_5_1;
+ },
+ function (keyboard_2_1) {
+ keyboard_2 = keyboard_2_1;
+ },
+ function (gearbit_5_1) {
+ gearbit_5 = gearbit_5_1;
+ }
+ ],
+ execute: function () {
+ SimulatorApp = class SimulatorApp extends PIXI.Container {
+ constructor(textures) {
+ super();
+ this.textures = textures;
+ this._width = 0;
+ this._height = 0;
+ this.partFactory = new factory_2.PartFactory(textures);
+ this.board = new board_3.Board(this.partFactory);
+ this.toolbar = new toolbar_1.Toolbar(this.board);
+ this.actionbar = new actionbar_1.Actionbar(this.board);
+ this.actionbar.peer = this.toolbar;
+ this.toolbar.peer = this.actionbar;
+ this.addChild(this.board.view);
+ this.addChild(this.toolbar);
+ this.addChild(this.actionbar);
+ this._layout();
+ // add event listeners
+ this._addKeyHandlers();
+ }
+ update(delta) {
+ animator_5.Animator.current.update(delta);
+ this.board.update(delta);
+ gearbit_5.GearBase.update();
+ renderer_9.Renderer.render();
+ }
+ get width() { return (this._width); }
+ set width(v) {
+ if (v === this._width)
+ return;
+ this._width = v;
+ this._layout();
+ }
+ get height() { return (this._height); }
+ set height(v) {
+ if (v === this._height)
+ return;
+ this._height = v;
+ this._layout();
+ }
+ _layout() {
+ this.toolbar.height = this.height;
+ this.actionbar.height = this.height;
+ this.actionbar.x = this.width - this.actionbar.width;
+ this.board.view.x = this.toolbar.width;
+ this.board.width = Math.max(0, this.width - (this.toolbar.width + this.actionbar.width));
+ this.board.height = this.height;
+ renderer_9.Renderer.needsUpdate();
+ }
+ _addKeyHandlers() {
+ keyboard_2.makeKeyHandler('w').press = () => {
+ this.board.physicalRouter.showWireframe =
+ !this.board.physicalRouter.showWireframe;
+ };
+ }
+ };
+ exports_33("SimulatorApp", SimulatorApp);
+ }
+ };
+});
+System.register("index", ["pixi.js", "app", "renderer", "board/builder", "board/serializer"], function (exports_34, context_34) {
+ "use strict";
+ var __moduleName = context_34 && context_34.id;
+ var PIXI, app_1, renderer_10, builder_2, serializer_2, sim, container, resizeApp, loader;
+ return {
+ setters: [
+ function (PIXI_9) {
+ PIXI = PIXI_9;
+ },
+ function (app_1_1) {
+ app_1 = app_1_1;
+ },
+ function (renderer_10_1) {
+ renderer_10 = renderer_10_1;
+ },
+ function (builder_2_1) {
+ builder_2 = builder_2_1;
+ },
+ function (serializer_2_1) {
+ serializer_2 = serializer_2_1;
+ }
+ ],
+ execute: function () {
+ // dynamically resize the app to track the size of the browser window
+ container = document.getElementById("container");
+ container.style.overflow = "hidden";
+ resizeApp = () => {
+ const r = container.getBoundingClientRect();
+ renderer_10.Renderer.instance.resize(r.width, r.height);
+ if (sim) {
+ sim.width = r.width;
+ sim.height = r.height;
+ }
+ };
+ resizeApp();
+ window.addEventListener("resize", resizeApp);
+ // load sprites
+ loader = PIXI.loader;
+ loader.add("images/parts.json").load(() => {
+ console.log("loading....");
+ sim = new app_1.SimulatorApp(PIXI.loader.resources["images/parts.json"].textures);
+ // restore state if there is any
+ sim.board.serializer = new serializer_2.URLBoardSerializer(sim.board);
+ sim.board.serializer.restore((restored) => {
+ // update toolbars based on restored state
+ sim.toolbar.updateToggled();
+ sim.actionbar.updateToggled();
+ sim.width = renderer_10.Renderer.instance.width;
+ sim.height = renderer_10.Renderer.instance.height;
+ renderer_10.Renderer.stage.addChild(sim);
+ // set up the standard board if there was no state
+ if (!restored) {
+ builder_2.BoardBuilder.initStandardBoard(sim.board);
+ sim.actionbar.zoomToFit();
+ }
+ // remove the loading animation
+ const loading = document.getElementById("loading");
+ if (loading) {
+ loading.style.opacity = "0";
+ // clear it from the display list after the animation,
+ // in case the browser still renders it at zero opacity
+ setTimeout(() => (loading.style.display = "none"), 1000);
+ }
+ // attach the stage to the document and fade it in
+ container.appendChild(renderer_10.Renderer.instance.view);
+ container.style.opacity = "1";
+ // start the game loop
+ PIXI.ticker.shared.add(sim.update, sim);
+ });
+ });
+ }
+ };
+});
diff --git a/ttsim/docs/images/icon.png b/ttsim/docs/images/icon.png
new file mode 100644
index 0000000..4dab64f
Binary files /dev/null and b/ttsim/docs/images/icon.png differ
diff --git a/ttsim/docs/images/loading.gif b/ttsim/docs/images/loading.gif
new file mode 100644
index 0000000..2621717
Binary files /dev/null and b/ttsim/docs/images/loading.gif differ
diff --git a/ttsim/docs/images/parts.json b/ttsim/docs/images/parts.json
new file mode 100644
index 0000000..0a6c86e
--- /dev/null
+++ b/ttsim/docs/images/parts.json
@@ -0,0 +1,2887 @@
+{
+ "frames": {
+ "Ball-f": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 108
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Ball-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 108
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Ball-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 108
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Bit-b": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 420
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Bit-f": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 420
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Bit-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 420
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Bit-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 316,
+ "y": 420
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Bit-s2": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 316,
+ "y": 177
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Bit-s4": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 316,
+ "y": 124
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Bit-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 732,
+ "y": 628
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "ColorWheel-f": {
+ "frame": {
+ "h": 64,
+ "w": 64,
+ "x": 800,
+ "y": 144
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 64,
+ "w": 64
+ },
+ "spriteSourceSize": {
+ "h": 64,
+ "w": 64,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "ColorWheel-m": {
+ "frame": {
+ "h": 64,
+ "w": 64,
+ "x": 732,
+ "y": 144
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 64,
+ "w": 64
+ },
+ "spriteSourceSize": {
+ "h": 64,
+ "w": 64,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Crossover-b": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 628
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Crossover-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 628
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Crossover-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 316,
+ "y": 628
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Crossover-s2": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 316,
+ "y": 193
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Crossover-s4": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 316,
+ "y": 140
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Crossover-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 732,
+ "y": 836
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Drop-b": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 732,
+ "y": 316
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Drop-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 732,
+ "y": 212
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Drop-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 732,
+ "y": 524
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Drop-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 940
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "DropButton-f": {
+ "frame": {
+ "h": 32,
+ "w": 32,
+ "x": 868,
+ "y": 144
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 32,
+ "w": 32
+ },
+ "spriteSourceSize": {
+ "h": 32,
+ "w": 32,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gear-f": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 212
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gear-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 316,
+ "y": 212
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gear-s2": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 316,
+ "y": 161
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gear-s4": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 316,
+ "y": 108
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gear-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 836,
+ "y": 836
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "GearLocation-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 836
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "GearLocation-sb": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 316,
+ "y": 836
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gearbit-b": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 316
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gearbit-f": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 316
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gearbit-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 316
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gearbit-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 316,
+ "y": 316
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gearbit-s2": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 316,
+ "y": 169
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gearbit-s4": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 316,
+ "y": 116
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Gearbit-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 836,
+ "y": 940
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Interceptor-b": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 524
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Interceptor-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 524
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Interceptor-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 316,
+ "y": 524
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Interceptor-s2": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 316,
+ "y": 185
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Interceptor-s4": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 316,
+ "y": 132
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Interceptor-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 732,
+ "y": 732
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "PartLocation-b": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 940
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "PartLocation-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 940
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "PartLocation-sb": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 316,
+ "y": 940
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "PartLocation-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 836
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Ramp-b": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 732
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Ramp-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 732
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Ramp-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 316,
+ "y": 732
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Ramp-s2": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 316,
+ "y": 201
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Ramp-s4": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 316,
+ "y": 148
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Ramp-sb": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 732
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Ramp-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 732,
+ "y": 940
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Side-b": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 420,
+ "y": 940
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Side-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 940
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Side-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 940
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Side-s2": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 464,
+ "y": 161
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Side-s4": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 396,
+ "y": 158
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Side-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 836,
+ "y": 732
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-b0": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 420,
+ "y": 836
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-b1": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 420,
+ "y": 732
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-b2": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 420,
+ "y": 628
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-b3": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 420,
+ "y": 524
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-b4": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 420,
+ "y": 420
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-b5": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 420,
+ "y": 316
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-b6": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 420,
+ "y": 212
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-m0": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 836
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-m1": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 732
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-m2": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 628
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-m3": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 524
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-m4": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 420
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-m5": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 316
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-m6": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 212
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s0": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 836
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s1": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 732
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s2": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 628
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s20": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 464,
+ "y": 169
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s21": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 464,
+ "y": 153
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s22": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 464,
+ "y": 145
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s23": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 464,
+ "y": 137
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s24": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 464,
+ "y": 129
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s25": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 464,
+ "y": 121
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s26": {
+ "frame": {
+ "h": 2,
+ "w": 2,
+ "x": 464,
+ "y": 113
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 2,
+ "w": 2
+ },
+ "spriteSourceSize": {
+ "h": 2,
+ "w": 2,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s3": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 524
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s4": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 420
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s40": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 396,
+ "y": 166
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s41": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 396,
+ "y": 150
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s42": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 396,
+ "y": 142
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s43": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 396,
+ "y": 134
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s44": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 396,
+ "y": 126
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s45": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 396,
+ "y": 118
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s46": {
+ "frame": {
+ "h": 6,
+ "w": 6,
+ "x": 396,
+ "y": 110
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 6,
+ "w": 6
+ },
+ "spriteSourceSize": {
+ "h": 6,
+ "w": 6,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s5": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 316
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-s6": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 212
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Slope-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 836,
+ "y": 628
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "TurnButton-f": {
+ "frame": {
+ "h": 32,
+ "w": 32,
+ "x": 868,
+ "y": 176
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 32,
+ "w": 32
+ },
+ "spriteSourceSize": {
+ "h": 32,
+ "w": 32,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Turnstile-f": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 836,
+ "y": 420
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Turnstile-m": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 836,
+ "y": 316
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Turnstile-s": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 836,
+ "y": 524
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "Turnstile-t": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 836,
+ "y": 212
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "board-clear": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 108
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "board-drawer": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 836,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "board-large": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 628
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "board-medium": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 836
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "board-small": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 524
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "clear-balls": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 940,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "download": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 628,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "faster": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 212
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "hand": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "heart": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "help": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 940,
+ "y": 108
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "octocat": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 732,
+ "y": 420
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "return": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 524,
+ "y": 108
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "schematic": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 108,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "slower": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 4,
+ "y": 212
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "upload": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 732,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "zoomin": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 212,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "zoomout": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 316,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ },
+ "zoomtofit": {
+ "frame": {
+ "h": 96,
+ "w": 96,
+ "x": 420,
+ "y": 4
+ },
+ "pivot": {
+ "x": 0.5,
+ "y": 0.5
+ },
+ "rotated": false,
+ "sourceSize": {
+ "h": 96,
+ "w": 96
+ },
+ "spriteSourceSize": {
+ "h": 96,
+ "w": 96,
+ "x": 0,
+ "y": 0
+ },
+ "trimmed": false
+ }
+ },
+ "meta": {
+ "image": "parts.png"
+ }
+}
\ No newline at end of file
diff --git a/ttsim/docs/images/parts.png b/ttsim/docs/images/parts.png
new file mode 100644
index 0000000..fc4b4a7
Binary files /dev/null and b/ttsim/docs/images/parts.png differ
diff --git a/ttsim/docs/images/usage/.touch b/ttsim/docs/images/usage/.touch
new file mode 100644
index 0000000..e69de29
diff --git a/ttsim/docs/images/usage/Ball-m.png b/ttsim/docs/images/usage/Ball-m.png
new file mode 100644
index 0000000..410e18c
Binary files /dev/null and b/ttsim/docs/images/usage/Ball-m.png differ
diff --git a/ttsim/docs/images/usage/Bit-t.png b/ttsim/docs/images/usage/Bit-t.png
new file mode 100644
index 0000000..5d41028
Binary files /dev/null and b/ttsim/docs/images/usage/Bit-t.png differ
diff --git a/ttsim/docs/images/usage/Crossover-t.png b/ttsim/docs/images/usage/Crossover-t.png
new file mode 100644
index 0000000..80c93ac
Binary files /dev/null and b/ttsim/docs/images/usage/Crossover-t.png differ
diff --git a/ttsim/docs/images/usage/Drop-t.png b/ttsim/docs/images/usage/Drop-t.png
new file mode 100644
index 0000000..191eb8f
Binary files /dev/null and b/ttsim/docs/images/usage/Drop-t.png differ
diff --git a/ttsim/docs/images/usage/Gear-t.png b/ttsim/docs/images/usage/Gear-t.png
new file mode 100644
index 0000000..7e7b0d2
Binary files /dev/null and b/ttsim/docs/images/usage/Gear-t.png differ
diff --git a/ttsim/docs/images/usage/Gearbit-t.png b/ttsim/docs/images/usage/Gearbit-t.png
new file mode 100644
index 0000000..761aaec
Binary files /dev/null and b/ttsim/docs/images/usage/Gearbit-t.png differ
diff --git a/ttsim/docs/images/usage/Interceptor-t.png b/ttsim/docs/images/usage/Interceptor-t.png
new file mode 100644
index 0000000..aae29fa
Binary files /dev/null and b/ttsim/docs/images/usage/Interceptor-t.png differ
diff --git a/ttsim/docs/images/usage/PartLocation-t.png b/ttsim/docs/images/usage/PartLocation-t.png
new file mode 100644
index 0000000..5eb3545
Binary files /dev/null and b/ttsim/docs/images/usage/PartLocation-t.png differ
diff --git a/ttsim/docs/images/usage/Ramp-t.png b/ttsim/docs/images/usage/Ramp-t.png
new file mode 100644
index 0000000..9467850
Binary files /dev/null and b/ttsim/docs/images/usage/Ramp-t.png differ
diff --git a/ttsim/docs/images/usage/Side-t.png b/ttsim/docs/images/usage/Side-t.png
new file mode 100644
index 0000000..fcd3516
Binary files /dev/null and b/ttsim/docs/images/usage/Side-t.png differ
diff --git a/ttsim/docs/images/usage/Slope-t.png b/ttsim/docs/images/usage/Slope-t.png
new file mode 100644
index 0000000..2d2ea8b
Binary files /dev/null and b/ttsim/docs/images/usage/Slope-t.png differ
diff --git a/ttsim/docs/images/usage/Turnstile-t.png b/ttsim/docs/images/usage/Turnstile-t.png
new file mode 100644
index 0000000..7c5b2c2
Binary files /dev/null and b/ttsim/docs/images/usage/Turnstile-t.png differ
diff --git a/ttsim/docs/images/usage/board-clear.png b/ttsim/docs/images/usage/board-clear.png
new file mode 100644
index 0000000..2df4903
Binary files /dev/null and b/ttsim/docs/images/usage/board-clear.png differ
diff --git a/ttsim/docs/images/usage/board-drawer.png b/ttsim/docs/images/usage/board-drawer.png
new file mode 100644
index 0000000..3e820ff
Binary files /dev/null and b/ttsim/docs/images/usage/board-drawer.png differ
diff --git a/ttsim/docs/images/usage/board-large.png b/ttsim/docs/images/usage/board-large.png
new file mode 100644
index 0000000..7f871e5
Binary files /dev/null and b/ttsim/docs/images/usage/board-large.png differ
diff --git a/ttsim/docs/images/usage/board-medium.png b/ttsim/docs/images/usage/board-medium.png
new file mode 100644
index 0000000..7d50e13
Binary files /dev/null and b/ttsim/docs/images/usage/board-medium.png differ
diff --git a/ttsim/docs/images/usage/board-small.png b/ttsim/docs/images/usage/board-small.png
new file mode 100644
index 0000000..c34721f
Binary files /dev/null and b/ttsim/docs/images/usage/board-small.png differ
diff --git a/ttsim/docs/images/usage/clear-balls.png b/ttsim/docs/images/usage/clear-balls.png
new file mode 100644
index 0000000..7e38e71
Binary files /dev/null and b/ttsim/docs/images/usage/clear-balls.png differ
diff --git a/ttsim/docs/images/usage/download.png b/ttsim/docs/images/usage/download.png
new file mode 100644
index 0000000..4c1b3bf
Binary files /dev/null and b/ttsim/docs/images/usage/download.png differ
diff --git a/ttsim/docs/images/usage/faster.png b/ttsim/docs/images/usage/faster.png
new file mode 100644
index 0000000..baceed6
Binary files /dev/null and b/ttsim/docs/images/usage/faster.png differ
diff --git a/ttsim/docs/images/usage/hand.png b/ttsim/docs/images/usage/hand.png
new file mode 100644
index 0000000..99b5bb0
Binary files /dev/null and b/ttsim/docs/images/usage/hand.png differ
diff --git a/ttsim/docs/images/usage/heart.png b/ttsim/docs/images/usage/heart.png
new file mode 100644
index 0000000..2adbf16
Binary files /dev/null and b/ttsim/docs/images/usage/heart.png differ
diff --git a/ttsim/docs/images/usage/help.png b/ttsim/docs/images/usage/help.png
new file mode 100644
index 0000000..131b1b7
Binary files /dev/null and b/ttsim/docs/images/usage/help.png differ
diff --git a/ttsim/docs/images/usage/octocat.png b/ttsim/docs/images/usage/octocat.png
new file mode 100644
index 0000000..1ff747a
Binary files /dev/null and b/ttsim/docs/images/usage/octocat.png differ
diff --git a/ttsim/docs/images/usage/return.png b/ttsim/docs/images/usage/return.png
new file mode 100644
index 0000000..4c440df
Binary files /dev/null and b/ttsim/docs/images/usage/return.png differ
diff --git a/ttsim/docs/images/usage/schematic.png b/ttsim/docs/images/usage/schematic.png
new file mode 100644
index 0000000..939e9dc
Binary files /dev/null and b/ttsim/docs/images/usage/schematic.png differ
diff --git a/ttsim/docs/images/usage/slower.png b/ttsim/docs/images/usage/slower.png
new file mode 100644
index 0000000..2df5ff8
Binary files /dev/null and b/ttsim/docs/images/usage/slower.png differ
diff --git a/ttsim/docs/images/usage/upload.png b/ttsim/docs/images/usage/upload.png
new file mode 100644
index 0000000..96ff06f
Binary files /dev/null and b/ttsim/docs/images/usage/upload.png differ
diff --git a/ttsim/docs/images/usage/zoomin.png b/ttsim/docs/images/usage/zoomin.png
new file mode 100644
index 0000000..e44aa21
Binary files /dev/null and b/ttsim/docs/images/usage/zoomin.png differ
diff --git a/ttsim/docs/images/usage/zoomout.png b/ttsim/docs/images/usage/zoomout.png
new file mode 100644
index 0000000..c959062
Binary files /dev/null and b/ttsim/docs/images/usage/zoomout.png differ
diff --git a/ttsim/docs/images/usage/zoomtofit.png b/ttsim/docs/images/usage/zoomtofit.png
new file mode 100644
index 0000000..11ef3cb
Binary files /dev/null and b/ttsim/docs/images/usage/zoomtofit.png differ
diff --git a/ttsim/docs/index.html b/ttsim/docs/index.html
new file mode 100644
index 0000000..9b9d0e4
--- /dev/null
+++ b/ttsim/docs/index.html
@@ -0,0 +1,58 @@
+
+
+ Turing Tumble Simulator
+
+
+
+
+ 0&&r.rotateAbout(s.position,n,e.position,s.position)}},o.setVelocity=function(e,t){e.positionPrev.x=e.position.x-t.x,e.positionPrev.y=e.position.y-t.y,
+e.velocity.x=t.x,e.velocity.y=t.y,e.speed=r.magnitude(e.velocity)},o.setAngularVelocity=function(e,t){e.anglePrev=e.angle-t,e.angularVelocity=t,e.angularSpeed=Math.abs(e.angularVelocity)},o.translate=function(e,t){o.setPosition(e,r.add(e.position,t))},o.rotate=function(e,t,n){if(n){var i=Math.cos(t),r=Math.sin(t),s=e.position.x-n.x,a=e.position.y-n.y;o.setPosition(e,{x:n.x+(s*i-a*r),y:n.y+(s*r+a*i)}),o.setAngle(e,e.angle+t)}else o.setAngle(e,e.angle+t)},o.scale=function(e,t,n,r){var s=0,a=0;r=r||e.position;for(var d=0;d0&&(s+=u.area,a+=u.inertia),u.position.x=r.x+(u.position.x-r.x)*t,u.position.y=r.y+(u.position.y-r.y)*n,l.update(u.bounds,u.vertices,e.velocity)
+}e.parts.length>1&&(e.area=s,e.isStatic||(o.setMass(e,e.density*s),o.setInertia(e,a))),e.circleRadius&&(t===n?e.circleRadius*=t:e.circleRadius=null)},o.update=function(e,t,n,o){var s=Math.pow(t*n*e.timeScale,2),a=1-e.frictionAir*n*e.timeScale,d=e.position.x-e.positionPrev.x,u=e.position.y-e.positionPrev.y;e.velocity.x=d*a*o+e.force.x/e.mass*s,e.velocity.y=u*a*o+e.force.y/e.mass*s,e.positionPrev.x=e.position.x,e.positionPrev.y=e.position.y,e.position.x+=e.velocity.x,e.position.y+=e.velocity.y,e.angularVelocity=(e.angle-e.anglePrev)*a*o+e.torque/e.inertia*s,e.anglePrev=e.angle,e.angle+=e.angularVelocity,e.speed=r.magnitude(e.velocity),e.angularSpeed=Math.abs(e.angularVelocity);for(var p=0;p0&&(f.position.x+=e.velocity.x,f.position.y+=e.velocity.y),0!==e.angularVelocity&&(i.rotate(f.vertices,e.angularVelocity,e.position),c.rotate(f.axes,e.angularVelocity),
