Долгое время я не знал, что все это значит в htop.
Я думал, что средняя загрузка 1,0 на моей двухъядерной машине означает, что загрузка процессора составляет 50%. Это не совсем верно. А также, почему он говорит 1.0?
Я решил посмотреть все и задокументировать это здесь.
Они также говорят, что лучший способ научиться чему-то - это научить этому.
- htop на Ubuntu Server 16.04 x64
- Uptime
- Средняя нагрузка
- Процессы
- ID / PID процесса
- Дерево процессов
- Пользователь процесса
- Состояние процесса
- R - работает или работает (в очереди выполнения)
- S - прерывистый сон (ожидание завершения события)
- D - непрерывный сон (обычно IO)
- Z - не существующий ("зомби") процесс, завершенный, но не собранный его родителем
- T - остановлено сигналом управления работой
- t - остановлен отладчиком во время трассировки
- Время процесса
- Любезность процессов и приоритеты
- Использование памяти - VIRT/RES/SHR/MEM
- VIRT/VSZ - виртуальный образ
- RES/RSS - Размер резидента
- SHR - размер общей памяти
- MEM% - использование памяти
- Процессы
- До
/sbin/init/lib/systemd/systemd-journald/sbin/lvmetad -f/lib/systemd/udevd/lib/systemd/timesyncd/usr/sbin/atd -f/usr/lib/snapd/snapd/usr/bin/dbus-daemon/lib/systemd/systemd-logind/usr/sbin/cron -f/usr/sbin/rsyslogd -n/usr/sbin/acpid/usr/bin/lxcfs /var/lib/lxcfs//usr/lib/accountservice/accounts-daemon/sbin/mdadm/usr/lib/policykit-1/polkitd --no-debug/usr/sbin/sshd -D/sbin/iscsid/sbin/agetty --noclear tty1 linuxsshd: root@pts/0&-bash&htop- После
- Аппендикс
- Исходный код
- Файловые дескрипторы и перенаправление
- Цвета в PuTTY
- Shell в C
- TODO
- Обновления
Вот скриншот htop, который я собираюсь описать.

Время работы показывает, как долго работает система.
Вы можете увидеть ту же информацию, запустив uptime:
$ uptime
12:17:58 up 111 days, 31 min, 1 user, load average: 0.00, 0.01, 0.05
Как программа uptime узнает об этом?
Читает информацию из файла /proc/uptime.
9592411.58 9566042.33
Первое число - это общее количество секунд, в течение которых система работала. Второе число показывает, сколько времени машина провела в режиме ожидания, в секундах. Второе значение может быть больше, чем общее время безотказной работы системы в системах с несколькими ядрами, поскольку оно является суммой.
Как я узнал это? Я посмотрел, какие файлы программа uptime открывает при запуске. Мы можем использовать инструмент "strace", чтобы сделать это.
strace uptime
Будет много вывода. Мы можем сделать grep для системного вызова open. Но это не сработает, поскольку strace выводит все в поток стандартных ошибок (stderr). Мы можем перенаправить stderr в стандартный поток вывода (stdout) с помощью 2>&1.
Наш вывод такой:
$ strace uptime 2>&1 | grep open
...
open("/proc/uptime", O_RDONLY) = 3
open("/var/run/utmp", O_RDONLY|O_CLOEXEC) = 4
open("/proc/loadavg", O_RDONLY) = 4
который содержит файл /proc/uptime, о котором я упоминал.
Оказывается, вы также можете использовать strace -e open uptime и не беспокоиться о grepping.
Так зачем нам нужна программа uptime, если мы можем просто прочитать содержимое файла? Результат uptime хорошо отформатирован для людей, тогда как количество секунд более полезно для использования в ваших собственных программах или скриптах.
Помимо времени безотказной работы, было также три числа, представляющих среднюю нагрузку.
$ uptime
12:59:09 up 32 min, 1 user, load average: 0.00, 0.01, 0.03
Они взяты из файла /proc/loadavg. Если вы еще раз посмотрите на вывод strace, вы увидите, что этот файл также был открыт.
$ cat /proc/loadavg
0.00 0.01 0.03 1/120 1500
Первые три столбца представляют среднюю загрузку системы за последние 1, 5 и 15-минутные периоды. Четвертый столбец показывает количество запущенных в данный момент процессов и общее количество процессов. В последнем столбце отображается последний использованный идентификатор процесса.
Начнем с последнего номера.
Каждый раз, когда вы запускаете новый процесс, ему присваивается идентификационный номер. Идентификаторы процесса обычно увеличиваются, если они не были исчерпаны и используются повторно. Идентификатор процесса с 1 принадлежит /sbin/init, который запускается во время загрузки.
Давайте снова посмотрим на содержимое /proc/loadavg и затем запустим команду sleep в фоновом режиме. Когда он запущен в фоновом режиме, будет показан его идентификатор процесса.
$ cat /proc/loadavg
0.00 0.01 0.03 1/123 1566
$ sleep 10 &
[1] 1567
Таким образом, 1/123 означает, что в данный момент запущен или готов к запуску один процесс и всего 123 обработано.
Когда вы запускаете htop и видите только один запущенный процесс, это означает, что это сам процесс htop.
Если вы запустите sleep 30 и снова запустите htop, вы заметите, что все еще только один запущенный процесс. Это потому, что sleep не работает, он спит или бездействует или, другими словами, ждет, когда что-то случится. Запущенный процесс - это процесс, который в данный момент выполняется на физическом процессоре или ожидает своей очереди для запуска на процессоре.
Если вы запустите cat /dev/urandom > /dev/null, который многократно генерирует случайные байты и записывает их в специальный файл, из которого никогда не производится чтение, вы увидите, что теперь есть два запущенных процесса.
$ cat /dev/urandom > /dev/null &
[1] 1639
$ cat /proc/loadavg
1.00 0.69 0.35 2/124 1679
Итак, теперь есть два запущенных процесса (генерация случайных чисел и cat, который читает содержимое /proc/loadavg), и вы также заметите, что средние значения нагрузки увеличились.
Средняя загрузка представляет собой среднюю загрузку системы за период времени.
Число загрузок рассчитывается путем подсчета количества запущенных (в данный момент запущенных или ожидающих выполнения) и непрерывных процессов (ожидающих активности диска или сети). Так что это просто ряд процессов.
Тогда средние значения нагрузки - это среднее число этих процессов за последние 1, 5 и 15 минут, верно?
Оказывается, не все так просто.
Среднее значение нагрузки является экспоненциально демпфированным скользящим средним числа нагрузки. Из Википедии:
Математически говоря, все три значения всегда усредняют всю загрузку системы с момента запуска системы. Все они экспоненциально разлагаются, но разлагаются с разной скоростью. Следовательно, 1-минутное среднее значение нагрузки будет составлять 63% нагрузки с последней минуты, плюс 37% нагрузки с момента запуска, исключая последнюю минуту. Таким образом, технически неточно, что среднее значение нагрузки за 1 минуту включает только последние 60 секунд активности (поскольку оно все еще включает 37% активности за прошлый период), но в основном включает последнюю минуту.
Это то, что вы ожидали?
Давайте вернемся к нашей генерации случайных чисел.
$ cat /proc/loadavg
1.00 0.69 0.35 2/124 1679
Хотя это технически неверно, я упростил средние значения нагрузки, чтобы было легче рассуждать о них.
В этом случае процесс генерации случайных чисел связан с процессором, поэтому средняя загрузка за последнюю минуту составляет 1,00 или в среднем 1 запущенный процесс.
Поскольку в моей системе только один процессор, загрузка процессора составляет 100%, поскольку мой процессор может одновременно запускать только один процесс.
Если бы у меня было два ядра, загрузка моего процессора составляла бы 50%, поскольку мой компьютер мог запускать два процесса одновременно. Средняя нагрузка на компьютер с 2 ядрами, который загружен на 100%, составила бы 2.00.
Вы можете увидеть количество ваших ядер или процессоров в верхнем левом углу «htop» или запустив «nproc».
Поскольку в число загрузки также входят процессы в непрерывном состоянии, которые не оказывают большого влияния на загрузку ЦП, не совсем правильно выводить использование ЦП из средних значений нагрузки, как я только что сделал. Это также объясняет, почему вы можете видеть высокие средние нагрузки, но не слишком большую нагрузку на процессор.
Но есть такие инструменты, как mpstat, которые могут показать мгновенную загрузку процессора.
$ sudo apt install sysstat -y
$ mpstat 1
Linux 4.4.0-47-generic (hostname) 12/03/2016 _x86_64_ (1 CPU)
10:16:20 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:16:21 PM all 0.00 0.00 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:16:22 PM all 0.00 0.00 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:16:23 PM all 0.00 0.00 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
# ...
# kill cat /dev/urandom
# ...
10:17:00 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:17:01 PM all 1.00 0.00 0.00 2.00 0.00 0.00 0.00 0.00 0.00 97.00
10:17:02 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
Почему тогда мы используем средние нагрузки?
$ curl -s https://raw.githubusercontent.com/torvalds/linux/v4.8/kernel/sched/loadavg.c | head -n 7
/*
* kernel/sched/loadavg.c
*
* This file contains the magic bits required to compute the global loadavg
* figure. Its a silly number but people think its important. We go through
* great pains to make it work on big machines and tickless kernels.
*/
В верхнем правом углу htop показывает общее количество процессов и их количество. Но он говорит: «Задачи, а не процессы». Зачем?
Другое название процесса - это задача. Ядро Linux внутренне называет процессы задачами. htop использует Задачи вместо Процессов, вероятно, потому что он короче и экономит место на экране.
Вы также можете увидеть темы в htop. Чтобы переключить видимость потоков, нажмите Shift + H на клавиатуре. Если вы видите `Tasks: 23, 10 thr', это означает, что они видны.
Вы также можете видеть потоки ядра с помощью Shift + K. Когда они будут видны, он скажет Tasks: 23, 40 kthr.
Каждый раз, когда запускается новый процесс, ему присваивается идентификационный номер (ID), который для краткости называется ID процесса или PID.
Если вы запустите программу в фоновом режиме (&) из bash, вы увидите номер задания в квадратных скобках и PID.
$ sleep 1000 &
[1] 12503
Если вы пропустили это, вы можете использовать переменную $! В bash, которая будет расширяться до последнего фонового идентификатора процесса.
$ echo $!
12503
Идентификатор процесса очень полезен. С его помощью можно увидеть детали процесса и контролировать его.
procfs - это псевдо файловая система, которая позволяет пользовательским программам получать информацию из ядра, читая файлы. Обычно он монтируется в /proc/ и для вас выглядит как обычный каталог, который вы можете просматривать с помощью ls и cd.
Вся информация, связанная с процессом, находится в /proc/<pid>/.
$ ls /proc/12503
attr coredump_filter fdinfo maps ns personality smaps task
auxv cpuset gid_map mem numa_maps projid_map stack uid_map
cgroup cwd io mountinfo oom_adj root stat wchan
clear_refs environ limits mounts oom_score schedstat statm
cmdline exe loginuid mountstats oom_score_adj sessionid status
comm fd map_files net pagemap setgroups syscall
Например, /proc/<pid>/cmdline даст команду, которая использовалась для запуска процесса.
$ cat /proc/12503/cmdline
sleep1000$
Тьфу, это не правильно. Оказывается, команда отделяется байтом \0.
$ od -c /proc/12503/cmdline
0000000 s l e e p \0 1 0 0 0 \0
0000013
который мы можем заменить пробелом или переводом строки
$ tr '\0' '\n' < /proc/12503/cmdline
sleep
1000
$ strings /proc/12503/cmdline
sleep
1000
Каталог процесса для процесса может содержать ссылки! Например, cwd указывает на текущий рабочий каталог, а exe - исполняемый двоичный файл.
$ ls -l /proc/12503/{cwd,exe}
lrwxrwxrwx 1 ubuntu ubuntu 0 Jul 6 10:10 /proc/12503/cwd -> /home/ubuntu
lrwxrwxrwx 1 ubuntu ubuntu 0 Jul 6 10:10 /proc/12503/exe -> /bin/sleep
Вот как htop, top, ps и другие диагностические утилиты получают информацию о деталях процесса: они читают ее из /proc/<pid>/<file> .
Когда вы запускаете новый процесс, процесс, который запустил новый процесс, называется родительским процессом. Новый процесс теперь является дочерним процессом для родительского процесса. Эти отношения образуют древовидную структуру.
Если вы нажмете F5 в htop, вы увидите иерархию процесса.
Вы также можете использовать переключатель f с ps
$ ps f
PID TTY STAT TIME COMMAND
12472 pts/0 Ss 0:00 -bash
12684 pts/0 R+ 0:00 \_ ps f
или pstree
$ pstree -a
init
├─atd
├─cron
├─sshd -D
│ └─sshd
│ └─sshd
│ └─bash
│ └─pstree -a
...
Если вы когда-нибудь задавались вопросом, почему вы часто видите bash или sshd как родителей некоторых из ваших процессов, вот почему.
Вот что происходит, когда вы запускаете, скажем, date из вашей оболочки bash:
bashсоздает новый процесс, который является его копией (с помощью системного вызоваfork)- он затем загрузит программу из исполняемого файла
/bin/dateв память (используя системный вызов exec) bash, как родительский процесс будет ожидать завершения своего потомка
Таким образом, /sbin/init с идентификатором 1 был запущен при загрузке, который породил демон SSH sshd. Когда вы подключаетесь к компьютеру, sshd запускает процесс для сеанса, который, в свою очередь, запускает оболочку bash.
Мне нравится использовать это древовидное представление в htop, когда я заинтересован видеть все потоки.
Каждый процесс принадлежит пользователю. Пользователи представлены с числовым идентификатором.
$ sleep 1000 &
[1] 2045
$ grep Uid /proc/2045/status
Uid: 1000 1000 1000 1000
Вы можете использовать команду id, чтобы узнать имя этого пользователя.
$ id 1000
uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu),4(adm)
Оказывается, id получает эту информацию из файлов /etc/passwd и /etc/group.
$ strace -e open id 1000
...
open("/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 3
open("/lib/x86_64-linux-gnu/libnss_compat.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/lib/x86_64-linux-gnu/libnss_files.so.2", O_RDONLY|O_CLOEXEC) = 3
open("/etc/passwd", O_RDONLY|O_CLOEXEC) = 3
open("/etc/group", O_RDONLY|O_CLOEXEC) = 3
...
Это связано с тем, что файл конфигурации Name Service Switch (NSS) /etc/nsswitch.conf говорит об использовании этих файлов для разрешения имен.
$ head -n 9 /etc/nsswitch.conf
# ...
passwd: compat
group: compat
shadow: compat
Значение compat (режим совместимости) такое же, как files, за исключением того, что разрешены другие специальные записи. files означает, что база данных хранится в файле (загружается с помощью libnss_files.so). Но вы также можете хранить своих пользователей в других базах данных и службах или использовать, например, облегченный протокол доступа к каталогам (LDAP).
/etc/passwd и /etc/group - это простые текстовые файлы, которые отображают числовые идентификаторы в удобочитаемые имена.
$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
ubuntu:x:1000:1000:Ubuntu:/home/ubuntu:/bin/bash
$ cat /etc/group
root:x:0:
adm:x:4:syslog,ubuntu
ubuntu:x:1000:
passwd? Но где пароли?
На самом деле они находятся в /etc/shadow.
$ sudo cat /etc/shadow
root:$6$mS9o0QBw$P1ojPSTexV2PQ.Z./rqzYex.k7TJE2nVeIVL0dql/:17126:0:99999:7:::
daemon:*:17109:0:99999:7:::
ubuntu:$6$GIfdqlb/$ms9ZoxfrUq455K6UbmHyOfz7DVf7TWaveyHcp.:17126:0:99999:7:::
Что это за бред?