+p>0&&r.rotateAbout(f.position,e.angularVelocity,e.position,f.position)),l.update(f.bounds,f.vertices,e.velocity)}},o.applyForce=function(e,t,n){e.force.x+=n.x,e.force.y+=n.y;var o={x:t.x-e.position.x,y:t.y-e.position.y};e.torque+=o.x*n.y-o.y*n.x},o._totalProperties=function(e){for(var t={mass:0,area:0,inertia:0,centre:{x:0,y:0}},n=1===e.parts.length?0:1;n1?1:0;u1?1:0;f0:0!=(e.mask&t.category)&&0!=(t.mask&e.category)}}()},{"../geometry/Bounds":26,"./Pair":7,"./SAT":11}],6:[function(e,t,n){var o={};t.exports=o;var i=e("./Pair"),r=e("./Detector"),s=e("../core/Common");!function(){o.create=function(e){var t={controller:o,detector:r.collisions,buckets:{},pairs:{},pairsList:[],bucketWidth:48,bucketHeight:48};return s.extend(t,e)},o.update=function(e,t,n,i){
+var r,s,a,l,c,d=n.world,u=e.buckets,p=!1;for(r=0;rd.bounds.max.x||f.bounds.max.yd.bounds.max.y)){var m=o._getRegion(e,f);if(!f.region||m.id!==f.region.id||i){f.region&&!i||(f.region=m);var v=o._regionUnion(m,f.region);for(s=v.startCol;s<=v.endCol;s++)for(a=v.startRow;a<=v.endRow;a++){c=o._getBucketId(s,a),l=u[c];var y=s>=m.startCol&&s<=m.endCol&&a>=m.startRow&&a<=m.endRow,g=s>=f.region.startCol&&s<=f.region.endCol&&a>=f.region.startRow&&a<=f.region.endRow;!y&&g&&g&&l&&o._bucketRemoveBody(e,l,f),(f.region===m||y&&!g||i)&&(l||(l=o._createBucket(u,c)),o._bucketAddBody(e,l,f))}f.region=m,p=!0}}}p&&(e.pairsList=o._createActivePairsList(e))},o.clear=function(e){e.buckets={},e.pairs={},e.pairsList=[]},o._regionUnion=function(e,t){var n=Math.min(e.startCol,t.startCol),i=Math.max(e.endCol,t.endCol),r=Math.min(e.startRow,t.startRow),s=Math.max(e.endRow,t.endRow)
+;return o._createRegion(n,i,r,s)},o._getRegion=function(e,t){var n=t.bounds,i=Math.floor(n.min.x/e.bucketWidth),r=Math.floor(n.max.x/e.bucketWidth),s=Math.floor(n.min.y/e.bucketHeight),a=Math.floor(n.max.y/e.bucketHeight);return o._createRegion(i,r,s,a)},o._createRegion=function(e,t,n,o){return{id:e+","+t+","+n+","+o,startCol:e,endCol:t,startRow:n,endRow:o}},o._getBucketId=function(e,t){return"C"+e+"R"+t},o._createBucket=function(e,t){return e[t]=[]},o._bucketAddBody=function(e,t,n){for(var o=0;o0?o.push(n):delete e.pairs[t[i]];return o}}()},{"../core/Common":14,"./Detector":5,"./Pair":7}],
+7:[function(e,t,n){var o={};t.exports=o;var i=e("./Contact");!function(){o.create=function(e,t){var n=e.bodyA,i=e.bodyB,r=e.parentA,s=e.parentB,a={id:o.id(n,i),bodyA:n,bodyB:i,contacts:{},activeContacts:[],separation:0,isActive:!0,isSensor:n.isSensor||i.isSensor,timeCreated:t,timeUpdated:t,inverseMass:r.inverseMass+s.inverseMass,friction:Math.min(r.friction,s.friction),frictionStatic:Math.max(r.frictionStatic,s.frictionStatic),restitution:Math.max(r.restitution,s.restitution),slop:Math.max(r.slop,s.slop)};return o.update(a,e,t),a},o.update=function(e,t,n){var r=e.contacts,s=t.supports,a=e.activeContacts,l=t.parentA,c=t.parentB;if(e.collision=t,e.inverseMass=l.inverseMass+c.inverseMass,e.friction=Math.min(l.friction,c.friction),e.frictionStatic=Math.max(l.frictionStatic,c.frictionStatic),e.restitution=Math.max(l.restitution,c.restitution),e.slop=Math.max(l.slop,c.slop),a.length=0,t.collided){for(var d=0;do._pairMaxIdleLife&&c.push(s);for(s=0;sf.friction*f.frictionStatic*E*n&&(F=T,L=s.clamp(f.friction*R*n,-F,F));var O=r.cross(A,g),q=r.cross(P,g),W=b/(v.inverseMass+y.inverseMass+v.inverseInertia*O*O+y.inverseInertia*q*q);if(V*=W,L*=W,I<0&&I*I>o._restingThresh*n)S.normalImpulse=0;else{var D=S.normalImpulse;S.normalImpulse=Math.min(S.normalImpulse+V,0),V=S.normalImpulse-D}if(_*_>o._restingThreshTangent*n)S.tangentImpulse=0;else{var N=S.tangentImpulse;S.tangentImpulse=s.clamp(S.tangentImpulse+L,-F,F),L=S.tangentImpulse-N}i.x=g.x*V+x.x*L,i.y=g.y*V+x.y*L,v.isStatic||v.isSleeping||(v.positionPrev.x+=i.x*v.inverseMass,v.positionPrev.y+=i.y*v.inverseMass,
+v.anglePrev+=r.cross(A,i)*v.inverseInertia),y.isStatic||y.isSleeping||(y.positionPrev.x-=i.x*y.inverseMass,y.positionPrev.y-=i.y*y.inverseMass,y.anglePrev-=r.cross(P,i)*y.inverseInertia)}}}}}()},{"../core/Common":14,"../geometry/Bounds":26,"../geometry/Vector":28,"../geometry/Vertices":29}],11:[function(e,t,n){var o={};t.exports=o;var i=e("../geometry/Vertices"),r=e("../geometry/Vector");!function(){o.collides=function(e,t,n){var s,a,l,c,d=!1;if(n){var u=e.parent,p=t.parent,f=u.speed*u.speed+u.angularSpeed*u.angularSpeed+p.speed*p.speed+p.angularSpeed*p.angularSpeed;d=n&&n.collided&&f<.2,c=n}else c={collided:!1,bodyA:e,bodyB:t};if(n&&d){var m=c.axisBody,v=m===e?t:e,y=[m.axes[n.axisNumber]];if(l=o._overlapAxes(m.vertices,v.vertices,y),c.reused=!0,l.overlap<=0)return c.collided=!1,c}else{if(s=o._overlapAxes(e.vertices,t.vertices,e.axes),s.overlap<=0)return c.collided=!1,c;if(a=o._overlapAxes(t.vertices,e.vertices,t.axes),a.overlap<=0)return c.collided=!1,c;s.overlapi?i=a:a=0?s.index-1:d.length-1],c.x=i.x-u.x,c.y=i.y-u.y,l=-r.dot(n,c),a=i,i=d[(s.index+1)%d.length],c.x=i.x-u.x,c.y=i.y-u.y,o=-r.dot(n,c),o0?1:.7),t.damping=t.damping||0,t.angularStiffness=t.angularStiffness||0,t.angleA=t.bodyA?t.bodyA.angle:t.angleA,t.angleB=t.bodyB?t.bodyB.angle:t.angleB,t.plugin={};var s={visible:!0,lineWidth:2,strokeStyle:"#ffffff",type:"line",anchors:!0};return 0===t.length&&t.stiffness>.1?(s.type="pin",s.anchors=!1):t.stiffness<.9&&(s.type="spring"),t.render=c.extend(s,t.render),t},o.preSolveAll=function(e){for(var t=0;t0&&(u.position.x+=c.x,u.position.y+=c.y),0!==c.angle&&(i.rotate(u.vertices,c.angle,n.position),l.rotate(u.axes,c.angle),
+d>0&&r.rotateAbout(u.position,c.angle,n.position,u.position)),a.update(u.bounds,u.vertices,n.velocity)}c.angle*=o._warming,c.x*=o._warming,c.y*=o._warming}}}}()},{"../core/Common":14,"../core/Sleeping":22,"../geometry/Axes":25,"../geometry/Bounds":26,"../geometry/Vector":28,"../geometry/Vertices":29}],13:[function(e,t,n){var o={};t.exports=o;var i=e("../geometry/Vertices"),r=e("../core/Sleeping"),s=e("../core/Mouse"),a=e("../core/Events"),l=e("../collision/Detector"),c=e("./Constraint"),d=e("../body/Composite"),u=e("../core/Common"),p=e("../geometry/Bounds");!function(){o.create=function(e,t){var n=(e?e.mouse:null)||(t?t.mouse:null);n||(e&&e.render&&e.render.canvas?n=s.create(e.render.canvas):t&&t.element?n=s.create(t.element):(n=s.create(),u.warn("MouseConstraint.create: options.mouse was undefined, options.element was undefined, may not function as expected")));var i=c.create({label:"Mouse Constraint",pointA:n.position,pointB:{x:0,y:0},length:.01,stiffness:.1,angularStiffness:1,
+render:{strokeStyle:"#90EE90",lineWidth:3}}),r={type:"mouseConstraint",mouse:n,element:null,body:null,constraint:i,collisionFilter:{category:1,mask:4294967295,group:0}},l=u.extend(r,t);return a.on(e,"beforeUpdate",function(){var t=d.allBodies(e.world);o.update(l,t),o._triggerEvents(l)}),l},o.update=function(e,t){var n=e.mouse,o=e.constraint,s=e.body;if(0===n.button){if(o.bodyB)r.set(o.bodyB,!1),o.pointA=n.position;else for(var c=0;c1?1:0;d0;t--){var n=Math.floor(o.random()*(t+1)),i=e[t];e[t]=e[n],e[n]=i}return e},o.choose=function(e){return e[Math.floor(o.random()*e.length)]},o.isElement=function(e){return"undefined"!=typeof HTMLElement?e instanceof HTMLElement:!!(e&&e.nodeType&&e.nodeName)},o.isArray=function(e){return"[object Array]"===Object.prototype.toString.call(e)},o.isFunction=function(e){return"function"==typeof e},o.isPlainObject=function(e){return"object"==typeof e&&e.constructor===Object},o.isString=function(e){return"[object String]"===toString.call(e)},o.clamp=function(e,t,n){return en?n:e},o.sign=function(e){return e<0?-1:1},o.now=function(){
+if(window.performance){if(window.performance.now)return window.performance.now();if(window.performance.webkitNow)return window.performance.webkitNow()}return new Date-o._nowStartTime},o.random=function(e,n){return e=void 0!==e?e:0,n=void 0!==n?n:1,e+t()*(n-e)};var t=function(){return o._seed=(9301*o._seed+49297)%233280,o._seed/233280};o.colorToNumber=function(e){return e=e.replace("#",""),3==e.length&&(e=e.charAt(0)+e.charAt(0)+e.charAt(1)+e.charAt(1)+e.charAt(2)+e.charAt(2)),parseInt(e,16)},o.logLevel=1,o.log=function(){console&&o.logLevel>0&&o.logLevel<=3&&console.log.apply(console,["matter-js:"].concat(Array.prototype.slice.call(arguments)))},o.info=function(){console&&o.logLevel>0&&o.logLevel<=2&&console.info.apply(console,["matter-js:"].concat(Array.prototype.slice.call(arguments)))},o.warn=function(){console&&o.logLevel>0&&o.logLevel<=3&&console.warn.apply(console,["matter-js:"].concat(Array.prototype.slice.call(arguments)))},o.nextId=function(){return o._nextId++},
+o.indexOf=function(e,t){if(e.indexOf)return e.indexOf(t);for(var n=0;n0&&d.trigger(e,"collisionStart",{pairs:h.collisionStart}),s.preSolvePosition(h.list),i=0;i0&&d.trigger(e,"collisionActive",{pairs:h.collisionActive}),h.collisionEnd.length>0&&d.trigger(e,"collisionEnd",{pairs:h.collisionEnd}),o._bodiesClearForces(y),d.trigger(e,"afterUpdate",v),e},o.merge=function(e,t){if(f.extend(e,t),t.world){e.world=t.world,o.clear(e);for(var n=u.allBodies(e.world),i=0;ir?(i.warn("Plugin.register:",o.toString(t),"was upgraded to",o.toString(e)),o._registry[e.name]=e):n-1},o.isFor=function(e,t){var n=e.for&&o.dependencyParse(e.for)
+;return!e.for||t.name===n.name&&o.versionSatisfies(t.version,n.range)},o.use=function(e,t){if(e.uses=(e.uses||[]).concat(t||[]),0===e.uses.length)return void i.warn("Plugin.use:",o.toString(e),"does not specify any dependencies to install.");for(var n=o.dependencies(e),r=i.topologicalSort(n),s=[],a=0;a0&&i.info(s.join(" "))},o.dependencies=function(e,t){var n=o.dependencyParse(e),r=n.name;if(t=t||{},!(r in t)){e=o.resolve(e)||e,t[r]=i.map(e.uses||[],function(t){o.isPlugin(t)&&o.register(t);var r=o.dependencyParse(t),s=o.resolve(t)
+;return s&&!o.versionSatisfies(s.version,r.range)?(i.warn("Plugin.dependencies:",o.toString(s),"does not satisfy",o.toString(r),"used by",o.toString(n)+"."),s._warned=!0,e._warned=!0):s||(i.warn("Plugin.dependencies:",o.toString(t),"used by",o.toString(n),"could not be resolved."),e._warned=!0),r.name});for(var s=0;s=i[2];if("^"===n.operator)return i[0]>0?s[0]===i[0]&&r.number>=n.number:i[1]>0?s[1]===i[1]&&s[2]>=i[2]:s[2]===i[2]}return e===t||"*"===e}}()},{"./Common":14}],21:[function(e,t,n){var o={};t.exports=o;var i=e("./Events"),r=e("./Engine"),s=e("./Common");!function(){var e,t;if("undefined"!=typeof window&&(e=window.requestAnimationFrame||window.webkitRequestAnimationFrame||window.mozRequestAnimationFrame||window.msRequestAnimationFrame,t=window.cancelAnimationFrame||window.mozCancelAnimationFrame||window.webkitCancelAnimationFrame||window.msCancelAnimationFrame),!e){var n;e=function(e){n=setTimeout(function(){e(s.now())},1e3/60)},t=function(){clearTimeout(n)}}o.create=function(e){var t={fps:60,correction:1,deltaSampleSize:60,
+counterTimestamp:0,frameCounter:0,deltaHistory:[],timePrev:null,timeScalePrev:1,frameRequestId:null,isFixed:!1,enabled:!0},n=s.extend(t,e);return n.delta=n.delta||1e3/n.fps,n.deltaMin=n.deltaMin||1e3/n.fps,n.deltaMax=n.deltaMax||1e3/(.5*n.fps),n.fps=1e3/n.delta,n},o.run=function(t,n){return void 0!==t.positionIterations&&(n=t,t=o.create()),function i(r){t.frameRequestId=e(i),r&&t.enabled&&o.tick(t,n,r)}(),t},o.tick=function(e,t,n){var o,s=t.timing,a=1,l={timestamp:s.timestamp};i.trigger(e,"beforeTick",l),i.trigger(t,"beforeTick",l),e.isFixed?o=e.delta:(o=n-e.timePrev||e.delta,e.timePrev=n,e.deltaHistory.push(o),e.deltaHistory=e.deltaHistory.slice(-e.deltaSampleSize),o=Math.min.apply(null,e.deltaHistory),o=oe.deltaMax?e.deltaMax:o,a=o/e.delta,e.delta=o),0!==e.timeScalePrev&&(a*=s.timeScale/e.timeScalePrev),0===s.timeScale&&(a=0),e.timeScalePrev=s.timeScale,e.correction=a,e.frameCounter+=1,
+n-e.counterTimestamp>=1e3&&(e.fps=e.frameCounter*((n-e.counterTimestamp)/1e3),e.counterTimestamp=n,e.frameCounter=0),i.trigger(e,"tick",l),i.trigger(t,"tick",l),t.world.isModified&&t.render&&t.render.controller&&t.render.controller.clear&&t.render.controller.clear(t.render),i.trigger(e,"beforeUpdate",l),r.update(t,o,a),i.trigger(e,"afterUpdate",l),t.render&&t.render.controller&&(i.trigger(e,"beforeRender",l),i.trigger(t,"beforeRender",l),t.render.controller.world(t.render),i.trigger(e,"afterRender",l),i.trigger(t,"afterRender",l)),i.trigger(e,"afterTick",l),i.trigger(t,"afterTick",l)},o.stop=function(e){t(e.frameRequestId)},o.start=function(e,t){o.run(e,t)}}()},{"./Common":14,"./Engine":15,"./Events":16}],22:[function(e,t,n){var o={};t.exports=o;var i=e("./Events");!function(){o._motionWakeThreshold=.18,o._motionSleepThreshold=.08,o._minBias=.9,o.update=function(e,t){for(var n=t*t*t,i=0;i0&&r.motion=r.sleepThreshold&&o.set(r,!0)):r.sleepCounter>0&&(r.sleepCounter-=1)}else o.set(r,!1)}},o.afterCollisions=function(e,t){for(var n=t*t*t,i=0;io._motionWakeThreshold*n&&o.set(c,!1)}}}},o.set=function(e,t){var n=e.isSleeping;t?(e.isSleeping=!0,e.sleepCounter=e.sleepThreshold,e.positionImpulse.x=0,e.positionImpulse.y=0,e.positionPrev.x=e.position.x,e.positionPrev.y=e.position.y,e.anglePrev=e.angle,e.speed=0,e.angularSpeed=0,e.motion=0,n||i.trigger(e,"sleepStart")):(e.isSleeping=!1,e.sleepCounter=0,n&&i.trigger(e,"sleepEnd"))}}()},{
+"./Events":16}],23:[function(e,t,n){var o={};t.exports=o;var i,r=e("../geometry/Vertices"),s=e("../core/Common"),a=e("../body/Body"),l=e("../geometry/Bounds"),c=e("../geometry/Vector");!function(){o.rectangle=function(e,t,n,o,i){i=i||{};var l={label:"Rectangle Body",position:{x:e,y:t},vertices:r.fromPath("L 0 0 L "+n+" 0 L "+n+" "+o+" L 0 "+o)};if(i.chamfer){var c=i.chamfer;l.vertices=r.chamfer(l.vertices,c.radius,c.quality,c.qualityMin,c.qualityMax),delete i.chamfer}return a.create(s.extend({},l,i))},o.trapezoid=function(e,t,n,o,i,l){l=l||{},i*=.5;var c,d=(1-2*i)*n,u=n*i,p=u+d,f=p+u;c=i<.5?"L 0 0 L "+u+" "+-o+" L "+p+" "+-o+" L "+f+" 0":"L 0 0 L "+p+" "+-o+" L "+f+" 0";var m={label:"Trapezoid Body",position:{x:e,y:t},vertices:r.fromPath(c)};if(l.chamfer){var v=l.chamfer;m.vertices=r.chamfer(m.vertices,v.radius,v.quality,v.qualityMin,v.qualityMax),delete l.chamfer}return a.create(s.extend({},m,l))},o.circle=function(e,t,n,i,r){i=i||{};var a={label:"Circle Body",circleRadius:n};r=r||25
+;var l=Math.ceil(Math.max(10,Math.min(r,n)));return l%2==1&&(l+=1),o.polygon(e,t,l,n,s.extend({},a,i))},o.polygon=function(e,t,n,i,l){if(l=l||{},n<3)return o.circle(e,t,i,l);for(var c=2*Math.PI/n,d="",u=.5*c,p=0;p0&&r.area(P)1?(f=a.create(s.extend({parts:m.slice(0)},o)),a.setPosition(f,{x:e,y:t}),f):m[0]}}()},{"../body/Body":1,"../core/Common":14,"../geometry/Bounds":26,"../geometry/Vector":28,"../geometry/Vertices":29}],24:[function(e,t,n){var o={};t.exports=o
+;var i=e("../body/Composite"),r=e("../constraint/Constraint"),s=e("../core/Common"),a=e("../body/Body"),l=e("./Bodies");!function(){o.stack=function(e,t,n,o,r,s,l){for(var c,d=i.create({label:"Stack"}),u=e,p=t,f=0,m=0;mv&&(v=x),a.translate(g,{x:.5*h,y:.5*x}),u=g.bounds.max.x+r,i.addBody(d,g),c=g,f+=1}else u+=r}p+=v+s,u=e}return d},o.chain=function(e,t,n,o,a,l){for(var c=e.bodies,d=1;d0)for(c=0;c0&&(p=f[c-1+(l-1)*t],i.addConstraint(e,r.create(s.extend({bodyA:p,bodyB:u},a)))),o&&cp)){c=p-c;var m=c,v=n-1-c;if(!(sv)){1===u&&a.translate(d,{x:(s+(n%2==1?1:-1))*f,y:0});return l(e+(d?s*f:0)+s*r,o,s,c,d,u)}}})},o.newtonsCradle=function(e,t,n,o,s){for(var a=i.create({label:"Newtons Cradle"}),c=0;ce.max.x&&(e.max.x=i.x),i.xe.max.y&&(e.max.y=i.y),i.y0?e.max.x+=n.x:e.min.x+=n.x,n.y>0?e.max.y+=n.y:e.min.y+=n.y)},o.contains=function(e,t){return t.x>=e.min.x&&t.x<=e.max.x&&t.y>=e.min.y&&t.y<=e.max.y},o.overlaps=function(e,t){return e.min.x<=t.max.x&&e.max.x>=t.min.x&&e.max.y>=t.min.y&&e.min.y<=t.max.y},o.translate=function(e,t){e.min.x+=t.x,
+e.max.x+=t.x,e.min.y+=t.y,e.max.y+=t.y},o.shift=function(e,t){var n=e.max.x-e.min.x,o=e.max.y-e.min.y;e.min.x=t.x,e.max.x=t.x+n,e.min.y=t.y,e.max.y=t.y+o}}()},{}],27:[function(e,t,n){var o={};t.exports=o;var i=(e("../geometry/Bounds"),e("../core/Common"));!function(){o.pathToVertices=function(e,t){"undefined"==typeof window||"SVGPathSeg"in window||i.warn("Svg.pathToVertices: SVGPathSeg not defined, a polyfill is required.");var n,r,s,a,l,c,d,u,p,f,m,v,y=[],g=0,x=0,h=0;t=t||15;var b=function(e,t,n){var o=n%2==1&&n>1;if(!p||e!=p.x||t!=p.y){p&&o?(m=p.x,v=p.y):(m=0,v=0);var i={x:m+e,y:v+t};!o&&p||(p=i),y.push(i),x=m+e,h=v+t}},w=function(e){var t=e.pathSegTypeAsLetter.toUpperCase();if("Z"!==t){switch(t){case"M":case"L":case"T":case"C":case"S":case"Q":x=e.x,h=e.y;break;case"H":x=e.x;break;case"V":h=e.y}b(x,h,e.pathSegType)}};for(o._svgPathToAbsolute(e),s=e.getTotalLength(),c=[],n=0;n0)return!1}return!0},o.scale=function(e,t,n,r){if(1===t&&1===n)return e;r=r||o.centre(e);for(var s,a,l=0;l=0?l-1:e.length-1],d=e[l],u=e[(l+1)%e.length],p=t[l0&&(r|=2),3===r)return!1;return 0!==r||null},o.hull=function(e){var t,n,o=[],r=[];for(e=e.slice(0),e.sort(function(e,t){var n=e.x-t.x;return 0!==n?n:e.y-t.y}),n=0;n=2&&i.cross3(r[r.length-2],r[r.length-1],t)<=0;)r.pop();r.push(t)}for(n=e.length-1;n>=0;n-=1){for(t=e[n];o.length>=2&&i.cross3(o[o.length-2],o[o.length-1],t)<=0;)o.pop();o.push(t)}return o.pop(),r.pop(),o.concat(r)}}()},{"../core/Common":14,"../geometry/Vector":28}],30:[function(e,t,n){var o=t.exports=e("../core/Matter");o.Body=e("../body/Body"),o.Composite=e("../body/Composite"),
+o.World=e("../body/World"),o.Contact=e("../collision/Contact"),o.Detector=e("../collision/Detector"),o.Grid=e("../collision/Grid"),o.Pairs=e("../collision/Pairs"),o.Pair=e("../collision/Pair"),o.Query=e("../collision/Query"),o.Resolver=e("../collision/Resolver"),o.SAT=e("../collision/SAT"),o.Constraint=e("../constraint/Constraint"),o.MouseConstraint=e("../constraint/MouseConstraint"),o.Common=e("../core/Common"),o.Engine=e("../core/Engine"),o.Events=e("../core/Events"),o.Mouse=e("../core/Mouse"),o.Runner=e("../core/Runner"),o.Sleeping=e("../core/Sleeping"),o.Plugin=e("../core/Plugin"),o.Bodies=e("../factory/Bodies"),o.Composites=e("../factory/Composites"),o.Axes=e("../geometry/Axes"),o.Bounds=e("../geometry/Bounds"),o.Svg=e("../geometry/Svg"),o.Vector=e("../geometry/Vector"),o.Vertices=e("../geometry/Vertices"),o.Render=e("../render/Render"),o.RenderPixi=e("../render/RenderPixi"),o.World.add=o.Composite.add,o.World.remove=o.Composite.remove,
+o.World.addComposite=o.Composite.addComposite,o.World.addBody=o.Composite.addBody,o.World.addConstraint=o.Composite.addConstraint,o.World.clear=o.Composite.clear,o.Engine.run=o.Runner.run},{"../body/Body":1,"../body/Composite":2,"../body/World":3,"../collision/Contact":4,"../collision/Detector":5,"../collision/Grid":6,"../collision/Pair":7,"../collision/Pairs":8,"../collision/Query":9,"../collision/Resolver":10,"../collision/SAT":11,"../constraint/Constraint":12,"../constraint/MouseConstraint":13,"../core/Common":14,"../core/Engine":15,"../core/Events":16,"../core/Matter":17,"../core/Metrics":18,"../core/Mouse":19,"../core/Plugin":20,"../core/Runner":21,"../core/Sleeping":22,"../factory/Bodies":23,"../factory/Composites":24,"../geometry/Axes":25,"../geometry/Bounds":26,"../geometry/Svg":27,"../geometry/Vector":28,"../geometry/Vertices":29,"../render/Render":31,"../render/RenderPixi":32}],31:[function(e,t,n){var o={};t.exports=o
+;var i=e("../core/Common"),r=e("../body/Composite"),s=e("../geometry/Bounds"),a=e("../core/Events"),l=e("../collision/Grid"),c=e("../geometry/Vector"),d=e("../core/Mouse");!function(){var e,t;"undefined"!=typeof window&&(e=window.requestAnimationFrame||window.webkitRequestAnimationFrame||window.mozRequestAnimationFrame||window.msRequestAnimationFrame||function(e){window.setTimeout(function(){e(i.now())},1e3/60)},t=window.cancelAnimationFrame||window.mozCancelAnimationFrame||window.webkitCancelAnimationFrame||window.msCancelAnimationFrame),o.create=function(e){var t={controller:o,engine:null,element:null,canvas:null,mouse:null,frameRequestId:null,options:{width:800,height:600,pixelRatio:1,background:"#18181d",wireframeBackground:"#0f0f13",hasBounds:!!e.bounds,enabled:!0,wireframes:!0,showSleeping:!0,showDebug:!1,showBroadphase:!1,showBounds:!1,showVelocity:!1,showCollisions:!1,showSeparations:!1,showAxes:!1,showPositions:!1,showAngleIndicator:!1,showIds:!1,showShadows:!1,
+showVertexNumbers:!1,showConvexHulls:!1,showInternalEdges:!1,showMousePosition:!1}},r=i.extend(t,e);return r.canvas&&(r.canvas.width=r.options.width||r.canvas.width,r.canvas.height=r.options.height||r.canvas.height),r.mouse=e.mouse,r.engine=e.engine,r.canvas=r.canvas||n(r.options.width,r.options.height),r.context=r.canvas.getContext("2d"),r.textures={},r.bounds=r.bounds||{min:{x:0,y:0},max:{x:r.canvas.width,y:r.canvas.height}},1!==r.options.pixelRatio&&o.setPixelRatio(r,r.options.pixelRatio),i.isElement(r.element)?r.element.appendChild(r.canvas):r.canvas.parentNode||i.log("Render.create: options.element was undefined, render.canvas was created but not appended","warn"),r},o.run=function(t){!function n(i){t.frameRequestId=e(n),o.world(t)}()},o.stop=function(e){t(e.frameRequestId)},o.setPixelRatio=function(e,t){var n=e.options,o=e.canvas;"auto"===t&&(t=u(o)),n.pixelRatio=t,o.setAttribute("data-pixel-ratio",t),o.width=n.width*t,o.height=n.height*t,o.style.width=n.width+"px",
+o.style.height=n.height+"px",e.context.scale(t,t)},o.lookAt=function(e,t,n,o){o=void 0===o||o,t=i.isArray(t)?t:[t],n=n||{x:0,y:0};for(var r={min:{x:1/0,y:1/0},max:{x:-1/0,y:-1/0}},s=0;sr.max.x&&(r.max.x=c.x),l.yr.max.y&&(r.max.y=c.y))}var u=r.max.x-r.min.x+2*n.x,p=r.max.y-r.min.y+2*n.y,f=e.canvas.height,m=e.canvas.width,v=m/f,y=u/p,g=1,x=1;y>v?x=y/v:g=v/y,e.options.hasBounds=!0,e.bounds.min.x=r.min.x,e.bounds.max.x=r.min.x+u*g,e.bounds.min.y=r.min.y,e.bounds.max.y=r.min.y+p*x,o&&(e.bounds.min.x+=.5*u-u*g*.5,e.bounds.max.x+=.5*u-u*g*.5,e.bounds.min.y+=.5*p-p*x*.5,e.bounds.max.y+=.5*p-p*x*.5),e.bounds.min.x-=n.x,e.bounds.max.x-=n.x,e.bounds.min.y-=n.y,e.bounds.max.y-=n.y,e.mouse&&(d.setScale(e.mouse,{x:(e.bounds.max.x-e.bounds.min.x)/e.canvas.width,y:(e.bounds.max.y-e.bounds.min.y)/e.canvas.height}),
+d.setOffset(e.mouse,e.bounds.min))},o.startViewTransform=function(e){var t=e.bounds.max.x-e.bounds.min.x,n=e.bounds.max.y-e.bounds.min.y,o=t/e.options.width,i=n/e.options.height;e.context.scale(1/o,1/i),e.context.translate(-e.bounds.min.x,-e.bounds.min.y)},o.endViewTransform=function(e){e.context.setTransform(e.options.pixelRatio,0,0,e.options.pixelRatio,0,0)},o.world=function(e){var t,n=e.engine,i=n.world,u=e.canvas,p=e.context,m=e.options,v=r.allBodies(i),y=r.allConstraints(i),g=m.wireframes?m.wireframeBackground:m.background,x=[],h=[],b={timestamp:n.timing.timestamp};if(a.trigger(e,"beforeRender",b),e.currentBackground!==g&&f(e,g),p.globalCompositeOperation="source-in",p.fillStyle="transparent",p.fillRect(0,0,u.width,u.height),p.globalCompositeOperation="source-over",m.hasBounds){for(t=0;t=500){var l="";s.timing&&(l+="fps: "+Math.round(s.timing.fps)+" "),e.debugString=l,e.debugTimestamp=o.timing.timestamp}if(e.debugString){n.font="12px Arial",a.wireframes?n.fillStyle="rgba(255,255,255,0.5)":n.fillStyle="rgba(0,0,0,0.5)";for(var c=e.debugString.split("\n"),d=0;d1?1:0;s1?1:0;a1?1:0;r1?1:0;a1?1:0;r1?1:0;r1?1:0;i0)){var u=o.activeContacts[0].vertex.x,p=o.activeContacts[0].vertex.y;2===o.activeContacts.length&&(u=(o.activeContacts[0].vertex.x+o.activeContacts[1].vertex.x)/2,p=(o.activeContacts[0].vertex.y+o.activeContacts[1].vertex.y)/2),i.bodyB===i.supports[0].body||!0===i.bodyA.isStatic?a.moveTo(u-8*i.normal.x,p-8*i.normal.y):a.moveTo(u+8*i.normal.x,p+8*i.normal.y),a.lineTo(u,p)}
+l.wireframes?a.strokeStyle="rgba(255,165,0,0.7)":a.strokeStyle="orange",a.lineWidth=1,a.stroke()},o.separations=function(e,t,n){var o,i,r,s,a,l=n,c=e.options;for(l.beginPath(),a=0;a1?1:0;p0)for(var r=e,o=e/t,i=1;i0?(this._kernels=e,this._quality=e.length,this._blur=Math.max.apply(Math,e)):(this._kernels=[0],this._quality=1)},r.clamp.get=function(){return this._clamp},r.pixelSize.set=function(e){"number"==typeof e?(this._pixelSize.x=e,this._pixelSize.y=e):Array.isArray(e)?(this._pixelSize.x=e[0],this._pixelSize.y=e[1]):e instanceof t.Point?(this._pixelSize.x=e.x,this._pixelSize.y=e.y):(this._pixelSize.x=1,this._pixelSize.y=1)},r.pixelSize.get=function(){return this._pixelSize},r.quality.get=function(){return this._quality},r.quality.set=function(e){this._quality=Math.max(1,Math.round(e)),this._generateKernels()},r.blur.get=function(){return this._blur},r.blur.set=function(e){this._blur=e,this._generateKernels()},Object.defineProperties(n.prototype,r),n}(t.Filter),u=n,c="\nuniform sampler2D uSampler;\nvarying vec2 vTextureCoord;\n\nuniform float threshold;\n\nvoid main() {\n vec4 color = texture2D(uSampler, vTextureCoord);\n\n // A simple & fast algorithm for getting brightness.\n // It's inaccuracy , but good enought for this feature.\n float _max = max(max(color.r, color.g), color.b);\n float _min = min(min(color.r, color.g), color.b);\n float brightness = (_max + _min) * 0.5;\n\n if(brightness > threshold) {\n gl_FragColor = color;\n } else {\n gl_FragColor = vec4(0.0, 0.0, 0.0, 0.0);\n }\n}\n",f=function(e){function t(t){void 0===t&&(t=.5),e.call(this,u,c),this.threshold=t}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={threshold:{configurable:!0}};return n.threshold.get=function(){return this.uniforms.threshold},n.threshold.set=function(e){this.uniforms.threshold=e},Object.defineProperties(t.prototype,n),t}(t.Filter),h="uniform sampler2D uSampler;\nvarying vec2 vTextureCoord;\n\nuniform sampler2D bloomTexture;\nuniform float bloomScale;\nuniform float brightness;\n\nvoid main() {\n vec4 color = texture2D(uSampler, vTextureCoord);\n color.rgb *= brightness;\n vec4 bloomColor = vec4(texture2D(bloomTexture, vTextureCoord).rgb, 0.0);\n bloomColor.rgb *= bloomScale;\n gl_FragColor = color + bloomColor;\n}\n",p=function(e){function n(n){e.call(this,u,h),"number"==typeof n&&(n={threshold:n}),n=Object.assign({threshold:.5,bloomScale:1,brightness:1,kernels:null,blur:8,quality:4,pixelSize:1,resolution:t.settings.RESOLUTION},n),this.bloomScale=n.bloomScale,this.brightness=n.brightness;var r=n.kernels,o=n.blur,i=n.quality,l=n.pixelSize,s=n.resolution;this._extractFilter=new f(n.threshold),this._extractFilter.resolution=s,this._blurFilter=r?new a(r):new a(o,i),this.pixelSize=l,this.resolution=s}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={resolution:{configurable:!0},threshold:{configurable:!0},kernels:{configurable:!0},blur:{configurable:!0},quality:{configurable:!0},pixelSize:{configurable:!0}};return n.prototype.apply=function(e,t,n,r,o){var i=e.getRenderTarget(!0);this._extractFilter.apply(e,t,i,!0,o);var l=e.getRenderTarget(!0);this._blurFilter.apply(e,i,l,!0,o),this.uniforms.bloomScale=this.bloomScale,this.uniforms.brightness=this.brightness,this.uniforms.bloomTexture=l,e.applyFilter(this,t,n,r),e.returnRenderTarget(l),e.returnRenderTarget(i)},r.resolution.get=function(){return this._resolution},r.resolution.set=function(e){this._resolution=e,this._extractFilter&&(this._extractFilter.resolution=e),this._blurFilter&&(this._blurFilter.resolution=e)},r.threshold.get=function(){return this._extractFilter.threshold},r.threshold.set=function(e){this._extractFilter.threshold=e},r.kernels.get=function(){return this._blurFilter.kernels},r.kernels.set=function(e){this._blurFilter.kernels=e},r.blur.get=function(){return this._blurFilter.blur},r.blur.set=function(e){this._blurFilter.blur=e},r.quality.get=function(){return this._blurFilter.quality},r.quality.set=function(e){this._blurFilter.quality=e},r.pixelSize.get=function(){return this._blurFilter.pixelSize},r.pixelSize.set=function(e){this._blurFilter.pixelSize=e},Object.defineProperties(n.prototype,r),n}(t.Filter),d=n,m="varying vec2 vTextureCoord;\n\nuniform vec4 filterArea;\nuniform float pixelSize;\nuniform sampler2D uSampler;\n\nvec2 mapCoord( vec2 coord )\n{\n coord *= filterArea.xy;\n coord += filterArea.zw;\n\n return coord;\n}\n\nvec2 unmapCoord( vec2 coord )\n{\n coord -= filterArea.zw;\n coord /= filterArea.xy;\n\n return coord;\n}\n\nvec2 pixelate(vec2 coord, vec2 size)\n{\n return floor( coord / size ) * size;\n}\n\nvec2 getMod(vec2 coord, vec2 size)\n{\n return mod( coord , size) / size;\n}\n\nfloat character(float n, vec2 p)\n{\n p = floor(p*vec2(4.0, -4.0) + 2.5);\n if (clamp(p.x, 0.0, 4.0) == p.x && clamp(p.y, 0.0, 4.0) == p.y)\n {\n if (int(mod(n/exp2(p.x + 5.0*p.y), 2.0)) == 1) return 1.0;\n }\n return 0.0;\n}\n\nvoid main()\n{\n vec2 coord = mapCoord(vTextureCoord);\n\n // get the rounded color..\n vec2 pixCoord = pixelate(coord, vec2(pixelSize));\n pixCoord = unmapCoord(pixCoord);\n\n vec4 color = texture2D(uSampler, pixCoord);\n\n // determine the character to use\n float gray = (color.r + color.g + color.b) / 3.0;\n\n float n = 65536.0; // .\n if (gray > 0.2) n = 65600.0; // :\n if (gray > 0.3) n = 332772.0; // *\n if (gray > 0.4) n = 15255086.0; // o\n if (gray > 0.5) n = 23385164.0; // &\n if (gray > 0.6) n = 15252014.0; // 8\n if (gray > 0.7) n = 13199452.0; // @\n if (gray > 0.8) n = 11512810.0; // #\n\n // get the mod..