$6$- используемый алгоритм хеширования паролей, в данном случае он обозначается какsha512- сопровождается случайно сгенерированной солью для защиты от радужных атак
- и наконец хэш вашего пароля + соль
Когда вы запустите программу, она будет запущена под вашим пользователем. Даже если исполняемый файл не принадлежит вам.
Если вы хотите запустить программу от имени пользователя root или другого пользователя, для этого и нужен sudo.
$ id
uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu),4(adm)
$ sudo id
uid=0(root) gid=0(root) groups=0(root)
$ sudo -u ubuntu id
uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu),4(adm)
$ sudo -u daemon id
uid=1(daemon) gid=1(daemon) groups=1(daemon)
Но что, если вы хотите войти в систему как другой пользователь для запуска различных команд? Используйте sudo bash или sudo -u user bash. Вы сможете использовать оболочку в качестве этого пользователя.
Если вам не нравится, когда вас постоянно просят ввести пароль root, вы можете просто отключить его, добавив своего пользователя в файл /etc/sudoers.
Давай попробуем:
$ echo "$USER ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
-bash: /etc/sudoers: Permission denied
Правильно, только root может это сделать.
$ sudo echo "$USER ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
-bash: /etc/sudoers: Permission denied
WTF?
Здесь происходит то, что вы выполняете команду echo от имени пользователя root, но добавляете строку в файл /etc/sudoers как пользователь.
Обычно есть два пути:
echo "$USER ALL=(ALL) NOPASSWD: ALL" | sudo tee -a /etc/sudoerssudo bash -c "echo '$USER ALL=(ALL) NOPASSWD: ALL' >> /etc/sudoers"
В первом случае tee -a добавит свой стандартный ввод в файл, и мы выполним эту команду как root.
Во втором случае мы запускаем bash от имени пользователя root и просим его выполнить команду (-c), и вся команда будет выполнена от имени пользователя root. Обратите внимание на хитрый "/' трюк здесь, который будет диктовать, когда переменная $USER будет расширена.
Если вы посмотрите на файл /etc/sudoers, то увидите, что он начинается с
$ sudo head -n 3 /etc/sudoers
#
# This file MUST be edited with the 'visudo' command as root.
#
Ооо
Это полезное предупреждение о том, что вы должны редактировать этот файл с помощью sudo visudo. Он проверит содержимое файла перед сохранением и предотвратит ваши ошибки. Если вы не используете visudo и допускаете ошибку, это может заблокировать вас от sudo. Это означает, что вы не сможете исправить свою ошибку!
Допустим, вы хотите изменить свой пароль. Вы можете сделать это командой passwd. Он, как мы видели ранее, сохранит пароль в файл /etc/shadow.
Этот файл чувствителен и доступен для записи только пользователю root:
$ ls -l /etc/shadow
-rw-r----- 1 root shadow 1122 Nov 27 18:52 /etc/shadow
Так как же возможно, что программа passwd, выполняемая обычным пользователем, может записывать в защищенный файл?
Ранее я говорил, что когда вы запускаете процесс, он принадлежит вам, даже если владельцем исполняемого файла является другой пользователь.
Оказывается, вы можете изменить это поведение, изменив права доступа к файлам. Давайте взглянем.
$ ls -l /usr/bin/passwd
-rwsr-xr-x 1 root root 54256 Mar 29 2016 /usr/bin/passwd
Обратите внимание на букву s. Это было сделано с помощью sudo chmod u+s /usr/bin/passwd. Это означает, что исполняемый файл будет запущен как владелец файла, который в этом случае является root.
Вы можете найти так называемые исполняемые файлы setuid с помощью команды find /bin -user root -perm -u+s.
Обратите внимание, что вы можете сделать то же самое с группой (g + s).
Далее мы рассмотрим столбец состояния процесса в htop, который обозначается просто буквой S.
Вот возможные значения:
R запущен или готов к запуску (в очереди выполнения)
S прерывистый сон (ожидание завершения события)
D непрерывный сон (обычно IO)
Z не существующий ("зомби") процесс, прерванный, но не собранный его родителем
T остановлен сигналом управления работой
t остановлен отладчиком во время трассировки
X мертвый (никогда не должно быть видно)
Я заказал их по тому, как часто я их вижу.
Обратите внимание, что когда вы запускаете ps, он также показывает подсостояния, такие как Ss, R+, Ss+ и т.д.
$ ps x
PID TTY STAT TIME COMMAND
1688 ? Ss 0:00 /lib/systemd/systemd --user
1689 ? S 0:00 (sd-pam)
1724 ? S 0:01 sshd: vagrant@pts/0
1725 pts/0 Ss 0:00 -bash
2628 pts/0 R+ 0:00 ps x
В этом состоянии процесс в данный момент выполняется или находится в очереди выполнения, ожидающей запуска.
Что значит бегать?
Когда вы компилируете исходный код написанной вами программы, этот машинный код является инструкциями процессора. Он сохраняется в файл, который может быть выполнен. Когда вы запускаете программу, она загружается в память, а затем процессор выполняет эти инструкции.
В основном это означает, что процессор физически выполняет инструкции. Или, другими словами, производит подсчеты.
Это означает, что инструкции кода этого процесса не выполняются на процессоре. Вместо этого этот процесс ожидает чего-то - события или условия - чтобы это произошло. Когда происходит событие, ядро устанавливает состояние на выполнение.
Одним из примеров является sleep от coreutils. Он будет спать в течение определенного количества секунд (приблизительно).
$ sleep 1000 &
[1] 10089
$ ps f
PID TTY STAT TIME COMMAND
3514 pts/1 Ss 0:00 -bash
10089 pts/1 S 0:00 \_ sleep 1000
10094 pts/1 R+ 0:00 \_ ps f
Так что это прерывистый сон. Как мы можем прервать это?
Отправив сигнал.
Вы можете отправить сигнал в htop, нажав F9 и выбрав один из сигналов в меню слева.
Отправка сигнала также называется kill. Это потому, что kill - это системный вызов, который может послать сигнал процессу. Существует программа /bin/kill, которая может сделать этот системный вызов из пользовательского пространства, и используемый по умолчанию сигнал - TERM, который попросит завершить процесс или, другими словами, попытаться его убить.
Сигнал это просто число. Числа трудно запомнить, поэтому мы даем им имена. Имена сигналов обычно пишутся в верхнем регистре и могут начинаться с префикса SIG.
Некоторыми обычно используемыми сигналами являются INT, KILL, STOP, CONT, HUP.
Давайте прервем процесс ожидания, отправив сигнал INT aka SIGINT aka 2 aka Terminal interrupt.
$ kill -INT 10089
[1]+ Interrupt sleep 1000
Это также то, что происходит, когда вы нажимаете CTRL + C на клавиатуре. bash отправит переднему плану обработать сигнал SIGINT, как мы это делали вручную.
Кстати, в bash, kill является встроенной командой, хотя в большинстве систем есть /bin/kill. Зачем? Это позволяет уничтожать процессы, если достигнут предел для процессов, которые вы можете создать.
Эти команды делают то же самое:
kill -INT 10089kill -2 10089/bin/kill -2 10089
Еще один полезный сигнал, который нужно знать, это SIGKILL aka 9. Возможно, вы использовали его, чтобы убить процесс, который не реагировал на ваши неистовые нажатия клавиш CTRL+C.
Когда вы пишете программу, вы можете настроить обработчики сигналов, которые будут вызываться при получении сигнала вашим процессом. Другими словами, вы можете поймать сигнал и затем что-то сделать, например, очистить и корректно завершить работу. Поэтому отправка SIGINT (пользователь хочет прервать процесс) и SIGTERM (пользователь хочет завершить процесс) не означает, что процесс будет прерван.
Возможно, вы видели это исключение при запуске скриптов Python:
$ python -c 'import sys; sys.stdin.read()'
^C
Traceback (most recent call last):
File "<string>", line 1, in <module>
KeyboardInterrupt
Вы можете указать ядру принудительно завершить процесс и не давать ему изменения, чтобы ответить, отправив сигнал KILL:
$ sleep 1000 &
[1] 2658
$ kill -9 2658
[1]+ Killed sleep 1000
В отличие от прерывистого сна, вы не можете разбудить этот процесс с сигналом. Вот почему многие люди боятся видеть это состояние. Вы не можете убить такие процессы, потому что уничтожение означает отправку сигналов SIGKILL процессам.
Это состояние используется, если процесс должен ждать без прерывания или когда событие должно произойти быстро. Как чтение с/на диск. Но это должно произойти только на долю секунды.
Вот хороший ответ по StackOverflow.
Непрерывные процессы обычно ожидают ввода-вывода после сбоя страницы. Процесс / задача не могут быть прерваны в этом состоянии, потому что он не может обрабатывать какие-либо сигналы; если это произойдет, произойдет сбой другой страницы, и он вернется туда, где он был.
Другими словами, это может произойти, если вы используете сетевую файловую систему (NFS), и для чтения и записи требуется некоторое время.
Или, по моему опыту, это также может означать, что некоторые процессы свопят, что означает, что у вас слишком мало доступной памяти.
Давайте попробуем заставить процесс войти в непрерывный сон.
8.8.8.8 - публичный DNS-сервер, предоставленный Google. У них там нет открытой NFS. Но это не остановит нас.
$ sudo mount 8.8.8.8:/tmp /tmp &
[1] 12646
$ sudo ps x | grep mount.nfs
12648 pts/1 D 0:00 /sbin/mount.nfs 8.8.8.8:/tmp /tmp -o rw
Как узнать, что вызывает это? strace!
Давайте strace команду в выводе ps выше.
$ sudo strace /sbin/mount.nfs 8.8.8.8:/tmp /tmp -o rw
...
mount("8.8.8.8:/tmp", "/tmp", "nfs", 0, ...
Таким образом, системный вызов mount блокирует процесс.
Если вам интересно, вы можете запустить mount с опцией intr, чтобы запустить как прерываемый: sudo mount 8.8.8.8:/tmp /tmp -o intr.
Когда процесс завершается через exit и у него все еще есть дочерние процессы, дочерние процессы становятся процессами-зомби.
- Если процессы зомби существуют в течение короткого времени, это совершенно нормально
- Зомби-процессы, которые существуют долгое время, могут указывать на ошибку в программе
- Процессы зомби не потребляют память, просто идентификатор процесса
- Вы не можете "убить" процесс зомби
- Вы можете попросить родительский процесс пожать(reap) зомби (сигнал
SIGCHLD) - Вы можете "убить" родительский процесс зомби, чтобы избавиться от родителя и его зомби
Я собираюсь написать код на C, чтобы показать это.
Вот наша программа.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
printf("Running\n");
int pid = fork();
if (pid == 0) {
printf("I am the child process\n");
printf("The child process is exiting now\n");
exit(0);
} else {
printf("I am the parent process\n");
printf("The parent process is sleeping now\n");
sleep(20);
printf("The parent process is finished\n");
}
return 0;
}
Давайте установим компилятор GNU C (GCC).
sudo apt install -y gcc
Скомпилируйте и запустите
gcc zombie.c -o zombie
./zombie
Посмотрите на дерево процессов
$ ps f
PID TTY STAT TIME COMMAND
3514 pts/1 Ss 0:00 -bash
7911 pts/1 S+ 0:00 \_ ./zombie
7912 pts/1 Z+ 0:00 \_ [zombie] <defunct>
1317 pts/0 Ss 0:00 -bash
7913 pts/0 R+ 0:00 \_ ps f
Мы получили нашего зомби!
When the parent process is done, the zombie is gone.
$ ps f
PID TTY STAT TIME COMMAND
3514 pts/1 Ss+ 0:00 -bash
1317 pts/0 Ss 0:00 -bash
7914 pts/0 R+ 0:00 \_ ps f
Если вы замените sleep (20) на while (true);, то зомби сразу исчезнет.
С помощью exit вся память и связанные с ней ресурсы освобождаются, чтобы их могли использовать другие процессы.
Зачем тогда держать процессы зомби?
У родительского процесса есть возможность узнать код завершения дочернего процесса (в обработчике сигналов) с помощью системного вызова wait. Если процесс спит, то ему нужно дождаться его пробуждения.
Почему бы просто не разбудить его силой и не убить? По той же причине вы не бросаете своего ребенка в мусорное ведро, когда вы устали от него. Могут случиться плохие вещи.
Я открыл два окна терминала и могу просматривать процессы моего пользователя с помощью ps u.
$ ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 1317 0.0 0.9 21420 4992 pts/0 Ss+ Jun07 0:00 -bash
ubuntu 3514 1.5 1.0 21420 5196 pts/1 Ss 07:28 0:00 -bash
ubuntu 3528 0.0 0.6 36084 3316 pts/1 R+ 07:28 0:00 ps u
Я опущу процессы -bash и ps u из вывода ниже.
Теперь запустите cat /dev/urandom> /dev/null в одном окне терминала. Его состояние R+ означает, что он работает.
$ ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 3540 103 0.1 6168 688 pts/1 R+ 07:29 0:04 cat /dev/urandom
Нажмите CTRL + Z, чтобы остановить процесс.
$ # CTRL+Z
[1]+ Stopped cat /dev/urandom > /dev/null
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 3540 86.8 0.1 6168 688 pts/1 T 07:29 0:15 cat /dev/urandom
Его состояние теперь T.
Запустите fg в первом терминале, чтобы возобновить его.
Другой способ остановить такой процесс - отправить сигнал STOP с kill процессу. Чтобы возобновить выполнение процесса, вы можете использовать сигнал CONT.
Сначала установите GNU Debugger (gdb)
sudo apt install -y gdb
Запустите программу, которая будет прослушивать входящие сетевые подключения через порт 1234.
$ nc -l 1234 &
[1] 3905
Он спит, то есть ожидает данных из сети.
$ ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 3905 0.0 0.1 9184 896 pts/0 S 07:41 0:00 nc -l 1234
Запустите отладчик и присоедините его к процессу с идентификатором 3905.
sudo gdb -p 3905
Вы увидите, что состояние t означает, что этот процесс отслеживается в отладчике.
$ ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ubuntu 3905 0.0 0.1 9184 896 pts/0 t 07:41 0:00 nc -l 1234
Linux является многозадачной операционной системой, что означает, что даже если у вас один ЦП, вы можете запускать несколько процессов одновременно. Вы можете подключиться к вашему серверу через SSH и посмотреть на вывод htop, пока ваш веб-сервер доставляет содержимое вашего блога вашим читателям через Интернет.
Как это возможно, когда один процессор может выполнять только одну инструкцию за раз?
Ответ - разделение времени.
Один процесс выполняется некоторое время, затем он приостанавливается, в то время как другие процессы, ожидающие запуска, по очереди работают некоторое время. Время, которое выполняется процессом, называется интервалом времени.
Временной интервал обычно составляет несколько миллисекунд, поэтому вы не особо замечаете это, когда ваша система не находится под высокой нагрузкой. (Было бы очень интересно узнать, как долго в Linux обычно работают срезы(time slice)).
Это должно помочь объяснить, почему средняя загрузка - это среднее число запущенных процессов. Если у вас есть только одно ядро, а средняя нагрузка равна 1,0, загрузка ЦП была равна 100%. Если средняя нагрузка выше, чем 1,0, это означает, что число процессов, которые нужно запустить, больше, чем может запустить ЦП, что может привести к замедлению или задержке. Если нагрузка ниже 1.0, это означает, что процессор иногда бездействует и ничего не делает.
Это также должно дать вам понять, почему иногда время выполнения процесса, который выполнялся в течение 10 секунд, выше или ниже, чем ровно 10 секунд.
Когда у вас есть больше задач для выполнения, чем количество доступных процессорных ядер, вам каким-то образом нужно решить, какие задачи запускать дальше, а какие продолжать ждать. За это отвечает планировщик задач.