\n vec2 modd = getMod(coord, vec2(pixelSize));\n\n gl_FragColor = color * character( n, vec2(-1.0) + modd * 2.0);\n\n}",g=function(e){function t(t){void 0===t&&(t=8),e.call(this,d,m),this.size=t}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={size:{configurable:!0}};return n.size.get=function(){return this.uniforms.pixelSize},n.size.set=function(e){this.uniforms.pixelSize=e},Object.defineProperties(t.prototype,n),t}(t.Filter),v=n,x="precision mediump float;\n\nvarying vec2 vTextureCoord;\nuniform sampler2D uSampler;\nuniform vec4 filterArea;\n\nuniform float transformX;\nuniform float transformY;\nuniform vec3 lightColor;\nuniform float lightAlpha;\nuniform vec3 shadowColor;\nuniform float shadowAlpha;\n\nvoid main(void) {\n vec2 transform = vec2(1.0 / filterArea) * vec2(transformX, transformY);\n vec4 color = texture2D(uSampler, vTextureCoord);\n float light = texture2D(uSampler, vTextureCoord - transform).a;\n float shadow = texture2D(uSampler, vTextureCoord + transform).a;\n\n color.rgb = mix(color.rgb, lightColor, clamp((color.a - light) * lightAlpha, 0.0, 1.0));\n color.rgb = mix(color.rgb, shadowColor, clamp((color.a - shadow) * shadowAlpha, 0.0, 1.0));\n gl_FragColor = vec4(color.rgb * color.a, color.a);\n}\n",y=function(e){function n(t){void 0===t&&(t={}),e.call(this,v,x),this.uniforms.lightColor=new Float32Array(3),this.uniforms.shadowColor=new Float32Array(3),t=Object.assign({rotation:45,thickness:2,lightColor:16777215,lightAlpha:.7,shadowColor:0,shadowAlpha:.7},t),this.rotation=t.rotation,this.thickness=t.thickness,this.lightColor=t.lightColor,this.lightAlpha=t.lightAlpha,this.shadowColor=t.shadowColor,this.shadowAlpha=t.shadowAlpha}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={rotation:{configurable:!0},thickness:{configurable:!0},lightColor:{configurable:!0},lightAlpha:{configurable:!0},shadowColor:{configurable:!0},shadowAlpha:{configurable:!0}};return n.prototype._updateTransform=function(){this.uniforms.transformX=this._thickness*Math.cos(this._angle),this.uniforms.transformY=this._thickness*Math.sin(this._angle)},r.rotation.get=function(){return this._angle/t.DEG_TO_RAD},r.rotation.set=function(e){this._angle=e*t.DEG_TO_RAD,this._updateTransform()},r.thickness.get=function(){return this._thickness},r.thickness.set=function(e){this._thickness=e,this._updateTransform()},r.lightColor.get=function(){return t.utils.rgb2hex(this.uniforms.lightColor)},r.lightColor.set=function(e){t.utils.hex2rgb(e,this.uniforms.lightColor)},r.lightAlpha.get=function(){return this.uniforms.lightAlpha},r.lightAlpha.set=function(e){this.uniforms.lightAlpha=e},r.shadowColor.get=function(){return t.utils.rgb2hex(this.uniforms.shadowColor)},r.shadowColor.set=function(e){t.utils.hex2rgb(e,this.uniforms.shadowColor)},r.shadowAlpha.get=function(){return this.uniforms.shadowAlpha},r.shadowAlpha.set=function(e){this.uniforms.shadowAlpha=e},Object.defineProperties(n.prototype,r),n}(t.Filter),_=t.filters,b=_.BlurXFilter,C=_.BlurYFilter,S=_.AlphaFilter,F=function(e){function n(n,r,o,i){var l,s;void 0===n&&(n=2),void 0===r&&(r=4),void 0===o&&(o=t.settings.RESOLUTION),void 0===i&&(i=5),e.call(this),"number"==typeof n?(l=n,s=n):n instanceof t.Point?(l=n.x,s=n.y):Array.isArray(n)&&(l=n[0],s=n[1]),this.blurXFilter=new b(l,r,o,i),this.blurYFilter=new C(s,r,o,i),this.blurYFilter.blendMode=t.BLEND_MODES.SCREEN,this.defaultFilter=new S}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={blur:{configurable:!0},blurX:{configurable:!0},blurY:{configurable:!0}};return n.prototype.apply=function(e,t,n){var r=e.getRenderTarget(!0);this.defaultFilter.apply(e,t,n),this.blurXFilter.apply(e,t,r),this.blurYFilter.apply(e,r,n),e.returnRenderTarget(r)},r.blur.get=function(){return this.blurXFilter.blur},r.blur.set=function(e){this.blurXFilter.blur=this.blurYFilter.blur=e},r.blurX.get=function(){return this.blurXFilter.blur},r.blurX.set=function(e){this.blurXFilter.blur=e},r.blurY.get=function(){return this.blurYFilter.blur},r.blurY.set=function(e){this.blurYFilter.blur=e},Object.defineProperties(n.prototype,r),n}(t.Filter),z=n,A="uniform float radius;\nuniform float strength;\nuniform vec2 center;\nuniform sampler2D uSampler;\nvarying vec2 vTextureCoord;\n\nuniform vec4 filterArea;\nuniform vec4 filterClamp;\nuniform vec2 dimensions;\n\nvoid main()\n{\n vec2 coord = vTextureCoord * filterArea.xy;\n coord -= center * dimensions.xy;\n float distance = length(coord);\n if (distance < radius) {\n float percent = distance / radius;\n if (strength > 0.0) {\n coord *= mix(1.0, smoothstep(0.0, radius / distance, percent), strength * 0.75);\n } else {\n coord *= mix(1.0, pow(percent, 1.0 + strength * 0.75) * radius / distance, 1.0 - percent);\n }\n }\n coord += center * dimensions.xy;\n coord /= filterArea.xy;\n vec2 clampedCoord = clamp(coord, filterClamp.xy, filterClamp.zw);\n vec4 color = texture2D(uSampler, clampedCoord);\n if (coord != clampedCoord) {\n color *= max(0.0, 1.0 - length(coord - clampedCoord));\n }\n\n gl_FragColor = color;\n}\n",w=function(e){function t(t,n,r){e.call(this,z,A),this.uniforms.dimensions=new Float32Array(2),this.center=t||[.5,.5],this.radius=n||100,this.strength=r||1}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={radius:{configurable:!0},strength:{configurable:!0},center:{configurable:!0}};return t.prototype.apply=function(e,t,n,r){this.uniforms.dimensions[0]=t.sourceFrame.width,this.uniforms.dimensions[1]=t.sourceFrame.height,e.applyFilter(this,t,n,r)},n.radius.get=function(){return this.uniforms.radius},n.radius.set=function(e){this.uniforms.radius=e},n.strength.get=function(){return this.uniforms.strength},n.strength.set=function(e){this.uniforms.strength=e},n.center.get=function(){return this.uniforms.center},n.center.set=function(e){this.uniforms.center=e},Object.defineProperties(t.prototype,n),t}(t.Filter),T=n,D="\nvarying vec2 vTextureCoord;\nuniform sampler2D uSampler;\n\nuniform sampler2D colorMap;\n\nuniform float _mix;\nuniform float _size;\nuniform float _sliceSize;\nuniform float _slicePixelSize;\nuniform float _sliceInnerSize;\n\nvoid main() {\n vec4 color = texture2D(uSampler, vTextureCoord.xy);\n\n float sliceIndex = color.b * (_size - 1.0);\n float zSlice0 = floor(sliceIndex);\n float zSlice1 = ceil(sliceIndex);\n\n float xOffset = _slicePixelSize * 0.5 + color.r * _sliceInnerSize;\n float s0 = xOffset + zSlice0 * _sliceSize;\n float s1 = xOffset + zSlice1 * _sliceSize;\n vec4 slice0Color = texture2D(colorMap, vec2(s0, color.g));\n vec4 slice1Color = texture2D(colorMap, vec2(s1, color.g));\n vec4 adjusted = mix(slice0Color, slice1Color, fract(sliceIndex));\n\n gl_FragColor = mix(color, adjusted, _mix);\n}\n",O=function(e){function n(t,n,r){void 0===n&&(n=!1),void 0===r&&(r=1),e.call(this,T,D),this._size=0,this._sliceSize=0,this._slicePixelSize=0,this._sliceInnerSize=0,this._scaleMode=null,this._nearest=!1,this.nearest=n,this.mix=r,this.colorMap=t}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={colorSize:{configurable:!0},colorMap:{configurable:!0},nearest:{configurable:!0}};return n.prototype.apply=function(e,t,n,r){this.uniforms._mix=this.mix,e.applyFilter(this,t,n,r)},r.colorSize.get=function(){return this._size},r.colorMap.get=function(){return this._colorMap},r.colorMap.set=function(e){e instanceof t.Texture||(e=t.Texture.from(e)),e&&e.baseTexture&&(e.baseTexture.scaleMode=this._scaleMode,e.baseTexture.mipmap=!1,this._size=e.height,this._sliceSize=1/this._size,this._slicePixelSize=this._sliceSize/this._size,this._sliceInnerSize=this._slicePixelSize*(this._size-1),this.uniforms._size=this._size,this.uniforms._sliceSize=this._sliceSize,this.uniforms._slicePixelSize=this._slicePixelSize,this.uniforms._sliceInnerSize=this._sliceInnerSize,this.uniforms.colorMap=e),this._colorMap=e},r.nearest.get=function(){return this._nearest},r.nearest.set=function(e){this._nearest=e,this._scaleMode=e?t.SCALE_MODES.NEAREST:t.SCALE_MODES.LINEAR;var n=this._colorMap;n&&n.baseTexture&&(n.baseTexture._glTextures={},n.baseTexture.scaleMode=this._scaleMode,n.baseTexture.mipmap=!1,n._updateID++,n.baseTexture.emit("update",n.baseTexture))},n.prototype.updateColorMap=function(){var e=this._colorMap;e&&e.baseTexture&&(e._updateID++,e.baseTexture.emit("update",e.baseTexture),this.colorMap=e)},n.prototype.destroy=function(t){this._colorMap&&this._colorMap.destroy(t),e.prototype.destroy.call(this)},Object.defineProperties(n.prototype,r),n}(t.Filter),P=n,M="varying vec2 vTextureCoord;\nuniform sampler2D uSampler;\nuniform vec3 originalColor;\nuniform vec3 newColor;\nuniform float epsilon;\nvoid main(void) {\n vec4 currentColor = texture2D(uSampler, vTextureCoord);\n vec3 colorDiff = originalColor - (currentColor.rgb / max(currentColor.a, 0.0000000001));\n float colorDistance = length(colorDiff);\n float doReplace = step(colorDistance, epsilon);\n gl_FragColor = vec4(mix(currentColor.rgb, (newColor + colorDiff) * currentColor.a, doReplace), currentColor.a);\n}\n",R=function(e){function n(t,n,r){void 0===t&&(t=16711680),void 0===n&&(n=0),void 0===r&&(r=.4),e.call(this,P,M),this.uniforms.originalColor=new Float32Array(3),this.uniforms.newColor=new Float32Array(3),this.originalColor=t,this.newColor=n,this.epsilon=r}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={originalColor:{configurable:!0},newColor:{configurable:!0},epsilon:{configurable:!0}};return r.originalColor.set=function(e){var n=this.uniforms.originalColor;"number"==typeof e?(t.utils.hex2rgb(e,n),this._originalColor=e):(n[0]=e[0],n[1]=e[1],n[2]=e[2],this._originalColor=t.utils.rgb2hex(n))},r.originalColor.get=function(){return this._originalColor},r.newColor.set=function(e){var n=this.uniforms.newColor;"number"==typeof e?(t.utils.hex2rgb(e,n),this._newColor=e):(n[0]=e[0],n[1]=e[1],n[2]=e[2],this._newColor=t.utils.rgb2hex(n))},r.newColor.get=function(){return this._newColor},r.epsilon.set=function(e){this.uniforms.epsilon=e},r.epsilon.get=function(){return this.uniforms.epsilon},Object.defineProperties(n.prototype,r),n}(t.Filter),j=n,L="precision mediump float;\n\nvarying mediump vec2 vTextureCoord;\n\nuniform sampler2D uSampler;\nuniform vec2 texelSize;\nuniform float matrix[9];\n\nvoid main(void)\n{\n vec4 c11 = texture2D(uSampler, vTextureCoord - texelSize); // top left\n vec4 c12 = texture2D(uSampler, vec2(vTextureCoord.x, vTextureCoord.y - texelSize.y)); // top center\n vec4 c13 = texture2D(uSampler, vec2(vTextureCoord.x + texelSize.x, vTextureCoord.y - texelSize.y)); // top right\n\n vec4 c21 = texture2D(uSampler, vec2(vTextureCoord.x - texelSize.x, vTextureCoord.y)); // mid left\n vec4 c22 = texture2D(uSampler, vTextureCoord); // mid center\n vec4 c23 = texture2D(uSampler, vec2(vTextureCoord.x + texelSize.x, vTextureCoord.y)); // mid right\n\n vec4 c31 = texture2D(uSampler, vec2(vTextureCoord.x - texelSize.x, vTextureCoord.y + texelSize.y)); // bottom left\n vec4 c32 = texture2D(uSampler, vec2(vTextureCoord.x, vTextureCoord.y + texelSize.y)); // bottom center\n vec4 c33 = texture2D(uSampler, vTextureCoord + texelSize); // bottom right\n\n gl_FragColor =\n c11 * matrix[0] + c12 * matrix[1] + c13 * matrix[2] +\n c21 * matrix[3] + c22 * matrix[4] + c23 * matrix[5] +\n c31 * matrix[6] + c32 * matrix[7] + c33 * matrix[8];\n\n gl_FragColor.a = c22.a;\n}\n",k=function(e){function t(t,n,r){e.call(this,j,L),this.uniforms.texelSize=new Float32Array(9),this.matrix=t,this.width=n,this.height=r}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={matrix:{configurable:!0},width:{configurable:!0},height:{configurable:!0}};return n.matrix.get=function(){return this.uniforms.matrix},n.matrix.set=function(e){this.uniforms.matrix=new Float32Array(e)},n.width.get=function(){return 1/this.uniforms.texelSize[0]},n.width.set=function(e){this.uniforms.texelSize[0]=1/e},n.height.get=function(){return 1/this.uniforms.texelSize[1]},n.height.set=function(e){this.uniforms.texelSize[1]=1/e},Object.defineProperties(t.prototype,n),t}(t.Filter),I=n,E="precision mediump float;\n\nvarying vec2 vTextureCoord;\n\nuniform sampler2D uSampler;\n\nvoid main(void)\n{\n float lum = length(texture2D(uSampler, vTextureCoord.xy).rgb);\n\n gl_FragColor = vec4(1.0, 1.0, 1.0, 1.0);\n\n if (lum < 1.00)\n {\n if (mod(gl_FragCoord.x + gl_FragCoord.y, 10.0) == 0.0)\n {\n gl_FragColor = vec4(0.0, 0.0, 0.0, 1.0);\n }\n }\n\n if (lum < 0.75)\n {\n if (mod(gl_FragCoord.x - gl_FragCoord.y, 10.0) == 0.0)\n {\n gl_FragColor = vec4(0.0, 0.0, 0.0, 1.0);\n }\n }\n\n if (lum < 0.50)\n {\n if (mod(gl_FragCoord.x + gl_FragCoord.y - 5.0, 10.0) == 0.0)\n {\n gl_FragColor = vec4(0.0, 0.0, 0.0, 1.0);\n }\n }\n\n if (lum < 0.3)\n {\n if (mod(gl_FragCoord.x - gl_FragCoord.y - 5.0, 10.0) == 0.0)\n {\n gl_FragColor = vec4(0.0, 0.0, 0.0, 1.0);\n }\n }\n}\n",B=function(e){function t(){e.call(this,I,E)}return e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t,t}(t.Filter),X=n,q="varying vec2 vTextureCoord;\nuniform sampler2D uSampler;\n\nuniform vec4 filterArea;\nuniform vec2 dimensions;\n\nconst float SQRT_2 = 1.414213;\n\nconst float light = 1.0;\n\nuniform float curvature;\nuniform float lineWidth;\nuniform float lineContrast;\nuniform bool verticalLine;\nuniform float noise;\nuniform float noiseSize;\n\nuniform float vignetting;\nuniform float vignettingAlpha;\nuniform float vignettingBlur;\n\nuniform float seed;\nuniform float time;\n\nfloat rand(vec2 co) {\n return fract(sin(dot(co.xy, vec2(12.9898, 78.233))) * 43758.5453);\n}\n\nvoid main(void)\n{\n vec2 pixelCoord = vTextureCoord.xy * filterArea.xy;\n vec2 coord = pixelCoord / dimensions;\n\n vec2 dir = vec2(coord - vec2(0.5, 0.5));\n\n float _c = curvature > 0. ? curvature : 1.;\n float k = curvature > 0. ?(length(dir * dir) * 0.25 * _c * _c + 0.935 * _c) : 1.;\n vec2 uv = dir * k;\n\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n vec3 rgb = gl_FragColor.rgb;\n\n\n if (noise > 0.0 && noiseSize > 0.0)\n {\n pixelCoord.x = floor(pixelCoord.x / noiseSize);\n pixelCoord.y = floor(pixelCoord.y / noiseSize);\n float _noise = rand(pixelCoord * noiseSize * seed) - 0.5;\n rgb += _noise * noise;\n }\n\n if (lineWidth > 0.0) {\n float v = (verticalLine ? uv.x * dimensions.x : uv.y * dimensions.y) * min(1.0, 2.0 / lineWidth ) / _c;\n float j = 1. + cos(v * 1.2 - time) * 0.5 * lineContrast;\n rgb *= j;\n float segment = verticalLine ? mod((dir.x + .5) * dimensions.x, 4.) : mod((dir.y + .5) * dimensions.y, 4.);\n rgb *= 0.99 + ceil(segment) * 0.015;\n }\n\n if (vignetting > 0.0)\n {\n float outter = SQRT_2 - vignetting * SQRT_2;\n float darker = clamp((outter - length(dir) * SQRT_2) / ( 0.00001 + vignettingBlur * SQRT_2), 0.0, 1.0);\n rgb *= darker + (1.0 - darker) * (1.0 - vignettingAlpha);\n }\n\n gl_FragColor.rgb = rgb;\n}\n",N=function(e){function t(t){e.call(this,X,q),this.uniforms.dimensions=new Float32Array(2),this.time=0,this.seed=0,Object.assign(this,{curvature:1,lineWidth:1,lineContrast:.25,verticalLine:!1,noise:0,noiseSize:1,seed:0,vignetting:.3,vignettingAlpha:1,vignettingBlur:.3,time:0},t)}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={curvature:{configurable:!0},lineWidth:{configurable:!0},lineContrast:{configurable:!0},verticalLine:{configurable:!0},noise:{configurable:!0},noiseSize:{configurable:!0},vignetting:{configurable:!0},vignettingAlpha:{configurable:!0},vignettingBlur:{configurable:!0}};return t.prototype.apply=function(e,t,n,r){this.uniforms.dimensions[0]=t.sourceFrame.width,this.uniforms.dimensions[1]=t.sourceFrame.height,this.uniforms.seed=this.seed,this.uniforms.time=this.time,e.applyFilter(this,t,n,r)},n.curvature.set=function(e){this.uniforms.curvature=e},n.curvature.get=function(){return this.uniforms.curvature},n.lineWidth.set=function(e){this.uniforms.lineWidth=e},n.lineWidth.get=function(){return this.uniforms.lineWidth},n.lineContrast.set=function(e){this.uniforms.lineContrast=e},n.lineContrast.get=function(){return this.uniforms.lineContrast},n.verticalLine.set=function(e){this.uniforms.verticalLine=e},n.verticalLine.get=function(){return this.uniforms.verticalLine},n.noise.set=function(e){this.uniforms.noise=e},n.noise.get=function(){return this.uniforms.noise},n.noiseSize.set=function(e){this.uniforms.noiseSize=e},n.noiseSize.get=function(){return this.uniforms.noiseSize},n.vignetting.set=function(e){this.uniforms.vignetting=e},n.vignetting.get=function(){return this.uniforms.vignetting},n.vignettingAlpha.set=function(e){this.uniforms.vignettingAlpha=e},n.vignettingAlpha.get=function(){return this.uniforms.vignettingAlpha},n.vignettingBlur.set=function(e){this.uniforms.vignettingBlur=e},n.vignettingBlur.get=function(){return this.uniforms.vignettingBlur},Object.defineProperties(t.prototype,n),t}(t.Filter),G=n,K="precision mediump float;\n\nvarying vec2 vTextureCoord;\nvarying vec4 vColor;\n\nuniform vec4 filterArea;\nuniform sampler2D uSampler;\n\nuniform float angle;\nuniform float scale;\n\nfloat pattern()\n{\n float s = sin(angle), c = cos(angle);\n vec2 tex = vTextureCoord * filterArea.xy;\n vec2 point = vec2(\n c * tex.x - s * tex.y,\n s * tex.x + c * tex.y\n ) * scale;\n return (sin(point.x) * sin(point.y)) * 4.0;\n}\n\nvoid main()\n{\n vec4 color = texture2D(uSampler, vTextureCoord);\n float average = (color.r + color.g + color.b) / 3.0;\n gl_FragColor = vec4(vec3(average * 10.0 - 5.0 + pattern()), color.a);\n}\n",Y=function(e){function t(t,n){void 0===t&&(t=1),void 0===n&&(n=5),e.call(this,G,K),this.scale=t,this.angle=n}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={scale:{configurable:!0},angle:{configurable:!0}};return n.scale.get=function(){return this.uniforms.scale},n.scale.set=function(e){this.uniforms.scale=e},n.angle.get=function(){return this.uniforms.angle},n.angle.set=function(e){this.uniforms.angle=e},Object.defineProperties(t.prototype,n),t}(t.Filter),W=n,Q="varying vec2 vTextureCoord;\nuniform sampler2D uSampler;\nuniform float alpha;\nuniform vec3 color;\nvoid main(void){\n vec4 sample = texture2D(uSampler, vTextureCoord);\n\n // Un-premultiply alpha before applying the color\n if (sample.a > 0.0) {\n sample.rgb /= sample.a;\n }\n\n // Premultiply alpha again\n sample.rgb = color.rgb * sample.a;\n\n // alpha user alpha\n sample *= alpha;\n\n gl_FragColor = sample;\n}",U=function(e){function n(n){n&&n.constructor!==Object&&(console.warn("DropShadowFilter now uses options instead of (rotation, distance, blur, color, alpha)"),n={rotation:n},void 0!==arguments[1]&&(n.distance=arguments[1]),void 0!==arguments[2]&&(n.blur=arguments[2]),void 0!==arguments[3]&&(n.color=arguments[3]),void 0!==arguments[4]&&(n.alpha=arguments[4])),n=Object.assign({rotation:45,distance:5,color:0,alpha:.5,shadowOnly:!1,kernels:null,blur:2,quality:3,pixelSize:1,resolution:t.settings.RESOLUTION},n),e.call(this);var r=n.kernels,o=n.blur,i=n.quality,l=n.pixelSize,s=n.resolution;this._tintFilter=new t.Filter(W,Q),this._tintFilter.uniforms.color=new Float32Array(4),this._tintFilter.resolution=s,this._blurFilter=r?new a(r):new a(o,i),this.pixelSize=l,this.resolution=s,this.targetTransform=new t.Matrix;var u=n.shadowOnly,c=n.rotation,f=n.distance,h=n.alpha,p=n.color;this.shadowOnly=u,this.rotation=c,this.distance=f,this.alpha=h,this.color=p,this._updatePadding()}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={resolution:{configurable:!0},distance:{configurable:!0},rotation:{configurable:!0},alpha:{configurable:!0},color:{configurable:!0},kernels:{configurable:!0},blur:{configurable:!0},quality:{configurable:!0},pixelSize:{configurable:!0}};return n.prototype.apply=function(e,t,n,r){var o=e.getRenderTarget();o.transform=this.targetTransform,this._tintFilter.apply(e,t,o,!0),o.transform=null,this._blurFilter.apply(e,o,n),!0!==this.shadowOnly&&e.applyFilter(this,t,n,r),e.returnRenderTarget(o)},n.prototype._updatePadding=function(){this.padding=this.distance+2*this.blur},n.prototype._updateTargetTransform=function(){this.targetTransform.tx=this.distance*Math.cos(this.angle),this.targetTransform.ty=this.distance*Math.sin(this.angle)},r.resolution.get=function(){return this._resolution},r.resolution.set=function(e){this._resolution=e,this._tintFilter&&(this._tintFilter.resolution=e),this._blurFilter&&(this._blurFilter.resolution=e)},r.distance.get=function(){return this._distance},r.distance.set=function(e){this._distance=e,this._updatePadding(),this._updateTargetTransform()},r.rotation.get=function(){return this.angle/t.DEG_TO_RAD},r.rotation.set=function(e){this.angle=e*t.DEG_TO_RAD,this._updateTargetTransform()},r.alpha.get=function(){return this._tintFilter.uniforms.alpha},r.alpha.set=function(e){this._tintFilter.uniforms.alpha=e},r.color.get=function(){return t.utils.rgb2hex(this._tintFilter.uniforms.color)},r.color.set=function(e){t.utils.hex2rgb(e,this._tintFilter.uniforms.color)},r.kernels.get=function(){return this._blurFilter.kernels},r.kernels.set=function(e){this._blurFilter.kernels=e},r.blur.get=function(){return this._blurFilter.blur},r.blur.set=function(e){this._blurFilter.blur=e,this._updatePadding()},r.quality.get=function(){return this._blurFilter.quality},r.quality.set=function(e){this._blurFilter.quality=e},r.pixelSize.get=function(){return this._blurFilter.pixelSize},r.pixelSize.set=function(e){this._blurFilter.pixelSize=e},Object.defineProperties(n.prototype,r),n}(t.Filter),Z=n,V="precision mediump float;\n\nvarying vec2 vTextureCoord;\n\nuniform sampler2D uSampler;\nuniform float strength;\nuniform vec4 filterArea;\n\n\nvoid main(void)\n{\n\tvec2 onePixel = vec2(1.0 / filterArea);\n\n\tvec4 color;\n\n\tcolor.rgb = vec3(0.5);\n\n\tcolor -= texture2D(uSampler, vTextureCoord - onePixel) * strength;\n\tcolor += texture2D(uSampler, vTextureCoord + onePixel) * strength;\n\n\tcolor.rgb = vec3((color.r + color.g + color.b) / 3.0);\n\n\tfloat alpha = texture2D(uSampler, vTextureCoord).a;\n\n\tgl_FragColor = vec4(color.rgb * alpha, alpha);\n}\n",H=function(e){function t(t){void 0===t&&(t=5),e.call(this,Z,V),this.strength=t}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={strength:{configurable:!0}};return n.strength.get=function(){return this.uniforms.strength},n.strength.set=function(e){this.uniforms.strength=e},Object.defineProperties(t.prototype,n),t}(t.Filter),$=n,J="// precision highp float;\n\nvarying vec2 vTextureCoord;\nuniform sampler2D uSampler;\n\nuniform vec4 filterArea;\nuniform vec4 filterClamp;\nuniform vec2 dimensions;\nuniform float aspect;\n\nuniform sampler2D displacementMap;\nuniform float offset;\nuniform float sinDir;\nuniform float cosDir;\nuniform int fillMode;\n\nuniform float seed;\nuniform vec2 red;\nuniform vec2 green;\nuniform vec2 blue;\n\nconst int TRANSPARENT = 0;\nconst int ORIGINAL = 1;\nconst int LOOP = 2;\nconst int CLAMP = 3;\nconst int MIRROR = 4;\n\nvoid main(void)\n{\n vec2 coord = (vTextureCoord * filterArea.xy) / dimensions;\n\n if (coord.x > 1.0 || coord.y > 1.0) {\n return;\n }\n\n float cx = coord.x - 0.5;\n float cy = (coord.y - 0.5) * aspect;\n float ny = (-sinDir * cx + cosDir * cy) / aspect + 0.5;\n\n // displacementMap: repeat\n // ny = ny > 1.0 ? ny - 1.0 : (ny < 0.0 ? 1.0 + ny : ny);\n\n // displacementMap: mirror\n ny = ny > 1.0 ? 2.0 - ny : (ny < 0.0 ? -ny : ny);\n\n vec4 dc = texture2D(displacementMap, vec2(0.5, ny));\n\n float displacement = (dc.r - dc.g) * (offset / filterArea.x);\n\n coord = vTextureCoord + vec2(cosDir * displacement, sinDir * displacement * aspect);\n\n if (fillMode == CLAMP) {\n coord = clamp(coord, filterClamp.xy, filterClamp.zw);\n } else {\n if( coord.x > filterClamp.z ) {\n if (fillMode == ORIGINAL) {\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n return;\n } else if (fillMode == LOOP) {\n coord.x -= filterClamp.z;\n } else if (fillMode == MIRROR) {\n coord.x = filterClamp.z * 2.0 - coord.x;\n } else {\n gl_FragColor = vec4(0., 0., 0., 0.);\n return;\n }\n } else if( coord.x < filterClamp.x ) {\n if (fillMode == ORIGINAL) {\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n return;\n } else if (fillMode == LOOP) {\n coord.x += filterClamp.z;\n } else if (fillMode == MIRROR) {\n coord.x *= -filterClamp.z;\n } else {\n gl_FragColor = vec4(0., 0., 0., 0.);\n return;\n }\n }\n\n if( coord.y > filterClamp.w ) {\n if (fillMode == ORIGINAL) {\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n return;\n } else if (fillMode == LOOP) {\n coord.y -= filterClamp.w;\n } else if (fillMode == MIRROR) {\n coord.y = filterClamp.w * 2.0 - coord.y;\n } else {\n gl_FragColor = vec4(0., 0., 0., 0.);\n return;\n }\n } else if( coord.y < filterClamp.y ) {\n if (fillMode == ORIGINAL) {\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n return;\n } else if (fillMode == LOOP) {\n coord.y += filterClamp.w;\n } else if (fillMode == MIRROR) {\n coord.y *= -filterClamp.w;\n } else {\n gl_FragColor = vec4(0., 0., 0., 0.);\n return;\n }\n }\n }\n\n gl_FragColor.r = texture2D(uSampler, coord + red * (1.0 - seed * 0.4) / filterArea.xy).r;\n gl_FragColor.g = texture2D(uSampler, coord + green * (1.0 - seed * 0.3) / filterArea.xy).g;\n gl_FragColor.b = texture2D(uSampler, coord + blue * (1.0 - seed * 0.2) / filterArea.xy).b;\n gl_FragColor.a = texture2D(uSampler, coord).a;\n}\n",ee=function(e){function n(n){void 0===n&&(n={}),e.call(this,$,J),this.uniforms.dimensions=new Float32Array(2),n=Object.assign({slices:5,offset:100,direction:0,fillMode:0,average:!1,seed:0,red:[0,0],green:[0,0],blue:[0,0],minSize:8,sampleSize:512},n),this.direction=n.direction,this.red=n.red,this.green=n.green,this.blue=n.blue,this.offset=n.offset,this.fillMode=n.fillMode,this.average=n.average,this.seed=n.seed,this.minSize=n.minSize,this.sampleSize=n.sampleSize,this._canvas=document.createElement("canvas"),this._canvas.width=4,this._canvas.height=this.sampleSize,this.texture=t.Texture.fromCanvas(this._canvas,t.SCALE_MODES.NEAREST),this._slices=0,this.slices=n.slices}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={sizes:{configurable:!0},offsets:{configurable:!0},slices:{configurable:!0},direction:{configurable:!0},red:{configurable:!0},green:{configurable:!0},blue:{configurable:!0}};return n.prototype.apply=function(e,t,n,r){var o=t.sourceFrame.width,i=t.sourceFrame.height;this.uniforms.dimensions[0]=o,this.uniforms.dimensions[1]=i,this.uniforms.aspect=i/o,this.uniforms.seed=this.seed,this.uniforms.offset=this.offset,this.uniforms.fillMode=this.fillMode,e.applyFilter(this,t,n,r)},n.prototype._randomizeSizes=function(){var e=this._sizes,t=this._slices-1,n=this.sampleSize,r=Math.min(this.minSize/n,.9/this._slices);if(this.average){for(var o=this._slices,i=1,l=0;l0;t--){var n=Math.random()*t>>0,r=e[t];e[t]=e[n],e[n]=r}},n.prototype._randomizeOffsets=function(){for(var e=0;e0?e:0,a=e<0?-e:0;r.fillStyle="rgba("+s+", "+a+", 0, 1)",r.fillRect(0,o>>0,t,l+1>>0),o+=l}n.baseTexture.emit("update",n.baseTexture),this.uniforms.displacementMap=n},r.sizes.set=function(e){for(var t=Math.min(this._slices,e.length),n=0;nthis._maxColors)throw"Length of replacements ("+o+") exceeds the maximum colors length ("+this._maxColors+")";n[3*o]=-1;for(var i=0;i 0.5) then: 1 - 2 * (1 - dst) * (1 - src)\n return vec3((dst.x <= 0.5) ? (2.0 * src.x * dst.x) : (1.0 - 2.0 * (1.0 - dst.x) * (1.0 - src.x)),\n (dst.y <= 0.5) ? (2.0 * src.y * dst.y) : (1.0 - 2.0 * (1.0 - dst.y) * (1.0 - src.y)),\n (dst.z <= 0.5) ? (2.0 * src.z * dst.z) : (1.0 - 2.0 * (1.0 - dst.z) * (1.0 - src.z)));\n}\n\n\nvoid main()\n{\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n vec3 color = gl_FragColor.rgb;\n\n if (sepia > 0.0)\n {\n float gray = (color.x + color.y + color.z) / 3.0;\n vec3 grayscale = vec3(gray);\n\n color = Overlay(SEPIA_RGB, grayscale);\n\n color = grayscale + sepia * (color - grayscale);\n }\n\n vec2 coord = vTextureCoord * filterArea.xy / dimensions.xy;\n\n if (vignetting > 0.0)\n {\n float outter = SQRT_2 - vignetting * SQRT_2;\n vec2 dir = vec2(vec2(0.5, 0.5) - coord);\n dir.y *= dimensions.y / dimensions.x;\n float darker = clamp((outter - length(dir) * SQRT_2) / ( 0.00001 + vignettingBlur * SQRT_2), 0.0, 1.0);\n color.rgb *= darker + (1.0 - darker) * (1.0 - vignettingAlpha);\n }\n\n if (scratchDensity > seed && scratch != 0.0)\n {\n float phase = seed * 256.0;\n float s = mod(floor(phase), 2.0);\n float dist = 1.0 / scratchDensity;\n float d = distance(coord, vec2(seed * dist, abs(s - seed * dist)));\n if (d < seed * 0.6 + 0.4)\n {\n highp float period = scratchDensity * 10.0;\n\n float xx = coord.x * period + phase;\n float aa = abs(mod(xx, 0.5) * 4.0);\n float bb = mod(floor(xx / 0.5), 2.0);\n float yy = (1.0 - bb) * aa + bb * (2.0 - aa);\n\n float kk = 2.0 * period;\n float dw = scratchWidth / dimensions.x * (0.75 + seed);\n float dh = dw * kk;\n\n float tine = (yy - (2.0 - dh));\n\n if (tine > 0.0) {\n float _sign = sign(scratch);\n\n tine = s * tine / period + scratch + 0.1;\n tine = clamp(tine + 1.0, 0.5 + _sign * 0.5, 1.5 + _sign * 0.5);\n\n color.rgb *= tine;\n }\n }\n }\n\n if (noise > 0.0 && noiseSize > 0.0)\n {\n vec2 pixelCoord = vTextureCoord.xy * filterArea.xy;\n pixelCoord.x = floor(pixelCoord.x / noiseSize);\n pixelCoord.y = floor(pixelCoord.y / noiseSize);\n // vec2 d = pixelCoord * noiseSize * vec2(1024.0 + seed * 512.0, 1024.0 - seed * 512.0);\n // float _noise = snoise(d) * 0.5;\n float _noise = rand(pixelCoord * noiseSize * seed) - 0.5;\n color += _noise * noise;\n }\n\n gl_FragColor.rgb = color;\n}\n",ge=function(e){function t(t,n){void 0===n&&(n=0),e.call(this,de,me),this.uniforms.dimensions=new Float32Array(2),"number"==typeof t?