Планировщик в ядре Linux отвечает за выбор того, какой процесс в очереди выполнения выбрать следующим, и это зависит от алгоритма планировщика, используемого в ядре.
Обычно вы не можете влиять на планировщик, но вы можете сообщить ему, какие процессы важнее для вас, и планировщик может принять это во внимание.
Niceness (NI) - это приоритет процессов в пространстве пользователя, варьирующийся от -20, который является самым высоким приоритетом, до 19, который является самым низким приоритетом. Это может сбивать с толку, но вы можете думать, что хороший процесс уступает менее приятному процессу. Таким образом, чем приятнее процесс, тем больше он приносит результатов.
Из того, что я собрал, прочитав StackOverflow и другие сайты, повышение уровня полезности(niceness) на 1 должно увеличить процессное время на 10%.
Приоритет (PRI) - это приоритет пространства ядра, который используется ядром Linux. Приоритеты варьируются от 0 до 139, а диапазон от 0 до 99 - в режиме реального времени и от 100 до 139 для пользователей.
Вы можете изменить ограниченность, и ядро учитывает это, но вы не можете изменить приоритет.
Отношение между приятным значением и приоритетом:
PR = 20 + NI
таким образом, значение PR = 20 + (от -20 до +19) составляет от 0 до 39, что отображает от 100 до 139.
Вы можете установить привлекательность процесса перед его запуском.
nice -n niceness program
Измените значение, если программа уже запущена с renice.
renice -n niceness -p PID
Вот что означают цвета использования процессора:
- Синий: потоки с низким приоритетом (nice > 0)
- Зеленый: потоки с нормальным приоритетом
- Красный: потоки ядра
http://askubuntu.com/questions/656771/process-niceness-vs-priority
У процесса есть иллюзия быть единственным в памяти. Это достигается с помощью виртуальной памяти.
Процесс не имеет прямого доступа к физической памяти. Вместо этого у него есть собственное виртуальное адресное пространство, и ядро переводит адреса виртуальной памяти в физическую память или может отображать некоторые из них на диск. Вот почему может показаться, что процессы используют больше памяти, чем установлено на вашем компьютере.
Смысл, который я хочу здесь подчеркнуть, состоит в том, что не очень просто определить, сколько памяти занимает процесс. Вы также хотите посчитать общие библиотеки или дисковую память? Но ядро предоставляет и htop показывает некоторую информацию, которая может помочь вам оценить использование памяти.
Вот что означают цвета использования памяти:
- Зеленый: используемая память
- Синий: буферы
- Оранжевый: Кэш
Общий объем виртуальной памяти, используемой задачей. Он включает в себя весь код, данные и общие библиотеки, а также страницы, которые были заменены, и страницы, которые были отображены, но не использовались.
VIRT - это использование виртуальной памяти. Он включает в себя все, включая файлы, отображенные в памяти.
Если приложение запрашивает 1 ГБ памяти, но использует только 1 МБ, то VIRT выдаст 1 ГБ. Если он mmapит 1 ГБ файл и никогда не использует его, VIRT также сообщит 1 ГБ.
В большинстве случаев это бесполезные данные.
Непеременная(non-swapped) физическая память, используемая задачей.
RES - это резидентное использование памяти, то есть то, что в данный момент находится в физической памяти.
Хотя RES может быть лучшим индикатором того, сколько памяти использует процесс, чем VIRT, имейте в виду, что
- это не включает выгруженную память
- часть памяти может быть использована другими процессами
Если процесс использует 1 ГБ памяти и вызывает fork (), результатом разветвления будут два процесса, для которых RES равен 1 ГБ, но фактически будет использоваться только 1 ГБ, поскольку Linux использует копирование при записи.
Объем разделяемой памяти, используемой задачей. Он просто отражает память, которая потенциально может использоваться другими процессами.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
printf("Started\n");
sleep(10);
size_t memory = 10 * 1024 * 1024; // 10 MB
char* buffer = malloc(memory);
printf("Allocated 10M\n");
sleep(10);
for (size_t i = 0; i < memory/2; i++)
buffer[i] = 42;
printf("Used 5M\n");
sleep(10);
int pid = fork();
printf("Forked\n");
sleep(10);
if (pid != 0) {
for (size_t i = memory/2; i < memory/2 + memory/5; i++)
buffer[i] = 42;
printf("Child used extra 2M\n");
}
sleep(10);
return 0;
}
fallocate -l 10G
gcc -std=c99 mem.c -o mem
./mem
Process Message VIRT RES SHR
main Started 4200 680 604
main Allocated 10M 14444 680 604
main Used 5M 14444 6168 1116
main Forked 14444 6168 1116
child Forked 14444 5216 0
main Child used extra 2M 8252 1116
child Child used extra 2M 5216 0
ТОДО: Я должен закончить это.
Используемая в настоящее время доля доступной физической памяти задачи.
Это RES, деленное на общее количество оперативной памяти, которое у вас есть.
Если RES равно 400M и у вас 8 гигабайт оперативной памяти, MEM% будет 400/8192 * 100\ =4.88%.
Я запустил дроплет Digital Ocean с Ubuntu Server.
Какие процессы запускаются при загрузке?
Вы действительно нуждаетесь в них?
Вот мои исследовательские заметки о процессах, которые запускаются при запуске новой капли Digital Ocean с Ubuntu Server 16.04.1 LTS x64.
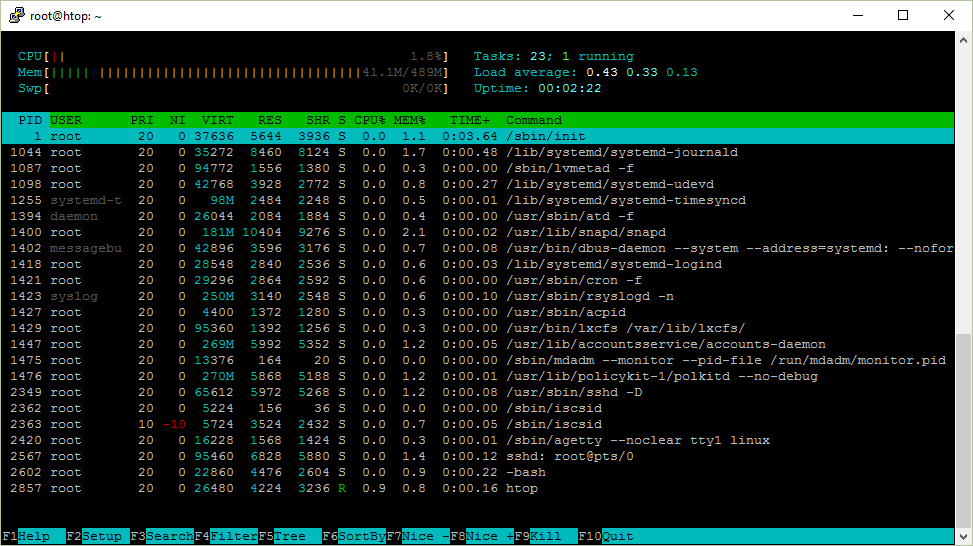
Программа /sbin/init (также называемая init) координирует остальную часть процесса загрузки и настраивает среду для пользователя.
Когда команда init запускается, она становится родителем или прародителем всех процессов, которые автоматически запускаются в системе.
Это systemd?
$ dpkg -S /sbin/init
systemd-sysv: /sbin/init
Да, это так.
Что произойдет, если ты убьешь его?
Ничего.
- https://wiki.ubuntu.com/SystemdForUpstartUsers
- https://www.centos.org/docs/5/html/5.1/Installation_Guide/s2-boot-init-shutdown-init.html
systemd-journald - системный сервис, который собирает и хранит данные журналов. Он создает и поддерживает структурированные, проиндексированные журналы на основе информации журнала, полученной из различных источников.
Другими словами:
Одним из основных изменений в journald было заменить простые текстовые файлы журнала специальным форматом, оптимизированным для сообщений журнала. Этот формат файлов позволяет системным администраторам более эффективно получать доступ к соответствующим сообщениям. Он также привносит некоторые возможности централизованного ведения журналов на основе баз данных в отдельные системы.
Вы должны использовать команду journalctl для запроса файлов журнала.
journalctl _COMM=sshdлоги по sshdjournalctl _COMM=sshd -o json-prettyлоги по sshd в JSONjournalctl --since "2015-01-10" --until "2015-01-11 03:00"journalctl --since 09:00 --until "1 hour ago"journalctl --since yesterdayjournalctl -bлоги с момента загрузкиjournalctl -fследить за журналамиjournalctl --disk-usagejournalctl --vacuum-size=1G
Довольно круто.
Похоже, что невозможно удалить или отключить эту службу, вы можете только отключить ведение журнала.
- https://www.freedesktop.org/software/systemd/man/systemd-journald.service.html
- https://www.digitalocean.com/community/tutorials/how-to-use-journalctl-to-view-and-manipulate-systemd-logs
- https://www.loggly.com/blog/why-journald/
- https://ask.fedoraproject.org/en/question/63985/how-to-correctly-disable-journald/
Демон lvmetad кэширует метаданные LVM, поэтому команды LVM могут читать метаданные без сканирования дисков.
Кэширование метаданных может быть преимуществом, поскольку сканирование дисков отнимает много времени и может мешать нормальной работе системы и дисков.
Но что такое LVM (управление логическими томами)?
Вы можете думать о LVM как о «динамических разделах», что означает, что вы можете создавать / изменять размер / удалять «разделы» LVM (они называются «логическими томами» на языке LVM) из командной строки, когда ваша система Linux работает: нет необходимо перезагрузить систему, чтобы ядро узнало о вновь созданных или измененных разделах.
Похоже, вы должны сохранить его, если вы используете LVM.
$ lvscan
$ sudo apt remove lvm2 -y --purge
- http://manpages.ubuntu.com/manpages/xenial/man8/lvmetad.8.html
- http://askubuntu.com/questions/3596/what-is-lvm-and-what-is-it-used-for
systemd-udevd слушает события ядра. Для каждого события systemd-udevd выполняет соответствующие инструкции, указанные в правилах udev.
udev - менеджер устройств для ядра Linux. Будучи преемником devfsd и hotplug, udev главным образом управляет узлами устройств в каталоге /dev.
Так что этот сервис управляет /dev.
Я не уверен, что мне нужно, чтобы он работал на виртуальном сервере.
- https://www.freedesktop.org/software/systemd/man/systemd-udevd.service.html
- https://wiki.archlinux.org/index.php/udev
systemd-timesyncd - это системная служба, которая может использоваться для синхронизации локальных системных часов с удаленным сервером протокола сетевого времени.
Так что это заменяет ntpd.
$ timedatectl status
Local time: Fri 2016-08-26 11:38:21 UTC
Universal time: Fri 2016-08-26 11:38:21 UTC
RTC time: Fri 2016-08-26 11:38:20
Time zone: Etc/UTC (UTC, +0000)
Network time on: yes
NTP synchronized: yes
RTC in local TZ: no
Если мы посмотрим на открытые порты на этом сервере:
$ sudo netstat -nlput
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 2178/sshd
tcp6 0 0 :::22 :::* LISTEN 2178/sshd
Прекрасный!
Ранее в Ubuntu 14.04 это было
$ sudo apt-get install ntp -y
$ sudo netstat -nlput
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1380/sshd
tcp6 0 0 :::22 :::* LISTEN 1380/sshd
udp 0 0 10.19.0.6:123 0.0.0.0:* 2377/ntpd
udp 0 0 139.59.256.256:123 0.0.0.0:* 2377/ntpd
udp 0 0 127.0.0.1:123 0.0.0.0:* 2377/ntpd
udp 0 0 0.0.0.0:123 0.0.0.0:* 2377/ntpd
udp6 0 0 fe80::601:6aff:fxxx:123 :::* 2377/ntpd
udp6 0 0 ::1:123 :::* 2377/ntpd
udp6 0 0 :::123 :::* 2377/ntpd
Ugh.
- https://www.freedesktop.org/software/systemd/man/systemd-timesyncd.service.html
- https://wiki.archlinux.org/index.php/systemd-timesyncd
atd - запускать задания в очереди для последующего выполнения. atd запускает задания в очереди в.
Команды at и batch read из стандартного ввода или указанного файла, которые должны быть выполнены позже
В отличие от cron, который планирует задания, которые периодически повторяются, at запускает задание в определенное время один раз.
$ echo "touch /tmp/yolo.txt" | at now + 1 minute
job 1 at Fri Aug 26 10:44:00 2016
$ atq
1 Fri Aug 26 10:44:00 2016 a root
$ sleep 60 && ls /tmp/yolo.txt
/tmp/yolo.txt
Я на самом деле никогда не использовал его до сих пор.
sudo apt remove at -y --purge
- http://manpages.ubuntu.com/manpages/xenial/man8/atd.8.html
- http://manpages.ubuntu.com/manpages/xenial/man1/at.1.html
- http://askubuntu.com/questions/162439/why-does-ubuntu-server-run-both-cron-and-atd
Snappy Ubuntu Core - это новая версия Ubuntu с обновлениями транзакций - минимальный образ сервера с теми же библиотеками, что и в современной Ubuntu, но приложения предоставляются с помощью более простого механизма.
Что?
Сегодня разработчики из нескольких дистрибутивов Linux и компаний объявили о сотрудничестве в универсальном формате пакетов Linux, позволяющем единому двоичному пакету работать идеально и безопасно на любом настольном компьютере, сервере, облаке или устройстве Linux.
По всей видимости, это упрощенный пакет deb, и вы должны объединить все зависимости в одину оснастку(snap), которую вы можете распространять.
Я никогда не использовал snappy для развертывания или распространения приложений на серверах.
sudo apt remove snapd -y --purge
- https://developer.ubuntu.com/en/snappy/
- https://insights.ubuntu.com/2016/06/14/universal-snap-packages-launch-on-multiple-linux-distros/
В вычислениях D-Bus или DBus - это механизм межпроцессного взаимодействия (IPC) и удаленного вызова процедур (RPC), который позволяет осуществлять связь между несколькими компьютерными программами (то есть процессами), одновременно запущенными на одном компьютере.
Насколько я понимаю, вам это нужно для настольных сред, но на сервере для запуска веб-приложений?
sudo apt remove dbus -y --purge
Интересно, который час и синхронизируется ли он с NTP?
$ timedatectl status
Failed to create bus connection: No such file or directory
К сожалению. Должен, вероятно, сохранить это.
systemd-logind - это системный сервис, который управляет логинами пользователей.
cron - демон для выполнения запланированных команд (Vixie Cron)
-fОставайтесь в режиме переднего плана, не демонизируйте.
Вы можете запланировать выполнение задач периодически с помощью cron.
Используйте crontab -e для редактирования конфигурации вашего пользователя или в Ubuntu. Я обычно использую каталоги /etc/cron.hourly, /etc/cron.daily и т.д.
Вы можете увидеть файлы журнала с
grep cron /var/log/syslogorjournalctl _COMM=cronor evenjournalctl _COMM=cron --since="date" --until="date"
Вы, вероятно, хотите сохранить Cron.
Но если вы этого не сделаете, то вам следует остановить и отключить службу:
sudo systemctl stop cron
sudo systemctl disable cron
Потому что в противном случае при попытке удалить его с помощью apt remove cron он попытается установить postfix!
$ sudo apt remove cron
The following packages will be REMOVED:
cron
The following NEW packages will be installed:
anacron bcron bcron-run fgetty libbg1 libbg1-doc postfix runit ssl-cert ucspi-unix
Похоже, cron нужен почтовый агент (MTA) для отправки писем.
$ apt show cron
Package: cron
Version: 3.0pl1-128ubuntu2
...
Suggests: anacron (>= 2.0-1), logrotate, checksecurity, exim4 | postfix | mail-transport-agent
$ apt depends cron
cron
...