(this.seed=t,t=null):this.seed=n,Object.assign(this,{sepia:.3,noise:.3,noiseSize:1,scratch:.5,scratchDensity:.3,scratchWidth:1,vignetting:.3,vignettingAlpha:1,vignettingBlur:.3},t)}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={sepia:{configurable:!0},noise:{configurable:!0},noiseSize:{configurable:!0},scratch:{configurable:!0},scratchDensity:{configurable:!0},scratchWidth:{configurable:!0},vignetting:{configurable:!0},vignettingAlpha:{configurable:!0},vignettingBlur:{configurable:!0}};return t.prototype.apply=function(e,t,n,r){this.uniforms.dimensions[0]=t.sourceFrame.width,this.uniforms.dimensions[1]=t.sourceFrame.height,this.uniforms.seed=this.seed,e.applyFilter(this,t,n,r)},n.sepia.set=function(e){this.uniforms.sepia=e},n.sepia.get=function(){return this.uniforms.sepia},n.noise.set=function(e){this.uniforms.noise=e},n.noise.get=function(){return this.uniforms.noise},n.noiseSize.set=function(e){this.uniforms.noiseSize=e},n.noiseSize.get=function(){return this.uniforms.noiseSize},n.scratch.set=function(e){this.uniforms.scratch=e},n.scratch.get=function(){return this.uniforms.scratch},n.scratchDensity.set=function(e){this.uniforms.scratchDensity=e},n.scratchDensity.get=function(){return this.uniforms.scratchDensity},n.scratchWidth.set=function(e){this.uniforms.scratchWidth=e},n.scratchWidth.get=function(){return this.uniforms.scratchWidth},n.vignetting.set=function(e){this.uniforms.vignetting=e},n.vignetting.get=function(){return this.uniforms.vignetting},n.vignettingAlpha.set=function(e){this.uniforms.vignettingAlpha=e},n.vignettingAlpha.get=function(){return this.uniforms.vignettingAlpha},n.vignettingBlur.set=function(e){this.uniforms.vignettingBlur=e},n.vignettingBlur.get=function(){return this.uniforms.vignettingBlur},Object.defineProperties(t.prototype,n),t}(t.Filter),ve=n,xe="varying vec2 vTextureCoord;\nuniform sampler2D uSampler;\n\nuniform vec2 thickness;\nuniform vec4 outlineColor;\nuniform vec4 filterClamp;\n\nconst float DOUBLE_PI = 3.14159265358979323846264 * 2.;\n\nvoid main(void) {\n vec4 ownColor = texture2D(uSampler, vTextureCoord);\n vec4 curColor;\n float maxAlpha = 0.;\n vec2 displaced;\n for (float angle = 0.; angle <= DOUBLE_PI; angle += ${angleStep}) {\n displaced.x = vTextureCoord.x + thickness.x * cos(angle);\n displaced.y = vTextureCoord.y + thickness.y * sin(angle);\n curColor = texture2D(uSampler, clamp(displaced, filterClamp.xy, filterClamp.zw));\n maxAlpha = max(maxAlpha, curColor.a);\n }\n float resultAlpha = max(maxAlpha, ownColor.a);\n gl_FragColor = vec4((ownColor.rgb + outlineColor.rgb * (1. - ownColor.a)) * resultAlpha, resultAlpha);\n}\n",ye=function(e){function n(t,r,o){void 0===t&&(t=1),void 0===r&&(r=0),void 0===o&&(o=.1);var i=Math.max(o*n.MAX_SAMPLES,n.MIN_SAMPLES),l=(2*Math.PI/i).toFixed(7);e.call(this,ve,xe.replace(/\$\{angleStep\}/,l)),this.uniforms.thickness=new Float32Array([0,0]),this.thickness=t,this.uniforms.outlineColor=new Float32Array([0,0,0,1]),this.color=r,this.quality=o}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={color:{configurable:!0}};return n.prototype.apply=function(e,t,n,r){this.uniforms.thickness[0]=this.thickness/t.size.width,this.uniforms.thickness[1]=this.thickness/t.size.height,e.applyFilter(this,t,n,r)},r.color.get=function(){return t.utils.rgb2hex(this.uniforms.outlineColor)},r.color.set=function(e){t.utils.hex2rgb(e,this.uniforms.outlineColor)},Object.defineProperties(n.prototype,r),n}(t.Filter);ye.MIN_SAMPLES=1,ye.MAX_SAMPLES=100;var _e=n,be="precision mediump float;\n\nvarying vec2 vTextureCoord;\n\nuniform vec2 size;\nuniform sampler2D uSampler;\n\nuniform vec4 filterArea;\n\nvec2 mapCoord( vec2 coord )\n{\n coord *= filterArea.xy;\n coord += filterArea.zw;\n\n return coord;\n}\n\nvec2 unmapCoord( vec2 coord )\n{\n coord -= filterArea.zw;\n coord /= filterArea.xy;\n\n return coord;\n}\n\nvec2 pixelate(vec2 coord, vec2 size)\n{\n\treturn floor( coord / size ) * size;\n}\n\nvoid main(void)\n{\n vec2 coord = mapCoord(vTextureCoord);\n\n coord = pixelate(coord, size);\n\n coord = unmapCoord(coord);\n\n gl_FragColor = texture2D(uSampler, coord);\n}\n",Ce=function(e){function t(t){void 0===t&&(t=10),e.call(this,_e,be),this.size=t}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={size:{configurable:!0}};return n.size.get=function(){return this.uniforms.size},n.size.set=function(e){"number"==typeof e&&(e=[e,e]),this.uniforms.size=e},Object.defineProperties(t.prototype,n),t}(t.Filter),Se=n,Fe="varying vec2 vTextureCoord;\nuniform sampler2D uSampler;\nuniform vec4 filterArea;\n\nuniform float uRadian;\nuniform vec2 uCenter;\nuniform float uRadius;\nuniform int uKernelSize;\n\nconst int MAX_KERNEL_SIZE = 2048;\n\nvoid main(void)\n{\n vec4 color = texture2D(uSampler, vTextureCoord);\n\n if (uKernelSize == 0)\n {\n gl_FragColor = color;\n return;\n }\n\n float aspect = filterArea.y / filterArea.x;\n vec2 center = uCenter.xy / filterArea.xy;\n float gradient = uRadius / filterArea.x * 0.3;\n float radius = uRadius / filterArea.x - gradient * 0.5;\n int k = uKernelSize - 1;\n\n vec2 coord = vTextureCoord;\n vec2 dir = vec2(center - coord);\n float dist = length(vec2(dir.x, dir.y * aspect));\n\n float radianStep = uRadian;\n if (radius >= 0.0 && dist > radius) {\n float delta = dist - radius;\n float gap = gradient;\n float scale = 1.0 - abs(delta / gap);\n if (scale <= 0.0) {\n gl_FragColor = color;\n return;\n }\n radianStep *= scale;\n }\n radianStep /= float(k);\n\n float s = sin(radianStep);\n float c = cos(radianStep);\n mat2 rotationMatrix = mat2(vec2(c, -s), vec2(s, c));\n\n for(int i = 0; i < MAX_KERNEL_SIZE - 1; i++) {\n if (i == k) {\n break;\n }\n\n coord -= center;\n coord.y *= aspect;\n coord = rotationMatrix * coord;\n coord.y /= aspect;\n coord += center;\n\n vec4 sample = texture2D(uSampler, coord);\n\n // switch to pre-multiplied alpha to correctly blur transparent images\n // sample.rgb *= sample.a;\n\n color += sample;\n }\n\n gl_FragColor = color / float(uKernelSize);\n}\n",ze=function(e){function t(t,n,r,o){void 0===t&&(t=0),void 0===n&&(n=[0,0]),void 0===r&&(r=5),void 0===o&&(o=-1),e.call(this,Se,Fe),this._angle=0,this.angle=t,this.center=n,this.kernelSize=r,this.radius=o}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={angle:{configurable:!0},center:{configurable:!0},radius:{configurable:!0}};return t.prototype.apply=function(e,t,n,r){this.uniforms.uKernelSize=0!==this._angle?this.kernelSize:0,e.applyFilter(this,t,n,r)},n.angle.set=function(e){this._angle=e,this.uniforms.uRadian=e*Math.PI/180},n.angle.get=function(){return this._angle},n.center.get=function(){return this.uniforms.uCenter},n.center.set=function(e){this.uniforms.uCenter=e},n.radius.get=function(){return this.uniforms.uRadius},n.radius.set=function(e){(e<0||e===1/0)&&(e=-1),this.uniforms.uRadius=e},Object.defineProperties(t.prototype,n),t}(t.Filter),Ae=n,we="varying vec2 vTextureCoord;\nuniform sampler2D uSampler;\n\nuniform vec4 filterArea;\nuniform vec4 filterClamp;\nuniform vec2 dimensions;\n\nuniform bool mirror;\nuniform float boundary;\nuniform vec2 amplitude;\nuniform vec2 waveLength;\nuniform vec2 alpha;\nuniform float time;\n\nfloat rand(vec2 co) {\n return fract(sin(dot(co.xy, vec2(12.9898, 78.233))) * 43758.5453);\n}\n\nvoid main(void)\n{\n vec2 pixelCoord = vTextureCoord.xy * filterArea.xy;\n vec2 coord = pixelCoord / dimensions;\n\n if (coord.y < boundary) {\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n return;\n }\n\n float k = (coord.y - boundary) / (1. - boundary + 0.0001);\n float areaY = boundary * dimensions.y / filterArea.y;\n float v = areaY + areaY - vTextureCoord.y;\n float y = mirror ? v : vTextureCoord.y;\n\n float _amplitude = ((amplitude.y - amplitude.x) * k + amplitude.x ) / filterArea.x;\n float _waveLength = ((waveLength.y - waveLength.x) * k + waveLength.x) / filterArea.y;\n float _alpha = (alpha.y - alpha.x) * k + alpha.x;\n\n float x = vTextureCoord.x + cos(v * 6.28 / _waveLength - time) * _amplitude;\n x = clamp(x, filterClamp.x, filterClamp.z);\n\n vec4 color = texture2D(uSampler, vec2(x, y));\n\n gl_FragColor = color * _alpha;\n}\n",Te=function(e){function t(t){e.call(this,Ae,we),this.uniforms.amplitude=new Float32Array(2),this.uniforms.waveLength=new Float32Array(2),this.uniforms.alpha=new Float32Array(2),this.uniforms.dimensions=new Float32Array(2),Object.assign(this,{mirror:!0,boundary:.5,amplitude:[0,20],waveLength:[30,100],alpha:[1,1],time:0},t)}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={mirror:{configurable:!0},boundary:{configurable:!0},amplitude:{configurable:!0},waveLength:{configurable:!0},alpha:{configurable:!0}};return t.prototype.apply=function(e,t,n,r){this.uniforms.dimensions[0]=t.sourceFrame.width,this.uniforms.dimensions[1]=t.sourceFrame.height,this.uniforms.time=this.time,e.applyFilter(this,t,n,r)},n.mirror.set=function(e){this.uniforms.mirror=e},n.mirror.get=function(){return this.uniforms.mirror},n.boundary.set=function(e){this.uniforms.boundary=e},n.boundary.get=function(){return this.uniforms.boundary},n.amplitude.set=function(e){this.uniforms.amplitude[0]=e[0],this.uniforms.amplitude[1]=e[1]},n.amplitude.get=function(){return this.uniforms.amplitude},n.waveLength.set=function(e){this.uniforms.waveLength[0]=e[0],this.uniforms.waveLength[1]=e[1]},n.waveLength.get=function(){return this.uniforms.waveLength},n.alpha.set=function(e){this.uniforms.alpha[0]=e[0],this.uniforms.alpha[1]=e[1]},n.alpha.get=function(){return this.uniforms.alpha},Object.defineProperties(t.prototype,n),t}(t.Filter),De=n,Oe="precision mediump float;\n\nvarying vec2 vTextureCoord;\n\nuniform sampler2D uSampler;\nuniform vec4 filterArea;\nuniform vec2 red;\nuniform vec2 green;\nuniform vec2 blue;\n\nvoid main(void)\n{\n gl_FragColor.r = texture2D(uSampler, vTextureCoord + red/filterArea.xy).r;\n gl_FragColor.g = texture2D(uSampler, vTextureCoord + green/filterArea.xy).g;\n gl_FragColor.b = texture2D(uSampler, vTextureCoord + blue/filterArea.xy).b;\n gl_FragColor.a = texture2D(uSampler, vTextureCoord).a;\n}\n",Pe=function(e){function t(t,n,r){void 0===t&&(t=[-10,0]),void 0===n&&(n=[0,10]),void 0===r&&(r=[0,0]),e.call(this,De,Oe),this.red=t,this.green=n,this.blue=r}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={red:{configurable:!0},green:{configurable:!0},blue:{configurable:!0}};return n.red.get=function(){return this.uniforms.red},n.red.set=function(e){this.uniforms.red=e},n.green.get=function(){return this.uniforms.green},n.green.set=function(e){this.uniforms.green=e},n.blue.get=function(){return this.uniforms.blue},n.blue.set=function(e){this.uniforms.blue=e},Object.defineProperties(t.prototype,n),t}(t.Filter),Me=n,Re="varying vec2 vTextureCoord;\nuniform sampler2D uSampler;\nuniform vec4 filterArea;\nuniform vec4 filterClamp;\n\nuniform vec2 center;\n\nuniform float amplitude;\nuniform float wavelength;\n// uniform float power;\nuniform float brightness;\nuniform float speed;\nuniform float radius;\n\nuniform float time;\n\nconst float PI = 3.14159;\n\nvoid main()\n{\n float halfWavelength = wavelength * 0.5 / filterArea.x;\n float maxRadius = radius / filterArea.x;\n float currentRadius = time * speed / filterArea.x;\n\n float fade = 1.0;\n\n if (maxRadius > 0.0) {\n if (currentRadius > maxRadius) {\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n return;\n }\n fade = 1.0 - pow(currentRadius / maxRadius, 2.0);\n }\n\n vec2 dir = vec2(vTextureCoord - center / filterArea.xy);\n dir.y *= filterArea.y / filterArea.x;\n float dist = length(dir);\n\n if (dist <= 0.0 || dist < currentRadius - halfWavelength || dist > currentRadius + halfWavelength) {\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n return;\n }\n\n vec2 diffUV = normalize(dir);\n\n float diff = (dist - currentRadius) / halfWavelength;\n\n float p = 1.0 - pow(abs(diff), 2.0);\n\n // float powDiff = diff * pow(p, 2.0) * ( amplitude * fade );\n float powDiff = 1.25 * sin(diff * PI) * p * ( amplitude * fade );\n\n vec2 offset = diffUV * powDiff / filterArea.xy;\n\n // Do clamp :\n vec2 coord = vTextureCoord + offset;\n vec2 clampedCoord = clamp(coord, filterClamp.xy, filterClamp.zw);\n vec4 color = texture2D(uSampler, clampedCoord);\n if (coord != clampedCoord) {\n color *= max(0.0, 1.0 - length(coord - clampedCoord));\n }\n\n // No clamp :\n // gl_FragColor = texture2D(uSampler, vTextureCoord + offset);\n\n color.rgb *= 1.0 + (brightness - 1.0) * p * fade;\n\n gl_FragColor = color;\n}\n",je=function(e){function t(t,n,r){void 0===t&&(t=[0,0]),void 0===n&&(n={}),void 0===r&&(r=0),e.call(this,Me,Re),this.center=t,Array.isArray(n)&&(console.warn("Deprecated Warning: ShockwaveFilter params Array has been changed to options Object."),n={}),n=Object.assign({amplitude:30,wavelength:160,brightness:1,speed:500,radius:-1},n),this.amplitude=n.amplitude,this.wavelength=n.wavelength,this.brightness=n.brightness,this.speed=n.speed,this.radius=n.radius,this.time=r}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={center:{configurable:!0},amplitude:{configurable:!0},wavelength:{configurable:!0},brightness:{configurable:!0},speed:{configurable:!0},radius:{configurable:!0}};return t.prototype.apply=function(e,t,n,r){this.uniforms.time=this.time,e.applyFilter(this,t,n,r)},n.center.get=function(){return this.uniforms.center},n.center.set=function(e){this.uniforms.center=e},n.amplitude.get=function(){return this.uniforms.amplitude},n.amplitude.set=function(e){this.uniforms.amplitude=e},n.wavelength.get=function(){return this.uniforms.wavelength},n.wavelength.set=function(e){this.uniforms.wavelength=e},n.brightness.get=function(){return this.uniforms.brightness},n.brightness.set=function(e){this.uniforms.brightness=e},n.speed.get=function(){return this.uniforms.speed},n.speed.set=function(e){this.uniforms.speed=e},n.radius.get=function(){return this.uniforms.radius},n.radius.set=function(e){this.uniforms.radius=e},Object.defineProperties(t.prototype,n),t}(t.Filter),Le=n,ke="varying vec2 vTextureCoord;\nuniform sampler2D uSampler;\nuniform sampler2D uLightmap;\nuniform vec4 filterArea;\nuniform vec2 dimensions;\nuniform vec4 ambientColor;\nvoid main() {\n vec4 diffuseColor = texture2D(uSampler, vTextureCoord);\n vec2 lightCoord = (vTextureCoord * filterArea.xy) / dimensions;\n vec4 light = texture2D(uLightmap, lightCoord);\n vec3 ambient = ambientColor.rgb * ambientColor.a;\n vec3 intensity = ambient + light.rgb;\n vec3 finalColor = diffuseColor.rgb * intensity;\n gl_FragColor = vec4(finalColor, diffuseColor.a);\n}\n",Ie=function(e){function n(t,n,r){void 0===n&&(n=0),void 0===r&&(r=1),e.call(this,Le,ke),this.uniforms.dimensions=new Float32Array(2),this.uniforms.ambientColor=new Float32Array([0,0,0,r]),this.texture=t,this.color=n}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={texture:{configurable:!0},color:{configurable:!0},alpha:{configurable:!0}};return n.prototype.apply=function(e,t,n,r){this.uniforms.dimensions[0]=t.sourceFrame.width,this.uniforms.dimensions[1]=t.sourceFrame.height,e.applyFilter(this,t,n,r)},r.texture.get=function(){return this.uniforms.uLightmap},r.texture.set=function(e){this.uniforms.uLightmap=e},r.color.set=function(e){var n=this.uniforms.ambientColor;"number"==typeof e?(t.utils.hex2rgb(e,n),this._color=e):(n[0]=e[0],n[1]=e[1],n[2]=e[2],n[3]=e[3],this._color=t.utils.rgb2hex(n))},r.color.get=function(){return this._color},r.alpha.get=function(){return this.uniforms.ambientColor[3]},r.alpha.set=function(e){this.uniforms.ambientColor[3]=e},Object.defineProperties(n.prototype,r),n}(t.Filter),Ee=n,Be="varying vec2 vTextureCoord;\n\nuniform sampler2D uSampler;\nuniform float blur;\nuniform float gradientBlur;\nuniform vec2 start;\nuniform vec2 end;\nuniform vec2 delta;\nuniform vec2 texSize;\n\nfloat random(vec3 scale, float seed)\n{\n return fract(sin(dot(gl_FragCoord.xyz + seed, scale)) * 43758.5453 + seed);\n}\n\nvoid main(void)\n{\n vec4 color = vec4(0.0);\n float total = 0.0;\n\n float offset = random(vec3(12.9898, 78.233, 151.7182), 0.0);\n vec2 normal = normalize(vec2(start.y - end.y, end.x - start.x));\n float radius = smoothstep(0.0, 1.0, abs(dot(vTextureCoord * texSize - start, normal)) / gradientBlur) * blur;\n\n for (float t = -30.0; t <= 30.0; t++)\n {\n float percent = (t + offset - 0.5) / 30.0;\n float weight = 1.0 - abs(percent);\n vec4 sample = texture2D(uSampler, vTextureCoord + delta / texSize * percent * radius);\n sample.rgb *= sample.a;\n color += sample * weight;\n total += weight;\n }\n\n color /= total;\n color.rgb /= color.a + 0.00001;\n\n gl_FragColor = color;\n}\n",Xe=function(e){function n(n,r,o,i){void 0===n&&(n=100),void 0===r&&(r=600),void 0===o&&(o=null),void 0===i&&(i=null),e.call(this,Ee,Be),this.uniforms.blur=n,this.uniforms.gradientBlur=r,this.uniforms.start=o||new t.Point(0,window.innerHeight/2),this.uniforms.end=i||new t.Point(600,window.innerHeight/2),this.uniforms.delta=new t.Point(30,30),this.uniforms.texSize=new t.Point(window.innerWidth,window.innerHeight),this.updateDelta()}e&&(n.__proto__=e),n.prototype=Object.create(e&&e.prototype),n.prototype.constructor=n;var r={blur:{configurable:!0},gradientBlur:{configurable:!0},start:{configurable:!0},end:{configurable:!0}};return n.prototype.updateDelta=function(){this.uniforms.delta.x=0,this.uniforms.delta.y=0},r.blur.get=function(){return this.uniforms.blur},r.blur.set=function(e){this.uniforms.blur=e},r.gradientBlur.get=function(){return this.uniforms.gradientBlur},r.gradientBlur.set=function(e){this.uniforms.gradientBlur=e},r.start.get=function(){return this.uniforms.start},r.start.set=function(e){this.uniforms.start=e,this.updateDelta()},r.end.get=function(){return this.uniforms.end},r.end.set=function(e){this.uniforms.end=e,this.updateDelta()},Object.defineProperties(n.prototype,r),n}(t.Filter),qe=function(e){function t(){e.apply(this,arguments)}return e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t,t.prototype.updateDelta=function(){var e=this.uniforms.end.x-this.uniforms.start.x,t=this.uniforms.end.y-this.uniforms.start.y,n=Math.sqrt(e*e+t*t);this.uniforms.delta.x=e/n,this.uniforms.delta.y=t/n},t}(Xe),Ne=function(e){function t(){e.apply(this,arguments)}return e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t,t.prototype.updateDelta=function(){var e=this.uniforms.end.x-this.uniforms.start.x,t=this.uniforms.end.y-this.uniforms.start.y,n=Math.sqrt(e*e+t*t);this.uniforms.delta.x=-t/n,this.uniforms.delta.y=e/n},t}(Xe),Ge=function(e){function t(t,n,r,o){void 0===t&&(t=100),void 0===n&&(n=600),void 0===r&&(r=null),void 0===o&&(o=null),e.call(this),this.tiltShiftXFilter=new qe(t,n,r,o),this.tiltShiftYFilter=new Ne(t,n,r,o)}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={blur:{configurable:!0},gradientBlur:{configurable:!0},start:{configurable:!0},end:{configurable:!0}};return t.prototype.apply=function(e,t,n){var r=e.getRenderTarget(!0);this.tiltShiftXFilter.apply(e,t,r),this.tiltShiftYFilter.apply(e,r,n),e.returnRenderTarget(r)},n.blur.get=function(){return this.tiltShiftXFilter.blur},n.blur.set=function(e){this.tiltShiftXFilter.blur=this.tiltShiftYFilter.blur=e},n.gradientBlur.get=function(){return this.tiltShiftXFilter.gradientBlur},n.gradientBlur.set=function(e){this.tiltShiftXFilter.gradientBlur=this.tiltShiftYFilter.gradientBlur=e},n.start.get=function(){return this.tiltShiftXFilter.start},n.start.set=function(e){this.tiltShiftXFilter.start=this.tiltShiftYFilter.start=e},n.end.get=function(){return this.tiltShiftXFilter.end},n.end.set=function(e){this.tiltShiftXFilter.end=this.tiltShiftYFilter.end=e},Object.defineProperties(t.prototype,n),t}(t.Filter),Ke=n,Ye="varying vec2 vTextureCoord;\n\nuniform sampler2D uSampler;\nuniform float radius;\nuniform float angle;\nuniform vec2 offset;\nuniform vec4 filterArea;\n\nvec2 mapCoord( vec2 coord )\n{\n coord *= filterArea.xy;\n coord += filterArea.zw;\n\n return coord;\n}\n\nvec2 unmapCoord( vec2 coord )\n{\n coord -= filterArea.zw;\n coord /= filterArea.xy;\n\n return coord;\n}\n\nvec2 twist(vec2 coord)\n{\n coord -= offset;\n\n float dist = length(coord);\n\n if (dist < radius)\n {\n float ratioDist = (radius - dist) / radius;\n float angleMod = ratioDist * ratioDist * angle;\n float s = sin(angleMod);\n float c = cos(angleMod);\n coord = vec2(coord.x * c - coord.y * s, coord.x * s + coord.y * c);\n }\n\n coord += offset;\n\n return coord;\n}\n\nvoid main(void)\n{\n\n vec2 coord = mapCoord(vTextureCoord);\n\n coord = twist(coord);\n\n coord = unmapCoord(coord);\n\n gl_FragColor = texture2D(uSampler, coord );\n\n}\n",We=function(e){function t(t,n,r){void 0===t&&(t=200),void 0===n&&(n=4),void 0===r&&(r=20),e.call(this,Ke,Ye),this.radius=t,this.angle=n,this.padding=r}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={offset:{configurable:!0},radius:{configurable:!0},angle:{configurable:!0}};return n.offset.get=function(){return this.uniforms.offset},n.offset.set=function(e){this.uniforms.offset=e},n.radius.get=function(){return this.uniforms.radius},n.radius.set=function(e){this.uniforms.radius=e},n.angle.get=function(){return this.uniforms.angle},n.angle.set=function(e){this.uniforms.angle=e},Object.defineProperties(t.prototype,n),t}(t.Filter),Qe=n,Ue="varying vec2 vTextureCoord;\nuniform sampler2D uSampler;\nuniform vec4 filterArea;\n\nuniform vec2 uCenter;\nuniform float uStrength;\nuniform float uInnerRadius;\nuniform float uRadius;\n\nconst float MAX_KERNEL_SIZE = 32.0;\n\nfloat random(vec3 scale, float seed) {\n // use the fragment position for a different seed per-pixel\n return fract(sin(dot(gl_FragCoord.xyz + seed, scale)) * 43758.5453 + seed);\n}\n\nvoid main() {\n\n float minGradient = uInnerRadius * 0.3;\n float innerRadius = (uInnerRadius + minGradient * 0.5) / filterArea.x;\n\n float gradient = uRadius * 0.3;\n float radius = (uRadius - gradient * 0.5) / filterArea.x;\n\n float countLimit = MAX_KERNEL_SIZE;\n\n vec2 dir = vec2(uCenter.xy / filterArea.xy - vTextureCoord);\n float dist = length(vec2(dir.x, dir.y * filterArea.y / filterArea.x));\n\n float strength = uStrength;\n\n float delta = 0.0;\n float gap;\n if (dist < innerRadius) {\n delta = innerRadius - dist;\n gap = minGradient;\n } else if (radius >= 0.0 && dist > radius) { // radius < 0 means it's infinity\n delta = dist - radius;\n gap = gradient;\n }\n\n if (delta > 0.0) {\n float normalCount = gap / filterArea.x;\n delta = (normalCount - delta) / normalCount;\n countLimit *= delta;\n strength *= delta;\n if (countLimit < 1.0)\n {\n gl_FragColor = texture2D(uSampler, vTextureCoord);\n return;\n }\n }\n\n // randomize the lookup values to hide the fixed number of samples\n float offset = random(vec3(12.9898, 78.233, 151.7182), 0.0);\n\n float total = 0.0;\n vec4 color = vec4(0.0);\n\n dir *= strength;\n\n for (float t = 0.0; t < MAX_KERNEL_SIZE; t++) {\n float percent = (t + offset) / MAX_KERNEL_SIZE;\n float weight = 4.0 * (percent - percent * percent);\n vec2 p = vTextureCoord + dir * percent;\n vec4 sample = texture2D(uSampler, p);\n\n // switch to pre-multiplied alpha to correctly blur transparent images\n // sample.rgb *= sample.a;\n\n color += sample * weight;\n total += weight;\n\n if (t > countLimit){\n break;\n }\n }\n\n color /= total;\n // switch back from pre-multiplied alpha\n color.rgb /= color.a + 0.00001;\n\n gl_FragColor = color;\n}\n",Ze=function(e){function t(t,n,r,o){void 0===t&&(t=.1),void 0===n&&(n=[0,0]),void 0===r&&(r=0),void 0===o&&(o=-1),e.call(this,Qe,Ue),this.center=n,this.strength=t,this.innerRadius=r,this.radius=o}e&&(t.__proto__=e),t.prototype=Object.create(e&&e.prototype),t.prototype.constructor=t;var n={center:{configurable:!0},strength:{configurable:!0},innerRadius:{configurable:!0},radius:{configurable:!0}};return n.center.get=function(){return this.uniforms.uCenter},n.center.set=function(e){this.uniforms.uCenter=e},n.strength.get=function(){return this.uniforms.uStrength},n.strength.set=function(e){this.uniforms.uStrength=e},n.innerRadius.get=function(){return this.uniforms.uInnerRadius},n.innerRadius.set=function(e){this.uniforms.uInnerRadius=e},n.radius.get=function(){return this.uniforms.uRadius},n.radius.set=function(e){(e<0||e===1/0)&&(e=-1),this.uniforms.uRadius=e},Object.defineProperties(t.prototype,n),t}(t.Filter);return e.AdjustmentFilter=o,e.AdvancedBloomFilter=p,e.AsciiFilter=g,e.BevelFilter=y,e.BloomFilter=F,e.BulgePinchFilter=w,e.ColorMapFilter=O,e.ColorReplaceFilter=R,e.ConvolutionFilter=k,e.CrossHatchFilter=B,e.CRTFilter=N,e.DotFilter=Y,e.DropShadowFilter=U,e.EmbossFilter=H,e.GlitchFilter=ee,e.GlowFilter=re,e.GodrayFilter=se,e.KawaseBlurFilter=a,e.MotionBlurFilter=ce,e.MultiColorReplaceFilter=pe,e.OldFilmFilter=ge,e.OutlineFilter=ye,e.PixelateFilter=Ce,e.RadialBlurFilter=ze,e.ReflectionFilter=Te,e.RGBSplitFilter=Pe,e.ShockwaveFilter=je,e.SimpleLightmapFilter=Ie,e.TiltShiftFilter=Ge,e.TiltShiftAxisFilter=Xe,e.TiltShiftXFilter=qe,e.TiltShiftYFilter=Ne,e.TwistFilter=We,e.ZoomBlurFilter=Ze,e}({},PIXI);Object.assign(PIXI.filters,this?this.__filters:__filters);
+//# sourceMappingURL=pixi-filters.js.map
diff --git a/ttsim/docs/pixi.min.js b/ttsim/docs/pixi.min.js
new file mode 100644
index 0000000..76b8321
--- /dev/null
+++ b/ttsim/docs/pixi.min.js
@@ -0,0 +1,22 @@
+/*!
+ * pixi.js - v4.8.1
+ * Compiled Wed, 06 Jun 2018 15:38:05 UTC
+ *
+ * pixi.js is licensed under the MIT License.
+ * http://www.opensource.org/licenses/mit-license
+ */
+!function(t){if("object"==typeof exports&&"undefined"!=typeof module)module.exports=t();else if("function"==typeof define&&define.amd)define([],t);else{var e;e="undefined"!=typeof window?window:"undefined"!=typeof global?global:"undefined"!=typeof self?self:this,e.PIXI=t()}}(function(){var t;return function(){function t(e,r,n){function i(s,a){if(!r[s]){if(!e[s]){var u="function"==typeof require&&require;if(!a&&u)return u(s,!0);if(o)return o(s,!0);var h=new Error("Cannot find module '"+s+"'");throw h.code="MODULE_NOT_FOUND",h}var l=r[s]={exports:{}};e[s][0].call(l.exports,function(t){var r=e[s][1][t];return i(r||t)},l,l.exports,t,e,r,n)}return r[s].exports}for(var o="function"==typeof require&&require,s=0;s0)-(t<0)},r.abs=function(t){var e=t>>31;return(t^e)-e},r.min=function(t,e){return e^(t^e)&-(t65535)<<4,t>>>=e,r=(t>255)<<3,t>>>=r,e|=r,r=(t>15)<<2,t>>>=r,e|=r,r=(t>3)<<1,t>>>=r,(e|=r)|t>>1},r.log10=function(t){return t>=1e9?9:t>=1e8?8:t>=1e7?7:t>=1e6?6:t>=1e5?5:t>=1e4?4:t>=1e3?3:t>=100?2:t>=10?1:0},r.popCount=function(t){return t-=t>>>1&1431655765,16843009*((t=(858993459&t)+(t>>>2&858993459))+(t>>>4)&252645135)>>>24},r.countTrailingZeros=n,r.nextPow2=function(t){return t+=0===t,--t,t|=t>>>1,t|=t>>>2,t|=t>>>4,t|=t>>>8,(t|=t>>>16)+1},r.prevPow2=function(t){return t|=t>>>1,t|=t>>>2,t|=t>>>4,t|=t>>>8,(t|=t>>>16)-(t>>>1)},r.parity=function(t){return t^=t>>>16,t^=t>>>8,t^=t>>>4,27030>>>(t&=15)&1};var i=new Array(256);!function(t){for(var e=0;e<256;++e){var r=e,n=e,i=7;for(r>>>=1;r;r>>>=1)n<<=1,n|=1&r,--i;t[e]=n<>>8&255]<<16|i[t>>>16&255]<<8|i[t>>>24&255]},r.interleave2=function(t,e){return t&=65535,t=16711935&(t|t<<8),t=252645135&(t|t<<4),t=858993459&(t|t<<2),t=1431655765&(t|t<<1),e&=65535,e=16711935&(e|e<<8),e=252645135&(e|e<<4),e=858993459&(e|e<<2),e=1431655765&(e|e<<1),t|e<<1},r.deinterleave2=function(t,e){return t=t>>>e&1431655765,t=858993459&(t|t>>>1),t=252645135&(t|t>>>2),t=16711935&(t|t>>>4),(t=65535&(t|t>>>16))<<16>>16},r.interleave3=function(t,e,r){return t&=1023,t=4278190335&(t|t<<16),t=251719695&(t|t<<8),t=3272356035&(t|t<<4),t=1227133513&(t|t<<2),e&=1023,e=4278190335&(e|e<<16),e=251719695&(e|e<<8),e=3272356035&(e|e<<4),e=1227133513&(e|e<<2),t|=e<<1,r&=1023,r=4278190335&(r|r<<16),r=251719695&(r|r<<8),r=3272356035&(r|r<<4),r=1227133513&(r|r<<2),t|r<<2},r.deinterleave3=function(t,e){return t=t>>>e&1227133513,t=3272356035&(t|t>>>2),t=251719695&(t|t>>>4),t=4278190335&(t|t>>>8),(t=1023&(t|t>>>16))<<22>>22},r.nextCombination=function(t){var e=t|t-1;return e+1|(~e&-~e)-1>>>n(t)+1}},{}],2:[function(t,e,r){"use strict";function n(t,e,r){r=r||2;var n=e&&e.length,o=n?e[0]*r:t.length,a=i(t,0,o,r,!0),u=[];if(!a)return u;var h,l,d,f,p,v,g;if(n&&(a=c(t,e,a,r)),t.length>80*r){h=d=t[0],l=f=t[1];for(var y=r;yd&&(d=p),v>f&&(f=v);g=Math.max(d-h,f-l),g=0!==g?1/g:0}return s(a,u,r,h,l,g),u}function i(t,e,r,n,i){var o,s;if(i===A(t,e,r,n)>0)for(o=e;o=e;o-=n)s=P(o,t[o],t[o+1],s);return s&&T(s,s.next)&&(C(s),s=s.next),s}function o(t,e){if(!t)return t;e||(e=t);var r,n=t;do{if(r=!1,n.steiner||!T(n,n.next)&&0!==x(n.prev,n,n.next))n=n.next;else{if(C(n),(n=e=n.prev)===n.next)break;r=!0}}while(r||n!==e);return e}function s(t,e,r,n,i,c,d){if(t){!d&&c&&v(t,n,i,c);for(var f,p,g=t;t.prev!==t.next;)if(f=t.prev,p=t.next,c?u(t,n,i,c):a(t))e.push(f.i/r),e.push(t.i/r),e.push(p.i/r),C(t),t=p.next,g=p.next;else if((t=p)===g){d?1===d?(t=h(t,e,r),s(t,e,r,n,i,c,2)):2===d&&l(t,e,r,n,i,c):s(o(t),e,r,n,i,c,1);break}}}function a(t){var e=t.prev,r=t,n=t.next;if(x(e,r,n)>=0)return!1;for(var i=t.next.next;i!==t.prev;){if(_(e.x,e.y,r.x,r.y,n.x,n.y,i.x,i.y)&&x(i.prev,i,i.next)>=0)return!1;i=i.next}return!0}function u(t,e,r,n){var i=t.prev,o=t,s=t.next;if(x(i,o,s)>=0)return!1;for(var a=i.xo.x?i.x>s.x?i.x:s.x:o.x>s.x?o.x:s.x,l=i.y>o.y?i.y>s.y?i.y:s.y:o.y>s.y?o.y:s.y,c=y(a,u,e,r,n),d=y(h,l,e,r,n),f=t.prevZ,p=t.nextZ;f&&f.z>=c&&p&&p.z<=d;){if(f!==t.prev&&f!==t.next&&_(i.x,i.y,o.x,o.y,s.x,s.y,f.x,f.y)&&x(f.prev,f,f.next)>=0)return!1;if(f=f.prevZ,p!==t.prev&&p!==t.next&&_(i.x,i.y,o.x,o.y,s.x,s.y,p.x,p.y)&&x(p.prev,p,p.next)>=0)return!1;p=p.nextZ}for(;f&&f.z>=c;){if(f!==t.prev&&f!==t.next&&_(i.x,i.y,o.x,o.y,s.x,s.y,f.x,f.y)&&x(f.prev,f,f.next)>=0)return!1;f=f.prevZ}for(;p&&p.z<=d;){if(p!==t.prev&&p!==t.next&&_(i.x,i.y,o.x,o.y,s.x,s.y,p.x,p.y)&&x(p.prev,p,p.next)>=0)return!1;p=p.nextZ}return!0}function h(t,e,r){var n=t;do{var i=n.prev,o=n.next.next;!T(i,o)&&w(i,n,n.next,o)&&S(i,o)&&S(o,i)&&(e.push(i.i/r),e.push(n.i/r),e.push(o.i/r),C(n),C(n.next),n=t=o),n=n.next}while(n!