Suggests: anacron (>= 2.0-1)
Suggests: logrotate
Suggests: checksecurity
|Suggests: exim4
|Suggests: postfix
Suggests: <mail-transport-agent>
...
exim4-daemon-heavy
postfix
- https://help.ubuntu.com/community/CronHowto
- https://www.digitalocean.com/community/tutorials/how-to-use-cron-to-automate-tasks-on-a-vps
- http://unix.stackexchange.com/questions/212355/where-is-my-logfile-of-crontab
Rsyslogd - системная утилита, обеспечивающая поддержку регистрации сообщений.
Другими словами, это то, что заполняет файлы журналов в /var/log/, например /var/ log/auth.log, для сообщений аутентификации, таких как попытки входа по SSH.
Файлы конфигурации находятся в /etc/rsyslog.d.
Вы также можете настроить rsyslogd для отправки файлов журнала на удаленный сервер и внедрения централизованного ведения журнала.
Вы можете использовать команду logger для записи сообщений в /var/log/syslog в фоновых скриптах, таких как те, которые запускаются при загрузке.
#!/bin/bash
logger Starting doing something
# NFS, get IPs, etc.
logger Done doing something
Да, но у нас уже работает systemd-journald. Нужен ли нам также rsyslogd?
Rsyslog и Journal, два приложения для ведения журналов, представленные в вашей системе, имеют несколько отличительных особенностей, которые делают их подходящими для конкретных случаев использования. Во многих ситуациях полезно комбинировать их возможности, например, создавать структурированные сообщения и сохранять их в файловой базе данных. Интерфейс связи, необходимый для этого взаимодействия, обеспечивается модулями ввода и вывода на стороне Rsyslog и коммуникационным сокетом журнала.
Так что, может быть? Я оставлю это на всякий случай.
- http://manpages.ubuntu.com/manpages/xenial/man8/rsyslogd.8.html
- http://manpages.ubuntu.com/manpages/xenial/man1/logger.1.html
- https://wiki.archlinux.org/index.php/rsyslog
- https://www.digitalocean.com/community/tutorials/how-to-centralize-logs-with-rsyslog-logstash-and-elasticsearch-on-ubuntu-14-04
- https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/System_Administrators_Guide/s1-interaction_of_rsyslog_and_journal.html
acpid - демон событий расширенной конфигурации и интерфейса питания
acpid предназначен для уведомления программ пользовательского пространства о событиях ACPI. acpid должен быть запущен во время загрузки системы и по умолчанию будет работать как фоновый процесс.
В вычислительной технике спецификация расширенного интерфейса конфигурации и питания (ACPI) предоставляет открытый стандарт, который операционные системы могут использовать для обнаружения и настройки компонентов аппаратного обеспечения компьютера, для управления питанием, например, переводя неиспользуемые компоненты в спящий режим и сделать мониторинг состояния.
Но я на виртуальном сервере, который я не собираюсь приостанавливать/возобновлять.
Я собираюсь удалить это для удовольствия и посмотреть, что произойдет.
sudo apt remove acpid -y --purge
Я смог успешно "перезагрузить" дроплет, но после "остановки" Digital Ocean подумал, что он все еще включен, поэтому мне пришлось отключить питание с помощью веб-интерфейса.
Так что я, наверное, должен сохранить это.
- http://manpages.ubuntu.com/manpages/xenial/man8/acpid.8.html
- https://en.wikipedia.org/wiki/Advanced_Configuration_and_Power_Interface
Lxcfs - это файловая система fuse, в основном предназначенная для использования контейнерами lxc. В системе Ubuntu 15.04 она будет использоваться по умолчанию для обеспечения двух вещей: во-первых, виртуального просмотра некоторых файлов /proc; и во-вторых, фильтрованный доступ к файловым системам хоста cgroup.
Таким образом, теперь на хосте 15.04 вы можете создать контейнер обычным способом: lxc-create ... Полученный контейнер будет иметь «правильные» результаты для uptime, top и т. Д.
По сути, это обходной путь в пользовательском пространстве к изменениям, которые считались необоснованными в ядре. Это делает контейнеры более похожими на отдельные системы, чем без них.
Не используете контейнеры LXC? Вы можете удалить это с
sudo apt remove lxcfs -y --purge
- https://insights.ubuntu.com/2015/03/02/introducing-lxcfs/
- https://www.stgraber.org/2016/03/31/lxcfs-2-0-has-been-released/
Пакет AccountsService предоставляет набор интерфейсов D-Bus для запроса и обработки информации об учетных записях пользователей и реализации этих интерфейсов на основе команд usermod (8), useradd (8) и userdel (8).
Когда я удалил DBus, он сломал temedatectl, интересно, что удалит этот сервис.
sudo apt remove accountsservice -y --purge
Время покажет.
mdadm - это утилита Linux, используемая для управления и мониторинга программных RAID-устройств.
Имя получено из узлов устройства md (несколько устройств), которые оно администрирует или управляет, и оно заменило предыдущую утилиту mdctl. Первоначальное название было «Зеркальный диск», но было изменено по мере увеличения функциональности.
RAID - это метод использования нескольких жестких дисков в качестве одного. Существует два назначения RAID: 1) Расширить емкость диска: RAID 0. Если у вас 2 х 500 ГБ жесткого диска, то общее пространство становится 1 ТБ. 2) Предотвращение потери данных в случае сбоя диска: например, RAID 1, RAID 5, RAID 6 и RAID 10.
Вы можете удалить это с
sudo apt remove mdadm -y --purge
- https://en.wikipedia.org/wiki/Mdadm
- https://help.ubuntu.com/community/Installation/SoftwareRAID
- http://manpages.ubuntu.com/manpages/xenial/man8/mdadm.8.html
polkitd - PolicyKit daemon
polkit - структура авторизации
Насколько я понимаю, это похоже на детализированный sudo. Вы можете разрешить пользователям без привилегий выполнять определенные действия от имени пользователя root. Например, перезагрузите компьютер, когда вы используете Linux на настольном компьютере.
Но я работаю на сервере. Вы можете удалить это с
sudo apt remove policykit-1 -y --purge
Все еще интересно, если это что-то ломает.
- http://manpages.ubuntu.com/manpages/xenial/man8/polkitd.8.html
- http://manpages.ubuntu.com/manpages/xenial/man8/polkit.8.html
- http://www.admin-magazine.com/Articles/Assigning-Privileges-with-sudo-and-PolicyKit
- https://wiki.archlinux.org/index.php/Polkit#Configuration
sshd (OpenSSH Daemon) - это программа-демон для ssh.
-D Если указана эта опция, sshd не отсоединится и не станет демоном. Это позволяет легко контролировать sshd.
iscsid - это демон (системная служба), который работает в фоновом режиме, воздействует на конфигурацию iSCSI и управляет соединениями. Из его справочной страницы:
Iscsid реализует путь управления по протоколу iSCSI, а также некоторые средства управления. Например, демон может быть настроен на автоматический перезапуск обнаружения при запуске на основе содержимого постоянной базы данных iSCSI.
http://unix.stackexchange.com/questions/216239/iscsi-vs-iscsid-services
Я никогда не слышал о iSCSI:
В вычислительной технике iSCSI(Listeni/aɪˈskʌzi/ eye-skuz-ee) является аббревиатурой от интерфейса малых компьютерных систем Интернета, сетевого стандарта хранения данных на основе Интернет-протокола (IP) для связи средств хранения данных.
Передавая команды SCSI по IP-сетям, iSCSI используется для облегчения передачи данных по интрасетям и для управления хранением на больших расстояниях. iSCSI может использоваться для передачи данных по локальным сетям (LAN), глобальным сетям (WAN) или Интернету и может обеспечивать независимое от местоположения хранение и поиск данных.
Протокол позволяет клиентам (так называемые инициаторы) отправлять команды SCSI (CDB) на устройства хранения SCSI (цели) на удаленных серверах. Это протокол сети хранения данных (SAN), позволяющий организациям консолидировать хранилище в массивы хранения центров обработки данных, предоставляя хостам (таким как базы данных и веб-серверы) иллюзию локально подключенных дисков.