==t);return n}function l(t,e,r,n,i,a){var u=t;do{for(var h=u.next.next;h!==u.prev;){if(u.i!==h.i&&b(u,h)){var l=M(u,h);return u=o(u,u.next),l=o(l,l.next),s(u,e,r,n,i,a),void s(l,e,r,n,i,a)}h=h.next}u=u.next}while(u!==t)}function c(t,e,r,n){var s,a,u,h,l,c=[];for(s=0,a=e.length;s=n.next.y&&n.next.y!==n.y){var a=n.x+(o-n.y)*(n.next.x-n.x)/(n.next.y-n.y);if(a<=i&&a>s){if(s=a,a===i){if(o===n.y)return n;if(o===n.next.y)return n.next}r=n.x=n.x&&n.x>=l&&i!==n.x&&_(or.x)&&S(n,t)&&(r=n,d=u),n=n.next;return r}function v(t,e,r,n){var i=t;do{null===i.z&&(i.z=y(i.x,i.y,e,r,n)),i.prevZ=i.prev,i.nextZ=i.next,i=i.next}while(i!==t);i.prevZ.nextZ=null,i.prevZ=null,g(i)}function g(t){var e,r,n,i,o,s,a,u,h=1;do{for(r=t,t=null,o=null,s=0;r;){for(s++,n=r,a=0,e=0;e0||u>0&&n;)0!==a&&(0===u||!n||r.z<=n.z)?(i=r,r=r.nextZ,a--):(i=n,n=n.nextZ,u--),o?o.nextZ=i:t=i,i.prevZ=o,o=i;r=n}o.nextZ=null,h*=2}while(s>1);return t}function y(t,e,r,n,i){return t=32767*(t-r)*i,e=32767*(e-n)*i,t=16711935&(t|t<<8),t=252645135&(t|t<<4),t=858993459&(t|t<<2),t=1431655765&(t|t<<1),e=16711935&(e|e<<8),e=252645135&(e|e<<4),e=858993459&(e|e<<2),e=1431655765&(e|e<<1),t|e<<1}function m(t){var e=t,r=t;do{e.x=0&&(t-s)*(n-a)-(r-s)*(e-a)>=0&&(r-s)*(o-a)-(i-s)*(n-a)>=0}function b(t,e){return t.next.i!==e.i&&t.prev.i!==e.i&&!E(t,e)&&S(t,e)&&S(e,t)&&O(t,e)}function x(t,e,r){return(e.y-t.y)*(r.x-e.x)-(e.x-t.x)*(r.y-e.y)}function T(t,e){return t.x===e.x&&t.y===e.y}function w(t,e,r,n){return!!(T(t,e)&&T(r,n)||T(t,n)&&T(r,e))||x(t,e,r)>0!=x(t,e,n)>0&&x(r,n,t)>0!=x(r,n,e)>0}function E(t,e){var r=t;do{if(r.i!==t.i&&r.next.i!==t.i&&r.i!==e.i&&r.next.i!==e.i&&w(r,r.next,t,e))return!0;r=r.next}while(r!==t);return!1}function S(t,e){return x(t.prev,t,t.next)<0?x(t,e,t.next)>=0&&x(t,t.prev,e)>=0:x(t,e,t.prev)<0||x(t,t.next,e)<0}function O(t,e){var r=t,n=!1,i=(t.x+e.x)/2,o=(t.y+e.y)/2;do{r.y>o!=r.next.y>o&&r.next.y!==r.y&&i<(r.next.x-r.x)*(o-r.y)/(r.next.y-r.y)+r.x&&(n=!n),r=r.next}while(r!==t);return n}function M(t,e){var r=new R(t.i,t.x,t.y),n=new R(e.i,e.x,e.y),i=t.next,o=e.prev;return t.next=e,e.prev=t,r.next=i,i.prev=r,n.next=r,r.prev=n,o.next=n,n.prev=o,n}function P(t,e,r,n){var i=new R(t,e,r);return n?(i.next=n.next,i.prev=n,n.next.prev=i,n.next=i):(i.prev=i,i.next=i),i}function C(t){t.next.prev=t.prev,t.prev.next=t.next,t.prevZ&&(t.prevZ.nextZ=t.nextZ),t.nextZ&&(t.nextZ.prevZ=t.prevZ)}function R(t,e,r){this.i=t,this.x=e,this.y=r,this.prev=null,this.next=null,this.z=null,this.prevZ=null,this.nextZ=null,this.steiner=!1}function A(t,e,r,n){for(var i=0,o=e,s=r-n;o0&&(n+=t[i-1].length,r.holes.push(n))}return r}},{}],3:[function(t,e,r){"use strict";function n(){}function i(t,e,r){this.fn=t,this.context=e,this.once=r||!1}function o(){this._events=new n,this._eventsCount=0}var s=Object.prototype.hasOwnProperty,a="~";Object.create&&(n.prototype=Object.create(null),(new n).__proto__||(a=!1)),o.prototype.eventNames=function(){var t,e,r=[];if(0===this._eventsCount)return r;for(e in t=this._events)s.call(t,e)&&r.push(a?e.slice(1):e);return Object.getOwnPropertySymbols?r.concat(Object.getOwnPropertySymbols(t)):r},o.prototype.listeners=function(t,e){var r=a?a+t:t,n=this._events[r];if(e)return!!n;if(!n)return[];if(n.fn)return[n.fn];for(var i=0,o=n.length,s=new Array(o);i=0;n--){var i=t[n];"."===i?t.splice(n,1):".."===i?(t.splice(n,1),r++):r&&(t.splice(n,1),r--)}if(e)for(;r--;r)t.unshift("..");return t}function n(t,e){if(t.filter)return t.filter(e);for(var r=[],n=0;n=-1&&!i;o--){var s=o>=0?arguments[o]:t.cwd();if("string"!=typeof s)throw new TypeError("Arguments to path.resolve must be strings");s&&(r=s+"/"+r,i="/"===s.charAt(0))}return r=e(n(r.split("/"),function(t){return!!t}),!i).join("/"),(i?"/":"")+r||"."},r.normalize=function(t){var i=r.isAbsolute(t),o="/"===s(t,-1);return t=e(n(t.split("/"),function(t){return!!t}),!i).join("/"),t||i||(t="."),t&&o&&(t+="/"),(i?"/":"")+t},r.isAbsolute=function(t){return"/"===t.charAt(0)},r.join=function(){var t=Array.prototype.slice.call(arguments,0);return r.normalize(n(t,function(t,e){if("string"!=typeof t)throw new TypeError("Arguments to path.join must be strings");return t}).join("/"))},r.relative=function(t,e){function n(t){for(var e=0;e=0&&""===t[r];r--);return e>r?[]:t.slice(e,r-e+1)}t=r.resolve(t).substr(1),e=r.resolve(e).substr(1);for(var i=n(t.split("/")),o=n(e.split("/")),s=Math.min(i.length,o.length),a=s,u=0;u=t.byteLength?n.bufferSubData(this.type,e,t):n.bufferData(this.type,t,this.drawType),this.data=t},i.prototype.bind=function(){this.gl.bindBuffer(this.type,this.buffer)},i.createVertexBuffer=function(t,e,r){return new i(t,t.ARRAY_BUFFER,e,r)},i.createIndexBuffer=function(t,e,r){return new i(t,t.ELEMENT_ARRAY_BUFFER,e,r)},i.create=function(t,e,r,n){return new i(t,e,r,n)},i.prototype.destroy=function(){this.gl.deleteBuffer(this.buffer)},e.exports=i},{}],10:[function(t,e,r){var n=t("./GLTexture"),i=function(t,e,r){this.gl=t,this.framebuffer=t.createFramebuffer(),this.stencil=null,this.texture=null,this.width=e||100,this.height=r||100};i.prototype.enableTexture=function(t){var e=this.gl;this.texture=t||new n(e),this.texture.bind(),this.bind(),e.framebufferTexture2D(e.FRAMEBUFFER,e.COLOR_ATTACHMENT0,e.TEXTURE_2D,this.texture.texture,0)},i.prototype.enableStencil=function(){if(!this.stencil){var t=this.gl;this.stencil=t.createRenderbuffer(),t.bindRenderbuffer(t.RENDERBUFFER,this.stencil),t.framebufferRenderbuffer(t.FRAMEBUFFER,t.DEPTH_STENCIL_ATTACHMENT,t.RENDERBUFFER,this.stencil),t.renderbufferStorage(t.RENDERBUFFER,t.DEPTH_STENCIL,this.width,this.height)}},i.prototype.clear=function(t,e,r,n){this.bind();var i=this.gl;i.clearColor(t,e,r,n),i.clear(i.COLOR_BUFFER_BIT|i.DEPTH_BUFFER_BIT)},i.prototype.bind=function(){var t=this.gl;t.bindFramebuffer(t.FRAMEBUFFER,this.framebuffer)},i.prototype.unbind=function(){var t=this.gl;t.bindFramebuffer(t.FRAMEBUFFER,null)},i.prototype.resize=function(t,e){var r=this.gl;this.width=t,this.height=e,this.texture&&this.texture.uploadData(null,t,e),this.stencil&&(r.bindRenderbuffer(r.RENDERBUFFER,this.stencil),r.renderbufferStorage(r.RENDERBUFFER,r.DEPTH_STENCIL,t,e))},i.prototype.destroy=function(){var t=this.gl;this.texture&&this.texture.destroy(),t.deleteFramebuffer(this.framebuffer),this.gl=null,this.stencil=null,this.texture=null},i.createRGBA=function(t,e,r,o){var s=n.fromData(t,null,e,r);s.enableNearestScaling(),s.enableWrapClamp();var a=new i(t,e,r);return a.enableTexture(s),a.unbind(),a},i.createFloat32=function(t,e,r,o){var s=new n.fromData(t,o,e,r);s.enableNearestScaling(),s.enableWrapClamp();var a=new i(t,e,r);return a.enableTexture(s),a.unbind(),a},e.exports=i},{"./GLTexture":12}],11:[function(t,e,r){var n=t("./shader/compileProgram"),i=t("./shader/extractAttributes"),o=t("./shader/extractUniforms"),s=t("./shader/setPrecision"),a=t("./shader/generateUniformAccessObject"),u=function(t,e,r,u,h){this.gl=t,u&&(e=s(e,u),r=s(r,u)),this.program=n(t,e,r,h),this.attributes=i(t,this.program),this.uniformData=o(t,this.program),this.uniforms=a(t,this.uniformData)};u.prototype.bind=function(){return this.gl.useProgram(this.program),this},u.prototype.destroy=function(){this.attributes=null,this.uniformData=null,this.uniforms=null,this.gl.deleteProgram(this.program)},e.exports=u},{"./shader/compileProgram":17,"./shader/extractAttributes":19,"./shader/extractUniforms":20,"./shader/generateUniformAccessObject":21,"./shader/setPrecision":25}],12:[function(t,e,r){var n=function(t,e,r,n,i){this.gl=t,this.texture=t.createTexture(),this.mipmap=!1,this.premultiplyAlpha=!1,this.width=e||-1,this.height=r||-1,this.format=n||t.RGBA,this.type=i||t.UNSIGNED_BYTE};n.prototype.upload=function(t){this.bind();var e=this.gl;e.pixelStorei(e.UNPACK_PREMULTIPLY_ALPHA_WEBGL,this.premultiplyAlpha);var r=t.videoWidth||t.width,n=t.videoHeight||t.height;n!==this.height||r!==this.width?e.texImage2D(e.TEXTURE_2D,0,this.format,this.format,this.type,t):e.texSubImage2D(e.TEXTURE_2D,0,0,0,this.format,this.type,t),this.width=r,this.height=n};var i=!1;n.prototype.uploadData=function(t,e,r){this.bind();var n=this.gl;if(t instanceof Float32Array){if(!i){if(!n.getExtension("OES_texture_float"))throw new Error("floating point textures not available");i=!0}this.type=n.FLOAT}else this.type=this.type||n.UNSIGNED_BYTE;n.pixelStorei(n.UNPACK_PREMULTIPLY_ALPHA_WEBGL,this.premultiplyAlpha),e!==this.width||r!==this.height?n.texImage2D(n.TEXTURE_2D,0,this.format,e,r,0,this.format,this.type,t||null):n.texSubImage2D(n.TEXTURE_2D,0,0,0,e,r,this.format,this.type,t||null),this.width=e,this.height=r},n.prototype.bind=function(t){var e=this.gl;void 0!==t&&e.activeTexture(e.TEXTURE0+t),e.bindTexture(e.TEXTURE_2D,this.texture)},n.prototype.unbind=function(){var t=this.gl;t.bindTexture(t.TEXTURE_2D,null)},n.prototype.minFilter=function(t){var e=this.gl;this.bind(),this.mipmap?e.texParameteri(e.TEXTURE_2D,e.TEXTURE_MIN_FILTER,t?e.LINEAR_MIPMAP_LINEAR:e.NEAREST_MIPMAP_NEAREST):e.texParameteri(e.TEXTURE_2D,e.TEXTURE_MIN_FILTER,t?e.LINEAR:e.NEAREST)},n.prototype.magFilter=function(t){var e=this.gl;this.bind(),e.texParameteri(e.TEXTURE_2D,e.TEXTURE_MAG_FILTER,t?e.LINEAR:e.NEAREST)},n.prototype.enableMipmap=function(){var t=this.gl;this.bind(),this.mipmap=!0,t.generateMipmap(t.TEXTURE_2D)},n.prototype.enableLinearScaling=function(){this.minFilter(!0),this.magFilter(!0)},n.prototype.enableNearestScaling=function(){this.minFilter(!1),this.magFilter(!1)},n.prototype.enableWrapClamp=function(){var t=this.gl;this.bind(),t.texParameteri(t.TEXTURE_2D,t.TEXTURE_WRAP_S,t.CLAMP_TO_EDGE),t.texParameteri(t.TEXTURE_2D,t.TEXTURE_WRAP_T,t.CLAMP_TO_EDGE)},n.prototype.enableWrapRepeat=function(){var t=this.gl;this.bind(),t.texParameteri(t.TEXTURE_2D,t.TEXTURE_WRAP_S,t.REPEAT),t.texParameteri(t.TEXTURE_2D,t.TEXTURE_WRAP_T,t.REPEAT)},n.prototype.enableWrapMirrorRepeat=function(){var t=this.gl;this.bind(),t.texParameteri(t.TEXTURE_2D,t.TEXTURE_WRAP_S,t.MIRRORED_REPEAT),t.texParameteri(t.TEXTURE_2D,t.TEXTURE_WRAP_T,t.MIRRORED_REPEAT)},n.prototype.destroy=function(){this.gl.deleteTexture(this.texture)},n.fromSource=function(t,e,r){var i=new n(t);return i.premultiplyAlpha=r||!1,i.upload(e),i},n.fromData=function(t,e,r,i){var o=new n(t);return o.uploadData(e,r,i),o},e.exports=n},{}],13:[function(t,e,r){function n(t,e){if(this.nativeVaoExtension=null,n.FORCE_NATIVE||(this.nativeVaoExtension=t.getExtension("OES_vertex_array_object")||t.getExtension("MOZ_OES_vertex_array_object")||t.getExtension("WEBKIT_OES_vertex_array_object")),this.nativeState=e,this.nativeVaoExtension){this.nativeVao=this.nativeVaoExtension.createVertexArrayOES();var r=t.getParameter(t.MAX_VERTEX_ATTRIBS);this.nativeState={tempAttribState:new Array(r),attribState:new Array(r)}}this.gl=t,this.attributes=[],this.indexBuffer=null,this.dirty=!1}var i=t("./setVertexAttribArrays");n.prototype.constructor=n,e.exports=n,n.FORCE_NATIVE=!1,n.prototype.bind=function(){if(this.nativeVao){if(this.nativeVaoExtension.bindVertexArrayOES(this.nativeVao),this.dirty)return this.dirty=!1,this.activate(),this;this.indexBuffer&&this.indexBuffer.bind()}else this.activate();return this},n.prototype.unbind=function(){return this.nativeVao&&this.nativeVaoExtension.bindVertexArrayOES(null),this},n.prototype.activate=function(){for(var t=this.gl,e=null,r=0;r1)for(var r=1;r1&&(n=r[0]+"@",t=r[1]),t=t.replace(D,"."),n+s(t.split("."),e).join(".")}function u(t){for(var e,r,n=[],i=0,o=t.length;i=55296&&e<=56319&&i65535&&(t-=65536,e+=F(t>>>10&1023|55296),t=56320|1023&t),e+=F(t)}).join("")}function l(t){return t-48<10?t-22:t-65<26?t-65:t-97<26?t-97:w}function c(t,e){return t+22+75*(t<26)-((0!=e)<<5)}function d(t,e,r){var n=0;for(t=r?B(t/M):t>>1,t+=B(t/e);t>N*S>>1;n+=w)t=B(t/N);return B(n+(N+1)*t/(t+O))}function f(t){var e,r,n,i,s,a,u,c,f,p,v=[],g=t.length,y=0,m=C,_=P;for(r=t.lastIndexOf(R),r<0&&(r=0),n=0;n=128&&o("not-basic"),v.push(t.charCodeAt(n));for(i=r>0?r+1:0;i=g&&o("invalid-input"),c=l(t.charCodeAt(i++)),(c>=w||c>B((T-y)/a))&&o("overflow"),y+=c*a,f=u<=_?E:u>=_+S?S:u-_,!(cB(T/p)&&o("overflow"),a*=p;e=v.length+1,_=d(y-s,e,0==s),B(y/e)>T-m&&o("overflow"),m+=B(y/e),y%=e,v.splice(y++,0,m)}return h(v)}function p(t){var e,r,n,i,s,a,h,l,f,p,v,g,y,m,_,b=[];for(t=u(t),g=t.length,e=C,r=0,s=P,a=0;a=e&&vB((T-r)/y)&&o("overflow"),r+=(h-e)*y,e=h,a=0;aT&&o("overflow"),v==e){for(l=r,f=w;p=f<=s?E:f>=s+S?S:f-s,!(l= 0x80 (not a basic code point)","invalid-input":"Invalid input"},N=w-E,B=Math.floor,F=String.fromCharCode;if(b={version:"1.4.1",ucs2:{decode:u,encode:h},decode:f,encode:p,toASCII:g,toUnicode:v},"function"==typeof t&&"object"==typeof t.amd&&t.amd)t("punycode",function(){return b});else if(y&&m)if(r.exports==y)m.exports=b;else for(x in b)b.hasOwnProperty(x)&&(y[x]=b[x]);else i.punycode=b}(this)}).call(this,"undefined"!=typeof global?global:"undefined"!=typeof self?self:"undefined"!=typeof window?window:{})},{}],28:[function(t,e,r){"use strict";function n(t,e){return Object.prototype.hasOwnProperty.call(t,e)}e.exports=function(t,e,r,o){e=e||"&",r=r||"=";var s={};if("string"!=typeof t||0===t.length)return s;var a=/\+/g;t=t.split(e);var u=1e3;o&&"number"==typeof o.maxKeys&&(u=o.maxKeys);var h=t.length;u>0&&h>u&&(h=u);for(var l=0;l=0?(c=v.substr(0,g),d=v.substr(g+1)):(c=v,d=""),f=decodeURIComponent(c),p=decodeURIComponent(d),n(s,f)?i(s[f])?s[f].push(p):s[f]=[s[f],p]:s[f]=p}return s};var i=Array.isArray||function(t){return"[object Array]"===Object.prototype.toString.call(t)}},{}],29:[function(t,e,r){"use strict";function n(t,e){if(t.map)return t.map(e);for(var r=[],n=0;n=i||0===r)){r=e+r>i?i-e:r;var o=i-r;for(n=e;n0&&void 0!==arguments[0]?arguments[0]:"",n=arguments.length>1&&void 0!==arguments[1]?arguments[1]:10;i(this,t),this.baseUrl=r,this.progress=0,this.loading=!1,this.defaultQueryString="",this._beforeMiddleware=[],this._afterMiddleware=[],this._resourcesParsing=[],this._boundLoadResource=function(t,r){return e._loadResource(t,r)},this._queue=d.queue(this._boundLoadResource,n),this._queue.pause(),this.resources={},this.onProgress=new u.default,this.onError=new u.default,this.onLoad=new u.default,this.onStart=new u.default,this.onComplete=new u.default}return t.prototype.add=function(t,e,r,n){if(Array.isArray(t)){for(var i=0;i0||e.responseType===t.XHR_RESPONSE_TYPE.BUFFER)?n=200:1223===n&&(n=204),2!=(n/100|0))return void this.abort("["+e.status+"] "+e.statusText+": "+e.responseURL);if(this.xhrType===t.XHR_RESPONSE_TYPE.TEXT)this.data=r,this.type=t.TYPE.TEXT;else if(this.xhrType===t.XHR_RESPONSE_TYPE.JSON)try{this.data=JSON.parse(r),this.type=t.TYPE.JSON}catch(t){return void this.abort("Error trying to parse loaded json: "+t)}else if(this.xhrType===t.XHR_RESPONSE_TYPE.DOCUMENT)try{if(window.DOMParser){var i=new DOMParser;this.data=i.parseFromString(r,"text/xml")}else{var o=document.createElement("div");o.innerHTML=r,this.data=o}this.type=t.TYPE.XML}catch(t){return void this.abort("Error trying to parse loaded xml: "+t)}else this.data=e.response||r;this.complete()},t.prototype._determineCrossOrigin=function(t,e){if(0===t.indexOf("data:"))return"";e=e||window.location,p||(p=document.createElement("a")),p.href=t,t=(0,l.default)(p.href,{strictMode:!0});var r=!t.port&&""===e.port||t.port===e.port,n=t.protocol?t.protocol+":":"";return t.host===e.hostname&&r&&n===e.protocol?"":"anonymous"},t.prototype._determineXhrType=function(){return t._xhrTypeMap[this.extension]||t.XHR_RESPONSE_TYPE.TEXT},t.prototype._determineLoadType=function(){return t._loadTypeMap[this.extension]||t.LOAD_TYPE.XHR},t.prototype._getExtension=function(){var t=this.url,e="";if(this.isDataUrl){var r=t.indexOf("/");e=t.substring(r+1,t.indexOf(";",r))}else{var n=t.indexOf("?"),i=t.indexOf("#"),o=Math.min(n>-1?n:t.length,i>-1?i:t.length);t=t.substring(0,o),e=t.substring(t.lastIndexOf(".")+1)}return e.toLowerCase()},t.prototype._getMimeFromXhrType=function(e){switch(e){case t.XHR_RESPONSE_TYPE.BUFFER:return"application/octet-binary";case t.XHR_RESPONSE_TYPE.BLOB:return"application/blob";case t.XHR_RESPONSE_TYPE.DOCUMENT:return"application/xml";case t.XHR_RESPONSE_TYPE.JSON:return"application/json";case t.XHR_RESPONSE_TYPE.DEFAULT:case t.XHR_RESPONSE_TYPE.TEXT:default:return"text/plain"}},u(t,[{key:"isDataUrl",get:function(){return this._hasFlag(t.STATUS_FLAGS.DATA_URL)}},{key:"isComplete",get:function(){return this._hasFlag(t.STATUS_FLAGS.COMPLETE)}},{key:"isLoading",get:function(){return this._hasFlag(t.STATUS_FLAGS.LOADING)}}]),t}();r.default=v,v.STATUS_FLAGS={NONE:0,DATA_URL:1,COMPLETE:2,LOADING:4},v.TYPE={UNKNOWN:0,JSON:1,XML:2,IMAGE:3,AUDIO:4,VIDEO:5,TEXT:6},v.LOAD_TYPE={XHR:1,IMAGE:2,AUDIO:3,VIDEO:4},v.XHR_RESPONSE_TYPE={DEFAULT:"text",BUFFER:"arraybuffer",BLOB:"blob",DOCUMENT:"document",JSON:"json",TEXT:"text"},v._loadTypeMap={gif:v.LOAD_TYPE.IMAGE,png:v.LOAD_TYPE.IMAGE,bmp:v.LOAD_TYPE.IMAGE,jpg:v.LOAD_TYPE.IMAGE,jpeg:v.LOAD_TYPE.IMAGE,tif:v.LOAD_TYPE.IMAGE,tiff:v.LOAD_TYPE.IMAGE,webp:v.LOAD_TYPE.IMAGE,tga:v.LOAD_TYPE.IMAGE,svg:v.LOAD_TYPE.IMAGE,"svg+xml":v.LOAD_TYPE.IMAGE,mp3:v.LOAD_TYPE.AUDIO,ogg:v.LOAD_TYPE.AUDIO,wav:v.LOAD_TYPE.AUDIO,mp4:v.LOAD_TYPE.VIDEO,webm:v.LOAD_TYPE.VIDEO},v._xhrTypeMap={xhtml:v.XHR_RESPONSE_TYPE.DOCUMENT,html:v.XHR_RESPONSE_TYPE.DOCUMENT,htm:v.XHR_RESPONSE_TYPE.DOCUMENT,xml:v.XHR_RESPONSE_TYPE.DOCUMENT,tmx:v.XHR_RESPONSE_TYPE.DOCUMENT,svg:v.XHR_RESPONSE_TYPE.DOCUMENT,tsx:v.XHR_RESPONSE_TYPE.DOCUMENT,gif:v.XHR_RESPONSE_TYPE.BLOB,png:v.XHR_RESPONSE_TYPE.BLOB,bmp:v.XHR_RESPONSE_TYPE.BLOB,jpg:v.XHR_RESPONSE_TYPE.BLOB,jpeg:v.XHR_RESPONSE_TYPE.BLOB,tif:v.XHR_RESPONSE_TYPE.BLOB,tiff:v.XHR_RESPONSE_TYPE.BLOB,webp:v.XHR_RESPONSE_TYPE.BLOB,tga:v.XHR_RESPONSE_TYPE.BLOB,json:v.XHR_RESPONSE_TYPE.JSON,text:v.XHR_RESPONSE_TYPE.TEXT,txt:v.XHR_RESPONSE_TYPE.TEXT,ttf:v.XHR_RESPONSE_TYPE.BUFFER,otf:v.XHR_RESPONSE_TYPE.BUFFER},v.EMPTY_GIF="data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw=="},{"mini-signals":5,"parse-uri":7}],34:[function(t,e,r){"use strict";function n(){}function i(t,e,r,n){var i=0,o=t.length;!function s(a){if(a||i===o)return void(r&&r(a));n?setTimeout(function(){e(t[i++],s)},1):e(t[i++],s)}()}function o(t){return function(){if(null===t)throw new Error("Callback was already called.");var e=t;t=null,e.apply(this,arguments)}}function s(t,e){function r(t,e,r){if(null!=r&&"function"!=typeof r)throw new Error("task callback must be a function");if(a.started=!0,null==t&&a.idle())return void setTimeout(function(){return a.drain()},1);var i={data:t,callback:"function"==typeof r?r:n};e?a._tasks.unshift(i):a._tasks.push(i),setTimeout(function(){return a.process()},1)}function i(t){return function(){s-=1,t.callback.apply(t,arguments),null!=arguments[0]&&a.error(arguments[0],t.data),s<=a.concurrency-a.buffer&&a.unsaturated(),a.idle()&&a.drain(),a.process()}}if(null==e)e=1;else if(0===e)throw new Error("Concurrency must not be zero");var s=0,a={_tasks:[],concurrency:e,saturated:n,unsaturated:n,buffer:e/4,empty:n,drain:n,error:n,started:!1,paused:!1,push:function(t,e){r(t,!1,e)},kill:function(){s=0,a.drain=n,a.started=!1,a._tasks=[]},unshift:function(t,e){r(t,!0,e)},process:function(){for(;!a.paused&&s>2,o[1]=(3&n[0])<<4|n[1]>>4,o[2]=(15&n[1])<<2|n[2]>>6,o[3]=63&n[2];switch(r-(t.length-1)){case 2:o[3]=64,o[2]=64;break;case 1:o[3]=64}for(var a=0;a",'"',"`"," ","\r","\n","\t"],p=["{","}","|","\\","^","`"].concat(f),v=["'"].concat(p),g=["%","/","?",";","#"].concat(v),y=["/","?","#"],m=/^[+a-z0-9A-Z_-]{0,63}$/,_=/^([+a-z0-9A-Z_-]{0,63})(.*)$/,b={javascript:!0,"javascript:":!0},x={javascript:!0,"javascript:":!0},T={http:!0,https:!0,ftp:!0,gopher:!0,file:!0,"http:":!0,"https:":!0,"ftp:":!0,"gopher:":!0,"file:":!0},w=t("querystring");n.prototype.parse=function(t,e,r){if(!h.isString(t))throw new TypeError("Parameter 'url' must be a string, not "+typeof t);var n=t.indexOf("?"),i=-1!==n&&n127?L+="x":L+=D[N];if(!L.match(m)){var F=A.slice(0,O),k=A.slice(O+1),j=D.match(_);j&&(F.push(j[1]),k.unshift(j[2])),k.length&&(a="/"+k.join(".")+a),this.hostname=F.join(".");break}}}this.hostname.length>255?this.hostname="":this.hostname=this.hostname.toLowerCase(),R||(this.hostname=u.toASCII(this.hostname));var U=this.port?":"+this.port:"",X=this.hostname||"";this.host=X+U,this.href+=this.host,R&&(this.hostname=this.hostname.substr(1,this.hostname.length-2),"/"!==a[0]&&(a="/"+a))}if(!b[p])for(var O=0,I=v.length;O0)&&r.host.split("@");S&&(r.auth=S.shift(),r.host=r.hostname=S.shift())}return r.search=t.search,r.query=t.query,h.isNull(r.pathname)&&h.isNull(r.search)||(r.path=(r.pathname?r.pathname:"")+(r.search?r.search:"")),r.href=r.format(),r}if(!w.length)return r.pathname=null,r.search?r.path="/"+r.search:r.path=null,r.href=r.format(),r;for(var O=w.slice(-1)[0],M=(r.host||t.host||w.length>1)&&("."===O||".."===O)||""===O,P=0,C=w.length;C>=0;C--)O=w[C],"."===O?w.splice(C,1):".."===O?(w.splice(C,1),P++):P&&(w.splice(C,1),P--);if(!_&&!b)for(;P--;P)w.unshift("..");!_||""===w[0]||w[0]&&"/"===w[0].charAt(0)||w.unshift(""),M&&"/"!==w.join("/").substr(-1)&&w.push("");var R=""===w[0]||w[0]&&"/"===w[0].charAt(0);if(E){r.hostname=r.host=R?"":w.length?w.shift():"";var S=!!(r.host&&r.host.indexOf("@")>0)&&r.host.split("@");S&&(r.auth=S.shift(),r.host=r.hostname=S.shift())}return _=_||r.host&&w.length,_&&!R&&w.unshift(""),w.length?r.pathname=w.join("/"):(r.pathname=null,r.path=null),h.isNull(r.pathname)&&h.isNull(r.search)||(r.path=(r.pathname?r.pathname:"")+(r.search?r.search:"")),r.auth=t.auth||r.auth,r.slashes=r.slashes||t.slashes,r.href=r.format(),r},n.prototype.parseHost=function(){var t=this.host,e=c.exec(t);e&&(e=e[0],":"!==e&&(this.port=e.substr(1)),t=t.substr(0,t.length-e.length)),t&&(this.hostname=t)}},{"./util":39,punycode:27,querystring:30}],39:[function(t,e,r){"use strict";e.exports={isString:function(t){return"string"==typeof t},isObject:function(t){return"object"==typeof t&&null!==t},isNull:function(t){return null===t},isNullOrUndefined:function(t){return null==t}}},{}],40:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var o=t("../core"),s=function(t){if(t&&t.__esModule)return t;var e={};if(null!=t)for(var r in t)Object.prototype.hasOwnProperty.call(t,r)&&(e[r]=t[r]);return e.default=t,e}(o),a=t("ismobilejs"),u=n(a),h=t("./accessibleTarget"),l=n(h);s.utils.mixins.delayMixin(s.DisplayObject.prototype,l.default);var c=100,d=0,f=0,p=2,v=function(){function t(e){i(this,t),!u.default.tablet&&!u.default.phone||navigator.isCocoonJS||this.createTouchHook();var r=document.createElement("div");r.style.width=c+"px",r.style.height=c+"px",r.style.position="absolute",r.style.top=d+"px",r.style.left=f+"px",r.style.zIndex=p,this.div=r,this.pool=[],this.renderId=0,this.debug=!1,this.renderer=e,this.children=[],this._onKeyDown=this._onKeyDown.bind(this),this._onMouseMove=this._onMouseMove.bind(this),this.isActive=!1,this.isMobileAccessabillity=!1,window.addEventListener("keydown",this._onKeyDown,!1)}return t.prototype.createTouchHook=function(){var t=this,e=document.createElement("button");e.style.width="1px",e.style.height="1px",e.style.position="absolute",e.style.top="-1000px",e.style.left="-1000px",e.style.zIndex=2,e.style.backgroundColor="#FF0000",e.title="HOOK DIV",e.addEventListener("focus",function(){t.isMobileAccessabillity=!0,t.activate(),document.body.removeChild(e)}),document.body.appendChild(e)},t.prototype.activate=function(){this.isActive||(this.isActive=!0,window.document.addEventListener("mousemove",this._onMouseMove,!0),window.removeEventListener("keydown",this._onKeyDown,!1),this.renderer.on("postrender",this.update,this),this.renderer.view.parentNode&&this.renderer.view.parentNode.appendChild(this.div))},t.prototype.deactivate=function(){this.isActive&&!this.isMobileAccessabillity&&(this.isActive=!1,window.document.removeEventListener("mousemove",this._onMouseMove),window.addEventListener("keydown",this._onKeyDown,!1),this.renderer.off("postrender",this.update),this.div.parentNode&&this.div.parentNode.removeChild(this.div))},t.prototype.updateAccessibleObjects=function(t){if(t.visible){t.accessible&&t.interactive&&(t._accessibleActive||this.addChild(t),t.renderId=this.renderId);for(var e=t.children,r=0;rthis.renderer.width&&(t.width=this.renderer.width-t.x),t.y+t.height>this.renderer.height&&(t.height=this.renderer.height-t.y)},t.prototype.addChild=function(t){var e=this.pool.pop();e||(e=document.createElement("button"),e.style.width=c+"px",e.style.height=c+"px",e.style.backgroundColor=this.debug?"rgba(255,0,0,0.5)":"transparent",e.style.position="absolute",e.style.zIndex=p,e.style.borderStyle="none",navigator.userAgent.toLowerCase().indexOf("chrome")>-1?e.setAttribute("aria-live","off"):e.setAttribute("aria-live","polite"),navigator.userAgent.match(/rv:.*Gecko\//)?e.setAttribute("aria-relevant","additions"):e.setAttribute("aria-relevant","text"),e.addEventListener("click",this._onClick.bind(this)),e.addEventListener("focus",this._onFocus.bind(this)),e.addEventListener("focusout",this._onFocusOut.bind(this))),t.accessibleTitle&&null!==t.accessibleTitle?e.title=t.accessibleTitle:t.accessibleHint&&null!==t.accessibleHint||(e.title="displayObject "+t.tabIndex),t.accessibleHint&&null!==t.accessibleHint&&e.setAttribute("aria-label",t.accessibleHint),t._accessibleActive=!0,t._accessibleDiv=e,e.displayObject=t,this.children.push(t),this.div.appendChild(t._accessibleDiv),t._accessibleDiv.tabIndex=t.tabIndex},t.prototype._onClick=function(t){var e=this.renderer.plugins.interaction;e.dispatchEvent(t.target.displayObject,"click",e.eventData)},t.prototype._onFocus=function(t){t.target.getAttribute("aria-live","off")||t.target.setAttribute("aria-live","assertive");var e=this.renderer.plugins.interaction;e.dispatchEvent(t.target.displayObject,"mouseover",e.eventData)},t.prototype._onFocusOut=function(t){t.target.getAttribute("aria-live","off")||t.target.setAttribute("aria-live","polite");var e=this.renderer.plugins.interaction;e.dispatchEvent(t.target.displayObject,"mouseout",e.eventData)},t.prototype._onKeyDown=function(t){9===t.keyCode&&this.activate()},t.prototype._onMouseMove=function(t){0===t.movementX&&0===t.movementY||this.deactivate()},t.prototype.destroy=function(){this.div=null;for(var t=0;t]*(?:\s(width|height)=('|")(\d*(?:\.\d+)?)(?:px)?('|"))[^>]*(?:\s(width|height)=('|")(\d*(?:\.\d+)?)(?:px)?('|"))[^>]*>/i,r.SHAPES={POLY:0,RECT:1,CIRC:2,ELIP:3,RREC:4},r.PRECISION={LOW:"lowp",MEDIUM:"mediump",HIGH:"highp"},r.TRANSFORM_MODE={STATIC:0,DYNAMIC:1},r.TEXT_GRADIENT={LINEAR_VERTICAL:0,LINEAR_HORIZONTAL:1},r.UPDATE_PRIORITY={INTERACTION:50,HIGH:25,NORMAL:0,LOW:-25,UTILITY:-50}},{}],47:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=t("../math"),o=function(){function t(){n(this,t),this.minX=1/0,this.minY=1/0,this.maxX=-1/0,this.maxY=-1/0,this.rect=null}return t.prototype.isEmpty=function(){return this.minX>this.maxX||this.minY>this.maxY},t.prototype.clear=function(){this.updateID++,this.minX=1/0,this.minY=1/0,this.maxX=-1/0,this.maxY=-1/0},t.prototype.getRectangle=function(t){return this.minX>this.maxX||this.minY>this.maxY?i.Rectangle.EMPTY:(t=t||new i.Rectangle(0,0,1,1),t.x=this.minX,t.y=this.minY,t.width=this.maxX-this.minX,t.height=this.maxY-this.minY,t)},t.prototype.addPoint=function(t){this.minX=Math.min(this.minX,t.x),this.maxX=Math.max(this.maxX,t.x),this.minY=Math.min(this.minY,t.y),this.maxY=Math.max(this.maxY,t.y)},t.prototype.addQuad=function(t){var e=this.minX,r=this.minY,n=this.maxX,i=this.maxY,o=t[0],s=t[1];e=on?o:n,i=s>i?s:i,o=t[2],s=t[3],e=on?o:n,i=s>i?s:i,o=t[4],s=t[5],e=on?o:n,i=s>i?s:i,o=t[6],s=t[7],e=on?o:n,i=s>i?s:i,this.minX=e,this.minY=r,this.maxX=n,this.maxY=i},t.prototype.addFrame=function(t,e,r,n,i){var o=t.worldTransform,s=o.a,a=o.b,u=o.c,h=o.d,l=o.tx,c=o.ty,d=this.minX,f=this.minY,p=this.maxX,v=this.maxY,g=s*e+u*r+l,y=a*e+h*r+c;d=gp?g:p,v=y>v?y:v,g=s*n+u*r+l,y=a*n+h*r+c,d=gp?g:p,v=y>v?y:v,g=s*e+u*i+l,y=a*e+h*i+c,d=gp?g:p,v=y>v?y:v,g=s*n+u*i+l,y=a*n+h*i+c,d=gp?g:p,v=y>v?y:v,this.minX=d,this.minY=f,this.maxX=p,this.maxY=v},t.prototype.addVertices=function(t,e,r,n){for(var i=t.worldTransform,o=i.a,s=i.b,a=i.c,u=i.d,h=i.tx,l=i.ty,c=this.minX,d=this.minY,f=this.maxX,p=this.maxY,v=r;vf?m:f,p=_>p?_:p}this.minX=c,this.minY=d,this.maxX=f,this.maxY=p},t.prototype.addBounds=function(t){var e=this.minX,r=this.minY,n=this.maxX,i=this.maxY;this.minX=t.minXn?t.maxX:n,this.maxY=t.maxY>i?t.maxY:i},t.prototype.addBoundsMask=function(t,e){var r=t.minX>e.minX?t.minX:e.minX,n=t.minY>e.minY?t.minY:e.minY,i=t.maxXu?i:u,this.maxY=o>h?o:h}},t.prototype.addBoundsArea=function(t,e){var r=t.minX>e.x?t.minX:e.x,n=t.minY>e.y?t.minY:e.y,i=t.maxXu?i:u,this.maxY=o>h?o:h}},t}();r.default=o},{"../math":70}],48:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function i(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function o(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}r.__esModule=!0;var s=function(){function t(t,e){for(var r=0;r1)for(var r=0;rthis.children.length)throw new Error(t+"addChildAt: The index "+e+" supplied is out of bounds "+this.children.length);return t.parent&&t.parent.removeChild(t),t.parent=this,t.transform._parentID=-1,this.children.splice(e,0,t),this._boundsID++,this.onChildrenChange(e),t.emit("added",this),t},e.prototype.swapChildren=function(t,e){if(t!==e){var r=this.getChildIndex(t),n=this.getChildIndex(e);this.children[r]=e,this.children[n]=t,this.onChildrenChange(r=this.children.length)throw new Error("The index "+e+" supplied is out of bounds "+this.children.length);var r=this.getChildIndex(t);(0,a.removeItems)(this.children,r,1),this.children.splice(e,0,t),this.onChildrenChange(e)},e.prototype.getChildAt=function(t){if(t<0||t>=this.children.length)throw new Error("getChildAt: Index ("+t+") does not exist.");return this.children[t]},e.prototype.removeChild=function(t){var e=arguments.length;if(e>1)for(var r=0;r0&&void 0!==arguments[0]?arguments[0]:0,e=arguments[1],r=t,n="number"==typeof e?e:this.children.length,i=n-r,o=void 0;if(i>0&&i<=n){o=this.children.splice(r,i);for(var s=0;s2&&void 0!==arguments[2]&&arguments[2]||(this._recursivePostUpdateTransform(),this.parent?this.displayObjectUpdateTransform():(this.parent=this._tempDisplayObjectParent,this.displayObjectUpdateTransform(),this.parent=null)),this.worldTransform.apply(t,e)},e.prototype.toLocal=function(t,e,r,n){return e&&(t=e.toGlobal(t,r,n)),n||(this._recursivePostUpdateTransform(),this.parent?this.displayObjectUpdateTransform():(this.parent=this._tempDisplayObjectParent,this.displayObjectUpdateTransform(),this.parent=null)),this.worldTransform.applyInverse(t,r)},e.prototype.renderWebGL=function(t){},e.prototype.renderCanvas=function(t){},e.prototype.setParent=function(t){if(!t||!t.addChild)throw new Error("setParent: Argument must be a Container");return t.addChild(this),t},e.prototype.setTransform=function(){var t=arguments.length>0&&void 0!==arguments[0]?arguments[0]:0,e=arguments.length>1&&void 0!==arguments[1]?arguments[1]:0,r=arguments.length>2&&void 0!==arguments[2]?arguments[2]:1,n=arguments.length>3&&void 0!==arguments[3]?arguments[3]:1,i=arguments.length>4&&void 0!==arguments[4]?arguments[4]:0,o=arguments.length>5&&void 0!==arguments[5]?arguments[5]:0,s=arguments.length>6&&void 0!==arguments[6]?arguments[6]:0,a=arguments.length>7&&void 0!==arguments[7]?arguments[7]:0,u=arguments.length>8&&void 0!==arguments[8]?arguments[8]:0;return this.position.x=t,this.position.y=e,this.scale.x=r||1,this.scale.y=n||1,this.rotation=i,this.skew.x=o,this.skew.y=s,this.pivot.x=a,this.pivot.y=u,this},e.prototype.destroy=function(){this.removeAllListeners(),this.parent&&this.parent.removeChild(this),this.transform=null,this.parent=null,this._bounds=null,this._currentBounds=null,this._mask=null,this.filterArea=null,this.interactive=!1,this.interactiveChildren=!1,this._destroyed=!0},a(e,[{key:"_tempDisplayObjectParent",get:function(){return null===this.tempDisplayObjectParent&&(this.tempDisplayObjectParent=new e),this.tempDisplayObjectParent}},{key:"x",get:function(){return this.position.x},set:function(t){this.transform.position.x=t}},{key:"y",get:function(){return this.position.y},set:function(t){this.transform.position.y=t}},{key:"worldTransform",get:function(){return this.transform.worldTransform}},{key:"localTransform",get:function(){return this.transform.localTransform}},{key:"position",get:function(){return this.transform.position},set:function(t){this.transform.position.copy(t)}},{key:"scale",get:function(){return this.transform.scale},set:function(t){this.transform.scale.copy(t)}},{key:"pivot",get:function(){return this.transform.pivot},set:function(t){this.transform.pivot.copy(t)}},{key:"skew",get:function(){return this.transform.skew},set:function(t){this.transform.skew.copy(t)}},{key:"rotation",get:function(){return this.transform.rotation},set:function(t){this.transform.rotation=t}},{key:"worldVisible",get:function(){var t=this;do{if(!t.visible)return!1;t=t.parent}while(t);return!0}},{key:"mask",get:function(){return this._mask},set:function(t){this._mask&&(this._mask.renderable=!0,this._mask.isMask=!1),this._mask=t,this._mask&&(this._mask.renderable=!1,this._mask.isMask=!0)}},{key:"filters",get:function(){return this._filters&&this._filters.slice()},set:function(t){this._filters=t&&t.slice()}}]),e}(h.default);r.default=b,b.prototype.displayObjectUpdateTransform=b.prototype.updateTransform},{"../const":46,"../math":70,"../settings":101,"./Bounds":47,"./Transform":50,"./TransformStatic":52,eventemitter3:3}],50:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function i(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function o(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}r.__esModule=!0;var s=function(){function t(t,e){for(var r=0;r0&&void 0!==arguments[0]&&arguments[0];i(this,e);var n=o(this,t.call(this));return n.fillAlpha=1,n.lineWidth=0,n.nativeLines=r,n.lineColor=0,n.lineAlignment=.5,n.graphicsData=[],n.tint=16777215,n._prevTint=16777215,n.blendMode=_.BLEND_MODES.NORMAL,n.currentPath=null,n._webGL={},n.isMask=!1,n.boundsPadding=0,n._localBounds=new x.default,n.dirty=0,n.fastRectDirty=-1,n.clearDirty=0,n.boundsDirty=-1,n.cachedSpriteDirty=!1,n._spriteRect=null,n._fastRect=!1,n}return s(e,t),e.prototype.clone=function(){var t=new e;t.renderable=this.renderable,t.fillAlpha=this.fillAlpha,t.lineWidth=this.lineWidth,t.lineColor=this.lineColor,t.lineAlignment=this.lineAlignment,t.tint=this.tint,t.blendMode=this.blendMode,t.isMask=this.isMask,t.boundsPadding=this.boundsPadding,t.dirty=0,t.cachedSpriteDirty=this.cachedSpriteDirty;for(var r=0;re.CURVES.maxSegments&&(r=e.CURVES.maxSegments),r},e.prototype.lineStyle=function(){var t=arguments.length>0&&void 0!==arguments[0]?arguments[0]:0,e=arguments.length>1&&void 0!==arguments[1]?arguments[1]:0,r=arguments.length>2&&void 0!==arguments[2]?arguments[2]:1,n=arguments.length>3&&void 0!==arguments[3]?arguments[3]:.5;if(this.lineWidth=t,this.lineColor=e,this.lineAlpha=r,this.lineAlignment=n,this.currentPath)if(this.currentPath.shape.points.length){var i=new y.Polygon(this.currentPath.shape.points.slice(-2));i.closed=!1,this.drawShape(i)}else this.currentPath.lineWidth=this.lineWidth,this.currentPath.lineColor=this.lineColor,this.currentPath.lineAlpha=this.lineAlpha,this.currentPath.lineAlignment=this.lineAlignment;return this},e.prototype.moveTo=function(t,e){var r=new y.Polygon([t,e]);return r.closed=!1,this.drawShape(r),this},e.prototype.lineTo=function(t,e){return this.currentPath.shape.points.push(t,e),this.dirty++,this},e.prototype.quadraticCurveTo=function(t,r,n,i){this.currentPath?0===this.currentPath.shape.points.length&&(this.currentPath.shape.points=[0,0]):this.moveTo(0,0);var o=this.currentPath.shape.points,s=0,a=0;0===o.length&&this.moveTo(0,0);for(var u=o[o.length-2],h=o[o.length-1],l=e.CURVES.adaptive?this._segmentsCount(this._quadraticCurveLength(u,h,t,r,n,i)):20,c=1;c<=l;++c){var d=c/l;s=u+(t-u)*d,a=h+(r-h)*d,o.push(s+(t+(n-t)*d-s)*d,a+(r+(i-r)*d-a)*d)}return this.dirty++,this},e.prototype.bezierCurveTo=function(t,r,n,i,o,s){this.currentPath?0===this.currentPath.shape.points.length&&(this.currentPath.shape.points=[0,0]):this.moveTo(0,0);var a=this.currentPath.shape.points,u=a[a.length-2],h=a[a.length-1];a.length-=2;var l=e.CURVES.adaptive?this._segmentsCount(this._bezierCurveLength(u,h,t,r,n,i,o,s)):20;return(0,w.default)(u,h,t,r,n,i,o,s,l,a),this.dirty++,this},e.prototype.arcTo=function(t,e,r,n,i){this.currentPath?0===this.currentPath.shape.points.length&&this.currentPath.shape.points.push(t,e):this.moveTo(t,e);var o=this.currentPath.shape.points,s=o[o.length-2],a=o[o.length-1],u=a-e,h=s-t,l=n-e,c=r-t,d=Math.abs(u*c-h*l);if(d<1e-8||0===i)o[o.length-2]===t&&o[o.length-1]===e||o.push(t,e);else{var f=u*u+h*h,p=l*l+c*c,v=u*l+h*c,g=i*Math.sqrt(f)/d,y=i*Math.sqrt(p)/d,m=g*v/f,_=y*v/p,b=g*c+y*h,x=g*l+y*u,T=h*(y+m),w=u*(y+m),E=c*(g+_),S=l*(g+_),O=Math.atan2(w-x,T-b),M=Math.atan2(S-x,E-b);this.arc(b+t,x+e,i,O,M,h*l>c*u)}return this.dirty++,this},e.prototype.arc=function(t,r,n,i,o){var s=arguments.length>5&&void 0!==arguments[5]&&arguments[5];if(i===o)return this;!s&&o<=i?o+=_.PI_2:s&&i<=o&&(i+=_.PI_2);var a=o-i,u=e.CURVES.adaptive?this._segmentsCount(Math.abs(a)*n):40*Math.ceil(Math.abs(a)/_.PI_2);if(0===a)return this;var h=t+Math.cos(i)*n,l=r+Math.sin(i)*n,c=this.currentPath?this.currentPath.shape.points:null;c?c[c.length-2]===h&&c[c.length-1]===l||c.push(h,l):(this.moveTo(h,l),c=this.currentPath.shape.points);for(var d=a/(2*u),f=2*d,p=Math.cos(d),v=Math.sin(d),g=u-1,y=g%1/g,m=0;m<=g;++m){var b=m+y*m,x=d+i+f*b,T=Math.cos(x),w=-Math.sin(x);c.push((p*T+v*w)*n+t,(p*-w+v*T)*n+r)}return this.dirty++,this},e.prototype.beginFill=function(){var t=arguments.length>0&&void 0!==arguments[0]?arguments[0]:0,e=arguments.length>1&&void 0!==arguments[1]?arguments[1]:1;return this.filling=!0,this.fillColor=t,this.fillAlpha=e,this.currentPath&&this.currentPath.shape.points.length<=2&&(this.currentPath.fill=this.filling,this.currentPath.fillColor=this.fillColor,this.currentPath.fillAlpha=this.fillAlpha),this},e.prototype.endFill=function(){return this.filling=!1,this.fillColor=null,this.fillAlpha=1,this},e.prototype.drawRect=function(t,e,r,n){return this.drawShape(new y.Rectangle(t,e,r,n)),this},e.prototype.drawRoundedRect=function(t,e,r,n,i){return this.drawShape(new y.RoundedRectangle(t,e,r,n,i)),this},e.prototype.drawCircle=function(t,e,r){return this.drawShape(new y.Circle(t,e,r)),this},e.prototype.drawEllipse=function(t,e,r,n){return this.drawShape(new y.Ellipse(t,e,r,n)),this},e.prototype.drawPolygon=function(t){var e=t,r=!0;if(e instanceof y.Polygon&&(r=e.closed,e=e.points),!Array.isArray(e)){e=new Array(arguments.length);for(var n=0;n5&&void 0!==arguments[5]?arguments[5]:0;i=i||n/2;for(var s=-1*Math.PI/2+o,a=2*r,u=_.PI_2/a,h=[],l=0;l0)&&(this.lineWidth=0,this.lineAlignment=.5,this.filling=!1,this.boundsDirty=-1,this.dirty++,this.clearDirty++,this.graphicsData.length=0),this.currentPath=null,this._spriteRect=null,this},e.prototype.isFastRect=function(){return 1===this.graphicsData.length&&this.graphicsData[0].shape.type===_.SHAPES.RECT&&!this.graphicsData[0].lineWidth},e.prototype._renderWebGL=function(t){this.dirty!==this.fastRectDirty&&(this.fastRectDirty=this.dirty,this._fastRect=this.isFastRect()),this._fastRect?this._renderSpriteRect(t):(t.setObjectRenderer(t.plugins.graphics),t.plugins.graphics.render(this))},e.prototype._renderSpriteRect=function(t){var e=this.graphicsData[0].shape;this._spriteRect||(this._spriteRect=new g.default(new d.default(d.default.WHITE)));var r=this._spriteRect;if(16777215===this.tint)r.tint=this.graphicsData[0].fillColor;else{var n=C,i=R;(0,m.hex2rgb)(this.graphicsData[0].fillColor,n),(0,m.hex2rgb)(this.tint,i),n[0]*=i[0],n[1]*=i[1],n[2]*=i[2],r.tint=(0,m.rgb2hex)(n)}r.alpha=this.graphicsData[0].fillAlpha,r.worldAlpha=this.worldAlpha*r.alpha,r.blendMode=this.blendMode,r._texture._frame.width=e.width,r._texture._frame.height=e.height,r.transform.worldTransform=this.transform.worldTransform,r.anchor.set(-e.x/e.width,-e.y/e.height),r._onAnchorUpdate(),r._renderWebGL(t)},e.prototype._renderCanvas=function(t){!0!==this.isMask&&t.plugins.graphics.render(this)},e.prototype._calculateBounds=function(){this.boundsDirty!==this.dirty&&(this.boundsDirty=this.dirty,this.updateLocalBounds(),this.cachedSpriteDirty=!0);var t=this._localBounds;this._bounds.addFrame(this.transform,t.minX,t.minY,t.maxX,t.maxY)},e.prototype.containsPoint=function(t){this.worldTransform.applyInverse(t,P);for(var e=this.graphicsData,r=0;re?o+a:e,r=sn?s+u:n;else if(c===_.SHAPES.CIRC)o=i.x,s=i.y,a=i.radius+d/2,u=i.radius+d/2,t=o-ae?o+a:e,r=s-un?s+u:n;else if(c===_.SHAPES.ELIP)o=i.x,s=i.y,a=i.width+d/2,u=i.height+d/2,t=o-ae?o+a:e,r=s-un?s+u:n;else for(var f=i.points,p=0,v=0,g=0,y=0,m=0,b=0,x=0,T=0,w=0;w+2e?x+m:e,r=T-bn?T+b:n)}else t=0,e=0,r=0,n=0;var E=this.boundsPadding;this._localBounds.minX=t-E,this._localBounds.maxX=e+E,this._localBounds.minY=r-E,this._localBounds.maxY=n+E},e.prototype.drawShape=function(t){this.currentPath&&this.currentPath.shape.points.length<=2&&this.graphicsData.pop(),this.currentPath=null;var e=new p.default(this.lineWidth,this.lineColor,this.lineAlpha,this.fillColor,this.fillAlpha,this.filling,this.nativeLines,t,this.lineAlignment);return this.graphicsData.push(e),e.type===_.SHAPES.POLY&&(e.shape.closed=e.shape.closed||this.filling,this.currentPath=e),this.dirty++,e},e.prototype.generateCanvasTexture=function(t){var e=arguments.length>1&&void 0!==arguments[1]?arguments[1]:1,r=this.getLocalBounds(),n=l.default.create(r.width,r.height,t,e);O||(O=new S.default),this.transform.updateLocalTransform(),this.transform.localTransform.copy(M),M.invert(),M.tx-=r.x,M.ty-=r.y,O.render(this,n,!0,M);var i=d.default.fromCanvas(n.baseTexture._canvasRenderTarget.canvas,t,"graphics");return i.baseTexture.resolution=e,i.baseTexture.update(),i},e.prototype.closePath=function(){var t=this.currentPath;return t&&t.shape&&t.shape.close(),this},e.prototype.addHole=function(){var t=this.graphicsData.pop();return this.currentPath=this.graphicsData[this.graphicsData.length-1],this.currentPath.addHole(t.shape),this.currentPath=null,this},e.prototype.destroy=function(e){t.prototype.destroy.call(this,e);for(var r=0;rP?P:M,r.beginPath(),r.moveTo(w,E+M),r.lineTo(w,E+O-M),r.quadraticCurveTo(w,E+O,w+M,E+O),r.lineTo(w+S-M,E+O),r.quadraticCurveTo(w+S,E+O,w+S,E+O-M),r.lineTo(w+S,E+M),r.quadraticCurveTo(w+S,E,w+S-M,E),r.lineTo(w+M,E),r.quadraticCurveTo(w,E,w,E+M),r.closePath(),(u.fillColor||0===u.fillColor)&&(r.globalAlpha=u.fillAlpha*n,r.fillStyle="#"+("00000"+(0|l).toString(16)).substr(-6),r.fill()),u.lineWidth&&(r.globalAlpha=u.lineAlpha*n,r.strokeStyle="#"+("00000"+(0|c).toString(16)).substr(-6),r.stroke())}}},t.prototype.updateGraphicsTint=function(t){t._prevTint=t.tint;for(var e=(t.tint>>16&255)/255,r=(t.tint>>8&255)/255,n=(255&t.tint)/255,i=0;i>16&255)/255*e*255<<16)+((s>>8&255)/255*r*255<<8)+(255&s)/255*n*255,o._lineTint=((a>>16&255)/255*e*255<<16)+((a>>8&255)/255*r*255<<8)+(255&a)/255*n*255}},t.prototype.renderPolygon=function(t,e,r){r.moveTo(t[0],t[1]);for(var n=1;n9&&void 0!==arguments[9]?arguments[9]:[],l=0,c=0,d=0,f=0,p=0;h.push(t,e);for(var v=1,g=0;v<=u;++v)g=v/u,l=1-g,c=l*l,d=c*l,f=g*g,p=f*g,h.push(d*t+3*c*g*r+3*l*f*i+p*s,d*e+3*c*g*n+3*l*f*o+p*a);return h}r.__esModule=!0,r.default=n},{}],57:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function o(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function s(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}r.__esModule=!0;var a=t("../../utils"),u=t("../../const"),h=t("../../renderers/webgl/utils/ObjectRenderer"),l=n(h),c=t("../../renderers/webgl/WebGLRenderer"),d=n(c),f=t("./WebGLGraphicsData"),p=n(f),v=t("./shaders/PrimitiveShader"),g=n(v),y=t("./utils/buildPoly"),m=n(y),_=t("./utils/buildRectangle"),b=n(_),x=t("./utils/buildRoundedRectangle"),T=n(x),w=t("./utils/buildCircle"),E=n(w),S=function(t){function e(r){i(this,e);var n=o(this,t.call(this,r));return n.graphicsDataPool=[],n.primitiveShader=null,n.gl=r.gl,n.CONTEXT_UID=0,n}return s(e,t),e.prototype.onContextChange=function(){this.gl=this.renderer.gl,this.CONTEXT_UID=this.renderer.CONTEXT_UID,this.primitiveShader=new g.default(this.gl)},e.prototype.destroy=function(){l.default.prototype.destroy.call(this);for(var t=0;t32e4)&&(n=this.graphicsDataPool.pop()||new p.default(this.renderer.gl,this.primitiveShader,this.renderer.state.attribsState),n.nativeLines=r,n.reset(e),t.data.push(n)),n.dirty=!0,n},e}(l.default);r.default=S,d.default.registerPlugin("graphics",S)},{"../../const":46,"../../renderers/webgl/WebGLRenderer":84,"../../renderers/webgl/utils/ObjectRenderer":94,"../../utils":125,"./WebGLGraphicsData":58,"./shaders/PrimitiveShader":59,"./utils/buildCircle":60,"./utils/buildPoly":62,"./utils/buildRectangle":63,"./utils/buildRoundedRectangle":64}],58:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=t("pixi-gl-core"),o=function(t){return t&&t.__esModule?t:{default:t}}(i),s=function(){function t(e,r,i){n(this,t),this.gl=e,this.color=[0,0,0],this.points=[],this.indices=[],this.buffer=o.default.GLBuffer.createVertexBuffer(e),this.indexBuffer=o.default.GLBuffer.createIndexBuffer(e),this.dirty=!0,this.nativeLines=!1,this.glPoints=null,this.glIndices=null,this.shader=r,this.vao=new o.default.VertexArrayObject(e,i).addIndex(this.indexBuffer).addAttribute(this.buffer,r.attributes.aVertexPosition,e.FLOAT,!1,24,0).addAttribute(this.buffer,r.attributes.aColor,e.FLOAT,!1,24,8)}return t.prototype.reset=function(){this.points.length=0,this.indices.length=0},t.prototype.upload=function(){this.glPoints=new Float32Array(this.points),this.buffer.upload(this.glPoints),this.glIndices=new Uint16Array(this.indices),this.indexBuffer.upload(this.glIndices),this.dirty=!1},t.prototype.destroy=function(){this.color=null,this.points=null,this.indices=null,this.vao.destroy(),this.buffer.destroy(),this.indexBuffer.destroy(),this.gl=null,this.buffer=null,this.indexBuffer=null,this.glPoints=null,this.glIndices=null},t}();r.default=s},{"pixi-gl-core":15}],59:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function i(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function o(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}r.__esModule=!0;var s=t("../../../Shader"),a=function(t){return t&&t.__esModule?t:{default:t}}(s),u=function(t){function e(r){return n(this,e),i(this,t.call(this,r,["attribute vec2 aVertexPosition;","attribute vec4 aColor;","uniform mat3 translationMatrix;","uniform mat3 projectionMatrix;","uniform float alpha;","uniform vec3 tint;","varying vec4 vColor;","void main(void){"," gl_Position = vec4((projectionMatrix * translationMatrix * vec3(aVertexPosition, 1.0)).xy, 0.0, 1.0);"," vColor = aColor * vec4(tint * alpha, alpha);","}"].join("\n"),["varying vec4 vColor;","void main(void){"," gl_FragColor = vColor;","}"].join("\n")))}return o(e,t),e}(a.default);r.default=u},{"../../../Shader":44}],60:[function(t,e,r){"use strict";function n(t,e,r){var n=t.shape,i=n.x,u=n.y,h=void 0,l=void 0;if(t.type===s.SHAPES.CIRC?(h=n.radius,l=n.radius):(h=n.width,l=n.height),0!==h&&0!==l){var c=Math.floor(30*Math.sqrt(n.radius))||Math.floor(15*Math.sqrt(n.width+n.height)),d=2*Math.PI/c;if(t.fill){var f=(0,a.hex2rgb)(t.fillColor),p=t.fillAlpha,v=f[0]*p,g=f[1]*p,y=f[2]*p,m=e.points,_=e.indices,b=m.length/6;_.push(b);for(var x=0;x196*p*p?(R=O-P,A=M-C,I=Math.sqrt(R*R+A*A),R/=I,A/=I,R*=p,A*=p,h.push(T-R*L,w-A*L),h.push(y,m,_,g),h.push(T+R*N,w+A*N),h.push(y,m,_,g),h.push(T-R*N*L,w-A*L),h.push(y,m,_,g),d++):(h.push(T+(H-T)*L,w+(V-w)*L),h.push(y,m,_,g),h.push(T-(H-T)*N,w-(V-w)*N),h.push(y,m,_,g))}}b=r[2*(c-2)],x=r[2*(c-2)+1],T=r[2*(c-1)],w=r[2*(c-1)+1],O=-(x-w),M=b-T,I=Math.sqrt(O*O+M*M),O/=I,M/=I,O*=p,M*=p,h.push(T-O*L,w-M*L),h.push(y,m,_,g),h.push(T+O*N,w+M*N),h.push(y,m,_,g),l.push(f);for(var Y=0;Y=6){for(var i=[],o=t.holes,u=0;u0&&(0,
+s.default)(t,e,r)}r.__esModule=!0,r.default=i;var o=t("./buildLine"),s=n(o),a=t("../../../utils"),u=t("earcut"),h=n(u)},{"../../../utils":125,"./buildLine":61,earcut:2}],63:[function(t,e,r){"use strict";function n(t,e,r){var n=t.shape,i=n.x,a=n.y,u=n.width,h=n.height;if(t.fill){var l=(0,s.hex2rgb)(t.fillColor),c=t.fillAlpha,d=l[0]*c,f=l[1]*c,p=l[2]*c,v=e.points,g=e.indices,y=v.length/6;v.push(i,a),v.push(d,f,p,c),v.push(i+u,a),v.push(d,f,p,c),v.push(i,a+h),v.push(d,f,p,c),v.push(i+u,a+h),v.push(d,f,p,c),g.push(y,y,y+1,y+2,y+3,y+3)}if(t.lineWidth){var m=t.points;t.points=[i,a,i+u,a,i+u,a+h,i,a+h,i,a],(0,o.default)(t,e,r),t.points=m}}r.__esModule=!0,r.default=n;var i=t("./buildLine"),o=function(t){return t&&t.__esModule?t:{default:t}}(i),s=t("../../../utils")},{"../../../utils":125,"./buildLine":61}],64:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e,r){var n=t.shape,i=n.x,o=n.y,a=n.width,h=n.height,d=n.radius,f=[];if(f.push(i,o+d),s(i,o+h-d,i,o+h,i+d,o+h,f),s(i+a-d,o+h,i+a,o+h,i+a,o+h-d,f),s(i+a,o+d,i+a,o,i+a-d,o,f),s(i+d,o,i,o,i,o+d+1e-10,f),t.fill){for(var p=(0,c.hex2rgb)(t.fillColor),v=t.fillAlpha,g=p[0]*v,y=p[1]*v,m=p[2]*v,_=e.points,b=e.indices,x=_.length/6,T=(0,u.default)(f,null,2),w=0,E=T.length;w6&&void 0!==arguments[6]?arguments[6]:[],u=a,h=0,l=0,c=0,d=0,f=0,p=0,v=0,g=0;v<=20;++v)g=v/20,h=o(t,r,g),l=o(e,n,g),c=o(r,i,g),d=o(n,s,g),f=o(h,c,g),p=o(l,d,g),u.push(f,p);return u}r.__esModule=!0,r.default=i;var a=t("earcut"),u=n(a),h=t("./buildLine"),l=n(h),c=t("../../../utils")},{"../../../utils":125,"./buildLine":61,earcut:2}],65:[function(t,e,r){"use strict";function n(t){if(t&&t.__esModule)return t;var e={};if(null!=t)for(var r in t)Object.prototype.hasOwnProperty.call(t,r)&&(e[r]=t[r]);return e.default=t,e}function i(t){return t&&t.__esModule?t:{default:t}}r.__esModule=!0,r.autoDetectRenderer=r.Application=r.Filter=r.SpriteMaskFilter=r.Quad=r.RenderTarget=r.ObjectRenderer=r.WebGLManager=r.Shader=r.CanvasRenderTarget=r.TextureUvs=r.VideoBaseTexture=r.BaseRenderTexture=r.RenderTexture=r.BaseTexture=r.TextureMatrix=r.Texture=r.Spritesheet=r.CanvasGraphicsRenderer=r.GraphicsRenderer=r.GraphicsData=r.Graphics=r.TextMetrics=r.TextStyle=r.Text=r.SpriteRenderer=r.CanvasTinter=r.CanvasSpriteRenderer=r.Sprite=r.TransformBase=r.TransformStatic=r.Transform=r.Container=r.DisplayObject=r.Bounds=r.glCore=r.WebGLRenderer=r.CanvasRenderer=r.ticker=r.utils=r.settings=void 0;var o=t("./const");Object.keys(o).forEach(function(t){"default"!==t&&"__esModule"!==t&&Object.defineProperty(r,t,{enumerable:!0,get:function(){return o[t]}})});var s=t("./math");Object.keys(s).forEach(function(t){"default"!==t&&"__esModule"!==t&&Object.defineProperty(r,t,{enumerable:!0,get:function(){return s[t]}})});var a=t("pixi-gl-core");Object.defineProperty(r,"glCore",{enumerable:!0,get:function(){return i(a).default}});var u=t("./display/Bounds");Object.defineProperty(r,"Bounds",{enumerable:!0,get:function(){return i(u).default}});var h=t("./display/DisplayObject");Object.defineProperty(r,"DisplayObject",{enumerable:!0,get:function(){return i(h).default}});var l=t("./display/Container");Object.defineProperty(r,"Container",{enumerable:!0,get:function(){return i(l).default}});var c=t("./display/Transform");Object.defineProperty(r,"Transform",{enumerable:!0,get:function(){return i(c).default}});var d=t("./display/TransformStatic");Object.defineProperty(r,"TransformStatic",{enumerable:!0,get:function(){return i(d).default}});var f=t("./display/TransformBase");Object.defineProperty(r,"TransformBase",{enumerable:!0,get:function(){return i(f).default}});var p=t("./sprites/Sprite");Object.defineProperty(r,"Sprite",{enumerable:!0,get:function(){return i(p).default}});var v=t("./sprites/canvas/CanvasSpriteRenderer");Object.defineProperty(r,"CanvasSpriteRenderer",{enumerable:!0,get:function(){return i(v).default}});var g=t("./sprites/canvas/CanvasTinter");Object.defineProperty(r,"CanvasTinter",{enumerable:!0,get:function(){return i(g).default}});var y=t("./sprites/webgl/SpriteRenderer");Object.defineProperty(r,"SpriteRenderer",{enumerable:!0,get:function(){return i(y).default}});var m=t("./text/Text");Object.defineProperty(r,"Text",{enumerable:!0,get:function(){return i(m).default}});var _=t("./text/TextStyle");Object.defineProperty(r,"TextStyle",{enumerable:!0,get:function(){return i(_).default}});var b=t("./text/TextMetrics");Object.defineProperty(r,"TextMetrics",{enumerable:!0,get:function(){return i(b).default}});var x=t("./graphics/Graphics");Object.defineProperty(r,"Graphics",{enumerable:!0,get:function(){return i(x).default}});var T=t("./graphics/GraphicsData");Object.defineProperty(r,"GraphicsData",{enumerable:!0,get:function(){return i(T).default}});var w=t("./graphics/webgl/GraphicsRenderer");Object.defineProperty(r,"GraphicsRenderer",{enumerable:!0,get:function(){return i(w).default}});var E=t("./graphics/canvas/CanvasGraphicsRenderer");Object.defineProperty(r,"CanvasGraphicsRenderer",{enumerable:!0,get:function(){return i(E).default}});var S=t("./textures/Spritesheet");Object.defineProperty(r,"Spritesheet",{enumerable:!0,get:function(){return i(S).default}});var O=t("./textures/Texture");Object.defineProperty(r,"Texture",{enumerable:!0,get:function(){return i(O).default}});var M=t("./textures/TextureMatrix");Object.defineProperty(r,"TextureMatrix",{enumerable:!0,get:function(){return i(M).default}});var P=t("./textures/BaseTexture");Object.defineProperty(r,"BaseTexture",{enumerable:!0,get:function(){return i(P).default}});var C=t("./textures/RenderTexture");Object.defineProperty(r,"RenderTexture",{enumerable:!0,get:function(){return i(C).default}});var R=t("./textures/BaseRenderTexture");Object.defineProperty(r,"BaseRenderTexture",{enumerable:!0,get:function(){return i(R).default}});var A=t("./textures/VideoBaseTexture");Object.defineProperty(r,"VideoBaseTexture",{enumerable:!0,get:function(){return i(A).default}});var I=t("./textures/TextureUvs");Object.defineProperty(r,"TextureUvs",{enumerable:!0,get:function(){return i(I).default}});var D=t("./renderers/canvas/utils/CanvasRenderTarget");Object.defineProperty(r,"CanvasRenderTarget",{enumerable:!0,get:function(){return i(D).default}});var L=t("./Shader");Object.defineProperty(r,"Shader",{enumerable:!0,get:function(){return i(L).default}});var N=t("./renderers/webgl/managers/WebGLManager");Object.defineProperty(r,"WebGLManager",{enumerable:!0,get:function(){return i(N).default}});var B=t("./renderers/webgl/utils/ObjectRenderer");Object.defineProperty(r,"ObjectRenderer",{enumerable:!0,get:function(){return i(B).default}});var F=t("./renderers/webgl/utils/RenderTarget");Object.defineProperty(r,"RenderTarget",{enumerable:!0,get:function(){return i(F).default}});var k=t("./renderers/webgl/utils/Quad");Object.defineProperty(r,"Quad",{enumerable:!0,get:function(){return i(k).default}});var j=t("./renderers/webgl/filters/spriteMask/SpriteMaskFilter");Object.defineProperty(r,"SpriteMaskFilter",{enumerable:!0,get:function(){return i(j).default}});var U=t("./renderers/webgl/filters/Filter");Object.defineProperty(r,"Filter",{enumerable:!0,get:function(){return i(U).default}});var X=t("./Application");Object.defineProperty(r,"Application",{enumerable:!0,get:function(){return i(X).default}});var G=t("./autoDetectRenderer");Object.defineProperty(r,"autoDetectRenderer",{enumerable:!0,get:function(){return G.autoDetectRenderer}});var W=t("./utils"),H=n(W),V=t("./ticker"),Y=n(V),z=t("./settings"),q=i(z),K=t("./renderers/canvas/CanvasRenderer"),Z=i(K),J=t("./renderers/webgl/WebGLRenderer"),Q=i(J);r.settings=q.default,r.utils=H,r.ticker=Y,r.CanvasRenderer=Z.default,r.WebGLRenderer=Q.default},{"./Application":43,"./Shader":44,"./autoDetectRenderer":45,"./const":46,"./display/Bounds":47,"./display/Container":48,"./display/DisplayObject":49,"./display/Transform":50,"./display/TransformBase":51,"./display/TransformStatic":52,"./graphics/Graphics":53,"./graphics/GraphicsData":54,"./graphics/canvas/CanvasGraphicsRenderer":55,"./graphics/webgl/GraphicsRenderer":57,"./math":70,"./renderers/canvas/CanvasRenderer":77,"./renderers/canvas/utils/CanvasRenderTarget":79,"./renderers/webgl/WebGLRenderer":84,"./renderers/webgl/filters/Filter":86,"./renderers/webgl/filters/spriteMask/SpriteMaskFilter":89,"./renderers/webgl/managers/WebGLManager":93,"./renderers/webgl/utils/ObjectRenderer":94,"./renderers/webgl/utils/Quad":95,"./renderers/webgl/utils/RenderTarget":96,"./settings":101,"./sprites/Sprite":102,"./sprites/canvas/CanvasSpriteRenderer":103,"./sprites/canvas/CanvasTinter":104,"./sprites/webgl/SpriteRenderer":106,"./text/Text":108,"./text/TextMetrics":109,"./text/TextStyle":110,"./textures/BaseRenderTexture":111,"./textures/BaseTexture":112,"./textures/RenderTexture":113,"./textures/Spritesheet":114,"./textures/Texture":115,"./textures/TextureMatrix":116,"./textures/TextureUvs":117,"./textures/VideoBaseTexture":118,"./ticker":121,"./utils":125,"pixi-gl-core":15}],66:[function(t,e,r){"use strict";function n(t){return t<0?-1:t>0?1:0}r.__esModule=!0;var i=t("./Matrix"),o=function(t){return t&&t.__esModule?t:{default:t}}(i),s=[1,1,0,-1,-1,-1,0,1,1,1,0,-1,-1,-1,0,1],a=[0,1,1,1,0,-1,-1,-1,0,1,1,1,0,-1,-1,-1],u=[0,-1,-1,-1,0,1,1,1,0,1,1,1,0,-1,-1,-1],h=[1,1,0,-1,-1,-1,0,1,-1,-1,0,1,1,1,0,-1],l=[],c=[];!function(){for(var t=0;t<16;t++){var e=[];c.push(e);for(var r=0;r<16;r++)for(var i=n(s[t]*s[r]+u[t]*a[r]),d=n(a[t]*s[r]+h[t]*a[r]),f=n(s[t]*u[r]+u[t]*h[r]),p=n(a[t]*u[r]+h[t]*h[r]),v=0;v<16;v++)if(s[v]===i&&a[v]===d&&u[v]===f&&h[v]===p){e.push(v);break}}for(var g=0;g<16;g++){var y=new o.default;y.set(s[g],a[g],u[g],h[g],0,0),l.push(y)}}();var d={E:0,SE:1,S:2,SW:3,W:4,NW:5,N:6,NE:7,MIRROR_VERTICAL:8,MIRROR_HORIZONTAL:12,uX:function(t){return s[t]},uY:function(t){return a[t]},vX:function(t){return u[t]},vY:function(t){return h[t]},inv:function(t){return 8&t?15&t:7&-t},add:function(t,e){return c[t][e]},sub:function(t,e){return c[t][d.inv(e)]},rotate180:function(t){return 4^t},isVertical:function(t){return 2==(3&t)},byDirection:function(t,e){return 2*Math.abs(t)<=Math.abs(e)?e>=0?d.S:d.N:2*Math.abs(e)<=Math.abs(t)?t>0?d.E:d.W:e>0?t>0?d.SE:d.SW:t>0?d.NE:d.NW},matrixAppendRotationInv:function(t,e){var r=arguments.length>2&&void 0!==arguments[2]?arguments[2]:0,n=arguments.length>3&&void 0!==arguments[3]?arguments[3]:0,i=l[d.inv(e)];i.tx=r,i.ty=n,t.append(i)}};r.default=d},{"./Matrix":67}],67:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=function(){function t(t,e){for(var r=0;r0&&void 0!==arguments[0]?arguments[0]:1,r=arguments.length>1&&void 0!==arguments[1]?arguments[1]:0,i=arguments.length>2&&void 0!==arguments[2]?arguments[2]:0,o=arguments.length>3&&void 0!==arguments[3]?arguments[3]:1,s=arguments.length>4&&void 0!==arguments[4]?arguments[4]:0,a=arguments.length>5&&void 0!