Вы можете удалить это с
sudo apt remove open-iscsi -y --purge
agetty - альтернативный линукс getty
getty, сокращение от «get tty», - это программа Unix, работающая на главном компьютере, который управляет физическими или виртуальными терминалами (TTY). Когда он обнаруживает соединение, он запрашивает имя пользователя и запускает программу «login» для аутентификации пользователя.
Первоначально в традиционных системах Unix getty обрабатывал соединения с последовательными терминалами (часто компьютерами Teletype), подключенными к главному компьютеру. Tty часть названия расшифровывается как Teletype, но стала обозначать любой тип текстового терминала.
Это позволяет вам входить в систему, когда вы физически находитесь на сервере. В Digital Ocean вы можете щелкнуть «Консоль» в сведениях о дроплете, и вы сможете взаимодействовать с этим терминалом в своем браузере (я думаю, это VNC-соединение).
В старые времена вы видели, как группа ttys запускала загрузку системы (настроенную в /etc/inittab), но в настоящее время они запускаются по требованию systemd.
Ради интереса я удалил этот файл конфигурации, который запускает и генерирует agetty:
sudo rm /etc/systemd/system/getty.target.wants/[email protected]
sudo rm /lib/systemd/system/[email protected]
Когда я перезагрузил сервер, я все еще мог подключиться к нему через SSH, но больше не мог войти в систему с веб-консоли Digital Ocean.

- http://manpages.ubuntu.com/manpages/xenial/man8/getty.8.html
- https://en.wikipedia.org/wiki/Getty_(Unix)
- http://0pointer.de/blog/projects/serial-console.html
- http://unix.stackexchange.com/questions/56531/how-to-get-fewer-ttys-with-systemd
sshd: root @ pts / 0 означает, что был установлен сеанс SSH для пользователя root на псевдотерминале # 0 (pts). Псевдотерминал эмулирует реальный текстовый терминал.
bash - это оболочка, которую я использую.
Почему в начале есть тире? Пользователь Reddit hirnbrot услужливо объяснил это:
В начале есть тире, потому что запуск «-bash» превратит его в оболочку входа. Оболочка входа - это та, чей первый символ аргумента ноль -, или тот, который начинается с опции --login. Это тогда заставит читать другой набор файлов конфигурации.
htop - это интерактивный инструмент для просмотра процессов, который запускается на скриншоте.
sudo apt remove lvm2 -y --purge
sudo apt remove at -y --purge
sudo apt remove snapd -y --purge
sudo apt remove lxcfs -y --purge
sudo apt remove mdadm -y --purge
sudo apt remove open-iscsi -y --purge
sudo apt remove accountsservice -y --purge
sudo apt remove policykit-1 -y --purge

Экстремальное издание:
sudo apt remove dbus -y --purge
sudo apt remove rsyslog -y --purge
sudo apt remove acpid -y --purge
sudo systemctl stop cron && sudo systemctl disable cron
sudo rm /etc/systemd/system/getty.target.wants/[email protected]
sudo rm /lib/systemd/system/[email protected]

Я следовал инструкциям в своем блоге об автоматической установке WordPress на Ubuntu Server, и это работает.
Вот nginx, PHP7 и MySQL.

Иногда смотреть на «strace» недостаточно.
Еще один способ выяснить, что делает программа, - посмотреть на ее исходный код.
Во-первых, мне нужно выяснить, с чего начать.
$ which uptime
/usr/bin/uptime
$ dpkg -S /usr/bin/uptime
procps: /usr/bin/uptime
Здесь мы обнаруживаем, что uptime на самом деле находится в /usr/bin/uptime и что в Ubuntu он является частью пакета procps.
Затем вы можете перейти на packages.ubuntu.com и найти пакет там.
Вот страница для procps:http://packages.ubuntu.com/source/xenial/procps
Если вы прокрутите страницу вниз, вы увидите ссылки на репозитории исходного кода:
- Исходный репозиторий пакетов Debian git://git.debian.org/collab-maint/procps.git
- Исходный репозиторий пакетов Debian (просматривается)https://anonscm.debian.org/cgit/collab-maint/procps.git/
Если вы хотите перенаправить стандартную ошибку (stderr) на стандартный вывод (stdout), это 2&>1 или 2>&1?
Вы можете запомнить, куда идет амперсанд &, зная, что echo что-то> файл запишет что-то в файл file. Это так же, как echo что-то 1> файл. Теперь echo что-то 2> файл запишет вывод stderr в файл file.
Если вы пишете echo что-то 2>1, это означает, что вы перенаправляете stderr в файл с именем 1. Добавьте пробелы, чтобы было понятнее: echo что-то 2>1.
Если вы добавите & перед 1, это означает, что 1 - это не имя файла, а идентификатор потока. Так что это echo что-то 2>&1.

Если у вас отсутствуют элементы в htop, когда вы используете PuTTY, вот как это решить.
- Щелкните правой кнопкой мыши на строке заголовка
- Нажмите Изменить настройки ...
- Перейти к окну -> Цвета
- Выберите переключатель оба
- Нажмите Применить

Давайте напишем очень простую оболочку на C, которая демонстрирует использование системных вызовов fork/exec/wait. Вот программа shell.c.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main() {
printf("Welcome to my shell\n");
char line[1024];
while (1) {
printf("> ");
fgets(line, sizeof(line), stdin);
line[strlen(line)-1] = '\0'; // strip \n
if (strcmp(line, "exit") == 0) // shell built-in
break;
int pid = fork();
if (pid == 0) {
printf("Executing: %s\n", line);
if (execlp(line, "", NULL) == -1) {
printf("ERROR!\n");
exit(1);
}
} else if (pid > 0) {
int status;
waitpid(pid, &status, 0);
printf("Child exited with %d\n", WEXITSTATUS(status));
} else {
printf("ERROR!\n");
break;
}
}
return 0;
}
Скомпилируйте программу.
gcc shell.c -o shell
И запустить его.
$ ./shell
Welcome to my shell
> date
Executing: date
Thu Dec 1 14:10:59 UTC 2016
Child exited with 0
> true
Executing: true
Child exited with 0
> false
Executing: false
Child exited with 1
> exit
Задумывались ли вы, что когда вы запускаете процесс в фоновом режиме, вы видите, что он завершился только через некоторое время, когда вы нажали Enter?
$ sleep 1 &
[1] 11686
$ # press Enter
[1]+ Done sleep 1
Это потому, что оболочка ждет вашего ввода. Только при вводе команды она проверяет состояние фоновых процессов и показывает, были ли они завершены.
Вот о чем я хотел бы узнать больше.
- состояния процесса (
Ss,Ss+,R+и т. д.) - потоки ядра
/dev/pts- больше о памяти (
CODE,DATA,SWAP) - выяснить длину отрезков времени
- алгоритм планировщика Linux
- закрепление процессов за ядрами
- написать о справочных страницах
- цвета ЦП/памяти в барах
- предел идентификатора процесса и форк бомба
lsof,ionice,schedtool
Вот список несущественных исправлений и обновлений с момента публикации поста.
- Время простоя в
/proc/uptimeявляется суммой всех ядер (2 декабря 2016 г.) - Мой родительский / дочерний
printfвzombie.cбыл изменен (2 декабря 2016 г.) apt remove cronустанавливаетpostfixиз-за зависимости от MTA (3 декабря 2016 г.)idможет загружать информацию из других источников (через/etc/nsswitch.conf), а не только из/etc/passwd(3 декабря 2016 г.)- Опишите
/etc/shadowформат хэша пароля (3 декабря 2016 г.) - Используйте
visudoдля редактирования файла/etc/sudoers, чтобы он был безопасным (3 декабря 2016 г.) - Объясните
MEM%(3 декабря 2016 г.) - Перепишите раздел о средних значениях нагрузки (4 декабря 2016 г.)
- Исправлено:
kill 1234по умолчанию отправляетTERM, а неINT(7 декабря 2016 г.) - Объясните цветовые полосы процессора и памяти (7 декабря 2016 г.)