==arguments[5]?arguments[5]:0;n(this,t),this.a=e,this.b=r,this.c=i,this.d=o,this.tx=s,this.ty=a,this.array=null}return t.prototype.fromArray=function(t){this.a=t[0],this.b=t[1],this.c=t[3],this.d=t[4],this.tx=t[2],this.ty=t[5]},t.prototype.set=function(t,e,r,n,i,o){return this.a=t,this.b=e,this.c=r,this.d=n,this.tx=i,this.ty=o,this},t.prototype.toArray=function(t,e){this.array||(this.array=new Float32Array(9));var r=e||this.array;return t?(r[0]=this.a,r[1]=this.b,r[2]=0,r[3]=this.c,r[4]=this.d,r[5]=0,r[6]=this.tx,r[7]=this.ty,r[8]=1):(r[0]=this.a,r[1]=this.c,r[2]=this.tx,r[3]=this.b,r[4]=this.d,r[5]=this.ty,r[6]=0,r[7]=0,r[8]=1),r},t.prototype.apply=function(t,e){e=e||new s.default;var r=t.x,n=t.y;return e.x=this.a*r+this.c*n+this.tx,e.y=this.b*r+this.d*n+this.ty,e},t.prototype.applyInverse=function(t,e){e=e||new s.default;var r=1/(this.a*this.d+this.c*-this.b),n=t.x,i=t.y;return e.x=this.d*r*n+-this.c*r*i+(this.ty*this.c-this.tx*this.d)*r,e.y=this.a*r*i+-this.b*r*n+(-this.ty*this.a+this.tx*this.b)*r,e},t.prototype.translate=function(t,e){return this.tx+=t,this.ty+=e,this},t.prototype.scale=function(t,e){return this.a*=t,this.d*=e,this.c*=t,this.b*=e,this.tx*=t,this.ty*=e,this},t.prototype.rotate=function(t){var e=Math.cos(t),r=Math.sin(t),n=this.a,i=this.c,o=this.tx;return this.a=n*e-this.b*r,this.b=n*r+this.b*e,this.c=i*e-this.d*r,this.d=i*r+this.d*e,this.tx=o*e-this.ty*r,this.ty=o*r+this.ty*e,this},t.prototype.append=function(t){var e=this.a,r=this.b,n=this.c,i=this.d;return this.a=t.a*e+t.b*n,this.b=t.a*r+t.b*i,this.c=t.c*e+t.d*n,this.d=t.c*r+t.d*i,this.tx=t.tx*e+t.ty*n+this.tx,this.ty=t.tx*r+t.ty*i+this.ty,this},t.prototype.setTransform=function(t,e,r,n,i,o,s,a,u){return this.a=Math.cos(s+u)*i,this.b=Math.sin(s+u)*i,this.c=-Math.sin(s-a)*o,this.d=Math.cos(s-a)*o,this.tx=t-(r*this.a+n*this.c),this.ty=e-(r*this.b+n*this.d),this},t.prototype.prepend=function(t){var e=this.tx;if(1!==t.a||0!==t.b||0!==t.c||1!==t.d){var r=this.a,n=this.c;this.a=r*t.a+this.b*t.c,this.b=r*t.b+this.b*t.d,this.c=n*t.a+this.d*t.c,this.d=n*t.b+this.d*t.d}return this.tx=e*t.a+this.ty*t.c+t.tx,this.ty=e*t.b+this.ty*t.d+t.ty,this},t.prototype.decompose=function(t){var e=this.a,r=this.b,n=this.c,i=this.d,o=-Math.atan2(-n,i),s=Math.atan2(r,e),u=Math.abs(o+s);return u<1e-5||Math.abs(a.PI_2-u)<1e-5?(t.rotation=s,e<0&&i>=0&&(t.rotation+=t.rotation<=0?Math.PI:-Math.PI),t.skew.x=t.skew.y=0):(t.rotation=0,t.skew.x=o,t.skew.y=s),t.scale.x=Math.sqrt(e*e+r*r),t.scale.y=Math.sqrt(n*n+i*i),t.position.x=this.tx,t.position.y=this.ty,t},t.prototype.invert=function(){var t=this.a,e=this.b,r=this.c,n=this.d,i=this.tx,o=t*n-e*r;return this.a=n/o,this.b=-e/o,this.c=-r/o,this.d=t/o,this.tx=(r*this.ty-n*i)/o,this.ty=-(t*this.ty-e*i)/o,this},t.prototype.identity=function(){return this.a=1,this.b=0,this.c=0,this.d=1,this.tx=0,this.ty=0,this},t.prototype.clone=function(){var e=new t;return e.a=this.a,e.b=this.b,e.c=this.c,e.d=this.d,e.tx=this.tx,e.ty=this.ty,e},t.prototype.copy=function(t){return t.a=this.a,t.b=this.b,t.c=this.c,t.d=this.d,t.tx=this.tx,t.ty=this.ty,t},i(t,null,[{key:"IDENTITY",get:function(){return new t}},{key:"TEMP_MATRIX",get:function(){return new t}}]),t}();r.default=u},{"../const":46,"./Point":69}],68:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=function(){function t(t,e){for(var r=0;r2&&void 0!==arguments[2]?arguments[2]:0,o=arguments.length>3&&void 0!==arguments[3]?arguments[3]:0;n(this,t),this._x=i,this._y=o,this.cb=e,this.scope=r}return t.prototype.set=function(t,e){var r=t||0,n=e||(0!==e?r:0);this._x===r&&this._y===n||(this._x=r,this._y=n,this.cb.call(this.scope))},t.prototype.copy=function(t){this._x===t.x&&this._y===t.y||(this._x=t.x,this._y=t.y,this.cb.call(this.scope))},i(t,[{key:"x",get:function(){return this._x},set:function(t){this._x!==t&&(this._x=t,this.cb.call(this.scope))}},{key:"y",get:function(){return this._y},set:function(t){this._y!==t&&(this._y=t,this.cb.call(this.scope))}}]),t}();r.default=o},{}],69:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=function(){function t(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:0,r=arguments.length>1&&void 0!==arguments[1]?arguments[1]:0;n(this,t),this.x=e,this.y=r}return t.prototype.clone=function(){return new t(this.x,this.y)},t.prototype.copy=function(t){this.set(t.x,t.y)},t.prototype.equals=function(t){return t.x===this.x&&t.y===this.y},t.prototype.set=function(t,e){this.x=t||0,this.y=e||(0!==e?this.x:0)},t}();r.default=i},{}],70:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}r.__esModule=!0;var i=t("./Point");Object.defineProperty(r,"Point",{enumerable:!0,get:function(){return n(i).default}});var o=t("./ObservablePoint");Object.defineProperty(r,"ObservablePoint",{enumerable:!0,get:function(){return n(o).default}});var s=t("./Matrix");Object.defineProperty(r,"Matrix",{enumerable:!0,get:function(){return n(s).default}});var a=t("./GroupD8");Object.defineProperty(r,"GroupD8",{enumerable:!0,get:function(){return n(a).default}});var u=t("./shapes/Circle");Object.defineProperty(r,"Circle",{enumerable:!0,get:function(){return n(u).default}});var h=t("./shapes/Ellipse");Object.defineProperty(r,"Ellipse",{enumerable:!0,get:function(){return n(h).default}});var l=t("./shapes/Polygon");Object.defineProperty(r,"Polygon",{enumerable:!0,get:function(){return n(l).default}});var c=t("./shapes/Rectangle");Object.defineProperty(r,"Rectangle",{enumerable:!0,get:function(){return n(c).default}});var d=t("./shapes/RoundedRectangle");Object.defineProperty(r,"RoundedRectangle",{enumerable:!0,get:function(){return n(d).default}})},{"./GroupD8":66,"./Matrix":67,"./ObservablePoint":68,"./Point":69,"./shapes/Circle":71,"./shapes/Ellipse":72,"./shapes/Polygon":73,"./shapes/Rectangle":74,"./shapes/RoundedRectangle":75}],71:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=t("./Rectangle"),o=function(t){return t&&t.__esModule?t:{default:t}}(i),s=t("../../const"),a=function(){function t(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:0,r=arguments.length>1&&void 0!==arguments[1]?arguments[1]:0,i=arguments.length>2&&void 0!==arguments[2]?arguments[2]:0;n(this,t),this.x=e,this.y=r,this.radius=i,this.type=s.SHAPES.CIRC}return t.prototype.clone=function(){return new t(this.x,this.y,this.radius)},t.prototype.contains=function(t,e){if(this.radius<=0)return!1;var r=this.radius*this.radius,n=this.x-t,i=this.y-e;return n*=n,i*=i,n+i<=r},t.prototype.getBounds=function(){return new o.default(this.x-this.radius,this.y-this.radius,2*this.radius,2*this.radius)},t}();r.default=a},{"../../const":46,"./Rectangle":74}],72:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=t("./Rectangle"),o=function(t){return t&&t.__esModule?t:{default:t}}(i),s=t("../../const"),a=function(){function t(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:0,r=arguments.length>1&&void 0!==arguments[1]?arguments[1]:0,i=arguments.length>2&&void 0!==arguments[2]?arguments[2]:0,o=arguments.length>3&&void 0!==arguments[3]?arguments[3]:0;n(this,t),this.x=e,this.y=r,this.width=i,this.height=o,this.type=s.SHAPES.ELIP}return t.prototype.clone=function(){return new t(this.x,this.y,this.width,this.height)},t.prototype.contains=function(t,e){if(this.width<=0||this.height<=0)return!1;var r=(t-this.x)/this.width,n=(e-this.y)/this.height;return r*=r,n*=n,r+n<=1},t.prototype.getBounds=function(){return new o.default(this.x-this.width,this.y-this.height,this.width,this.height)},t}();r.default=a},{"../../const":46,"./Rectangle":74}],73:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=t("../Point"),o=function(t){return t&&t.__esModule?t:{default:t}}(i),s=t("../../const"),a=function(){function t(){for(var e=arguments.length,r=Array(e),i=0;ie!=h>e&&t<(e-a)/(h-a)*(u-s)+s&&(r=!r)}return r},t}();r.default=a},{"../../const":46,"../Point":69}],74:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=function(){function t(t,e){for(var r=0;r0&&void 0!==arguments[0]?arguments[0]:0,r=arguments.length>1&&void 0!==arguments[1]?arguments[1]:0,i=arguments.length>2&&void 0!==arguments[2]?arguments[2]:0,s=arguments.length>3&&void 0!==arguments[3]?arguments[3]:0;n(this,t),this.x=Number(e),this.y=Number(r),this.width=Number(i),this.height=Number(s),this.type=o.SHAPES.RECT}return t.prototype.clone=function(){return new t(this.x,this.y,this.width,this.height)},t.prototype.copy=function(t){return this.x=t.x,this.y=t.y,this.width=t.width,this.height=t.height,this},t.prototype.contains=function(t,e){return!(this.width<=0||this.height<=0)&&(t>=this.x&&t=this.y&&et.x+t.width&&(this.width=t.width-this.x,this.width<0&&(this.width=0)),this.y+this.height>t.y+t.height&&(this.height=t.height-this.y,this.height<0&&(this.height=0))},t.prototype.enlarge=function(t){var e=Math.min(this.x,t.x),r=Math.max(this.x+this.width,t.x+t.width),n=Math.min(this.y,t.y),i=Math.max(this.y+this.height,t.y+t.height);this.x=e,this.width=r-e,this.y=n,this.height=i-n},i(t,[{key:"left",get:function(){return this.x}},{key:"right",get:function(){return this.x+this.width}},{key:"top",get:function(){return this.y}},{key:"bottom",get:function(){return this.y+this.height}}],[{key:"EMPTY",get:function(){return new t(0,0,0,0)}}]),t}();r.default=s},{"../../const":46}],75:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=t("../../const"),o=function(){function t(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:0,r=arguments.length>1&&void 0!==arguments[1]?arguments[1]:0,o=arguments.length>2&&void 0!==arguments[2]?arguments[2]:0,s=arguments.length>3&&void 0!==arguments[3]?arguments[3]:0,a=arguments.length>4&&void 0!==arguments[4]?arguments[4]:20;n(this,t),this.x=e,this.y=r,this.width=o,this.height=s,this.radius=a,this.type=i.SHAPES.RREC}return t.prototype.clone=function(){return new t(this.x,this.y,this.width,this.height,this.radius)},t.prototype.contains=function(t,e){if(this.width<=0||this.height<=0)return!1;if(t>=this.x&&t<=this.x+this.width&&e>=this.y&&e<=this.y+this.height){if(e>=this.y+this.radius&&e<=this.y+this.height-this.radius||t>=this.x+this.radius&&t<=this.x+this.width-this.radius)return!0;var r=t-(this.x+this.radius),n=e-(this.y+this.radius),i=this.radius*this.radius;if(r*r+n*n<=i)return!0;if((r=t-(this.x+this.width-this.radius))*r+n*n<=i)return!0;if(n=e-(this.y+this.height-this.radius),r*r+n*n<=i)return!0;if((r=t-(this.x+this.radius))*r+n*n<=i)return!0}return!1},t}();r.default=o},{"../../const":46}],76:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function o(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function s(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}r.__esModule=!0;var a=function(){function t(t,e){for(var r=0;rE?E:w,e.moveTo(_,b+w),e.lineTo(_,b+T-w),e.quadraticCurveTo(_,b+T,_+w,b+T),e.lineTo(_+x-w,b+T),e.quadraticCurveTo(_+x,b+T,_+x,b+T-w),e.lineTo(_+x,b+w),e.quadraticCurveTo(_+x,b,_+x-w,b),e.lineTo(_+w,b),e.quadraticCurveTo(_,b,_,b+w),e.closePath()}}}},t.prototype.popMask=function(t){t.context.restore(),t.invalidateBlendMode()},t.prototype.destroy=function(){},t}();r.default=o},{"../../../const":46}],79:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=function(){function t(t,e){for(var r=0;r0&&void 0!==arguments[0]?arguments[0]:[];return(0,s.default)()?(t[i.BLEND_MODES.NORMAL]="source-over",t[i.BLEND_MODES.ADD]="lighter",t[i.BLEND_MODES.MULTIPLY]="multiply",t[i.BLEND_MODES.SCREEN]="screen",t[i.BLEND_MODES.OVERLAY]="overlay",t[i.BLEND_MODES.DARKEN]="darken",t[i.BLEND_MODES.LIGHTEN]="lighten",t[i.BLEND_MODES.COLOR_DODGE]="color-dodge",t[i.BLEND_MODES.COLOR_BURN]="color-burn",t[i.BLEND_MODES.HARD_LIGHT]="hard-light",t[i.BLEND_MODES.SOFT_LIGHT]="soft-light",t[i.BLEND_MODES.DIFFERENCE]="difference",t[i.BLEND_MODES.EXCLUSION]="exclusion",t[i.BLEND_MODES.HUE]="hue",t[i.BLEND_MODES.SATURATION]="saturate",t[i.BLEND_MODES.COLOR]="color",t[i.BLEND_MODES.LUMINOSITY]="luminosity"):(t[i.BLEND_MODES.NORMAL]="source-over",t[i.BLEND_MODES.ADD]="lighter",t[i.BLEND_MODES.MULTIPLY]="source-over",t[i.BLEND_MODES.SCREEN]="source-over",t[i.BLEND_MODES.OVERLAY]="source-over",t[i.BLEND_MODES.DARKEN]="source-over",t[i.BLEND_MODES.LIGHTEN]="source-over",t[i.BLEND_MODES.COLOR_DODGE]="source-over",t[i.BLEND_MODES.COLOR_BURN]="source-over",t[i.BLEND_MODES.HARD_LIGHT]="source-over",t[i.BLEND_MODES.SOFT_LIGHT]="source-over",t[i.BLEND_MODES.DIFFERENCE]="source-over",t[i.BLEND_MODES.EXCLUSION]="source-over",t[i.BLEND_MODES.HUE]="source-over",t[i.BLEND_MODES.SATURATION]="source-over",t[i.BLEND_MODES.COLOR]="source-over",t[i.BLEND_MODES.LUMINOSITY]="source-over"),t[i.BLEND_MODES.NORMAL_NPM]=t[i.BLEND_MODES.NORMAL],t[i.BLEND_MODES.ADD_NPM]=t[i.BLEND_MODES.ADD],t[i.BLEND_MODES.SCREEN_NPM]=t[i.BLEND_MODES.SCREEN],t}r.__esModule=!0,r.default=n;var i=t("../../../const"),o=t("./canUseNewCanvasBlendModes"),s=function(t){return t&&t.__esModule?t:{default:t}}(o)},{"../../../const":46,"./canUseNewCanvasBlendModes":80}],82:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=t("../../const"),o=t("../../settings"),s=function(t){return t&&t.__esModule?t:{default:t}}(o),a=function(){function t(e){n(this,t),this.renderer=e,this.count=0,this.checkCount=0,this.maxIdle=s.default.GC_MAX_IDLE,this.checkCountMax=s.default.GC_MAX_CHECK_COUNT,this.mode=s.default.GC_MODE}return t.prototype.update=function(){this.count++,this.mode!==i.GC_MODES.MANUAL&&++this.checkCount>this.checkCountMax&&(this.checkCount=0,this.run())},t.prototype.run=function(){for(var t=this.renderer.textureManager,e=t._managedTextures,r=!1,n=0;nthis.maxIdle&&(t.destroyTexture(i,!0),e[n]=null,r=!0)}if(r){for(var o=0,s=0;s=0;r--)this.unload(t.children[r])},t}();r.default=a},{"../../const":46,"../../settings":101}],83:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=t("pixi-gl-core"),o=t("../../const"),s=t("./utils/RenderTarget"),a=function(t){return t&&t.__esModule?t:{default:t}}(s),u=t("../../utils"),h=function(){function t(e){n(this,t),this.renderer=e,this.gl=e.gl,this._managedTextures=[]}return t.prototype.bindTexture=function(){},t.prototype.getTexture=function(){},t.prototype.updateTexture=function(t,e){var r=this.gl,n=!!t._glRenderTargets;if(!t.hasLoaded)return null;var s=this.renderer.boundTextures;if(void 0===e){e=0;for(var u=0;u 0.5)"," {"," color = vec4(1.0, 0.0, 0.0, 1.0);"," }"," else"," {"," color = vec4(0.0, 1.0, 0.0, 1.0);"," }"," gl_FragColor = mix(sample, masky, 0.5);"," gl_FragColor *= sample.a;","}"].join("\n")}}]),t}();r.default=f},{"../../../const":46,"../../../settings":101,"../../../utils":125,"./extractUniformsFromSrc":87}],87:[function(t,e,r){"use strict";function n(t,e,r){var n=i(t),o=i(e);return Object.assign(n,o)}function i(t){for(var e=new RegExp("^(projectionMatrix|uSampler|filterArea|filterClamp)$"),r={},n=void 0,i=t.replace(/\s+/g," ").split(/\s*;\s*/),o=0;o-1){var u=s.split(" "),h=u[1],l=u[2],c=1;l.indexOf("[")>-1&&(n=l.split(/\[|]/),l=n[0],c*=Number(n[1])),l.match(e)||(r[l]={value:a(h,c),name:l,type:h})}}return r}r.__esModule=!0,r.default=n;var o=t("pixi-gl-core"),s=function(t){return t&&t.__esModule?t:{default:t}}(o),a=s.default.shader.defaultValue},{"pixi-gl-core":15}],88:[function(t,e,r){"use strict";function n(t,e,r){var n=t.identity();return n.translate(e.x/r.width,e.y/r.height),n.scale(r.width,r.height),n}function i(t,e,r){var n=t.identity();n.translate(e.x/r.width,e.y/r.height);var i=r.width/e.width,o=r.height/e.height;return n.scale(i,o),n}function o(t,e,r,n){var i=n._texture.orig,o=t.set(r.width,0,0,r.height,e.x,e.y),a=n.worldTransform.copy(s.Matrix.TEMP_MATRIX);return a.invert(),o.prepend(a),o.scale(1/i.width,1/i.height),o.translate(n.anchor.x,n.anchor.y),o}r.__esModule=!0,r.calculateScreenSpaceMatrix=n,r.calculateNormalizedScreenSpaceMatrix=i,r.calculateSpriteMatrix=o;var s=t("../../../math")},{"../../../math":70}],89:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function o(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function s(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}r.__esModule=!0;var a=t("../Filter"),u=n(a),h=t("../../../../math"),l=(t("path"),t("../../../../textures/TextureMatrix")),c=n(l),d=function(t){function e(r){i(this,e);var n=new h.Matrix,s=o(this,t.call(this,"attribute vec2 aVertexPosition;\nattribute vec2 aTextureCoord;\n\nuniform mat3 projectionMatrix;\nuniform mat3 otherMatrix;\n\nvarying vec2 vMaskCoord;\nvarying vec2 vTextureCoord;\n\nvoid main(void)\n{\n gl_Position = vec4((projectionMatrix * vec3(aVertexPosition, 1.0)).xy, 0.0, 1.0);\n\n vTextureCoord = aTextureCoord;\n vMaskCoord = ( otherMatrix * vec3( aTextureCoord, 1.0) ).xy;\n}\n","varying vec2 vMaskCoord;\nvarying vec2 vTextureCoord;\n\nuniform sampler2D uSampler;\nuniform sampler2D mask;\nuniform float alpha;\nuniform vec4 maskClamp;\n\nvoid main(void)\n{\n float clip = step(3.5,\n step(maskClamp.x, vMaskCoord.x) +\n step(maskClamp.y, vMaskCoord.y) +\n step(vMaskCoord.x, maskClamp.z) +\n step(vMaskCoord.y, maskClamp.w));\n\n vec4 original = texture2D(uSampler, vTextureCoord);\n vec4 masky = texture2D(mask, vMaskCoord);\n\n original *= (masky.r * masky.a * alpha * clip);\n\n gl_FragColor = original;\n}\n"));return r.renderable=!1,s.maskSprite=r,s.maskMatrix=n,s}return s(e,t),e.prototype.apply=function(t,e,r){var n=this.maskSprite,i=this.maskSprite.texture;i.valid&&(i.transform||(i.transform=new c.default(i,0)),i.transform.update(),this.uniforms.mask=i,this.uniforms.otherMatrix=t.calculateSpriteMatrix(this.maskMatrix,n).prepend(i.transform.mapCoord),this.uniforms.alpha=n.worldAlpha,this.uniforms.maskClamp=i.transform.uClampFrame,t.applyFilter(this,e,r))},e}(u.default);r.default=d},{"../../../../math":70,"../../../../textures/TextureMatrix":116,"../Filter":86,path:8}],90:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function o(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}function s(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var a=t("./WebGLManager"),u=n(a),h=t("../utils/RenderTarget"),l=n(h),c=t("../utils/Quad"),d=n(c),f=t("../../../math"),p=t("../../../Shader"),v=n(p),g=t("../filters/filterTransforms"),y=function(t){if(t&&t.__esModule)return t;var e={};if(null!=t)for(var r in t)Object.prototype.hasOwnProperty.call(t,r)&&(e[r]=t[r]);return e.default=t,e}(g),m=t("bit-twiddle"),_=n(m),b=function(){function t(){s(this,t),this.renderTarget=null,this.target=null,this.resolution=1,this.sourceFrame=new f.Rectangle,this.destinationFrame=new f.Rectangle,this.filters=[]}return t.prototype.clear=function(){this.filters=null,this.target=null,this.renderTarget=null},t}(),x=function(t){function e(r){s(this,e);var n=i(this,t.call(this,r));return n.gl=n.renderer.gl,n.quad=new d.default(n.gl,r.state.attribState),n.shaderCache={},n.pool={},n.filterData=null,n.managedFilters=[],n.renderer.on("prerender",n.onPrerender,n),n._screenWidth=r.view.width,n._screenHeight=r.view.height,n}return o(e,t),e.prototype.pushFilter=function(t,e){var r=this.renderer,n=this.filterData;if(!n){n=this.renderer._activeRenderTarget.filterStack;var i=new b;i.sourceFrame=i.destinationFrame=this.renderer._activeRenderTarget.size,i.renderTarget=r._activeRenderTarget,this.renderer._activeRenderTarget.filterData=n={index:0,stack:[i]},this.filterData=n}var o=n.stack[++n.index],s=n.stack[0].destinationFrame;o||(o=n.stack[n.index]=new b);var a=t.filterArea&&0===t.filterArea.x&&0===t.filterArea.y&&t.filterArea.width===r.screen.width&&t.filterArea.height===r.screen.height,u=e[0].resolution,h=0|e[0].padding,l=a?r.screen:t.filterArea||t.getBounds(!0),c=o.sourceFrame,d=o.destinationFrame;c.x=(l.x*u|0)/u,c.y=(l.y*u|0)/u,c.width=(l.width*u|0)/u,c.height=(l.height*u|0)/u,a||(n.stack[0].renderTarget.transform||e[0].autoFit&&c.fit(s),c.pad(h)),d.width=c.width,d.height=c.height;var f=this.getPotRenderTarget(r.gl,c.width,c.height,u);o.target=t,o.filters=e,o.resolution=u,o.renderTarget=f,f.setFrame(d,c),r.bindRenderTarget(f),f.clear()},e.prototype.popFilter=function(){var t=this.filterData,e=t.stack[t.index-1],r=t.stack[t.index];this.quad.map(r.renderTarget.size,r.sourceFrame).upload();var n=r.filters;if(1===n.length)n[0].apply(this,r.renderTarget,e.renderTarget,!1,r),this.freePotRenderTarget(r.renderTarget);else{var i=r.renderTarget,o=this.getPotRenderTarget(this.renderer.gl,r.sourceFrame.width,r.sourceFrame.height,r.resolution);o.setFrame(r.destinationFrame,r.sourceFrame),o.clear();var s=0;for(s=0;s0&&void 0!==arguments[0]&&arguments[0],e=this.renderer,r=this.managedFilters;e.off("prerender",this.onPrerender,this);for(var n=0;n0&&(e+="\nelse "),r1&&void 0!==arguments[1]?arguments[1]:[];return e[i.BLEND_MODES.NORMAL]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.ADD]=[t.ONE,t.DST_ALPHA],e[i.BLEND_MODES.MULTIPLY]=[t.DST_COLOR,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.SCREEN]=[t.ONE,t.ONE_MINUS_SRC_COLOR],e[i.BLEND_MODES.OVERLAY]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.DARKEN]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.LIGHTEN]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.COLOR_DODGE]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.COLOR_BURN]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.HARD_LIGHT]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.SOFT_LIGHT]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.DIFFERENCE]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.EXCLUSION]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.HUE]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.SATURATION]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.COLOR]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.LUMINOSITY]=[t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.NORMAL_NPM]=[t.SRC_ALPHA,t.ONE_MINUS_SRC_ALPHA,t.ONE,t.ONE_MINUS_SRC_ALPHA],e[i.BLEND_MODES.ADD_NPM]=[t.SRC_ALPHA,t.DST_ALPHA,t.ONE,t.DST_ALPHA],e[i.BLEND_MODES.SCREEN_NPM]=[t.SRC_ALPHA,t.ONE_MINUS_SRC_COLOR,t.ONE,t.ONE_MINUS_SRC_COLOR],e}r.__esModule=!0,r.default=n;var i=t("../../../const")},{"../../../const":46}],99:[function(t,e,r){"use strict";function n(t){var e=arguments.length>1&&void 0!==arguments[1]?arguments[1]:{};return e[i.DRAW_MODES.POINTS]=t.POINTS,e[i.DRAW_MODES.LINES]=t.LINES,e[i.DRAW_MODES.LINE_LOOP]=t.LINE_LOOP,e[i.DRAW_MODES.LINE_STRIP]=t.LINE_STRIP,e[i.DRAW_MODES.TRIANGLES]=t.TRIANGLES,e[i.DRAW_MODES.TRIANGLE_STRIP]=t.TRIANGLE_STRIP,e[i.DRAW_MODES.TRIANGLE_FAN]=t.TRIANGLE_FAN,e}r.__esModule=!0,r.default=n;var i=t("../../../const")},{"../../../const":46}],100:[function(t,e,r){"use strict";function n(t){t.getContextAttributes().stencil||console.warn("Provided WebGL context does not have a stencil buffer, masks may not render correctly")}r.__esModule=!0,r.default=n},{}],101:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}r.__esModule=!0;var i=t("./utils/maxRecommendedTextures"),o=n(i),s=t("./utils/canUploadSameBuffer"),a=n(s);r.default={TARGET_FPMS:.06,MIPMAP_TEXTURES:!0,RESOLUTION:1,FILTER_RESOLUTION:1,SPRITE_MAX_TEXTURES:(0,o.default)(32),SPRITE_BATCH_SIZE:4096,RETINA_PREFIX:/@([0-9\.]+)x/,RENDER_OPTIONS:{view:null,antialias:!1,forceFXAA:!1,autoResize:!1,transparent:!1,backgroundColor:0,clearBeforeRender:!0,preserveDrawingBuffer:!1,roundPixels:!1,width:800,height:600,legacy:!1},TRANSFORM_MODE:0,GC_MODE:0,GC_MAX_IDLE:3600,GC_MAX_CHECK_COUNT:600,WRAP_MODE:0,SCALE_MODE:0,PRECISION_VERTEX:"highp",PRECISION_FRAGMENT:"mediump",CAN_UPLOAD_SAME_BUFFER:(0,a.default)(),MESH_CANVAS_PADDING:0}},{"./utils/canUploadSameBuffer":122,"./utils/maxRecommendedTextures":127}],102:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function o(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function s(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}r.__esModule=!0;var a=function(){function t(t,e){for(var r=0;r=n&&v.x=i&&v.y>16)+(65280&t)+((255&t)<<16)}},{key:"texture",get:function(){return this._texture},set:function(t){this._texture!==t&&(this._texture=t,this.cachedTint=16777215,this._textureID=-1,this._textureTrimmedID=-1,t&&(t.baseTexture.hasLoaded?this._onTextureUpdate():t.once("update",this._onTextureUpdate,this)))}}]),e}(p.default);r.default=g},{"../const":46,"../display/Container":48,"../math":70,"../textures/Texture":115,"../utils":125}],103:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var o=t("../../renderers/canvas/CanvasRenderer"),s=n(o),a=t("../../const"),u=t("../../math"),h=t("./CanvasTinter"),l=n(h),c=new u.Matrix,d=function(){function t(e){i(this,t),this.renderer=e}return t.prototype.render=function(t){var e=t._texture,r=this.renderer,n=e._frame.width,i=e._frame.height,o=t.transform.worldTransform,s=0,h=0;if(!(e.orig.width<=0||e.orig.height<=0)&&e.baseTexture.source&&(r.setBlendMode(t.blendMode),e.valid)){r.context.globalAlpha=t.worldAlpha;var d=e.baseTexture.scaleMode===a.SCALE_MODES.LINEAR;r.smoothProperty&&r.context[r.smoothProperty]!==d&&(r.context[r.smoothProperty]=d),e.trim?(s=e.trim.width/2+e.trim.x-t.anchor.x*e.orig.width,h=e.trim.height/2+e.trim.y-t.anchor.y*e.orig.height):(s=(.5-t.anchor.x)*e.orig.width,h=(.5-t.anchor.y)*e.orig.height),e.rotate&&(o.copy(c),o=c,u.GroupD8.matrixAppendRotationInv(o,e.rotate,s,h),s=0,h=0),s-=n/2,h-=i/2,r.roundPixels?(r.context.setTransform(o.a,o.b,o.c,o.d,o.tx*r.resolution|0,o.ty*r.resolution|0),s|=0,h|=0):r.context.setTransform(o.a,o.b,o.c,o.d,o.tx*r.resolution,o.ty*r.resolution);var f=e.baseTexture.resolution;16777215!==t.tint?(t.cachedTint===t.tint&&t.tintedTexture.tintId===t._texture._updateID||(t.cachedTint=t.tint,t.tintedTexture=l.default.getTintedTexture(t,t.tint)),r.context.drawImage(t.tintedTexture,0,0,n*f,i*f,s*r.resolution,h*r.resolution,n*r.resolution,i*r.resolution)):r.context.drawImage(e.baseTexture.source,e._frame.x*f,e._frame.y*f,n*f,i*f,s*r.resolution,h*r.resolution,n*r.resolution,i*r.resolution)}},t.prototype.destroy=function(){this.renderer=null},t}();r.default=d,s.default.registerPlugin("sprite",d)},{"../../const":46,"../../math":70,"../../renderers/canvas/CanvasRenderer":77,"./CanvasTinter":104}],104:[function(t,e,r){"use strict";r.__esModule=!0;var n=t("../../utils"),i=t("../../renderers/canvas/utils/canUseNewCanvasBlendModes"),o=function(t){return t&&t.__esModule?t:{default:t}}(i),s={getTintedTexture:function(t,e){var r=t._texture;e=s.roundColor(e);var n="#"+("00000"+(0|e).toString(16)).substr(-6);r.tintCache=r.tintCache||{};var i=r.tintCache[n],o=void 0;if(i){if(i.tintId===r._updateID)return r.tintCache[n];o=r.tintCache[n]}else o=s.canvas||document.createElement("canvas");if(s.tintMethod(r,e,o),o.tintId=r._updateID,s.convertTintToImage){var a=new Image;a.src=o.toDataURL(),r.tintCache[n]=a}else r.tintCache[n]=o,s.canvas=null;return o},tintWithMultiply:function(t,e,r){var n=r.getContext("2d"),i=t._frame.clone(),o=t.baseTexture.resolution;i.x*=o,i.y*=o,i.width*=o,i.height*=o,r.width=Math.ceil(i.width),r.height=Math.ceil(i.height),n.save(),n.fillStyle="#"+("00000"+(0|e).toString(16)).substr(-6),n.fillRect(0,0,i.width,i.height),n.globalCompositeOperation="multiply",n.drawImage(t.baseTexture.source,i.x,i.y,i.width,i.height,0,0,i.width,i.height),n.globalCompositeOperation="destination-atop",n.drawImage(t.baseTexture.source,i.x,i.y,i.width,i.height,0,0,i.width,i.height),n.restore()},tintWithOverlay:function(t,e,r){var n=r.getContext("2d"),i=t._frame.clone(),o=t.baseTexture.resolution;i.x*=o,i.y*=o,i.width*=o,i.height*=o,r.width=Math.ceil(i.width),r.height=Math.ceil(i.height),n.save(),n.globalCompositeOperation="copy",n.fillStyle="#"+("00000"+(0|e).toString(16)).substr(-6),n.fillRect(0,0,i.width,i.height),n.globalCompositeOperation="destination-atop",n.drawImage(t.baseTexture.source,i.x,i.y,i.width,i.height,0,0,i.width,i.height),n.restore()},tintWithPerPixel:function(t,e,r){var i=r.getContext("2d"),o=t._frame.clone(),s=t.baseTexture.resolution;o.x*=s,o.y*=s,o.width*=s,o.height*=s,r.width=Math.ceil(o.width),r.height=Math.ceil(o.height),i.save(),i.globalCompositeOperation="copy",i.drawImage(t.baseTexture.source,o.x,o.y,o.width,o.height,0,0,o.width,o.height),i.restore();for(var a=(0,n.hex2rgb)(e),u=a[0],h=a[1],l=a[2],c=i.getImageData(0,0,o.width,o.height),d=c.data,f=0;f=this.size&&this.flush(),t._texture._uvs&&(this.sprites[this.currentIndex++]=t)},e.prototype.flush=function(){if(0!==this.currentIndex){var t=this.renderer.gl,e=this.MAX_TEXTURES,r=S.default.nextPow2(this.currentIndex),n=S.default.log2(r),i=this.buffers[n],o=this.sprites,s=this.groups,a=i.float32View,u=i.uint32View,h=this.boundTextures,l=this.renderer.boundTextures,c=this.renderer.textureGC.count,d=0,f=void 0,p=void 0,v=1,g=0,y=s[0],m=void 0,_=void 0,T=x.premultiplyBlendMode[o[0]._texture.baseTexture.premultipliedAlpha?1:0][o[0].blendMode];y.textureCount=0,y.start=0,y.blend=T,O++;var E=void 0;for(E=0;E0&&(e+="\nelse "),r0&&(r.shadowColor=e.dropShadowColor);for(var f=Math.cos(e.dropShadowAngle)*e.dropShadowDistance,p=Math.sin(e.dropShadowAngle)*e.dropShadowDistance,v=0;v3&&void 0!==arguments[3]&&arguments[3],i=this._style,o=i.letterSpacing;if(0===o)return void(n?this.context.strokeText(t,e,r):this.context.fillText(t,e,r));for(var s=String.prototype.split.call(t,""),a=e,u=0,h="";u3&&void 0!==arguments[3]?arguments[3]:t._canvas;n=n||r.wordWrap;var o=r.toFontString(),s=t.measureFont(o),a=i.getContext("2d");a.font=o;for(var u=n?t.wordWrap(e,r,i):e,h=u.split(/(?:\r\n|\r|\n)/),l=new Array(h.length),c=0,d=0;d2&&void 0!==arguments[2]?arguments[2]:t._canvas,i=n.getContext("2d"),o=0,s="",a="",u={},h=r.letterSpacing,l=r.whiteSpace,c=t.collapseSpaces(l),d=t.collapseNewlines(l),f=!c,p=r.wordWrapWidth+h,v=t.tokenize(e),g=0;gp)if(""!==s&&(a+=t.addLine(s),s="",o=0),t.canBreakWords(y,r.breakWords))for(var x=y.split(""),T=0;Tp&&(a+=t.addLine(s),f=!1,s="",o=0),s+=w,o+=M}else{s.length>0&&(a+=t.addLine(s),s="",o=0);var P=g===v.length-1;a+=t.addLine(y,!P),f=!1,s="",o=0}else b+o>p&&(f=!1,a+=t.addLine(s),s="",o=0),(s.length>0||!t.isBreakingSpace(y)||f)&&(s+=y,o+=b)}return a+=t.addLine(s,!1)},t.addLine=function(e){var r=!(arguments.length>1&&void 0!==arguments[1])||arguments[1];return e=t.trimRight(e),e=r?e+"\n":e},t.getFromCache=function(t,e,r,n){var i=r[t];if(void 0===i){var o=t.length*e;i=n.measureText(t).width+o,r[t]=i}return i},t.collapseSpaces=function(t){return"normal"===t||"pre-line"===t},t.collapseNewlines=function(t){return"normal"===t},t.trimRight=function(e){if("string"!=typeof e)return"";for(var r=e.length-1;r>=0;r--){var n=e[r];if(!t.isBreakingSpace(n))break;e=e.slice(0,-1)}return e},t.isNewline=function(e){return"string"==typeof e&&t._newlines.indexOf(e.charCodeAt(0))>=0},t.isBreakingSpace=function(e){return"string"==typeof e&&t._breakingSpaces.indexOf(e.charCodeAt(0))>=0},t.tokenize=function(e){var r=[],n="";if("string"!=typeof e)return r;for(var i=0;ia;--d){for(var g=0;g0&&void 0!==arguments[0]?arguments[0]:"";e?delete t._fonts[e]:t._fonts={}},t}();r.default=i;var o=document.createElement("canvas");o.width=o.height=10,i._canvas=o,i._context=o.getContext("2d"),i._fonts={},i.METRICS_STRING="|Éq",i.BASELINE_SYMBOL="M",i.BASELINE_MULTIPLIER=1.4,i._newlines=[10,13],i._breakingSpaces=[9,32,8192,8193,8194,8195,8196,8197,8198,8200,8201,8202,8287,12288]},{}],110:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function i(t){return"number"==typeof t?(0,l.hex2string)(t):("string"==typeof t&&0===t.indexOf("0x")&&(t=t.replace("0x","#")),t)}function o(t){if(Array.isArray(t)){for(var e=0;e=0;r--){var n=e[r].trim();/([\"\'])[^\'\"]+\1/.test(n)||(n='"'+n+'"'),e[r]=n}return this.fontStyle+" "+this.fontVariant+" "+this.fontWeight+" "+t+" "+e.join(",")},u(t,[{key:"align",get:function(){return this._align},set:function(t){this._align!==t&&(this._align=t,this.styleID++)}},{key:"breakWords",get:function(){return this._breakWords},set:function(t){this._breakWords!==t&&(this._breakWords=t,this.styleID++)}},{key:"dropShadow",get:function(){return this._dropShadow},set:function(t){this._dropShadow!==t&&(this._dropShadow=t,this.styleID++)}},{key:"dropShadowAlpha",get:function(){return this._dropShadowAlpha},set:function(t){this._dropShadowAlpha!==t&&(this._dropShadowAlpha=t,this.styleID++)}},{key:"dropShadowAngle",get:function(){return this._dropShadowAngle},set:function(t){this._dropShadowAngle!==t&&(this._dropShadowAngle=t,this.styleID++)}},{key:"dropShadowBlur",get:function(){return this._dropShadowBlur},set:function(t){this._dropShadowBlur!==t&&(this._dropShadowBlur=t,this.styleID++)}},{key:"dropShadowColor",get:function(){return this._dropShadowColor},set:function(t){var e=o(t);this._dropShadowColor!==e&&(this._dropShadowColor=e,this.styleID++)}},{key:"dropShadowDistance",get:function(){return this._dropShadowDistance},set:function(t){this._dropShadowDistance!==t&&(this._dropShadowDistance=t,this.styleID++)}},{key:"fill",get:function(){return this._fill},set:function(t){var e=o(t);this._fill!==e&&(this._fill=e,this.styleID++)}},{key:"fillGradientType",get:function(){return this._fillGradientType},set:function(t){this._fillGradientType!==t&&(this._fillGradientType=t,this.styleID++)}},{key:"fillGradientStops",get:function(){return this._fillGradientStops},set:function(t){s(this._fillGradientStops,t)||(this._fillGradientStops=t,this.styleID++)}},{key:"fontFamily",get:function(){return this._fontFamily},set:function(t){this.fontFamily!==t&&(this._fontFamily=t,this.styleID++)}},{key:"fontSize",get:function(){return this._fontSize},set:function(t){this._fontSize!==t&&(this._fontSize=t,this.styleID++)}},{key:"fontStyle",get:function(){return this._fontStyle},set:function(t){this._fontStyle!==t&&(this._fontStyle=t,this.styleID++)}},{key:"fontVariant",get:function(){return this._fontVariant},set:function(t){this._fontVariant!==t&&(this._fontVariant=t,this.styleID++)}},{key:"fontWeight",get:function(){return this._fontWeight},set:function(t){this._fontWeight!==t&&(this._fontWeight=t,this.styleID++)}},{key:"letterSpacing",get:function(){return this._letterSpacing},set:function(t){this._letterSpacing!==t&&(this._letterSpacing=t,this.styleID++)}},{key:"lineHeight",get:function(){return this._lineHeight},set:function(t){this._lineHeight!==t&&(this._lineHeight=t,this.styleID++)}},{key:"leading",get:function(){return this._leading},set:function(t){this._leading!==t&&(this._leading=t,this.styleID++)}},{key:"lineJoin",get:function(){return this._lineJoin},set:function(t){this._lineJoin!==t&&(this._lineJoin=t,this.styleID++)}},{key:"miterLimit",get:function(){return this._miterLimit},set:function(t){this._miterLimit!==t&&(this._miterLimit=t,this.styleID++)}},{key:"padding",get:function(){return this._padding},set:function(t){this._padding!==t&&(this._padding=t,this.styleID++)}},{key:"stroke",get:function(){return this._stroke},set:function(t){var e=o(t);this._stroke!==e&&(this._stroke=e,this.styleID++)}},{key:"strokeThickness",get:function(){return this._strokeThickness},set:function(t){this._strokeThickness!==t&&(this._strokeThickness=t,this.styleID++)}},{key:"textBaseline",get:function(){return this._textBaseline},set:function(t){this._textBaseline!==t&&(this._textBaseline=t,this.styleID++)}},{key:"trim",get:function(){return this._trim},set:function(t){this._trim!==t&&(this._trim=t,this.styleID++)}},{key:"whiteSpace",get:function(){return this._whiteSpace},set:function(t){this._whiteSpace!==t&&(this._whiteSpace=t,this.styleID++)}},{key:"wordWrap",get:function(){return this._wordWrap},set:function(t){this._wordWrap!==t&&(this._wordWrap=t,this.styleID++)}},{key:"wordWrapWidth",get:function(){return this._wordWrapWidth},set:function(t){this._wordWrapWidth!==t&&(this._wordWrapWidth=t,this.styleID++)}}]),t}();r.default=d},{"../const":46,"../utils":125}],111:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function o(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function s(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}r.__esModule=!0;var a=t("./BaseTexture"),u=n(a),h=t("../settings"),l=n(h),c=function(t){function e(){var r=arguments.length>0&&void 0!==arguments[0]?arguments[0]:100,n=arguments.length>1&&void 0!==arguments[1]?arguments[1]:100,s=arguments[2],a=arguments[3];i(this,e);var u=o(this,t.call(this,null,s));return u.resolution=a||l.default.RESOLUTION,u.width=Math.ceil(r),u.height=Math.ceil(n),u.realWidth=u.width*u.resolution,u.realHeight=u.height*u.resolution,u.scaleMode=void 0!==s?s:l.default.SCALE_MODE,u.hasLoaded=!0,u._glRenderTargets={},u._canvasRenderTarget=null,u.valid=!1,u}return s(e,t),e.prototype.resize=function(t,e){t=Math.ceil(t),e=Math.ceil(e),t===this.width&&e===this.height||(this.valid=t>0&&e>0,this.width=t,this.height=e,this.realWidth=this.width*this.resolution,this.realHeight=this.height*this.resolution,this.valid&&this.emit("update",this))},e.prototype.destroy=function(){t.prototype.destroy.call(this,!0),this.renderer=null},e}(u.default);r.default=c},{"../settings":101,"./BaseTexture":112}],112:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function o(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function s(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}r.__esModule=!0;var a=t("../utils"),u=t("../settings"),h=n(u),l=t("eventemitter3"),c=n(l),d=t("../utils/determineCrossOrigin"),f=n(d),p=t("bit-twiddle"),v=n(p),g=function(t){function e(r,n,s){i(this,e);var u=o(this,t.call(this));return u.uid=(0,a.uid)(),u.touched=0,u.resolution=s||h.default.RESOLUTION,u.width=100,u.height=100,u.realWidth=100,u.realHeight=100,u.scaleMode=void 0!==n?n:h.default.SCALE_MODE,u.hasLoaded=!1,u.isLoading=!1,u.source=null,u.origSource=null,u.imageType=null,u.sourceScale=1,u.premultipliedAlpha=!0,u.imageUrl=null,u.isPowerOfTwo=!1,u.mipmap=h.default.MIPMAP_TEXTURES,u.wrapMode=h.default.WRAP_MODE,u._glTextures={},u._enabled=0,u._virtalBoundId=-1,u._destroyed=!1,u.textureCacheIds=[],r&&u.loadSource(r),u}return s(e,t),e.prototype.update=function(){"svg"!==this.imageType&&(this.realWidth=this.source.naturalWidth||this.source.videoWidth||this.source.width,this.realHeight=this.source.naturalHeight||this.source.videoHeight||this.source.height,this._updateDimensions()),this.emit("update",this)},e.prototype._updateDimensions=function(){this.width=this.realWidth/this.resolution,this.height=this.realHeight/this.resolution,this.isPowerOfTwo=v.default.isPow2(this.realWidth)&&v.default.isPow2(this.realHeight)},e.prototype.loadSource=function(t){var e=this.isLoading;this.hasLoaded=!1,this.isLoading=!1,e&&this.source&&(this.source.onload=null,this.source.onerror=null);var r=!this.source;if(this.source=t,(t.src&&t.complete||t.getContext)&&t.width&&t.height)this._updateImageType(),"svg"===this.imageType?this._loadSvgSource():this._sourceLoaded(),r&&this.emit("loaded",this);else if(!t.getContext){this.isLoading=!0;var n=this;if(t.onload=function(){if(n._updateImageType(),t.onload=null,t.onerror=null,n.isLoading){if(n.isLoading=!1,n._sourceLoaded(),"svg"===n.imageType)return void n._loadSvgSource();n.emit("loaded",n)}},t.onerror=function(){t.onload=null,t.onerror=null,n.isLoading&&(n.isLoading=!1,n.emit("error",n))},t.complete&&t.src){if(t.onload=null,t.onerror=null,"svg"===n.imageType)return void n._loadSvgSource();this.isLoading=!1,t.width&&t.height?(this._sourceLoaded(),e&&this.emit("loaded",this)):e&&this.emit("error",this)}}},e.prototype._updateImageType=function(){if(this.imageUrl){var t=(0,a.decomposeDataUri)(this.imageUrl),e=void 0;if(t&&"image"===t.mediaType){var r=t.subType.split("+")[0];if(!(e=(0,a.getUrlFileExtension)("."+r)))throw new Error("Invalid image type in data URI.")}else(e=(0,a.getUrlFileExtension)(this.imageUrl))||(e="png");this.imageType=e}},e.prototype._loadSvgSource=function(){if("svg"===this.imageType){var t=(0,a.decomposeDataUri)(this.imageUrl);t?this._loadSvgSourceUsingDataUri(t):this._loadSvgSourceUsingXhr()}},e.prototype._loadSvgSourceUsingDataUri=function(t){var e=void 0;if("base64"===t.encoding){if(!atob)throw new Error("Your browser doesn't support base64 conversions.");e=atob(t.data)}else e=t.data;this._loadSvgSourceUsingString(e)},e.prototype._loadSvgSourceUsingXhr=function(){var t=this,e=new XMLHttpRequest;e.onload=function(){if(e.readyState!==e.DONE||200!==e.status)throw new Error("Failed to load SVG using XHR.");t._loadSvgSourceUsingString(e.response)},e.onerror=function(){return t.emit("error",t)},e.open("GET",this.imageUrl,!0),e.send()},e.prototype._loadSvgSourceUsingString=function(t){var r=(0,a.getSvgSize)(t),n=r.width,i=r.height;if(!n||!i)throw new Error("The SVG image must have width and height defined (in pixels), canvas API needs them.");this.realWidth=Math.round(n*this.sourceScale),this.realHeight=Math.round(i*this.sourceScale),this._updateDimensions();var o=document.createElement("canvas");o.width=this.realWidth,o.height=this.realHeight,o._pixiId="canvas_"+(0,a.uid)(),o.getContext("2d").drawImage(this.source,0,0,n,i,0,0,this.realWidth,this.realHeight),this.origSource=this.source,this.source=o,e.addToCache(this,o._pixiId),this.isLoading=!1,this._sourceLoaded(),this.emit("loaded",this)},e.prototype._sourceLoaded=function(){this.hasLoaded=!0,this.update()},e.prototype.destroy=function(){this.imageUrl&&(delete a.TextureCache[this.imageUrl],this.imageUrl=null,navigator.isCocoonJS||(this.source.src="")),this.source=null,this.dispose(),e.removeFromCache(this),this.textureCacheIds=null,this._destroyed=!0},e.prototype.dispose=function(){this.emit("dispose",this)},e.prototype.updateSourceImage=function(t){this.source.src=t,this.loadSource(this.source)},e.fromImage=function(t,r,n,i){var o=a.BaseTextureCache[t];if(!o){var s=new Image;void 0===r&&0!==t.indexOf("data:")?s.crossOrigin=(0,f.default)(t):r&&(s.crossOrigin="string"==typeof r?r:"anonymous"),o=new e(s,n),o.imageUrl=t,i&&(o.sourceScale=i),o.resolution=(0,a.getResolutionOfUrl)(t),s.src=t,e.addToCache(o,t)}return o},e.fromCanvas=function(t,r){var n=arguments.length>2&&void 0!==arguments[2]?arguments[2]:"canvas";t._pixiId||(t._pixiId=n+"_"+(0,a.uid)());var i=a.BaseTextureCache[t._pixiId];return i||(i=new e(t,r),e.addToCache(i,t._pixiId)),i},e.from=function(t,r,n){if("string"==typeof t)return e.fromImage(t,void 0,r,n);if(t instanceof HTMLImageElement){var i=t.src,o=a.BaseTextureCache[i];return o||(o=new e(t,r),o.imageUrl=i,n&&(o.sourceScale=n),o.resolution=(0,a.getResolutionOfUrl)(i),e.addToCache(o,i)),o}return t instanceof HTMLCanvasElement?e.fromCanvas(t,r):t},e.addToCache=function(t,e){e&&(-1===t.textureCacheIds.indexOf(e)&&t.textureCacheIds.push(e),a.BaseTextureCache[e]=t)},e.removeFromCache=function(t){if("string"==typeof t){var e=a.BaseTextureCache[t];if(e){var r=e.textureCacheIds.indexOf(t);return r>-1&&e.textureCacheIds.splice(r,1),delete a.BaseTextureCache[t],e}}else if(t&&t.textureCacheIds){for(var n=0;n0&&e>0,this._frame.width=this.orig.width=t,this._frame.height=this.orig.height=e,r||this.baseTexture.resize(t,e),this._updateUvs()},e.create=function(t,r,n,i){return new e(new u.default(t,r,n,i))},e}(l.default);r.default=c},{"./BaseRenderTexture":111,"./Texture":115}],114:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=function(){function t(t,e){for(var r=0;r2&&void 0!==arguments[2]?arguments[2]:null;n(this,t),this.baseTexture=e,this.textures={},this.data=r,this.resolution=this._updateResolution(i||this.baseTexture.imageUrl),this._frames=this.data.frames,this._frameKeys=Object.keys(this._frames),this._batchIndex=0,this._callback=null}return i(t,null,[{key:"BATCH_SIZE",get:function(){return 1e3}}]),
+t.prototype._updateResolution=function(t){var e=this.data.meta.scale,r=(0,s.getResolutionOfUrl)(t,null);return null===r&&(r=void 0!==e?parseFloat(e):1),1!==r&&(this.baseTexture.resolution=r,this.baseTexture.update()),r},t.prototype.parse=function(e){this._batchIndex=0,this._callback=e,this._frameKeys.length<=t.BATCH_SIZE?(this._processFrames(0),this._parseComplete()):this._nextBatch()},t.prototype._processFrames=function(e){for(var r=e,n=t.BATCH_SIZE,i=this.baseTexture.sourceScale;r-e0&&void 0!==arguments[0]&&arguments[0];for(var e in this.textures)this.textures[e].destroy();this._frames=null,this._frameKeys=null,this.data=null,this.textures=null,t&&this.baseTexture.destroy(),this.baseTexture=null},t}();r.default=a},{"../":65,"../utils":125}],115:[function(t,e,r){"use strict";function n(t){return t&&t.__esModule?t:{default:t}}function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}function o(t,e){if(!t)throw new ReferenceError("this hasn't been initialised - super() hasn't been called");return!e||"object"!=typeof e&&"function"!=typeof e?t:e}function s(t,e){if("function"!=typeof e&&null!==e)throw new TypeError("Super expression must either be null or a function, not "+typeof e);t.prototype=Object.create(e&&e.prototype,{constructor:{value:t,enumerable:!1,writable:!0,configurable:!0}}),e&&(Object.setPrototypeOf?Object.setPrototypeOf(t,e):t.__proto__=e)}function a(t){t.destroy=function(){},t.on=function(){},t.once=function(){},t.emit=function(){}}r.__esModule=!0;var u=function(){function t(t,e){for(var r=0;r2&&void 0!==arguments[2]?arguments[2]:"canvas";return new e(l.default.fromCanvas(t,r,n))},e.fromVideo=function(t,r){return"string"==typeof t?e.fromVideoUrl(t,r):new e(d.default.fromVideo(t,r))},e.fromVideoUrl=function(t,r){return new e(d.default.fromUrl(t,r))},e.from=function(t){if("string"==typeof t){var r=m.TextureCache[t];if(!r){return null!==t.match(/\.(mp4|webm|ogg|h264|avi|mov)$/)?e.fromVideoUrl(t):e.fromImage(t)}return r}return t instanceof HTMLImageElement?new e(l.default.from(t)):t instanceof HTMLCanvasElement?e.fromCanvas(t,b.default.SCALE_MODE,"HTMLCanvasElement"):t instanceof HTMLVideoElement?e.fromVideo(t):t instanceof l.default?new e(t):t},e.fromLoader=function(t,r,n){var i=new l.default(t,void 0,(0,m.getResolutionOfUrl)(r)),o=new e(i);return i.imageUrl=r,n||(n=r),l.default.addToCache(o.baseTexture,n),e.addToCache(o,n),n!==r&&(l.default.addToCache(o.baseTexture,r),e.addToCache(o,r)),o},e.addToCache=function(t,e){e&&(-1===t.textureCacheIds.indexOf(e)&&t.textureCacheIds.push(e),m.TextureCache[e]=t)},e.removeFromCache=function(t){if("string"==typeof t){var e=m.TextureCache[t];if(e){var r=e.textureCacheIds.indexOf(t);return r>-1&&e.textureCacheIds.splice(r,1),delete m.TextureCache[t],e}}else if(t&&t.textureCacheIds){for(var n=0;nthis.baseTexture.width,s=r+i>this.baseTexture.height;if(o||s){var a=o&&s?"and":"or",u="X: "+e+" + "+n+" = "+(e+n)+" > "+this.baseTexture.width,h="Y: "+r+" + "+i+" = "+(r+i)+" > "+this.baseTexture.height;throw new Error("Texture Error: frame does not fit inside the base Texture dimensions: "+u+" "+a+" "+h)}this.valid=n&&i&&this.baseTexture.hasLoaded,this.trim||this.rotate||(this.orig=t),this.valid&&this._updateUvs()}},{key:"rotate",get:function(){return this._rotate},set:function(t){this._rotate=t,this.valid&&this._updateUvs()}},{key:"width",get:function(){return this.orig.width}},{key:"height",get:function(){return this.orig.height}}]),e}(g.default);r.default=x,x.EMPTY=new x(new l.default),a(x.EMPTY),a(x.EMPTY.baseTexture),x.WHITE=function(){var t=document.createElement("canvas");t.width=10,t.height=10;var e=t.getContext("2d");return e.fillStyle="white",e.fillRect(0,0,10,10),new x(new l.default(t))}(),a(x.WHITE),a(x.WHITE.baseTexture)},{"../math":70,"../settings":101,"../utils":125,"./BaseTexture":112,"./TextureUvs":117,"./VideoBaseTexture":118,eventemitter3:3}],116:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=function(){function t(t,e){for(var r=0;r0&&!1===t.paused&&!1===t.ended&&t.readyState>2},e.prototype._isSourceReady=function(){return 3===this.source.readyState||4===this.source.readyState},e.prototype._onPlayStart=function(){this.hasLoaded||this._onCanPlay(),!this._isAutoUpdating&&this.autoUpdate&&(d.shared.add(this.update,this,f.UPDATE_PRIORITY.HIGH),this._isAutoUpdating=!0)},e.prototype._onPlayStop=function(){this._isAutoUpdating&&(d.shared.remove(this.update,this),this._isAutoUpdating=!1)},e.prototype._onCanPlay=function(){this.hasLoaded=!0,this.source&&(this.source.removeEventListener("canplay",this._onCanPlay),this.source.removeEventListener("canplaythrough",this._onCanPlay),this.width=this.source.videoWidth,this.height=this.source.videoHeight,this.__loaded||(this.__loaded=!0,this.emit("loaded",this)),this._isSourcePlaying()?this._onPlayStart():this.autoPlay&&this.source.play())},e.prototype.destroy=function(){this._isAutoUpdating&&d.shared.remove(this.update,this),this.source&&this.source._pixiId&&(l.default.removeFromCache(this.source._pixiId),delete this.source._pixiId,this.source.pause(),this.source.src="",this.source.load()),t.prototype.destroy.call(this)},e.fromVideo=function(t,r){t._pixiId||(t._pixiId="video_"+(0,c.uid)());var n=c.BaseTextureCache[t._pixiId];return n||(n=new e(t,r),l.default.addToCache(n,t._pixiId)),n},e.fromUrl=function(t,r,n){var i=document.createElement("video");i.setAttribute("webkit-playsinline",""),i.setAttribute("playsinline","");var o=Array.isArray(t)?t[0].src||t[0]:t.src||t;if(void 0===n&&0!==o.indexOf("data:")?i.crossOrigin=(0,v.default)(o):n&&(i.crossOrigin="string"==typeof n?n:"anonymous"),Array.isArray(t))for(var s=0;s2&&void 0!==arguments[2]?arguments[2]:u.UPDATE_PRIORITY.NORMAL;return this._addListener(new l.default(t,e,r))},t.prototype.addOnce=function(t,e){var r=arguments.length>2&&void 0!==arguments[2]?arguments[2]:u.UPDATE_PRIORITY.NORMAL;return this._addListener(new l.default(t,e,r,!0))},t.prototype._addListener=function(t){var e=this._head.next,r=this._head;if(e){for(;e;){if(t.priority>e.priority){t.connect(r);break}r=e,e=e.next}t.previous||t.connect(r)}else t.connect(r);return this._startIfPossible(),this},t.prototype.remove=function(t,e){for(var r=this._head.next;r;)r=r.match(t,e)?r.destroy():r.next;return this._head.next||this._cancelIfNeeded(),this},t.prototype.start=function(){this.started||(this.started=!0,this._requestIfNeeded())},t.prototype.stop=function(){this.started&&(this.started=!1,this._cancelIfNeeded())},t.prototype.destroy=function(){this.stop();for(var t=this._head.next;t;)t=t.destroy(!0);this._head.destroy(),this._head=null},t.prototype.update=function(){var t=arguments.length>0&&void 0!==arguments[0]?arguments[0]:performance.now(),e=void 0;if(t>this.lastTime){e=this.elapsedMS=t-this.lastTime,e>this._maxElapsedMS&&(e=this._maxElapsedMS),this.deltaTime=e*a.default.TARGET_FPMS*this.speed;for(var r=this._head,n=r.next;n;)n=n.emit(this.deltaTime);r.next||this._cancelIfNeeded()}else this.deltaTime=this.elapsedMS=0;this.lastTime=t},o(t,[{key:"FPS",get:function(){return 1e3/this.elapsedMS}},{key:"minFPS",get:function(){return 1e3/this._maxElapsedMS},set:function(t){var e=Math.min(Math.max(0,t)/1e3,a.default.TARGET_FPMS);this._maxElapsedMS=1/e}}]),t}();r.default=c},{"../const":46,"../settings":101,"./TickerListener":120}],120:[function(t,e,r){"use strict";function n(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}r.__esModule=!0;var i=function(){function t(e){var r=arguments.length>1&&void 0!==arguments[1]?arguments[1]:null,i=arguments.length>2&&void 0!==arguments[2]?arguments[2]:0,o=arguments.length>3&&void 0!==arguments[3]&&arguments[3];n(this,t),this.fn=e,this.context=r,this.priority=i,this.once=o,this.next=null,this.previous=null,this._destroyed=!1}return t.prototype.match=function(t,e){return e=e||null,this.fn===t&&this.context===e},t.prototype.emit=function(t){this.fn&&(this.context?this.fn.call(this.context,t):this.fn(t));var e=this.next;return this.once&&this.destroy(!0),this._destroyed&&(this.next=null),e},t.prototype.connect=function(t){this.previous=t,t.next&&(t.next.previous=this),this.next=t.next,t.next=this},t.prototype.destroy=function(){var t=arguments.length>0&&void 0!==arguments[0]&&arguments[0];this._destroyed=!0,this.fn=null,this.context=null,this.previous&&(this.previous.next=this.next),this.next&&(this.next.previous=this.previous);var e=this.next;return this.next=t?null:e,this.previous=null,e},t}();r.default=i},{}],121:[function(t,e,r){"use strict";r.__esModule=!0,r.Ticker=r.shared=void 0;var n=t("./Ticker"),i=function(t){return t&&t.__esModule?t:{default:t}}(n),o=new i.default;o.autoStart=!0,o.destroy=function(){},r.shared=o,r.Ticker=i.default},{"./Ticker":119}],122:[function(t,e,r){"use strict";function n(){return!(!!navigator.platform&&/iPad|iPhone|iPod/.test(navigator.platform))}r.__esModule=!0,r.default=n},{}],123:[function(t,e,r){"use strict";function n(t){for(var e=6*t,r=new Uint16Array(e),n=0,i=0;n1&&void 0!==arguments[1]?arguments[1]:window.location;if(0===t.indexOf("data:"))return"";e=e||window.location,s||(s=document.createElement("a")),s.href=t,t=o.default.parse(s.href);var r=!t.port&&""===e.port||t.port===e.port;return t.hostname===e.hostname&&r&&t.protocol===e.protocol?"":"anonymous"}r.__esModule=!0,r.default=n;var i=t("url"),o=function(t){return t&&t.__esModule?t:{default:t}}(i),s=void 0},{url:38}],125:[function(t,e,r){"use strict";function n(t){if(t&&t.__esModule)return t;var e={};if(null!=t)for(var r in t)Object.prototype.hasOwnProperty.call(t,r)&&(e[r]=t[r]);return e.default=t,e}function i(t){return t&&t.__esModule?t:{default:t}}function o(){return++U}function s(t,e){return e=e||[],e[0]=(t>>16&255)/255,e[1]=(t>>8&255)/255,e[2]=(255&t)/255,e}function a(t){return t=t.toString(16),"#"+(t="000000".substr(0,6-t.length)+t)}function u(t){return(255*t[0]<<16)+(255*t[1]<<8)+(255*t[2]|0)}function h(t,e){var r=S.default.RETINA_PREFIX.exec(t);return r?parseFloat(r[1]):void 0!==e?e:1}function l(t){var e=w.DATA_URI.exec(t);if(e)return{mediaType:e[1]?e[1].toLowerCase():void 0,subType:e[2]?e[2].toLowerCase():void 0,charset:e[3]?e[3].toLowerCase():void 0,encoding:e[4]?e[4].toLowerCase():void 0,data:e[5]}}function c(t){var e=w.URL_FILE_EXTENSION.exec(t);if(e)return e[1].toLowerCase()}function d(t){var e=w.SVG_SIZE.exec(t),r={};return e&&(r[e[1]]=Math.round(parseFloat(e[3])),r[e[5]]=Math.round(parseFloat(e[7]))),r}function f(){X=!0}function p(t){if(!X){if(navigator.userAgent.toLowerCase().indexOf("chrome")>-1){var e=["\n %c %c %c PixiJS "+w.VERSION+" - ✰ "+t+" ✰ %c %c http://www.pixijs.com/ %c %c ♥%c♥%c♥ \n\n","background: #ff66a5; padding:5px 0;","background: #ff66a5; padding:5px 0;","color: #ff66a5; background: #030307; padding:5px 0;","background: #ff66a5; padding:5px 0;","background: #ffc3dc; padding:5px 0;","background: #ff66a5; padding:5px 0;","color: #ff2424; background: #fff; padding:5px 0;","color: #ff2424; background: #fff; padding:5px 0;","color: #ff2424; background: #fff; padding:5px 0;"];window.console.log.apply(console,e)}else window.console&&window.console.log("PixiJS "+w.VERSION+" - "+t+" - http://www.pixijs.com/");X=!0}}function v(){var t={stencil:!0,failIfMajorPerformanceCaveat:!0};try{if(!window.WebGLRenderingContext)return!1;var e=document.createElement("canvas"),r=e.getContext("webgl",t)||e.getContext("experimental-webgl",t),n=!(!r||!r.getContextAttributes().stencil);if(r){var i=r.getExtension("WEBGL_lose_context");i&&i.loseContext()}return r=null,n}catch(t){return!1}}function g(t){return 0===t?0:t<0?-1:1}function y(){var t=void 0;for(t in G)G[t].destroy();for(t in W)W[t].destroy()}function m(){var t=void 0;for(t in G)delete G[t];for(t in W)delete W[t]}function _(t,e){return H[e?1:0][t]}function b(t,e){if(1===e)return(255*e<<24)+t;if(0===e)return 0;var r=t>>16&255,n=t>>8&255,i=255&t;return r=r*e+.5|0,n=n*e+.5|0,i=i*e+.5|0,(255*e<<24)+(r<<16)+(n<<8)+i}function x(t,e,r,n){return r=r||new Float32Array(4),n||void 0===n?(r[0]=t[0]*e,r[1]=t[1]*e,r[2]=t[2]*e):(r[0]=t[0],r[1]=t[1],r[2]=t[2]),r[3]=e,r}function T(t,e,r,n){return r=r||new Float32Array(4),r[0]=(t>>16&255)/255,r[1]=(t>>8&255)/255,r[2]=(255&t)/255,(n||void 0===n)&&(r[0]*=e,r[1]*=e,r[2]*=e),r[3]=e,r}r.__esModule=!0,r.premultiplyBlendMode=r.BaseTextureCache=r.TextureCache=r.earcut=r.mixins=r.pluginTarget=r.EventEmitter=r.removeItems=r.isMobile=void 0,r.uid=o,r.hex2rgb=s,r.hex2string=a,r.rgb2hex=u,r.getResolutionOfUrl=h,r.decomposeDataUri=l,r.getUrlFileExtension=c,r.getSvgSize=d,r.skipHello=f,r.sayHello=p,r.isWebGLSupported=v,r.sign=g,r.destroyTextureCache=y,r.clearTextureCache=m,r.correctBlendMode=_,r.premultiplyTint=b,r.premultiplyRgba=x,r.premultiplyTintToRgba=T;var w=t("../const"),E=t("../settings"),S=i(E),O=t("eventemitter3"),M=i(O),P=t("./pluginTarget"),C=i(P),R=t("./mixin"),A=n(R),I=t("ismobilejs"),D=n(I),L=t("remove-array-items"),N=i(L),B=t("./mapPremultipliedBlendModes"),F=i(B),k=t("earcut"),j=i(k),U=0,X=!1;r.isMobile=D,r.removeItems=N.default,r.EventEmitter=M.default,r.pluginTarget=C.default,r.mixins=A,r.earcut=j.default;var G=r.TextureCache=Object.create(null),W=r.BaseTextureCache=Object.create(null),H=r.premultiplyBlendMode=(0,F.default)()},{"../const":46,"../settings":101,"./mapPremultipliedBlendModes":126,"./mixin":128,"./pluginTarget":129,earcut:2,eventemitter3:3,ismobilejs:4,"remove-array-items":31}],126:[function(t,e,r){"use strict";function n(){for(var t=[],e=[],r=0;r<32;r++)t[r]=r,e[r]=r;t[i.BLEND_MODES.NORMAL_NPM]=i.BLEND_MODES.NORMAL,t[i.BLEND_MODES.ADD_NPM]=i.BLEND_MODES.ADD,t[i.BLEND_MODES.SCREEN_NPM]=i.BLEND_MODES.SCREEN,e[i.BLEND_MODES.NORMAL]=i.BLEND_MODES.NORMAL_NPM,e[i.BLEND_MODES.ADD]=i.BLEND_MODES.ADD_NPM,e[i.BLEND_MODES.SCREEN]=i.BLEND_MODES.SCREEN_NPM;var n=[];return n.push(e),n.push(t),n}r.__esModule=!0,r.default=n;var i=t("../const")},{"../const":46}],127:[function(t,e,r){"use strict";function n(t){return o.default.tablet||o.default.phone?4:t}r.__esModule=!0,r.default=n;var i=t("ismobilejs"),o=function(t){return t&&t.__esModule?t:{default:t}}(i)},{ismobilejs:4}],128:[function(t,e,r){"use strict";function n(t,e){if(t&&e)for(var r=Object.keys(e),n=0;n1?this._fontStyle="italic":t.indexOf("oblique")>-1?this._fontStyle="oblique":this._fontStyle="normal",t.indexOf("small-caps")>-1?this._fontVariant="small-caps":this._fontVariant="normal";var e=t.split(" "),r=-1;this._fontSize=26;for(var i=0;i-1&&r=this._durations[this.currentFrame];)n-=this._durations[this.currentFrame]*i,this._currentTime+=i;this._currentTime+=n/this._durations[this.currentFrame]}else this._currentTime+=e;this._currentTime<0&&!this.loop?(this.gotoAndStop(0),this.onComplete&&this.onComplete()):this._currentTime>=this._textures.length&&!this.loop?(this.gotoAndStop(this._textures.length-1),this.onComplete&&this.onComplete()):r!==this.currentFrame&&(this.loop&&this.onLoop&&(this.animationSpeed>0&&this.currentFramer&&this.onLoop()),this.updateTexture())},e.prototype.updateTexture=function(){this._texture=this._textures[this.currentFrame],this._textureID=-1,this.cachedTint=16777215,this.onFrameChange&&this.onFrameChange(this.currentFrame)},e.prototype.destroy=function(e){this.stop(),t.prototype.destroy.call(this,e)},e.fromFrames=function(t){for(var r=[],n=0;n  +
+ +
+ | The green edge forwards an incoming marble to the left or to the right side. |
+|
| The green edge forwards an incoming marble to the left or to the right side. |
+|  | The blue Bit forwards an incoming marble to the left or right, depending on its position. Flips (changes its position) after a marble passes through it. |
+|
| The blue Bit forwards an incoming marble to the left or right, depending on its position. Flips (changes its position) after a marble passes through it. |
+|  +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+